51c大模型~合集49
我自己的原文哦~ https://blog.51cto.com/whaosoft/11960038
#Illuminate
任意论文一键变播客,谷歌正式发布Illuminate,它能重构研究者的学习方式吗?
像听书一样「读」论文。
先来听一段英文播客,内容是不是很熟悉?
,时长04:27
是的,这俩人就是在聊那篇《Attention is All You Need》。在 4 分半的对话里,他们介绍了论文的核心内容,一问一答,听上去相当自然。
播客原址:https://illuminate.google.com/home?pli=1&play=Pa5iGH1___bGy1
实际上,播客中对谈的双方都是 AI,生成这段四分钟音频内容的产品是 Illuminate,来自谷歌。
Illuminate 是一个将学术论文转化为人工智能生成的音频讨论的项目。已有用户晒出自己的试用结果,效果不错:
谷歌实验室在邀请用户尝试「前沿技术」方面有着悠久的历史。Illuminate 最早在今年五月的 Google I/O 大会上亮相,当时谷歌重点强调了自身大模型的多模态和长文本能力。但那时 Illuminate 只是一个私人测试版本。
显然,谷歌未必是第一个想出这个点子的公司,但却是第一个做出这个产品的公司:
当时 Illuminate 的宣传点是「按照自己的方式学习」。因为 Illuminate 可以使用 AI 将复杂的研究论文转化为引人入胜的音频对话,从而「重新构想学习」。
想法很简单:由谷歌的 LLM Gemini 生成论文摘要和问答,在引入两个人工智能生成的声音,一个男性采访者和一个女性专家,分工完成一个简短的采访,描述论文内容。
目前,在 Google Illuminate 网站上,已经能够收听到一些经典研究的播客样本。

这个产品在什么场景下用呢?
设想,你可以在运动或开车时「聆听」那些看不过来的新增研究论文核心内容。
同时,播客还可以很容易地调整为其他叙述形式,以适应不同的使用场景。
也许你想马上动手制作一期属于自己论文的播客,别急,让我们看看使用说明。
如何将论文一键转化为播客访谈?
打开 Illuminate,界面如下所示。需要注意的是,用户需先申请候选名单,通过审核后才能使用。
目前,Illuminate 针对已发表的关于计算机科学的论文进行了优化。

体验地址:https://illuminate.google.com/home
官方网站上列举了很多示例,我们以经典论文《Attention is All You Need》为例。首先,你可以查看原始论文,点击「View Source」直达论文,这样一来,用户既可以回顾论文内容,也可以根据播客音频进行学习。

接着点击「play」选项,在界面下方是生成的两个 AI 对话的访谈。这是 Illuminate 的关键部分,对话内容围绕研究展开。
我们还是以《Attention is All You Need》为例,对话过程涉及很多知识点,可能是你在读论文时没有注意到的,比如论文的核心概念是什么。生成的音频内容干货满满,会谈到「序列模型 RNN、LSTM, 这些模型在语言处理、翻译和文本摘要等任务中占据主导地位,但这些 RNN 在处理长序列时有明显的不足,因为它们需要一步步处理信息,这是一个重大限制。
而这篇论文通过引入一种名为 Transformer 的模型来解决这个问题,该模型使用一种称为自注意力的机制,可以一次性处理整个序列,从而识别出哪些部分最相关…… Transformer 还引入了多头注意力机制,它不仅仅使用一个注意力机制,而是使用多个注意力头……」
听完整段对话,你对论内容会有一个重新的认识。
随着 Illuminate 的不断完善,以后遇到新论文,就可以先让 Illuminate 帮你做好预习,在之后的阅读过程中,就会轻松很多。

对于生成的音频内容,如果你没听清,可以后退数秒,也可以前进几秒,甚至还可以控制语速,0.5 倍、2 倍速都可以选择。

点击「share」按钮,你可以将播客内容分享到各个平台。

下面是我们将对话内容分享到 X。你不用编辑任何文本,分享的内容都是自动生成的。这样一来,其他人也可以点开链接进行查看、学习。
除了论文,Illuminate 处理一整本书也是可以的,官方网站上已经列举了很多名著,如《傲慢与偏见》《本杰明・富兰克林自传》等等。

不过,整体看下来,Illuminate 还是有些小缺点,比如生成的对话都是英文,音频不能下载,也没有相应的字幕。或许,不久的将来,我们会看到更加用户友好的 Illuminate。
#A Survey on Graph Neural Networks and Graph Transformers in Computer Vision: A Task-Oriented Perspective
计算机视觉中基于图神经网络和图Transformers的方法和最新进展
本篇综述工作已被《IEEE 模式分析与机器智能汇刊》(IEEE TPAMI)接收,作者来自三个团队:香港大学俞益洲教授与博士生陈超奇、周洪宇,香港中文大学(深圳)韩晓光教授与博士生吴毓双、许牧天,上海科技大学杨思蓓教授与硕士生戴启元。
近年来,由于在图表示学习(graph representation learning)和非网格数据(non-grid data)上的性能优势,基于图神经网络(Graph Neural Networks,GNN)的方法被广泛应用于不同问题并且显著推动了相关领域的进步,包括但不限于数据挖掘(例如,社交网络分析、推荐系统开发)、计算机视觉(例如,目标检测、点云处理)和自然语言处理(例如,关系提取、序列学习)。考虑到图神经网络已经取得了丰硕的成果,一篇全面且详细的综述可以帮助相关研究人员掌握近年来计算机视觉中基于图神经网络的方法的进展,以及从现有论文中总结经验和产生新的想法。可惜的是,我们发现由于图神经网络在计算机视觉中应用非常广泛,现有的综述文章往往在全面性或者时效性上存在不足,因此无法很好的帮助科研人员入门和熟悉相关领域的经典方法和最新进展。同时,如何合理地组织和呈现相关的方法和应用是一个不小的挑战。
论文标题:A Survey on Graph Neural Networks and Graph Transformers in Computer Vision: A Task-Oriented Perspective
论文地址:https://arxiv.org/abs/2209.13232(预印版)https://ieeexplore.ieee.org/document/10638815(IEEE 版)
尽管基于卷积神经网络(CNN)的方法在处理图像等规则网格上定义的输入数据方面表现出色,研究人员逐渐意识到,具有不规则拓扑的视觉信息对于表示学习至关重要,但尚未得到彻底研究。与具有内在连接和节点概念的自然图数据(如社交网络)相比,从规则网格数据构建图缺乏统一的原则且严重依赖于特定的领域知识。另一方面,某些视觉数据格式(例如点云和网格)并非在笛卡尔网格上定义的,并且涉及复杂的关系信息。因此,规则和不规则的视觉数据格式都将受益于拓扑结构和关系的探索,特别是对于具有挑战性的任务,例如理解复杂场景、从有限的经验中学习以及跨领域进行知识传递。
在计算机视觉领域,目前许多与 GNN 相关的研究都有以下两个目标之一:(1) GNN 和 CNN 主干的混合,以及 (2) 用于表示学习的纯 GNN 架构。前者通常旨在提高基于 CNN 的特征的远程建模能力,并适用于以前使用纯 CNN 架构解决的视觉任务,例如图像分类和语义分割。后者用作某些视觉数据格式(例如点云)的特征提取器。尽管取得了丰硕的进展,但仍然没有一篇综述能够系统、及时地回顾基于 GNN 的计算机视觉的发展情况。
在本文中,我们首先介绍了图神经网络的发展史和最新进展,包括最常用、最经典的图神经网络和图 Transformers。然后,我们以任务为导向对计算机视觉中基于图神经网络(包括图 Transformers)的方法和最新进展进行了全面且详细的调研。具体来说,我们根据输入数据的模态将图神经网络在计算机视觉中的应用大致划分为五类:自然图像(二维)、视频、视觉 + 语言、三维数据(例如,点云)以及医学影像。在每个类别中,我们再根据视觉任务的不同对方法和应用进一步分类。这种以任务为导向的分类法使我们能够研究不同的基于图神经网络的方法是如何处理每个任务的,以及较为公平地比较这些方法在不同数据集上的性能,在内容上我们同时还涵盖了基于 Transformers 的图神经网络方法。对于不同的任务,我们系统性地总结了其统一的数学表达,阐明了我们组织这些文章的逻辑关系,突出了该领域的关键挑战,展示了图神经网络在应对这些挑战的独特优势,并讨论了它的局限和未来发展路线。

图神经网络发展史
GNN 最初以循环 GNN 的形式发展,用于从有向无环图中提取节点表示。随着研究的发展,GNN 逐渐扩展到更多类型的图结构,如循环图和无向图。受到深度学习中 CNN 的启发,研究人员开发了将卷积概念推广到图域的方法,主要包括基于频域的方法和基于空域的方法。频域方法依赖于图的拉普拉斯谱来定义图卷积,而空域方法则通过聚合节点邻居的信息来实现图卷积。这些方法为处理复杂的图结构和不规则拓扑提供了有效的工具,极大地推动了 GNN 在多个领域,尤其是计算机视觉中的应用和发展。

具体来说,我们详尽地调查了如下这些任务:
- 建立在自然图像(二维)上的视觉任务包括 Image Classification (multi-label、few-shot、zero-shot、transfer learning),Object Detection,Semantic Segmentation,和 Scene Graph Generation。
- 建立在视频上的视觉任务包括 Video Action Recognition,Temporal Action Localization,Multi-Object Tracking,Human Motion Prediction,和 Trajectory Prediction。
- 视觉 + 语言方向的任务包括 Visual Question Answering,Visual Grounding,Image Captioning,Image-Text Matching,和 Vision-Language Navigation。
- 建立在三维数据上的视觉任务包括 3D Representation Learning (Point Clouds、Meshes),3D Understanding (Point Cloud Segmentation、3D Object Detection、3D Visual Grounding),和 3D Generation (Point Cloud Completion、3D Data Denoising、3D Reconstruction)。
- 建立在医学影像上的任务包括 Brain Activity Investigation,Disease Diagnosis (Brain Diseases、Chest Diseases),Anatomy Segmentation (Brain Surfaces、Vessels、etc)。
总结来说,尽管在感知领域取得了突破性的进展,如何赋予深度学习模型推理能力仍然是现代计算机视觉系统面临的巨大挑战。在这方面,图神经网络和图 Transformers 在处理 “关系” 任务方面表现出了显著的灵活性和优越性。为此,我们从面向任务的角度首次对计算机视觉中的图神经网络和图 Transformers 进行了全面的综述。各种经典和最新的算法根据输入数据的模态(如图像、视频和点云)分为五类。通过系统地整理每个任务的方法,我们希望本综述能够为未来的更多进展提供启示。通过讨论关键的创新、局限性和潜在的研究方向,我们希望读者能够获得新的见解,并朝着类似人类的视觉理解迈进一步。
#腾讯大模型的「实用」路线
我们看到了企业应用AI的新方向
「现在每家公司都是 AI 公司,但引入 AI 之后,利润真的能提高吗?」
在针对 Transformer 作者、Cohere CEO Aidan Gomez 的一次采访中,播客主持人 Harry Stebbings 问出了这样一个问题。
Stebbings 提到,现在很多公司都在往产品中引入 AI,比如提供客户支持的 Zendesk、笔记记录软件 Notion、提供设计服务的 Canva…… 但是选择维持产品价格不变的 Canva 等公司却担心,自己的利润不升反降,因为他们现在要为每个查询付出更高的成本。Canva 甚至在最近的节目中直言不讳地表示,他们的利润正在压缩。
对于这一问题,Gomez 提到,其实企业不必过于担心,因为 AI 的成本正在迅速下降,在提升客户体验的同时维持产品价格不变会是一个不错的选择,有利于扩大企业的用户基数。
如果观察一下国内外的 AI 市场,我们会发现 Aidan Gomez 的预测是有依据的。很多 AI 公司,尤其是技术实力雄厚的大厂,都在通过技术升级来降低模型成本、提高模型可用性,从而让企业以更低的门槛使用 AI。
在国内,腾讯混元大模型走的就是这样一条路线。这个从亮相时就强调「实用」标签的大模型一直在持续进化。在刚刚过去的腾讯全球数字生态大会上,我们不仅看到了训练、推理效率提升 1 倍多,但推理成本降低 50% 的新模型混元 Turbo,还看到了升级版的大模型知识引擎、图像创作引擎、视频创作引擎等大模型产品。
对于那些还在怀疑自己是否有能力引入 AI,以及引入 AI 之后能否保住利润的企业来说,这些高性价比的模型以及低门槛、易用的大模型产品或许可以提供一个答案。
距 GPT-4o 仅 1.29%
混元 Turbo 拿下国内第一,价格还降了一半
效率提升,但成本不升反降的混元 Turbo 听上去似乎很有吸引力,但模型质量怎么样呢?第三方中文大模型基准测评机构 SuperCLUE 发布的《中文大模型基准测评 2024 年 8 月报告》提供了一个客观的参考。
这个报告聚焦通用能力测评,测评方案由理科、文科和 Hard 三大维度构成。理科能力包括计算、逻辑推理和代码能力;文科任务覆盖知识百科、语言理解、长文本、角色扮演、生成与创作、安全和工具使用;Hard 任务则侧重于精确指令遵循以及复杂任务高阶推理。
报告显示,混元 Turbo 在理科、文科均居于第一名,在 Hard 任务上表现也相当出色,是国内唯一超过 70 分的大模型,仅与 ChatGPT-4o 有微小差距。

腾讯混元在 8 项核心任务上排名国内第一。
更重要的是,在这个模型发布后,国内 TOP 1 大模型在中文领域的通用能力与国外领先模型的差距缩小到了 1.29%(总分相差 1 分左右)。而去年 5 月,这一数字还高达 30.12%。

所以,单从性能上来看,混元 Turbo 是可以满足很多企业对模型能力的高要求的。
那训练、推理效率提升超过 1 倍,推理部署成本下降 50% 是怎么做到的呢?简单总结就是:技术创新。
混元技术团队介绍说,相较于上一代混元 Pro MoE 大模型,Turbo 模型在数据优化之外自研了全新的万亿级分层异构 MoE 结构,在模型不同层采用不同的专家个数和不同的激活参数量,最终用更多的专家数、更少的激活参数量实现了更好的效果。

混元 Turbo 推理速度对比前代有明显提升。
这样的技术创新创造了更多的让利空间,使得混元 Turbo 的定价(输入和输出价格)仅为混元 Pro 版的一半。目前,该模型已经在腾讯云上线,企业和开发者可以通过 API 接入。
此外,腾讯混元的技术团队还在研究中发现,其实 MoE 架构不只适用于语言模型,用来构建多模态大模型也是最佳选择,因为它能够更好地兼容更多模态和任务,确保不同模态和任务之间是互相促进而非竞争的关系。
按照这个思路,他们构建了国内首个基于 MoE 架构的多模态大模型,而且以简单、合理、可规模化的原则来设计这个模型。比如,该模型支持原生任意分辨率,最高可支持的分辨率达到 7K,而不是采用业界主流的固定分辨率或切子图方法。此外,它采用的简单 MLP 适配器也能比主流的 Q-former 适配器损失更少的信息。这些实用的升级无疑是在为进入产业应用场景做好充分的准备。

腾讯混元多模态大模型是业内首个支持超过 7K 分辨率和任意长宽比图片理解的多模态模型。
模型之外,产品实用性也升级到 Next Level
「模型本身不是完整的产品,要搭很多能力。用户要用得爽,不是简单的『模型吐东西』。」在前段时间的一次采访中,腾讯集团高级执行副总裁、云与智慧产业事业群 CEO 汤道生分享了这样一个观点。
基于这种认知,腾讯云其实不止打造了腾讯混元系列大模型,还围绕这个大模型打磨了一系列精调工具链(基于 TI 平台)和开箱即用的产品,包括大模型知识引擎、图像创作引擎、视频创作引擎等。

这些工具链、产品看似分散,其实组合到一起能解决很多问题。
就拿要求最苛刻的医疗场景来说。当下,很多人吐槽医生人心冷漠 —— 病人背着大包小包、坐了十几个小时火车去看病,结果只能跟医生沟通五分钟,失落的心情可想而知。
但其实,医生也很无奈,尤其是负责重症病人的医生。因为他们每天要花大量时间去理清多维度、连续变化的患者数据,还要书写病历和病程记录,分不出时间和精力去精细化地关怀每个病人。
为了解决这一问题,为重症医疗提供器械和解决方案的迈瑞医疗和腾讯一起打造了首个重症大模型瑞智 GPT,并基于该模型开发了「病历撰写、患者个体化病情查询、重症知识检索」三个面向重症科室的大模型智能应用。
这些应用可以帮助医生灵活查询患者的病情变化、自动撰写病历,还能为低年资医生提供高年资医生的重症知识和诊疗建议,极大地降低了医生解读大量连续变化的临床数据的难度,缓解了撰写病历和病程记录的工作负担。
这个解决方案要打通医院的病历、生理参数、医学影像、检验、护理、医嘱等多个数据接口,还要把这些数据充分利用起来,因此涉及腾讯为行业打造的多个工具和产品。
比如数据准备环节要用到数据清洗、标注等多项 TI 平台上的能力,病历的识别、数据的检索离不开知识引擎中的 OCR 识别、语义切分、RAG、复杂表格处理等子能力(关于知识引擎,请参见《大模型进入「实用」时代!腾讯助力「销冠」量产,5 分钟创建智能助手》)。
在生态大会上,这些工具链、产品也迎来了新一轮升级,在「实用」维度上又上了一个台阶。
其中,TI 平台上线了多模态数据标注,支持文生文、图生文、图文改写、图文混合问答等全部细分任务类型。高质量的训练数据是精调出一个可落地大模型的前提条件。TI 平台的多模态数据集管理和数据标注能力,可大幅提升数据准备效率,提升最终效果。此外,针对 OCR 和工业质检等相对成熟且使用广泛的垂直场景,TI 平台也进行了升级,比如可智能反馈出模糊、反光等场景下的误识别,可实现超复杂场景「0 漏检」等。


TI 平台的多模态数据标注功能。
知识引擎在用户需求识别与理解、企业知识处理等能力上都有很大的升级。比如,技术团队综合运用向量检索、摘要检索、text2sql 多种技术手段,显著提升了复杂大表的检索及问答准确率。同时,他们升级了多模态知识解析、检索、阅读理解能力,实现读懂文中的「数据图」、「自然场景图」、「图文关系」。
,时长01:48
知识引擎的复杂大表检索及问答准确率显著提升。
图像创作引擎的图像风格化通过算法升级大幅降低了人脸瑕疵;AI 写真实现了免训练技术突破,支持输入一张照片,一键生成高清写真艺术照,整体出图耗时缩短 75%;商品背景生成的背景画面真实度、商品分割细腻度、实物融合自然度大幅提升;模特换装场景采用 3D 先验方案,提升了重建人像效果。

图像创作引擎生成的风格化图像。

图像创作引擎生成的高清 AI 写真照。

图像创作引擎生成的商品背景图,实现了商品在不同场景的逼真效果展示。

图像创作引擎生成的模特换装图,高度保持了模特脸部和手部的细节,同时精确地将服装版型与模特身体特征对齐,确保换装后的效果逼真自然,能直接用于电商等生产场景。
视频创作引擎新增了图片跳舞、图片唱演和视频转译等能力。其中,在图片跳舞中,单段舞蹈的生成时间从 10 分钟下降至 1 分钟级别,同时支持转身、侧身等复杂舞蹈动作。图片唱演可以支持一张人像图片生成一段唱演视频。视频转译支持 15 + 小语种,覆盖主流外语翻译,可应用于视频本地化、跨境电商等场景。

人物跳舞自然度的提升得益于技术团队基于 3D 身体重建技术进一步优化了算法,画面的真实度和自然度也有了明显提升。
,时长00:29
唱演视频生成的人物的面部表情和情绪演绎都更加自然灵动。
,时长00:32
转译后的视频能够保留说话人的音色特征,同时实现说话人口型与目标语种一致的视听效果。
引入最强 AI,做最有用的产品
回到文章开头的问题 —— 企业引入 AI 真的是一个具有经济效益的选择吗?在生态大会现场,易车研发平台部总经理孙佑时分享了他们的经验。
就拿看车这个常见的场景来说。以往,用户线上看车基本就是打开图片或录制好的视频,被动听里面的讲解,缺乏现场看车的沉浸感。为了解决这个问题,易车和腾讯合作,基于内置在 TI 平台的大模型,使用大模型精调工具链,精调训练出「易车大模型」。这个大模型能为用户提供 3D 看车、AI 解读、AI 对比问答和 AI 搜索等服务,增强了用户获取信息的效率。据统计,这些功能上线后,用户的停留时长有了 大幅提升。
此外,我们看到,已经引入 AI 的企业也已经在下一个维度开卷。比如前文提到的 Zendesk 改变了传统的 SaaS 收费模式,提出只有在聊天机器人独立完成任务、不需要员工介入时,才会向企业收费。相信这会给还未引入 AI 或者引入的 AI 不够强的同行造成一些压力。
正如 Gomez 所说,如果你想扩大用户群体,那就为他们提供目前最有用的产品。一旦用户体验提升,利润自然就会随之而来。更何况,AI 的成本确实在下降,能做的事情也越来越多。
而且,除了经济效益,引入 AI 所带来的社会价值是短期内难以衡量的,正如迈瑞医疗所做的事情一样。
当然,这件事做起来没有那么容易,腾讯也是处在摸索阶段。他们深知,「要搭建一套有用的智能系统,大模型可能只是其中一个模块。」所以他们向着「开箱即用」的方向打磨大模型相关产品,致力于让企业以最小的必要输入来获得最佳的大模型应用实践。与此同时,他们也在从内部产品和外部客户业务中努力找场景,让技术和产品解决真问题。
大模型的未来也是一样,技术仍然在持续迭代,而价值的产生一定是在真实的落地场景中。
#Scalling Law并非一成不变
10人团队融了10亿美元,Ilya最新访谈
公司刚10人,种子轮融资就融了10亿美元。
这种惊掉人下巴的事儿,也只有发生Ilya Sutskever身上,才稍显“正常”。
Ilya,在大模型席卷全球的当下,他的贡献被公认为达到了改变世界的级别:
他是AlexNet三位作者之一,和恩师Hinton一起被挖到谷歌之后,又深度参与了震惊世界的AlphaGo项目。
2015年,他参与了OpenAI的创立,出任首席科学家。ChatGPT再次改变世界,他被认为是背后最关键的人物之一。
从去年11月至今,Ilya的一举一动更是被推到台前,受到全球科技圈的瞩目:
由他发动的OpenAI董事会内讧揭开大模型发展路线之争,而他在今年5月与OpenAI彻底分道扬镳之后,所有人都在等待他的下一步创业动向。
现在,尘埃初定。一向低调的Ilya本人,也在这个时间点上,同外界分享了更多有关他的公司SSI,以及他本人对AGI思考的信息。
在与路透社的交流中,Ilya回答了关键的6个问题。以下,原文奉上:
为什么创立SSI?
我们已经发现了一座与我之前的工作有些不同的“大山”……一旦你登上这座山的顶峰,范式就会改变……我们所知的关于人工智能的一切都将再次改变。
到那时,超级智能安全工作会变得非常关键。
我们的第一个产品将会是安全的超级智能。
在超级智能之前,会发布和人类一样智能的AI吗?
我认为关键在于:它是否安全?它是否是世界上一股向善的力量?我认为,当我们做到这一点时,世界将会发生很大的变化。因此现在就给出“我们将要做什么”的明确计划是相当困难的。
我可以告诉你的是,世界将会变得非常不同。外界对AI领域正在发生的事情的看法将会发生巨大变化,并且很难理解。这将是一场更加激烈的对话。这可能不仅取决于我们的决定。
SSI如何判定何为安全的人工智能?
要回答这个问题,我们需要开展一些重要的研究。特别是如果你和我们一样,认为事情会发生很大变化……很多伟大的想法正在被发现。
很多人都在思考,当AI变得更加强大时,需要对其采取哪些测试?这有点棘手,还有很多研究要做。
我不想说现在已经有了明确的答案。但这是我们要弄清楚的事情之一。
关于尺度假设和AI安全
每个人都在说“尺度假设”,但每个人都忽略了一个问题:我们在scaling什么?
过去十年深度学习的巨大突破,是一个关于尺度假设的特定公式。但它会改变……随着它的改变,系统的能力将会增强,安全问题将变得最为紧迫,这就是我们需要解决的问题。
SSI会开源吗?
目前,所有人工智能公司都没有开源他们的主要工作,我们也是如此。但我觉得,取决于某些因素,会有很多机会去开源超级智能安全工作。也许不是全部,但肯定会有一些。
对其他AI公司安全研究工作的看法
实际上,我对业界有很高的评价。我认为,随着人们继续取得进展,所有公司都会意识到——可能是在不同的时间点——他们所面临的挑战的本质。因此,我们并不是认为其他人都做不到,而是说,我们认为我们可以做出贡献。
10亿美元用来干什么
最后,补充一些Ilya话外的背景信息。
SSI的消息最早在今年6月释出,目标很明确,搞Ilya在OpenAI没干成的事:构建安全超级智能。
目前SSI只有10名员工,融完资后,计划利用这笔资金买算力并聘请顶尖人才——
认同他们的理念,已经做好AI有一天会超越人类智能的心理准备的那种。
联合创始人Daniel Gross还透露,他们并不过分看重资历和经验,反而会花好几个小时审查候选人是否具有“良好的品格”。
算力方面,SSI计划和云厂商及芯片公司开展合作,具体和哪些公司合作、怎么合作尚未明确。
除了Ilya本人之外,SSI的联创还有Daniel Gross和Daniel Levy。
△左:Daniel Gross;右:Daniel Levy
Daniel Gross毕业于哈佛大学计算机系,此前也是Y Combinator的合伙人之一,也曾创办或参与创办了多家公司,包括Citrus Lane、WriteLaTeX(后更名为Overleaf)等。
他被《时代100》杂志列为“人工智能领域最具影响力的人物”之一。
Daniel Levy则毕业于斯坦福计算机系,此前是OpenAI优化团队的负责人。
#SAM2Point
大模型继续发力!首次实现任意3D场景+任意Prompt
文章链接:https://arxiv.org/pdf/2408.16768
在线Demo: https://huggingface.co/spaces/ZiyuG/SAM2Point
Code链接:https://github.com/ZiyuGuo99/SAM2Point

图 1 SAM2POINT的分割范式
重点概述:
1.无需投影到2D的SAM 2分割方案:SAM2POINT 通过将 3D 数据体素化为视频格式,避免了复杂的 2D至3D 的投影,实现了高效的零样本 3D 分割,同时保留了丰富的空间信息。
2.支持任意用户提示(Prompt):该方法支持 3D 点、3D框和Mask三种提示类型,实现了灵活的交互式分割, 增强了 3D 分割的精确度和适应性。
3.泛化任何3D场景:SAM2POINT 在多种 3D 场景中表现出优越的泛化能力,包括单个物体、室内场景、室外场景和原始 LiDAR 数据, 显示了良好的跨领域转移能力。
SAM2POINT,是3D可提示分割领域的初步探索,将 Segment Anything Model 2(SAM 2)适配于零样本和可提示的3D分割。SAM2POINT 将任何 3D 数据解释为一系列多方向视频,并利用 SAM2 进行3D空间分割,无需进一步训练或 2D至3D 投影。SAM2POINT框架支持多种提示类型,包括 3D 点、 3D框和3D Mask,并且可以在多种不同场景中进行泛化,例如 3D 单个物体、室内场景、室外场景和原始激光雷达数据( LiDAR)。在多个3D 数据集上的演示,如 Objaverse、S3DIS、ScanNet、Semantic3D 和 KITTI,突出了 SAM2POINT 的强大泛化能力。据我们所知,这是SAM在3D中最忠实的实现,可能为未来可提示的3D分割研究提供一个起点。
SAM2Point的动机与方法创新
Segment Anything Model(SAM)已经建立了一个卓越且基础的交互式图像分割框架。基于其强大的迁移能力,后续研究将SAM扩展到多样的视觉领域,例如个性化物体、医学影像和时间序列。更近期的Segment Anything Model 2(SAM 2)提出了在视频场景中的印象深刻的分割能力,捕捉复杂的现实世界动态。

表 1:SAM2POINT与以往基于SAM的3D分割方法的比较。SAM2POINT是SAM在3D中最忠实的实现,展示了在3D分割中的卓越实施效率、可提示的灵活性和泛化能力。
尽管如此,如何有效地将SAM适应于3D分割仍然是一个未解决的挑战。表1列举了前期工作的主要问题,这些问题阻碍了充分利用SAM的优势:
2D到3D投影的效率低。 考虑到2D和3D之间的领域差距,大多数现有工作将3D数据表示为其2D对应输入给SAM,并将分割结果反向投影到3D空间,例如使用额外的RGB图像、多视图渲染或神经辐射场。这种模态转换引入了显著的处理复杂性,阻碍了有效的实施。
3D空间信息的退化。 依赖2D投影导致了精细的3D几何形态和语义的丢失,多视图数据常常无法保留空间关系。此外,3D物体的内部结构不能被2D图像充分捕获,显著限制了分割精度。
提示灵活性的丧失。 SAM的一个引人注目的优点是通过各种提示替代品的交互能力。不幸的是,这些功能在当前方法中大多被忽视,因为用户难以使用2D表示来精确指定3D位置。因此,SAM通常用于在整个多视图图像中进行密集分割,从而牺牲了交互性。
有限的领域迁移能力。 现有的2D-3D投影技术通常是为特定的3D场景量身定制的,严重依赖于领域内的模式。这使得它们难以应用于新的环境,例如从物体到场景或从室内到室外环境。另一个研究方向旨在从头开始训练一个可提示的3D网络。虽然绕过了2D投影的需要,但它需要大量的训练和数据资源,可能仍受训练数据分布的限制。
相比之下,SAM2POINT将SAM 2适应于高效、无投影、可提示和零样本的3D分割。 作为这一方向的初步步骤,SAM2POINT的目标不在于突破性能极限,而是展示SAM在多种环境中实现强大且有效的3D分割的潜力。
效果展示
图2-图7展示了 SAM2POINT 在使用不同 3D 提示对不同数据集进行 3D 数据分割的演示,其中3D提示用红色表示,分割结果用绿色表示:

图2 使用SAM2POINT在Objaverse数据集上进行3D物体分割

图3 使用SAM2POINT在S3DIS数据集上进行3D室内场景分割

图4 使用SAM2POINT在ScanNet数据集上进行3D室内场景分割

图5 使用SAM2POINT在Semantic3D数据集上进行3D室外场景分割

图 6使用SAM2POINT在KITTI上进行3D原始激光雷达数据分割
SAM2Point的3D物体的多方向视频:
SAM2Point的3D室内场景多方向视频:
SAM2Point的3D室外场景多方向视频:
SAM2Point的3D原始激光雷达的多方向视频:
SAM2POINT方法详述
SAM2POINT 的详细方法如下图所示。下面介绍了 SAM2POINT 如何高效地处理 3D 数据以适配 SAM 2, 从而避免复杂的投影过程。接下来, 以及详细说明了支持的三种 3D 提示类型及其相关的分割技术。最后, 展示了 SAM2POINT 有效解决的四种具有挑战性的 3D 场景。

图8 SAM2POINT的具体方法
3D 数据作为视频
对于任何物体级或场景级的点云, 用 表示, 每个点为 。本文的目标是将
通过这种方式, 获得了 3D 输入的体素化表示, 记作 , 每个体素为 。为了简化, 值根据距离体素中心最近的点设置。这种格式与形状为
可提示分割
为了实现灵活的交互性, SAM2POINT 支持三种类型的 3D 提示, 这些提示可以单独或联合使用。以下详细说明提示和分割细节:
- 3D 点提示, 记作 。首先将 视为 3D 空间中的针点, 以定义三个正交的 2D 截面。从这些截面开始, 我们沿六个空间方向将 3D 体素分为六个子部分, 即前、后、左、右、上和下。接着, 我们将它们视为六个不同的视频,其中截面作为第一帧,
- 3D 框提示, 记作 ,包括 3D 中心坐标和尺寸。我们采用 的几何中心作为针点,并按照上述方法将 3D 体素表示为六个不同的视频。对于某一方向的视频, 我们将 投影到相应的 2D 截面,作为分割的框点。我们还支持具有旋转角度的 3D 框,例如 ,对于这种情况,采用投影后的
- 3D mask提示,记作,其中 1 或 0 表示mask区域和非mask区域。使用mask提示的质心作为锚点,同样将3D空间分为六个视频。3D mask提示与每个截面的交集被用作 2D mask提示进行分割。这种提示方式也可以作为后期精炼步骤, 以提高先前预测的 3D mask的准确性。
任意3D场景
通过简洁的框架设计,SAM2POINT在不同领域表现出卓越的零样本泛化性能,涵盖从物体到场景,从室内到室外环境。以下详细介绍四种不同的 3D 场景:
- 3D 单个物体, 如 Objaverse, 拥有广泛的类别, 具有不同实例的独特特征, 包括颜色、形状和几何结构。对象的相邻组件可能会重叠、遮挡或与彼此融合, 这要求模型准确识别细微差别以进行部分分割。
- 3D室内场景, 如 S3DIS和 ScanNet, 通常以多个物体在有限空间内(如房间)排列的特点为主。复杂的空间布局、外观相似性以及物体之间不同的方向性,为模型从背景中分割物体带来挑战。
- 3D 室外场景, 如 Semantic3D, 与室内场景主要不同在于物体(建筑、车辆和人)之间的明显大小对比以及点云的更大规模(从一个房间到整条街道)。这些变化使得无论是全局还是细粒度层面的物体分割都变得复杂。
- 原始激光雷达数据(LIDAR), 例如用于自动驾驶的KITTI(Geiger等人,2012),与典型点云不同,其特点是稀疏分布和缺乏RGB信息。稀疏性要求模型推断缺失的语义以理解场景,而缺乏颜色则强迫模型只依靠几何线索来区分物体。在SAM2POINT中,我们直接根据激光雷达的强度设置3D体素的RGB值。
讨论与洞察
基于SAM2POINT的有效性,文章深入探讨了3D领域中两个引人注目但具有挑战性的问题,并分享了作者对未来多模态学习的见解。
如何将2D基础模型适应到3D?
大规模高质量数据的可用性显著促进了语言和视觉-语言领域大型模型的发展。相比之下,3D领域长期以来一直面临数据匮乏的问题,这阻碍了大型3D模型的训练。因此,研究人员转而尝试将预训练的2D模型转移到3D中。
主要挑战在于桥接2D和3D之间的模态差距。如PointCLIP V1及其V2版本和后续方法等开创性方法,将3D数据投影成多视角图像,这遇到了实施效率低和信息丢失的问题。另一条研究线,包括ULIP系列、I2P-MAE及其他,采用了使用2D-3D配对数据的知识蒸馏。虽然这种方法由于广泛的训练通常表现更好,但在非域场景中的3D迁移能力有限。
近期的努力还探索了更复杂且成本更高的解决方案,例如联合多模态空间(例如Point-Bind & Point-LLM),大规模预训练(Uni3D)和虚拟投影技术(Any2Point)。
从SAM2POINT我们观察到,通过体素化将3D数据表示为视频可能提供了一个最佳解决方案,提供了性能和效率之间的平衡折衷。这种方法不仅以简单的转换保留了3D空间中固有的空间几何形状,还呈现了一种2D模型可以直接处理的基于网格的数据格式。尽管如此,仍需要进一步的实验来验证并加强这一观察。
SAM2POINT在3D领域的潜力是什么?
SAM2POINT展示了SAM在3D中最准确和全面的实现,成功继承了其实施效率、可提示的灵活性和泛化能力。虽然之前基于SAM的方法已经实现了3D分割,但它们在可扩展性和迁移到其他3D任务的能力方面往往表现不足。相比之下,受到2D领域SAM的启发,SAM2POINT展现了推进各种3D应用的重大潜力。
对于基本的3D理解,SAM2POINT可以作为一个统一的初始化主干,进一步微调,同时为3D物体、室内场景、室外场景和原始激光雷达提供强大的3D表示。在训练大型3D模型的背景下,SAM2POINT可以作为自动数据标注工具,通过在不同场景中生成大规模分割标签来缓解数据稀缺问题。对于3D和语言视觉学习,SAM2POINT天生提供了一个跨2D、3D和视频领域的联合嵌入空间,由于其零样本能力,这可能进一步增强模型的效果,如Point-Bind。此外,在开发3D大语言模型(LLMs)的过程中,SAM2POINT可以作为一个强大的3D编码器,为LLMs提供3D Tokens,并利用其可提示的特征为LLMs装备可提示的指令遵循能力。
总结
SAM2Point, 利用 Segment Anything 2 (SAM 2) 实现了零样本和可提示的3D分割框架。通过将 3D 数据表示为多方向视频, SAM2POINT 支持多种类型的用户提供的提示 (3D 点、3D框和3D mask), 并在多种 3D 场景(3D 单个物体、室内场景、室外场景和原始稀疏激光雷达)中展现出强大的泛化能力。作为一项初步探索,SAM2POINT为有效和高效地适应SAM 2以理解3D提供了独特的见解。希望SAM2Point能成为可提示3D分割的基础基准,鼓励进一步的研究,以充分利用SAM 2在3D领域的潜力。
#A Survey on Self-play Methods in Reinforcement Learning
清华、北大等发布Self-Play强化学习最新综述
本文作者来自于清华大学电子工程系,北京大学人工智能研究院、第四范式、腾讯和清华-伯克利深圳学院。其中第一作者张瑞泽为清华大学硕士,主要研究方向为博弈算法。通讯作者为清华大学电子工程系汪玉教授、于超博后和第四范式研究员黄世宇博士。
自博弈(self-play)指的是智能体通过与自身副本或历史版本进行博弈而进行演化的方法,近年来在强化学习领域受到广泛重视。这篇综述首先梳理了自博弈的基本背景,包括多智能体强化学习框架和博弈论的基础知识。随后,提出了一个统一的自博弈算法框架,并在此框架下对现有的自博弈算法进行了分类和对比。此外,通过展示自博弈在多种场景下的应用,架起了理论与实践之间的桥梁。文章最后总结了自博弈面临的开放性挑战,并探讨了未来研究方向。
- 论文题目:A Survey on Self-play Methods in Reinforcement Learning
- 研究机构:清华大学电子工程系、北京大学人工智能研究院、第四范式、腾讯、清华-伯克利深圳学院
- 论文链接:https://arxiv.org/abs/2408.01072
引言
强化学习(Reinforcement Learning,RL)是机器学习中的一个重要范式,旨在通过与环境的交互不断优化策略。基本问题建模是基于马尔可夫决策过程(Markov decision process,MDP),智能体通过观察状态、根据策略执行动作、接收相应的奖励并转换到下一个状态。最终目标是找到能最大化期望累计奖励的最优策略。
自博弈(self-play)通过与自身副本或过去版本进行交互,从而实现更加稳定的策略学习过程。自博弈在围棋、国际象棋、扑克以及游戏等领域都取得了一系列的成功应用。在这些场景中,通过自博弈训练得到了超越人类专家的策略。尽管自博弈应用广泛,但它也伴随着一些局限性,例如可能收敛到次优策略以及显著的计算资源需求等。
本综述组织架构如下:首先,背景部分介绍了强化学习框架和基础的博弈论概念。其次,在算法部分提出了一个统一的框架,并根据该框架将现有的自博弈算法分为四类,进行系统的比较和分析。在之后的应用部分中,展示自博弈具体如何应用到具体的复杂博弈场景。最后,进一步讨论了自博弈中的开放问题和未来的研究方向,并进行总结。
背景
该部分分别介绍了强化学习框架以及博弈论基本知识。强化学习框架我们考虑最一般的形式:部分可观察的马尔可夫博弈(partially observable Markov game, POMGs),即多智能体场景,且其中每个智能体无法完全获取环境的全部状态。
博弈论基础知识介绍了博弈具体类型,包括(非)完美信息博弈和(非)完全信息博弈、标准型博弈和扩展型博弈、传递性博弈和非传递性博弈、阶段博弈和重复博弈、团队博弈等。同样也介绍了博弈论框架重要概念包括最佳回应(Best responce, BR)和纳什均衡 (Nash equilibrium, NE)等。
复杂的博弈场景分析通常采用更高层次的抽象,即元博弈(meta-game)。元博弈关注的不再是单独的动作,而是更高层的复杂策略。在这种高层次抽象下,复杂博弈场景可以看作是特殊的标准型博弈,策略集合由复杂策略组成。元策略(meta-strategies)是对策略集合中的复杂策略进行概率分配的混合策略。
在该部分最后,我们介绍了多种常用的自博弈评估指标,包括 Nash convergence(NASHCONV)、Elo、Glicko、Whole-History Rating(WHR) 和 TrueSkill。
算法
我们定义了一个统一的自博弈框架,并将自博弈算法分为四大类:传统自博弈算法、PSRO 系列算法、基于持续训练的系列算法和后悔最小化系列算法。
算法框架

首先,该框架(算法1)的输入定义如下:
● : 在策略集合 中,每个策略 都取决于一个策略条件函数 。
● : 策略集合的交互矩阵。 描述了如何为策略 采样对手。例如, 可以用每个对手策略采样概率表示(此时 如下图所示)。

● : 元策略求解器(Meta Strategy Solver,MSS)。输入是表现矩阵 ,并生成一个新的交互矩阵 作为输出。 表示策略 的表现水平。
该框架(算法1)的核心步骤说明:
● 算法1伪代码第1行: 表示整个策略集合的总训练轮数,也即策略池中每个策略的更新次数。
● 算法1伪代码第3行:各个策略初始化可以选择随机初始化、预训练模型初始化或者是继承之前训练完成的策略进行初始化。
● 算法1伪代码第4行:可以选用不同的 ORACLE 算法得到训练策略,最直接的方式是计算 BR 。但是由于对于复杂任务来说,直接计算 BR 难度高,因此通常选择训练近似BR来训练策略,可以采用强化学习(算法2),进化算法(算法3),后悔最小化(算法4)等方法。



类型一:传统自博弈算法
传统自博弈算法从单一策略开始,逐步扩展策略池,包括Vanilla self-play(训练时每次对手都选择最新生成的策略),Fictitious self-play(训练时每次对手都在现有训练完的策略中均匀采样),δ-uniform self-play(训练时每次对手都在现有训练完的最近的百分之δ策略中均匀采样),Prioritized Fictitious Self-play(根据优先级函数计算当前训练完的策略的优先级,训练时每次对手都根据这个优先级进行采样),Independent RL(训练时双方策略都会改变,对手策略不再固定)。
类型二:PSRO 系列算法
类似于传统自博弈算法,Policy-Space Response Oracle(PSRO)系列算法同样从单一策略开始,通过计算 ORACLE 逐步扩展策略池,这些新加入的策略是对当前元策略的近似 BR 。PSRO 系列与传统自博弈算法的主要区别在于,PSRO 系列采用了更复杂的MSS,旨在处理更复杂的任务。例如,α-PSRO 使用了基于 α-rank 的 MSS 来应对多玩家的复杂博弈。
类型三:持续训练系列算法
PSRO 系列算法中存在的两个主要挑战:首先,由于训练成本大,通常在每次迭代中截断近似BR计算,会将训练不充分的策略添加到策略池;其次,在每次迭代中会重复学习基本技能,导致效率较低。为了解决这些挑战,基于持续训练系列的算法提倡反复训练所有策略。与前面提到的两类最大区别是,持续训练系列算法同时训练整个策略池策略。这类算法采用多个训练周期,并在每个训练周期内依次训练策略池所有策略,而不再是通过逐步扩展策略池进行训练。
类型四:后悔最小化系列算法
另一类自博弈算法是基于后悔最小化的算法。基于后悔最小化的算法与其他类别的主要区别在于,它们优先考虑累积的长期收益,而不仅仅关注单次回合的表现。这种方法可以训练得到更具攻击性和适应性的策略,避免随着时间的推移被对手利用。这些算法要求玩家在多轮中推测并适应对手的策略。这种情况通常在重复博弈中观察到,而不是单回合游戏中。例如,在德州扑克或狼人游戏中,玩家必须使用欺骗、隐瞒和虚张声势的策略,以争取整体胜利,而不仅仅是赢得一局。
各类型算法比较与总结图

应用
在本节中,我们通过将三类经典场景来介绍自博弈的经典应用:棋类游戏,通常涉及完全信息;牌类游戏(包括麻将),通常涉及不完全信息;以及电子游戏,具有实时动作而非简单回合制游戏。
场景一:棋类游戏
棋类游戏领域,绝大多数是完全信息游戏,曾因引入两项关键技术而发生革命性变化:位置评估和蒙特卡罗树搜索。这两项技术在象棋、西洋跳棋、黑白棋、西洋双陆棋等棋盘游戏方面展现了超越人类的效果。相比之下,当这些技术应用于围棋时,由于围棋棋盘布局种类远超于上述提到的棋类游戏,因此仅能达到业余水平的表现。直到 DeepMind 推出了 AlphaGo 系列而发生了革命性的变化,AlphaGo 系列算法利用自博弈的强大功能显著提升了性能,为围棋领域设立了新的基准。
除了围棋,还有一种难度较高的棋类游戏是“军棋”(Stratego)。与大多数完全信息的棋类游戏不同,“军棋”是一个两人参与的不完全信息棋盘游戏。游戏分为两个阶段:部署阶段,玩家秘密安排他们的单位,为战略深度奠定基础;以及游戏阶段,目标是推断对手的布局并夺取他们的旗帜。DeepNash 采用基于进化的自博弈算法 R-NaD 达到了世界第三的人类水平。
场景二:牌类游戏
德州扑克(Texas Hold’em)是一种欧美流行的扑克游戏,适合 2 到 10 名玩家,当玩家数量增加,游戏变得更加复杂。此外,有三种下注形式:无限注、固定注和底池限注。每种形式在具有不同的游戏复杂度。在牌类游戏中,游戏抽象对于简化游戏复杂程度至关重要,可以将游戏的庞大状态空间减少到更容易处理的数量。Cepheus 采用后悔最小化系列算法 CFR+ 解决了最容易的双人有限注德州扑克。对于更复杂的双人无限注德州扑克,DeepStack 和 Libratus 采用子博弈重新计算的方式来实时做出决策,击败职业德州扑克选手。Pluribus 在 Libratus 基础上更进一步解决了六人无限注德州扑克。
斗地主需要同时考虑农民之间的合作和农民地主之间的竞争。斗地主同样是不完全信息博弈,这为游戏增加了不确定性和策略深度。DeltaDou 是基于 AlphaZero 开发的首个实现专家级斗地主表现的算法。之后的 DouZero 通过选择采样方法而非树搜索方法来降低训练成本,采用自博弈获取训练数据。
麻将同样基于不完全信息做出决策,此外,麻将的牌数更多,获胜牌型也更为复杂,对 AI 更具挑战性。Suphx 通过监督学习和自我博弈强化学习成为首个达到与人类专家水平的算法。NAGA 和腾讯设计的 LuckyJ 同样也在在线平台上达到了人类专家水平。
场景三:电子游戏
与传统棋类游戏和牌类游戏不同,电子游戏通常具有实时操作、更长的动作序列以及更广泛的动作空间和观察空间。在星际争霸(StarCraft)中,玩家需要收集资源、建设基地并组建军队,通过精心的计划和战术执行,使对方玩家失去所有建筑物,来取得胜利。AlphaStar 使用监督学习、端到端的强化学习和分层自博弈训练策略,在星际争霸II的 1v1 模式比赛中击败了职业玩家。
MOBA游戏要求两支玩家队伍各自操控他们独特的英雄,互相竞争以摧毁对方的基地。每个英雄都有独特的技能,并在队伍中扮演特定的角色,也无法观测全部地图。OpenAI Five 在简化版本的 Dota 2 中击败了世界冠军队,其训练过程使用混合类型自博弈,有 80% 的概率进行 Naive self-play,20% 的概率使用 Prioritized self-play。腾讯同样采用自博弈训练在王者荣耀游戏 1v1 和 5v5 模式中都击败了职业选手。
Google Research Football(GRF)是一个开源的足球模拟器,输入是高层次的动作,需要考虑队友之间的合作和两个队伍之间的竞争,且每队有 11 人。TiKick 通过 WeKick 的自博弈数据进行模仿学习,再利用分布式离线强化学习开发了一个多智能体AI。TiZero将课程学习与自博弈结合,无需专家数据,达到了比TiKick更高的TrueSkill评分。
各场景类型比较与总结图

讨论
自博弈方法因其独特的迭代学习过程和适应复杂环境的能力而表现出卓越的性能,然而,仍有不少方向值得进一步研究。
虽然许多算法在博弈论理论基础上提出,但在将这些算法应用于复杂的现实场景时,往往存在理论与现实应用的差距。例如,尽管 AlphaGo、AlphaStar 和 OpenAI Five 在实证上取得了成功,但它们的有效性缺乏正式的博弈论证明。
随着团队数量和团队内玩家数量的增加,自博弈方法的可扩展性面临显著挑战。例如,在 OpenAI Five 中,英雄池的大小被限制在仅17个英雄。根本上是由于自博弈方法在计算和存储两个方面训练效率有限:由于自博弈的迭代特性,智能体反复与自身或过去的版本对战,因而计算效率较低;自博弈需要维护一个策略池,因而对存储资源需求较高。
凭借卓越的能力和广泛的泛化性,大型语言模型(LLM)被认为是实现人类水平智能的潜在基础。为了减少对人工标注数据的依赖,自博弈方法被利用到微调LLM来增强LLM的推理性能。自博弈方法还在构建具有强大战略能力的基于 LLM 的代理方面做出了贡献,在”外交“游戏中达到了人类水平的表现。尽管近期取得了一些进展,将自博弈应用于 LLM 仍处于探索阶段。
自我博弈面另一个挑战是其在现实具身场景中无法直接应用。其迭代特性需要大量的试验和错误,很难直接在真实环境中完成。因此,通常只能在仿真器中进行自博弈训练,再将自博弈有效部署到现实具身场景中,关键问题仍在于克服 Sim2Real 差距。
#苹果首款AI手机发布
A18芯片,新增拍照按钮,AirPods变助听器
北京时间 9 月 10 日凌晨 1 点,苹果开始发光了。随着苹果园区中蒂姆・库克的身影在六色拱门前显现,主题为「It’s Glowtime」的苹果发布会序幕拉开。
没有任何意外,这次发布会上,库克和一众苹果同事带来了最新一代 iPhone 系列手机,包括 iPhone 16、iPhone 16 Plus、iPhone 16 Pro 和 iPhone 16 Pro Max。新一代 iPhone 多了两个按钮(相机控制按钮和动作按钮),颜色也变得更加丰富。
另外,苹果还发布了新一代 AirPods 和 Apple Watch。
AI 是这场发布会的重要看点。今天发布的几乎每款产品都配置了一定的智能能力,围绕 Apple Intelligence,涵盖语言、视觉、健康、生活等诸多方面。
所有硬件产品将于 9 月 13 日 20:00 开启预售,9 月 20 日发售。Apple Intelligence 则将在下个月开始向用户推送。
iPhone 16 标准版
祖传 60Hz,相机控制成亮点
在之前爆料中,iPhone 16 标准版的摄像头布局要有所变化。果不其然,此次上新的 iPhone 16 采用了双摄像头垂直排列,除此之外,总体设计与上代没有变化,正面顶部依然是「灵动岛」开孔,用于防止前置摄像头和 Face ID 传感器。屏幕刷新率仍为祖传的 60Hz,并据称配备了 8GB 运行内存。
iPhone 16 标准版提供了 5 种配色,分别为黑、白、粉、群青、和深青。屏幕亮度支持范围为 1-2000 尼特。

标准版有两个尺寸可供选择,包括了 6.1 英寸的 iPhone 16 和 6.7 英寸的 iPhone 16 Plus。储存容量同样有 128GB、256GB 和 512GB 可选;支持 IP68 防溅、抗水、防尘;首次支持 MagSafe 快速充电,通过 30W 充电器,充电功率可达 25W,同时支持最高 15W 无线充电。

在芯片方面,此次标准版搭载了全新的 A18 处理器,采用第二代 3nm 工艺,CPU 为 6 核心,包括 2 个性能核心和 4 个效率核心。苹果表示,CPU 性能要比 iPhone 15 的 CPU 快 30%,比 iPhone 12 的 A14 快 60%。
同时,iPhone 16 搭载了 16 核神经网络引擎,并针对大型生成模型进行优化,机器学习速度最高提升 2 倍,内存带宽增加 17%。

GPU 方面,A18 搭载的 5 核 GPU 性能比 iPhone 15 的 A16 快了 40%,同时能耗降低了 35%。

在相机方面,标准版采用双摄系统,主摄 4800 万像素,支持 26 毫米焦距、ƒ/1.6 光圈、传感器位移式光学图像防抖功能、100% Focus Pixels、以及超高分辨率照片(2400 万像素和 4800 万像素)。主摄同时支持 1200 万像素 2 倍长焦功能。

另外一颗是 1200 万像素超广角摄像头,支持 13 毫米焦距、ƒ/2.2 光圈和 120° 视角、100% Focus Pixels。

在视频方面,标准版支持了最高 60 fps 的 4K 杜比视界视频拍摄和 1080p 杜比视界视频拍摄、最高 4K HDR、30 fps 的电影效果模式、最高 2.8K、60 fps 的运动模式、以及 1080p、30 fps 的空间视频拍摄等功能。
此次,标准版在相机控制方面有了较大创新, 在设备侧面配备了一个新的电容式按钮(Camera Control),装有蓝宝石玻璃。用户可以滑动切换功能和参数,并可以感知按压力度,从而更方便地拍摄照片和视频。
现在,用户只需要滑动手指,就能调整曝光、景深等相机功能,还能切换各个镜头或使用数码变焦取景构图。

苹果新推出的新视觉人工智能功能也可以通过相机控制快速访问。标准版还可以让用户使用空间拍摄功能,以全新方式拍出鲜活的照片和视频。搭配使用 Apple Vision Pro,用户可以感受 3D 世界。
此外,标准版也配备了去年 Pro 机型上首次亮相的 Action 按钮,取代了以往的静音开关,并且可自定义。用户可以将其设置为激活手电筒或语音备忘录录音,还可以触发快捷方式等功能。

详细规格参考下图。

至于价格,iPhone 16 售价 799 美元起,iPhone 16 Plus 售价 899 美元起。国行版价格也已经出炉,iPhone 16 最低 5999 元(128GB),iPhone 16 Plus 128GB 价格售价为 6999 元,与上一代 15 标准版定价相同。
iPhone 16 Pro 版
CPU 最强、尺寸最大
iPhone 16 标准版的一些功能让用户眼前一亮,而 Pro 版更像是「巨无霸」。
尺寸方面,iPhone 16 Pro 为 6.3 英寸,iPhone 16 Pro Max 为 6.9 英寸,后者成为苹果有史以来最大的显示屏。最大屏幕的同时边框也实现了迄今最窄,同样配备了灵动岛功能、ProMotion 自适应刷新率技术,屏幕刷新率最高 120 Hz、原彩显示、2000 尼特峰值亮度。
两个版本均提供 4 种配色,分别是黑色钛金属、白色钛金属、原色钛金属、沙漠色钛金属。储存容量方面,iPhone 16 Pro 提供 128GB、256GB、512GB、1TB,iPhone 16 Pro Max 则少了 128GB 版本。同时支持 8G 运行内存,IP68 防溅、抗水、防尘,iPhone 16 Pro Max 达成有史以来续航最强。

芯片方面,Pro 版搭载了 A18 Pro 芯片,是对上一代 A17 Pro 的升级。该芯片同样采用了第二代 3nm 工艺,拥有 16 核神经引擎,每秒可以处理 35 万亿运算,速度更快且能效更高,内存带宽提升了 17%。

CPU 方面,A18 Pro 搭载了 6 核 CPU,包括 2 个性能核心和 4 个效率核心,速度比 A17 Pro 提升了 15%,同时功耗降低了 20%。同时比 A18 缓存更大,还支持下一代机器学习(ML)加速器。

苹果称 A18 Pro 为「当今智能手机中最快的 CPU」。
GPU 方面,A18 Pro 采用了桌面级架构,搭载了 6 核 GPU,性能比 A17 Pro 提升了 20%,支持网格着色功能,光线追踪速度是 A17 Pro 的两倍。

影像方面,Pro 版采用了三摄分布,并进行了全面升级。第一颗是 4800 万像素融合式主摄,支持 24 毫米焦距、ƒ/1.78 光圈、第二代传感器位移式光学图像防抖功能、100% Focus Pixels、超高分辨率照片(2400 万像素和 4800 万像素)。同时支持 1200 万像素 2 倍长焦功能。
第二颗同样是 4800 万像素超广角摄像头,支持 13 毫米焦距、ƒ/2.2 光圈和 120° 视角、Hybrid Focus Pixels 以及超高分辨率照片(4800 万像素),同时支持自动对焦。
第三颗为 1200 万像素 5 倍长焦摄像头,支持 120 毫米焦距、ƒ/2.8 光圈和 20° 视角、100% Focus Pixels、七镜式镜头、3D 传感器位移式光学图像防抖和自动对焦等。
与标准版一样,Pro 版支持相机控制功能,用户可以快速打开相机 App,滑动手指切换镜头,体验长焦等功能。

视频方面同样有了很大更新,支持 120 fps(融合式摄像头)的 4K 杜比视界视频拍摄、最高 120 fps(融合式摄像头)的 1080p 杜比视界视频拍摄、30 fps 720p 杜比视界视频拍摄、最高 4K HDR、30 fps 电影效果模式、以及 1080p 30 fps 的空间视频拍摄。此外支持用户直接外接硬盘录制 4K 120 fps 的 ProRes 视频。

更详细规格参见下图。

价格方面,iPhone 16 Pro 国行起售价 7999 元(128GB),iPhone 16 Pro Max 起售价 9999 元(256GB),最高 13999 元(1TB)。
Apple Intelligence
围绕个人语境的全产品线智能
在今年 6 月的苹果全球开发者大会 WWDC 上,苹果震撼发布了其全新的个性化智能系统 ——Apple intelligence,全面接入了生成式 AI 能力。
不过,在刚刚的发布会上,Apple Intelligence 功能并未明显超出人们的预期,其核心主要围绕三个方面:语言、图像和动作。但其亮点在于融合用户的 Personal Context(个人语境)并与苹果新一代产品全面整合。
苹果公司软件负责人 Craig Federighi 说:「Apple Intelligence 使用了我们芯片的强大能力,可在你口袋中的 iPhone 上运行多个生成模型,并且它们能动态适应你的当前活动。」
语言方面,iPhone 配置了智能化的文本工具,可帮助用户自动处理输入的文本。纠错是最基本的,该工具还能让文本内容变得更加专业化、更友善或更简洁。另外,其还非常擅长处理 emoji 表情,如有需要,用户甚至可以输入自然语言来生成自己想要的 emoji 并将其发送给朋友。
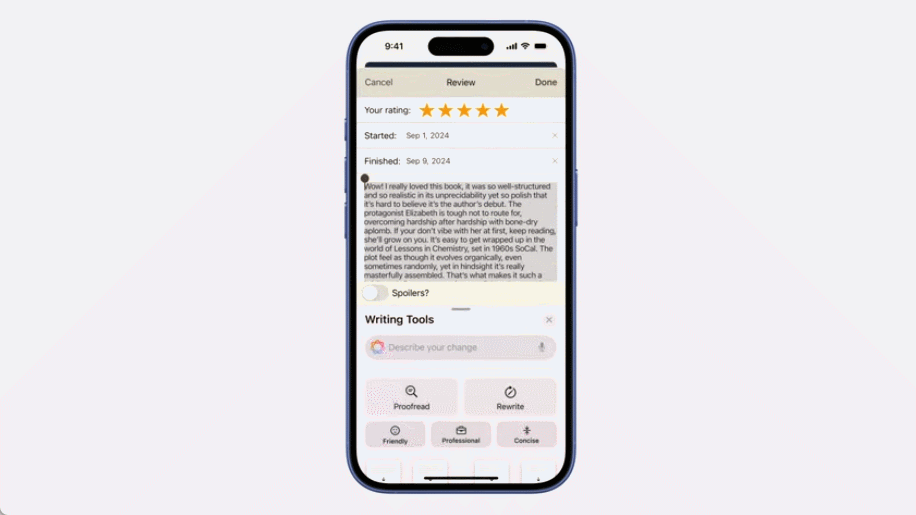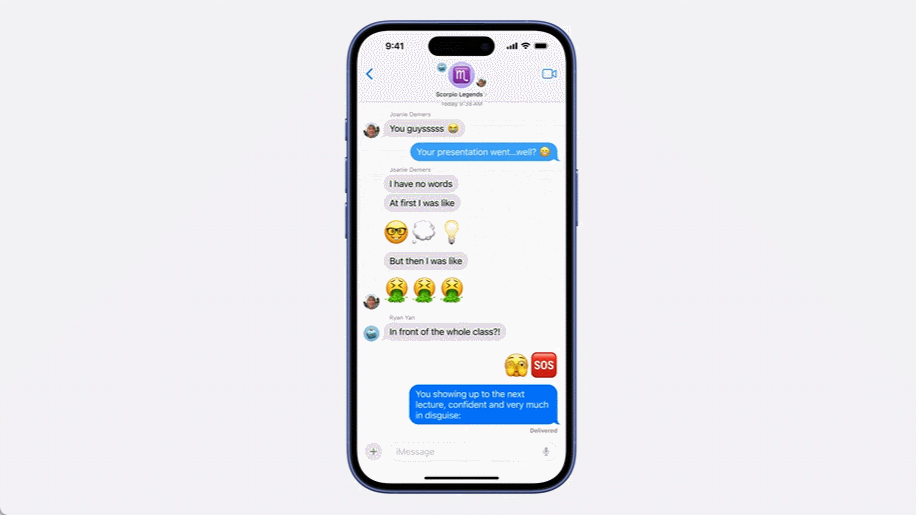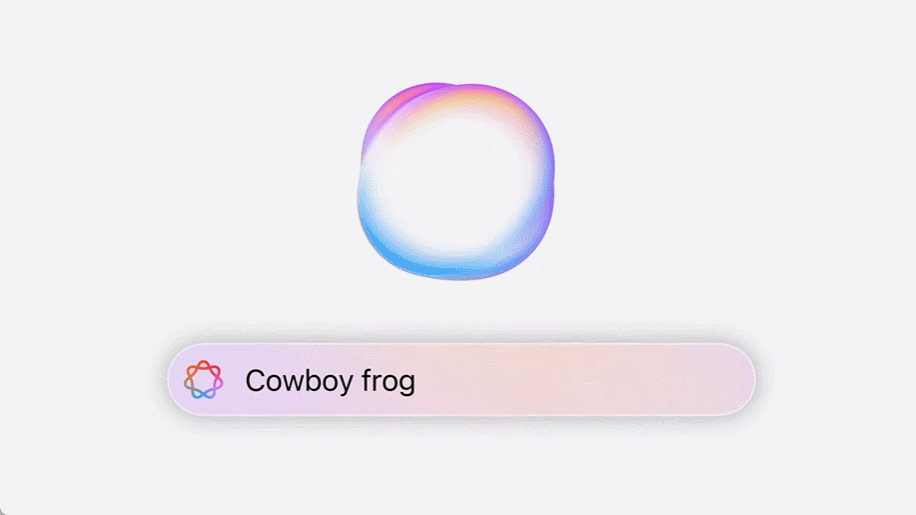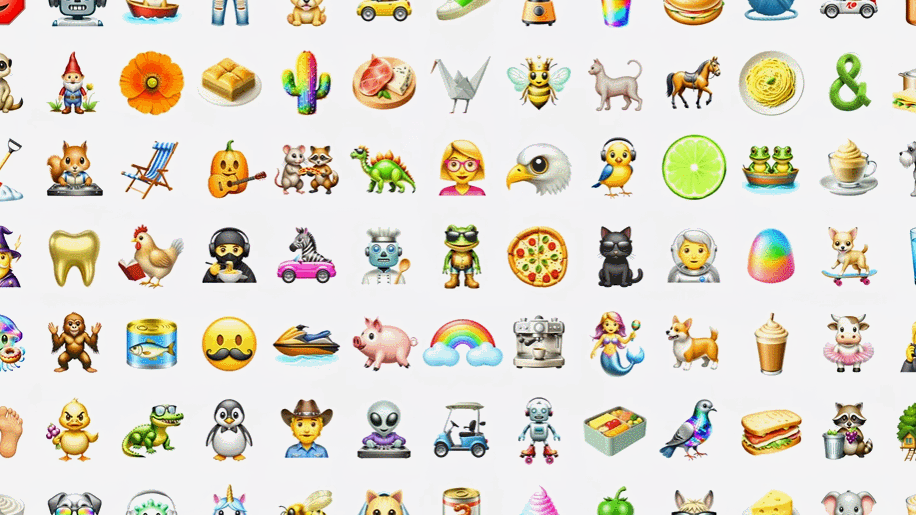
视觉方面,苹果将视觉智能全面赋予了新一代 iPhone 系列手机,其上新增的相机控制键成为了视觉智能的重要入口。
用户只需按下相机控制键,就能让 AI 分析照片中的内容,然后 AI 能进一步检索相关信息、执行翻译、添加日程安排、查询 ChatGPT、定位产品页面…… 或者查询路上遇到的狗狗的品种。

此外,苹果照片应用也将深度整合智能能力,用户可以使用自然语言查询定位自己的照片 / 视频、为照片添加最合适的滤镜特效以及自动制作动态相册。此外,用户也可以在消息应用中直接使用自然语言查询自己的相册并将其发送出去。
iPhone 还能拍摄用于 Apple Vision Pro 等虚拟 / 增强现实设备的空间照片。

语言和图像再加上用户设备中各种各样的个人信息(比如从健康应用读取的个人健康数据、日程安排、笔记等),构成了用户的个人语境。而个人语境自然就是苹果针对用户实现个性化智能的基础。
作为苹果语音助手的 Siri 自然而然便是 Apple Intelligence 的一大主要入口。现已支持文本和语音输入的 Siri 还具备了屏幕感知能力,也就是说其能分析用户当前屏幕上显示的内容,从而进一步提升其对用户个人语境的理解。
基于构成用户个人语境的信息,Apple Intelligence 可以根据用户需求将其变成 Action(动作)。苹果新推出的设备能为用户执行成百上千种不同动作。
在 iPhone 上,新增的动作按钮可让用户自己配置自己想要的动作,从而实现不同的功能,比如打开日历或其它应用、开启手电筒、锁定汽车等快捷功能或一键记录语音速记、执行翻译、识别音乐等智能功能。
在 AirPods 上,苹果打造了一个强大的个性化空间音频系统。与 Siri 对话以及通过点头和摇头来发出指令是最基本的功能,AirPods 还支持智能噪声消除和自适应音频能力。
比如 AirPods 可在用户与其他人对话时降低降噪效果甚至增强对话的声音,这一能力使其不仅仅作为一副耳机,更是能充当助听器。事实上,AirPods 也已加入苹果健康大家庭。据介绍,世卫组织调查发现全球有 15 亿人都存在听力受损问题,而这些问题又可能造成进一步的困难,比如认知下降、跌倒和社交隔离。为此,AirPods Pro 2 具备了三大基于智能技术的新功能:通过智能降噪来预防听力下降、经过临床验证的听力测试、临床级的听力辅助功能(Hearing Aid)。

而在新一代 Apple Watch 上,AI 也被用于根据墙纸内容自动调整时间等内容的显示方式,同时还被用于监测和预防睡眠呼吸暂停(sleep apnea)等疾病。
此外,苹果还表示如果 iPhone 的智能不够用,还能使用的他们的私有云计算(Private Cloud Compute)。Federighi 说:「对于计算更密集的任务,Apple Intelligence 可通过私有云计算解锁更多智能。私有云计算与你的 iPhone 一样隐私和安全,同时还能让你访问比你口袋中的设备所能承载的远远更大的生成模型。」
当然,不只是今天发布的 iPhone,大部分较新的苹果设备都支持 Apple Intelligence。

Apple Intelligence 将以免费软件更新的形式提供给 iPhone 用户。具体来说,下个月将向用户推送 beta 版,其中包含部分功能,更多功能将在未来几个月陆续推出。语言方面,Apple Intelligence 一开始仅支持美国英语,之后会在 12 月份支持加拿大、英国、澳大利亚等更多本地化英语。至于我们更关心的汉语支持,得等到明年了。
Apple Watch
更大、更薄,能检测睡眠呼吸暂停
2024 正值 Apple Watch 发布十周年。2014 年 9 月 9 日,苹果发布了第一代 Apple Watch,包含了运动追踪、健康监测和无线通信等功能,集成 watchOS 并与其他苹果设备联动。
此后,Apple Watch 成为了全球最畅销的智能穿戴设备之一。2024 年 4 月,市场调研机构 Canalys 的数据显示,2023 年全球可穿戴腕带设备出货量 1.85 亿台,苹果以 19%时长份额稳居第一。
今天发布的 Apple Watch Series 10 拥有迄今为止的最大、最先进的显示屏,而且比以往任何型号都薄。此外,它还支持睡眠呼吸暂停通知以及与涉水运动相关的水深和温度感应,充电也比以往更快。



Apple Watch Series 10 有铝金属和钛金属两种材质,拥有一系列令人惊艳的颜色和外观。铝金属有亮黑色、玫瑰金和银色可选。其中,亮黑色是一种全新的抛光铝金属外观,具有独特的反光效果和时尚感。而新的钛金属表壳有原色、金色和石板色可选。

新的金属后盖集成了一个更大、更高效的充电线圈,使 Series 10 成为有史以来充电最快的苹果手表。15 分钟的充电可提供 8 小时的正常日常使用,8 分钟的充电可提供长达 8 小时的睡眠跟踪。用户可以在大约 30 分钟内将电量充到 80%。
Apple Watch Series 10 搭载了苹果全新 S10 芯片,拥有四核神经网络单元,其上可以运行 Transformer 模型来增强智能性,包括双击手势、Siri、听写和自动运动检测等。此外,它还支持车祸检测和摔倒检测以及通话降噪等功能。

Apple Watch 提供了一项有助于识别睡眠呼吸暂停迹象的功能。众所周知,睡眠呼吸暂停会对健康产生重要后果,包括高血压、糖尿病和心脏问题的风险增加。为了检测睡眠呼吸暂停,Apple Watch 使用加速计来监测手腕上与正常呼吸模式中断有关的细微动作,并通过 Apple Watch 的新指标「呼吸紊乱」进行跟踪。

新的睡眠呼吸暂停算法会分析呼吸紊乱数据。算法是利用先进的机器学习和大量临床级睡眠呼吸暂停测试数据集开发的。
新的水温传感器能提供游泳这项体能训练的更多信息。加上新的水深传感器,Series 10 非常适合游泳和浮潜时佩戴。

下图是 Apple Watch Series 10 亮点的全部概览:

国行版售价如下:

备受期待的 Apple Watch Ultra 3 缺席了这次发布会。Ultra 2 新增全新黑色钛金属表壳。它不仅满载日常所需的各种连接、健康和安全功能,更配有运动手表中精准度超高的 GPS。

所有核心指标如下:

售价 6499 元起。

AirPods
既是降噪耳机,也是助听器
在耳机这个品类,苹果发布了 AirPods 4 普通版和主动降噪版;AirPods Max 新增了一些配色,并提供 USB-C 充电功能;AirPods Pro 2 将推出全球首款端到端听力健康体验,提供主动听力保护、经过科学验证的听力测试和临床级助听器功能。

AirPods 4 的一大亮点是舒适度。为了适合不同耳型,苹果构建了一个庞大的数据集,该数据集使用先进的建模工具来精确绘制和分析数千个耳朵形状以及总共超过 5000 万个单独的数据点,这使得 AirPods 4 成为有史以来最舒适的 AirPods。

AirPods 4 首次将主动降噪(ANC)技术引入开放式耳机设计,并推出了一个新型号。这款具有 ANC 功能的 AirPods 4 能够有效减少飞机发动机、城市交通等环境噪音,为用户提供更清晰的听觉体验。它通过硬件和软件的协同工作,实现了最自然的聆听体验。此外,AirPods 4 还引入了通透模式等智能功能,允许外界声音进入,让用户在需要时了解自己的环境。它还具备自适应音频功能,能够根据用户所处的环境条件动态地混合通透模式和 ANC,以及对话意识功能,当用户开始与附近的人交谈时,它会自动降低媒体音量,确保对话清晰。
AirPods 4 配置 H2 芯片。有了这块芯片,AirPods 4 就能带来只有苹果芯片才能提供的智能音频体验,例如语音隔离功能,无论环境条件如何,都能实现更清晰的通话质量;Siri 交互功能,用户只需点头同意或轻轻摇头拒绝,就能对 Siri 通知做出回应。为了获得更多控制功能,AirPods 4 还在耳机柄上配备了全新的力传感器,只需快速按下即可播放或暂停媒体,静音或结束通话。由于采用了 H2 芯片,AirPods 4 还非常适合游戏,在与队友和其他玩家聊天时可提供低无线音频延迟和出色的语音质量,包括支持 16 位 48kHz 音频。

为了更加方便,充电盒现在提供 USB-C 充电功能,并且体积比前代产品小 10% 以上,同时仍可提供长达 30 小时的电池续航时间。

AirPods 4 完整亮点如下:

起售价如下:

苹果还发布了升级版的 AirPods Max,支持 USB-C 充电,并增加了橙色、紫色和星光三种新颜色。

这款耳机在国内的售价为 3999 元。

AirPods Pro 2 新增了听力保护功能,分为预防、检测和辅助三种情况。
听力保护功能将默认启用。该功能在机器学习的帮助下降噪,可以在保留细节的情况下屏蔽噪音,以防止损坏听力。该功能可与耳塞已提供的被动噪音隔离功能共同发挥作用。
为了帮助用户检查听力,苹果很快将在健康应用程序中提供经过临床验证的听力测试。使用交互式纯音听力测试,耳机将能够识别用户是否有听力损失,并提供详细的摘要,突出显示每年的听力损失程度、分类和建议。用户将能够轻松地与医生分享这些结果并采取适当的措施。
对于那些已经患有听力损失的人,AirPods Pro 2 将利用听力测试收集的数据来生成自定义声音配置文件并增强聆听体验。它将充当轻度至中度听力损失人士的临床级助听器,使他们能够更好地听到他人或周围环境的声音。用户还可以使用医疗专业人员创建的听力图来设置助听器功能。
这款耳机的完整亮点如下:

总结
虽然发布会后苹果 CEO 蒂姆・库克发推表示新一代 iPhone 是专为 Apple Intelligence 打造的,这标志着 iPhone 已经进入了一个新时代,但整体而言,苹果此次发布的硬件和功能都未能超出人们的预期。发布会的股价表现也佐证了这一点:几乎没有变化。

发布会后,不少网友调侃说新一代 iPhone 看起来和上一代差不多。
但也有网友表示虽然楼上说得对,但还是要买:
你是否打算入手一台为 AI 而生的 iPhone 呢?
顺带一提,今天下午,苹果在中国的主要竞争对手华为将举办华为见非凡品牌盛典及鸿蒙智行新品发布会,届时将发布 HUAWEI Mate XT 非凡大师。不知道这场发布会又能否给我们带来一些惊喜呢?
#Training-Free Open-Ended Object Detection and Segmentation via Attention as Prompts
无需训练,一个框架搞定开放式目标检测、实例分割
本文介绍了来自北京大学王选计算机研究所的王勇涛团队的最新研究成果 VL-SAM。针对开放场景,该篇工作提出了一个基于注意力图提示的免训练开放式目标检测和分割框架 VL-SAM,在无需训练的情况下,取得了良好的开放式 (Open-ended) 目标检测和实例分割结果,论文已被 NeurIPS 2024 录用。
- 论文标题:Training-Free Open-Ended Object Detection and Segmentation via Attention as Prompts
- 论文链接:https://arxiv.org/abs/2410.05963
论文概述
本文提出了一个无需训练的开放式目标检测和分割框架,结合了现有的泛化物体识别模型(如视觉语言大模型 VLM)与泛化物体定位模型(如分割基础模型 SAM),并使用注意力图作为提示进行两者的连接。在长尾数据集 LVIS 上,该框架超过了之前需要训练的开放式方法,同时能够提供额外的实例分割结果。在自动驾驶 corner case 数据集 CODA 上,VL-SAM 也表现出了不错的结果,证明了其在真实应用场景下的能力。此外,VL-SAM 展现了强大的模型泛化能力,能够结合当前各种 VLM 和 SAM 模型。
研究背景
深度学习在感知任务方面取得了显著成功,其中,自动驾驶是一个典型的成功案例。现有的基于深度学习的感知模型依赖于广泛的标记训练数据来学习识别和定位对象。然而,训练数据不能完全覆盖真实世界场景中所有类型的物体。当面对分布外的物体时,现有的感知模型可能无法进行识别和定位,从而可能会发生严重的安全问题。
为了解决这个问题,研究者们提出了许多开放世界感知方法。这些方法大致可以分为两类:开集感知(open-set)和开放式感知(open-ended)。开集感知方法通常使用预训练的 CLIP 模型来计算图像区域和类别名称之间的相似性。因此,在推理过程中,这类方法需要预定义的对象类别名称作为 CLIP 文本编码器的输入。然而,在许多现实世界的应用场景中,并不会提供确切的对象类别名称。例如,在自动驾驶场景中,自动驾驶车辆可能会遇到各种意想不到的物体,包括起火或侧翻的事故车和各种各样的建筑车辆。相比之下,开放式感知方法更具通用性和实用性,因为这些可以同时预测对象类别和位置,而不需要给定确切的对象类别名称。
与此同时,在最近的研究中,大型视觉语言模型(VLM)显示出强大的物体识别泛化能力,例如,它可以在自动驾驶场景中的长尾数据上(corner case)识别非常见的物体,并给出准确的描述。然而,VLM 的定位能力相比于特定感知模型较弱,经常会漏检物体或给出错误的定位结果。另一方面,作为一个纯视觉基础模型,SAM 对来自许多不同领域的图像表现出良好的分割泛化能力。然而,SAM 无法为分割的对象提供类别。基于此,本文提出了一个无需训练的开放式目标检测和分割框架 VL-SAM,将现有的泛化物体识别模型 VLM 与泛化物体定位模型 SAM 相结合,利用注意力图作为中间提示进行连接,以解决开放式感知任务。
方法部分
作者提出了 VL-SAM,一个无需训练的开放式目标检测和分割框架。具体框架如下图所示:

图 1 VL-SAM 框架图
具体而言,作者设计了注意力图生成模块,采用头聚合和注意力流的方式对多层多头注意力图进行传播,从而生成高质量的注意力图。之后,作者使用迭代式正负样本点采样的方式,从生成的注意力图中进行采样,得到 SAM 的点提示作为输入,最终得到物体的分割结果。
1、注意力图生成模块(Attention Map Generation Module)
给定一张输入图片,使用 VLM 给出图片中所有的物体类别。在这个过程中存储 VLM 生成的所有 query 和 key,并使用 query 和 key 构建多层多头注意力图:

其中 N 表示 token 的数量,H 表示多头注意力的数量,L 表示 VLM 的层数。
之后,采用 Mean-max 的方式对多头注意力图进行聚合,如图 2 所示:

图 2 多头注意力聚合
首先计算每个头的注意力的权重:
![]()
之后采用基于权重的多头注意力加权进行信息聚合:
![]()
其中
![]()
表示矩阵点乘。
在聚合多头注意力图之后,采用注意力流的方式进一步聚合多层注意力图,如图 3 所示

图 3 注意力流
具体而言,采用 attention rollout 的方式,计算第
![]()
层到第
![]()
层的注意力图传播:

其中
![]()
表示单位矩阵。最后,作者仅使用传播后的最后一层注意力图作为最终的注意力图。
2、SAM 提示生成
生成的注意力图中可能会存在不稳定的假阳性峰值。为了过滤这部分假阳性,作者首先采用阈值过滤的方式进行初步过滤,并找到剩余激活部分的最大联通区域作为正样本区域,其余的部分作为负样本区域。之后,采用峰值检测的方式分别从正负样本区域进行采样,得到正负样本点,作为 SAM 的点提示输入。
3、迭代式分割优化
从 SAM 得到分割结果可能会存在粗糙的边界或者背景噪声,作者采用两种迭代式方式进一步对分割结果进行优化。在第一种迭代方式中,作者借鉴 PerSAM 使用 cascaded post-refinement 的方式,将初始的分割结果作为额外的提示输入到 SAM 中。对于第二种迭代方式,作者使用初始的分割结果对注意力图进行掩码,之后在掩码的区域进行正负样本点采样。
4、多尺度聚合和问题提示聚合
作者还采用两种聚合(Ensemble)的方式进一步改良结果。对于 VLM 的低分率问题,作者使用多尺度聚合,将图片切成 4 块进行输入。此外,由于 VLM 对问题输入较为敏感,作者采用问题提示聚合,使得 VLM 能够尽量多得输出物体类别。最后,采用 NMS 对这些聚合结果进行过滤。
实验结果
在包含 1203 类物体类别的长尾数据集 LVIS 验证集上,相比于之前的开放式方法,VL-SAM 取得了更高的包围框 AP 值。同时,VL-SAM 还能够获取物体分割结果。此外,相比于开集检测方法,VL-SAM 也取得了具有竞争力的性能。

表 1 LVIS 结果
在自动驾驶场景 corner case 数据集 CODA 上,VL-SAM 也取得了不错的结果,超过了开集检测和开放式检测的方法。

表 2 CODA 结果
结论
本文提出了 VL-SAM,一个基于注意力图提示的免训练开放式目标检测和分割框架 VL-SAM,在无需训练的情况下,取得了良好的开放式 (Open-ended) 目标检测和实例分割结果。
#LeCun 的世界模型初步实现
基于预训练视觉特征,看一眼任务就能零样本规划
在 LLM 应用不断迭代升级更新的当下,图灵奖得主 Yann LeCun 却代表了一股不同的声音。他在许多不同场合都反复重申了自己的一个观点:当前的 LLM 根本无法理解世界。他曾说过:LLM「理解逻辑的能力非常有限…… 无法理解物理世界,没有持续性记忆,不能推理(只要推理的定义是合理的)、不能规划。」
Yann LeCun 批评 LLM 的推文之一
相反,他更注重所谓的世界模型(World Model),也就是根据世界数据拟合的一个动态模型。比如驴,正是有了这样的世界模型,它们才能找到更省力的负重登山方法。
近日,LeCun 团队发布了他们在世界模型方面的一项新研究成果:基于预训练的视觉特征训练的世界模型可以实现零样本规划!也就是说该模型无需依赖任何专家演示、奖励建模或预先学习的逆向模型。
- 论文标题:DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning
- 论文地址:https://arxiv.org/pdf/2411.04983v1
- 项目地址:https://dino-wm.github.io/
该团队提出的 DINO-WM 是一种可基于离线的轨迹数据集构建与任务无关的世界模型的简单新方法。据介绍,DINO-WM 是基于世界的紧凑嵌入建模世界的动态,而不是使用原始的观察本身。
对于嵌入,他们使用的是来自 DINOv2 模型的预训练图块特征,其能提供空间的和以目标为中心的表征先验。该团队推测,这种预训练的表征可实现稳健且一致的世界建模,从而可放宽对具体任务数据的需求。
有了这些视觉嵌入和动作后,DINO-WM 会使用 ViT 架构来预测未来嵌入。

完成模型训练之后,在解决任务时,规划会被构建成视觉目标的达成,即给定当前观察达成未来的预期目标。由于 DINO-WM 的预测质量很高,于是就可以简单地使用模型预测控制和推理时间优化来达成期望的目标,而无需在测试期间使用任何额外信息。
DINO 世界模型
概述和问题表述:该研究遵循基于视觉的控制任务框架,即将环境建模为部分可观察的马尔可夫决策过程 (POMDP)。POMDP 可定义成一个元组 (O, A, p),其中 O 表示观察空间,A 表示动作空间。p (o_{t+1} | o≤t, a≤t) 是一个转移分布,建模了环境的动态,可根据过去的动作和观察预测未来的观察。
这项研究的目标是从预先收集的离线数据集中学习与任务无关的世界模型,然后在测试时间使用这些世界模型来执行视觉推理。
在测试时间,该系统可从一个任意的环境状态开始,然后根据提供的目标观察(RGB 图像形式),执行一系列动作 a_0, ..., a_T,使得目标状态得以实现。
该方法不同于在线强化学习中使用的世界模型,其目标是优化手头一组固定任务的奖励;也不同于基于文本的世界模型,其目标需要通过文本提示词指定。
基于 DINO 的世界模型(DINO-WM)

该团队将环境动态建模到了隐藏空间中。更具体而言,在每个时间步骤 t,该世界模型由以下组分构成:

其中,观察模型是将图像观察编码成隐藏状态 z_t,而转移模型则是以长度为 H 的过去隐藏状态历史为输入。解码器模型则是以隐藏的 z_t 为输入,重建出图像观察 o_t。这里的 θ 表示这些模型的参数。
该团队指出,其中的解码器是可选的,因为解码器的训练目标与训练世界模型的其余部分无关。这样一来,就不必在训练和测试期间重建图像了;相比于将观察模型和解码器的训练结合在一起的做法,这还能降低计算成本。
DINO-WM 仅会建模环境中离线轨迹数据中可用的信息,这不同于近期的在线强化学习世界模型方法(还需要奖励和终止条件等与任务相关的信息)。
使用 DINO-WM 实现视觉规划
为了评估世界模型的质量,需要了解其在下游任务上的推理和规划能力。一种标准的评估指标是在测试时间使用世界模型执行轨迹优化并测量其性能。虽然规划方法本身相当标准,但它可以作为一种展现世界模型质量的手段。
为此,该团队使用 DINO-WM 执行了这样的操作:以当前观察 o_0 和目标观察 o_g(都是 RGB 图像)为输入,规划便是搜索能使智能体到达 o_g 的一个动作序列。为了实现这一点,该团队使用了模型预测性控制(MPC),即通过考虑未来动作的结果来促进规划。
为了优化每次迭代的动作序列,该团队还使用了一种随机优化算法:交叉熵方法(CEM)。其规划成本定义为当前隐藏状态与目标隐藏状态之间的均方误差(MSE),如下所示:

实验
该团队基于以下四个关键问题进行了实验:
- 能否使用预先收集的离线数据集有效地训练 DINO-WM?
- 训练完成后,DINO-WM 可以用于视觉规划吗?
- 世界模型的质量在多大程度上取决于预训练的视觉表征?
- DINO-WM 是否可以泛化到新的配置,例如不同的空间布局和物体排列方式?
为了解答这些问题,该团队在 5 个环境套件(Point Maze、Push-T、Wall、Rope Manipulation、Granular Manipulation)中训练和评估了 DINO-WM,并将其与多种在隐藏空间和原始像素空间中建模世界的世界模型进行了比较。
使用 DINO-WM 优化行为
该团队研究了 DINO-WM 是否可直接用于在隐藏空间中实现零样本规划。
如表 1 所示,在 Wall 和 PointMaze 等较简单的环境中,DINO-WM 与 DreamerV3 等最先进的世界模型相当。但是,在需要准确推断丰富的接触信息和物体动态才能完成任务的操纵环境中,DINO-WM 的表现明显优于之前的方法。

下面展示了一些可视化的规划结果:

预训练的视觉表征重要吗?
该团队使用不同的预训练通用编码器作为世界模型的观察模型,并评估了它们的下游规划性能。

在涉及简单动态和控制的 PointMaze 任务中,该团队观察到具有不同观察编码器的世界模型都实现了近乎完美的成功率。然而,随着环境复杂性的增加(需要更精确的控制和空间理解),将观察结果编码为单个隐藏向量的世界模型的性能会显著下降。他们猜想基于图块的表征可以更好地捕获空间信息,而 R3M、ResNet 和 DINO CLS 等模型是将观察结果简化为单个全局特征向量,这样会丢失操作任务所需的关键空间细节。
泛化到全新的环境配置
该团队也评估了新提出的模型对不同环境的泛化能力。为此,他们构建了三类环境:WallRandom、PushObj 和 GranularRandom。实验中,世界模型会被部署在从未见过的环境中去实现从未见过的任务。图 6 展示了一些示例。

结果见表 3。可以看到,DINO-WM 在 WallRandom 环境中的表现明显更好,这表明世界模型已经有效地学习了墙壁和门的一般概念,即使它们位于训练期间未曾见过的位置。相比之下,其他方法很难做到这一点。

PushObj 任务对于所有方法来说都挺难,因为该模型仅针对四种物体形状进行了训练,这使其很难精确推断重心和惯性等物理参数。
在 GranularRandom 中,智能体遇到的粒子不到训练时出现的一半,导致图像出现在了训练实例的分布之外。尽管如此,DINO-WM 依然准确地编码了场景,并成功地将粒子聚集到与基线相比具有最小 Chamfer Distance(CD)的指定方形位置。这说明 DINO-WM 具有更好的场景理解能力。该团队猜想这是由于 DINO-WM 的观察模型会将场景编码为图块特征,使得粒子数量的方差仍然在每个图块的分布范围内。
与生成式视频模型的定性比较
鉴于生成式视频模型的突出地位,可以合理地假设它们可以很容易地用作世界模型。为了研究 DINO-WM 相对于此类视频生成模型的实用性,该团队将其与 AVDC(一个基于扩散的生成式模型)进行了比较。
如图 7 所示,可以看到,在基准上训练的扩散模型能得到看起来相当真实的未来图像,但它们在物理上并不合理,因为可以看到在单个预测时间步骤中就可能出现较大的变化,并且可能难以达到准确的目标状态。

DINO-WM 所代表的方法看起来颇有潜力,该团队表示:「DINO-WM 朝着填补任务无关型世界建模以及推理和控制之间的空白迈出了一步,为现实世界应用中的通用世界模型提供了光明的前景。」
参考链接:
https://www.ft.com/content/23fab126-f1d3-4add-a457-207a25730ad9
原文地址:https://blog.csdn.net/weixin_49587977/article/details/143822228
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!