CS224N课程笔记,第一课,词向量的演变
文章目录
关键词/热点词
Word vectors, feed-forward networks, recurrent networks, attention, encoder-decoder models, transformers, large pre-trained language models, Word meaning, dependency parsing, machine translation, question answering, Distributional semantics
1. 引言
大家好.欢迎来到斯坦福大学的CS224N,也称为Ling284,深度学习的自然语言处理。我是克里斯托弗·曼宁,我是这门课的主要讲师。因此,我将花费大约10分钟来讨论课程,然后我们将直接进入内容,原因我将在一分钟内解释。因此,我们将讨论人类语言和单词含义,然后我将介绍用于学习单词含义的 word2vec 算法的思想。然后从那里开始,我们将具体讨论如何根据 word2vec 算法计算目标函数梯度,并说一点优化是如何工作的。然后在课程结束时,我想花一点时间让您了解这些词向量的工作原理,以及您可以使用它们做什么。所以今天学习的关键是,我想让你了解深度学习词向量是多么的神奇。因此,我们得到了一个非常令人惊讶的结果,即单词的含义可以用一个大的实数向量来表示,尽管不是完美的,但实际上也能工作的相当好。
1-1. 人类语言的复杂性
从某种意义上说,这(treat word as a large vector of real numbers)是过去十年深度学习的常见现象,但它与数千年的传统背道而驰,这确实是一个出乎意料的结果。好,那么我们希望在这门课程中教什么?我们有三个主要目标:首先是教你基础,包括深度学习如何应用于NLP。因此,我们将从基础开始,然后继续NLP中使用的关键方法,循环网络、注意力机制、 transformers 等等。我们想做的不仅仅是这些。我们也想给你一些关于人类语言的整体理解的感觉,以及为什么它们为什么实际上很难理解,即使人类似乎很容易做到。如果你真的想学很多关于这个话题的知识,你应该报名参加语言学系开始上一些课。但尽管如此,对于你们中的许多人来说,这是你在硕士学位或其他课程中看到的唯一的人类语言内容。因此,我们希望从今天开始在这方面花一点时间。最后,我们想让您了解在PyTorch中构建系统的能力,这是NLP中的一些主要问题。因此,我们将学习单词含义,依赖解析,机器翻译,问题回答。
让我们深入人类语言。从前,我有一个更长的介绍,给出了很多关于人类语言如何被误解和复杂的例子,我将在后面的讲座中展示其中的一些例子。但是从今天开始,我们将专注于单词的含义。我想我只举一个例子,它来自一个非常漂亮的卡通动画。 这不是关于句子的一些句法歧义,而是强调 语言是一种社会系统,由人们构建和解释 。这就是 – 当人们决定适应它的结构时,它会发生变化,这也是为什么人类语言作为人类的自适应系统很伟大,但作为我们的计算机至今难以理解的系统的部分原因。所以在这两个女人之间的对话中,一个人说,不管怎样,我可以不在乎。另一个说,我认为你的意思是你不能不在乎,说你可以不在乎意味着你至少在乎一些。每一种措辞、拼写、语气和时间的选择都带有无数的同步信号、上下文和潜台词,而且每个听众都以自己的方式解释这些信号。语言不是一个正式的系统,语言是庞大的混乱。你永远无法确定任何单词对任何人意味着什么,你所能做的就是试着更好地猜测你的单词如何影响人们。所以你可以有机会找到那些会让他们感觉像你想要他们的感觉。其他一切都是毫无意义的。好,这就是我们最终的目标,如何更好地构建计算系统,试图更好地猜测他们的话会如何影响其他人,以及其他人选择说的话的含义。
关于人类语言的一个有趣的事情是,它是由人类构建的系统。 从某种意义上说,这是一个相对较新的系统。因此,在讨论人工智能时,很多时候人们都将注意力集中在人脑和经过的神经元上,而这种智能应该存在于人们的大脑中。但我只想暂时集中在语言的作用上,这实际上是有争议的,但人类并不一定比黑猩猩或倭黑猩猩等高等类人猿聪明得多,黑猩猩和倭黑猩猩被证明能够使用工具制定计划,事实上黑猩猩的短期记忆比人类好得多。因此,相对于此,如果您浏览地球上生命的历史,人类确实是最近才发展出语言的。大多数人估计,人类的语言大约在十万到一百万年前出现,这与地球上生命的进化过程相比只是一瞬间。但是人类之间强大的交流很快就使我们建立起对其他生物的优势。因此,有趣的是,最终的力量并不是有毒的毒药,也不是超级快或超级大,而是具有与部落其他成员交流的能力。 最近,人类再次发展了写作,这使得知识可以跨越时间和空间的距离进行交流,这只是最近5,000年左右发生的事情。因此,在短短几千年的时间里,保存和分享知识的能力将我们从青铜时代带到了今天的智能手机和平板电脑时代。因此,人工智能和人机交互的一个关键问题是如何让计算机能够理解人类语言传达的信息。
1-2. NLP 惊人的发展
我们需要知识来很好地理解语言和人,但同样的情况是,许多知识都包含在语言中,遍布世界各地的书籍和网页,这就是我们在本课程中要研究的事情之一,如何构建理解这些内容的计算机系统,目前已经取得了很多进展,在过去十年左右的时间里,尤其是在过去的几年里,随着机器翻译的更加新颖的方法出现,我们现在处于一个机器翻译真正运行良好的时代。从世界历史来看,这真是太神奇了,几千年来,学习别人的语言是一项需要大量努力和专心的人类任务。 但是现在我们可以跳上网络浏览器,然后想,哦,我想知道今天肯尼亚有什么新闻,你可以去肯尼亚的网站,嗯,然后你可以让谷歌为你翻译斯瓦希里语,翻译不是很完美,但相当不错。
去年NLP在流行媒体中最大的发展是GPT-3,这是OpenAI发布的一个巨大的新模型。 GPT-3是关于什么的,为什么它很棒,实际上有点微妙,所以我不能在这里详细介绍所有的细节,但这很令人兴奋,因为这似乎是我们称之为通用模型的第一步,在那里你可以训练一个非常大的模型,比如我之前展示的图书馆图片,它只是有世界知识,人类语言知识,如何完成任务。然后你可以用它来做各种各样的事情。所以我们不再是建立一个检测垃圾邮件的模型,然后是一个检测色情内容的模型,然后是一个检测任何外语内容的模型,只是为每个不同的任务建立所有这些单独的监督分类器,我们现在刚刚建立了一个理解的模型。因此,它的确切作用是预测下一个单词。
在左边,它被告知要以苏斯博士的风格写埃隆·马斯克,它从一些文本开始,然后生成更多的文本。它生成更多文本的方式实际上是通过一次预测一个单词,跟随单词来完成其文本。但这有一个非常强大的功能,因为你可以用GPT-3做的是,你可以举几个例子来说明你想要它做什么。所以我可以给它一些文字示例,我打破了窗户,紧接着是一个问题,我打破了什么?如果你再输入一个句子,比如我今天中午吃了番茄炒鸡蛋,它就会说,我今天中午吃了什么?所以这个提示告诉GPT-3我想要它做什么。所以如果我给它另一个提示,比如,“我给了约翰·弗劳尔斯三个…”,预测接下来会出现什么单词。它会按照我的提示,生成我送花给谁?或者我可以说我给了她一朵玫瑰和一把吉他,它会按照这个模式的想法,我给了谁一朵玫瑰和一把吉他? 实际上,这个模型可以做一系列令人惊叹的事情,仅举一个例子。你可以做的另一件事是把人类语言句子翻译成SQL。所以这可以使cs145更容易。因此,考虑到人类语言文本的SQL翻译的几个例子,我在这个时候没有显示,因为它不适合我的幻灯片,然后我可以给它一个句子,查询有多少用户注册自2020年,它把句子变成SQL。或者我可以给它另一个查询什么是每个用户订阅的平均影响数,然后再将其转换为SQL。所以GPT-3非常了解语言的含义以及SQL等其他事物的含义,并且可以流利地操作它。
1-3. WordNet
我们如何表示一个词的含义?或者说我们如何去知道一个单词什么意思?嗯,我们可以查一下韦伯斯特词典,然后说,好,用一个词来表示的想法,一个人想用词来表达的想法,等等。韦伯斯特的字典定义确实以某种方式专注于 “想法” 一词,但这与语言学家思考含义的最常见方式非常接近。因此,他们认为单词的含义是一个单词之间的配对,该单词是一个能指或符号,它所表示的事物,即一个想法或事物。所以椅子这个词的意思是椅子的一组东西,这被称为指称语义,这个术语也被使用并类似地应用于编程语言的语义。这个模型的可实施性不是很深,我如何从椅子意味着世界上的椅子组合的想法转变为我可以用计算机操纵意义的东西?因此,传统上,在自然语言处理系统中通常处理含义的方式是利用诸如字典之类的资源,尤其是同义词库。流行的WordNet将单词和术语组织成同义词集,这些同义词集可以表示相同的事物,对应于is a关系。因此,对于 is a关系,例如小熊猫是一种食肉动物,是一种胎盘,是一种哺乳动物。
语言系统是由人类定义的系统,是自适应的,因此一个词语的含义可能会随着时代变迁而发生较大的变化,另外,一些词语在不同的语境中也会有不同的含义,还有一点需要注意的是,很多词语也会被新造出来,以及一些古老的词语会被遗忘。这就指明了 WordNet 这样一个固定的同义词库可能是不精准的,难以维护并且难以使用的。例如,在 WordNet 中, proficient 被列为 good 的同义词, 前者表示精通, 后者表示好 – 这个近似显然只在一些很少的情况下才会为真。当你说熟练与优秀时,你的意思是完全不同的。特别是有很多单词和单词的大量用法是不存在的,包括任何最新的术语,例如wicked is there for the wicked witch, but not for more modern colloquial uses. 忍者当然不是为了某些人对程序员的描述而存在的,它(维护同义词表)需要大量的人力劳动,而且不可能跟上最新的。这些问题被统称为 不完整性(incompleteness)
- A useful resource but missing nuance: “proficient” is listed as a synonym for “good” – This is only correct in some contexts
- Missing new meanings of words
- Subjective
- Requires human labor to create and adapt
- Can’t be used to accurately compute word similarity
1-4. OneHot Encoding
那么很多传统的NLP有什么问题呢?许多传统NLP的问题是,单词被视为离散符号。所以我们有酒店、会议、汽车旅馆等符号,在深度学习中,我们称之为本地化表示(localized representation)。 这是因为如果你在统计机器学习系统中,想要表示这些符号,它们每个都是一个单独的东西,所以表示它们的标准方式,这就是你在统计模型中所做的,如果你正在构建一个以单词为特征的逻辑回归模型,你将它们表示为一个单词向量。所以你有一个维度为每个不同的词。所以也许像我的例子,这里是我的表示作为汽车旅馆和酒店的向量。 因此,这意味着我们必须拥有与词汇表中单词数量相对应的巨大向量。所以,如果你有一本高中英语词典,它可能有大约250,000个单词,但这门语言真的有很多更多的单词。因此,也许我们至少希望有一个500,000维的向量能够应对这一点。
motel = [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
hotel = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]
motel
英 [məʊˈtel]
美 [moʊˈtel]
n. 汽车旅馆
【名】 (Motel)(德)莫特尔(人名)
[ 复数 motels ]
hotel
英 [həʊˈtel]
美 [hoʊˈtel]
n. 旅馆,酒店,饭店;(无线电通讯中)字母H的代码
【名】 (Hotel)(美)奥泰尔(人名)
[ 复数 hotels ]
好,但是离散符号的更大问题是我们没有单词关系和相似性的概念。 例如,在网络搜索中,如果用户搜索西雅图汽车旅馆,我们也想匹配包含西雅图酒店的网页。但是我们的问题是,对于不同的单词,我们有一个单词向量。因此,从正式的数学意义上讲,这两个向量是正交的,因此它们之间没有任何相似性的自然概念。嗯,有些事情我们可以做,但要努力做到这一点,2010年人们确实做到了这一点。 我们可以说,嘿,我们可以使用WordNet同义词,我们计算同义词列表无论如何都是相似的。或者,嘿,也许我们可以以某种方式建立我们对有意义、重叠的单词的表示,而人们做了所有这些事情。但是它们往往会因为不完整性而严重失败,所以我今天要介绍的是现代深度学习方法,我们在实值向量本身中编码相似性。
1-5. distributional semantics
那我们该怎么做呢?我们这样做的方法是利用这个叫做分布语义学的想法。因此,当您第一次看到分布语义学的概念时,可能会感到有些疯狂,因为我们现在要做的不是像指称语义学这样的东西,而是说一个单词的含义将由经常出现在它附近的单词给出。J. R Firth是上世纪中叶的英国语言学家,他的一个精辟的名言是 you shall know a word by the company it keeps。这是在统计和深度学习NLP中使用的最成功的想法之一,它被证明是一种极具计算意义上的语义,这使得它在深度学习系统中被非常成功地使用。当一个单词出现在文本中时,它具有上下文,也即你所看到的那些单词。所以对于一个特定的词,我的例子是银行业(banking),我们会在文本中找到多处银行出现的地方,并收集附近的单词,即上下文单词,这些上下文中的单词在某种意义上代表了银行这个词的含义。
government debt problems turning into banking crises as happened in 2009...
...saying that Europe needs unified banking regulation to replace the hodgepodge...
...India has just given its banking system a shot in the arm...

好,那么我们该如何处理语言的分布模型呢?我们要做的是将上下文中的单词视为向量,我们希望为每个单词构建密集的实值向量,在某种意义上代表该单词的含义。它表示该单词含义的方式是,该向量将有助于预测上下文中的其他单词。所以在这个例子中,为了保持它在幻灯片上的可管理性,矢量只有八维。但实际上我们使用相当大的向量,所以一个非常常见的大小实际上是300维向量。 注意,词向量(word vector) 也时常被表述为 (neural word representation)神经词表示,或者被称为词嵌入(word embeddings)。因此,这些现在是分布式表示,而不是本地化表示,因为 “银行” 一词的含义分布在向量的所有300维度上。这些被称为单词嵌入 ,因为当我们有一大堆单词时,这些表示将它们全部放置在高维向量空间中,因此它们被嵌入到该空间中。不幸的是,人类不善于观察300维向量空间,甚至是8维向量空间,所以我唯一能展示给你们的,是这个空间的二维投影。现在,即使这很有用,但同样重要的是要意识到,当您进行三维空间的二维投影时,您将丢失该空间中几乎所有信息,很多东西会被压在一起。

2. word2vec
我现在要介绍的算法是一个叫做word2vec的算法,它是由Tomas Mikolov及其同事2013年作为学习单词向量的框架而提出的,它是一个简单易懂的起点。我们的想法是我们有很多来自某个地方的文本,我们通常称之为 语料库(corpus) 。文本语料库就像拉丁语中的正文一样,所以它是文本的主体。然后我们选择一个固定的 词汇表(vocabulary) ,它通常很大,但仍然被截断,所以我们去掉了一些非常罕见的单词,所以我们可以说词汇量为400,000,然后我们为每个单词创建向量。好的,那么我们要做的是为每个单词计算出一个好的向量,真正有趣的是,我们可以从一大堆文本中学习这些单词向量,通过这个分布相似性的任务,能够预测什么词出现在其他词的上下文中。我们遍历文本中的单词,所以在任何时候我们都有一个 中心词C(center word, c) ,以及它之外(outside)的上下文词(context word, o)。 然后根据当前的词向量,我们将计算上下文词出现的概率
P
(
o
∣
c
)
P(o|c)
P(o∣c)。给定中心词和一个上下文窗口,我们就知道哪些单词确实出现在中心词的上下文中,所以我们要做的是继续调整单词向量,以最大化分配给实际出现在中心词上下文中的单词的概率。所以让它变得更具体一点,这就是我们正在做的:
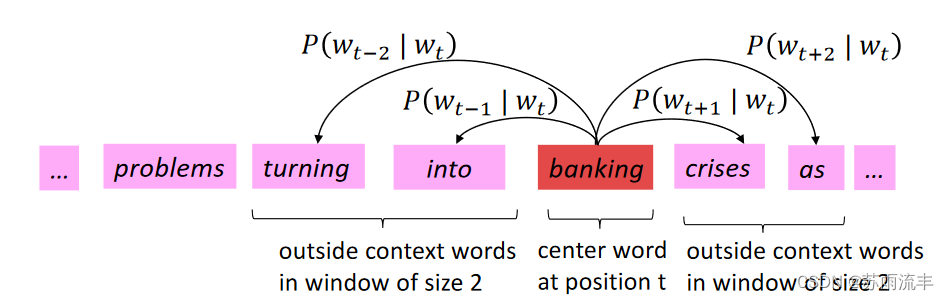
Word2vec 的主要思想是:
- 我们有一个大的文本语料库(corpus): 一个长长的单词列表
- 每个单词位于一个固定词汇表(vocabulary)中, 可以用一个向量(low-dimensional (much smaller than vocabulary size))表示
- 遍历文本中的每个位置
t, 其中有一个中心词(center word)c和上下文单词(context words)o - 使用
c和o的词向量的相似度来计算给定c条件下o(反之亦然)的概率: P ( w t + j ∣ w t ) P(w_{t+j}|w_t) P(wt+j∣wt) - 不断调整词向量使这个概率最大化
这里, 可以将向量点积作为单词之间的相似性度量, 也即余弦相似度(cosine similarity), 词向量是随机初始化的, 是稠密的实值向量, 它的维数比词表大小小得多。
2-1. Loss Function
对于 corpus 中的每一个单词位置
t
=
1
,
.
.
.
,
T
t=1, ... , T
t=1,...,T, 我们预测一个大小为
m
m
m 的固定上下文窗口内其它单词的出现概率
P
(
w
t
+
j
∣
w
t
)
P(w_{t+j}|w_t)
P(wt+j∣wt), 计算似然函数:
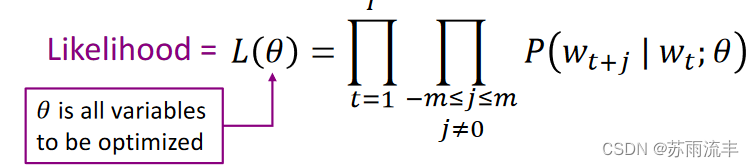
一个小 trick 是, 我们将似然函数取负对数平均就得到了我们的损失函数或称目标函数
J
(
θ
)
J(\theta)
J(θ)(sometimes called a cost or loss function)
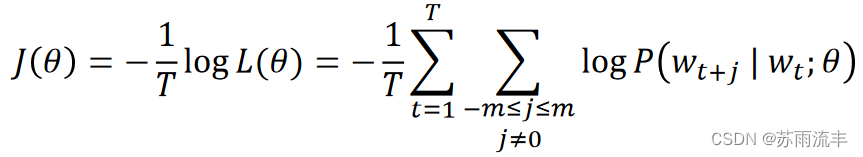
此时, 我们的目标从最大化似然函数(也即尽可能地使得上下文单词的出现概率提高) 变为了最小化目标函数 J ( θ ) J(\theta) J(θ)
2-2. P ( w t + j ∣ w t ) P(w_{t+j}|w_t) P(wt+j∣wt)
我们使用两个符号来表示当w作为中心词或者上下文时的词向量:
v
w
v_w
vw when w is center word
u
w
u_w
uw when w is context
因此, 对于一个中心词c和上下文单词o:
P
(
o
∣
c
)
=
exp
(
u
o
T
v
c
)
∑
w
∈
V
exp
(
u
w
T
v
c
)
P(o|c)=\frac{\exp(u_o^Tv_c)}{\sum_{w\in V}\exp(u_w^Tv_c)}
P(o∣c)=∑w∈Vexp(uwTvc)exp(uoTvc)
这可能是大家所熟悉的softmax函数,它取任意的分数(在这里,每个词都有一个词汇表,由点积产生),并产生一个概率分布,其中分数较大的事物获得较高的概率。
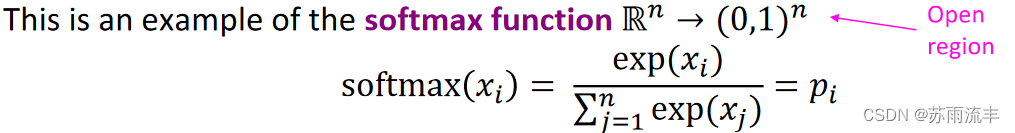
• max because amplifies probability of largest
x
i
x_i
xi
• soft because still assigns some probability to smaller
x
i
x_i
xi
• Frequently used in Deep Learning
2-3 随机梯度下降
那么现在我们得到了一个原始的目标函数,它的定义是一个负平均对数似然,概率分布由softmax给出,我们知道,通常为了优化目标函数,一个提通常的做法是求目标函数关于每个参数的偏导
对向量
v
c
v_c
vc 求偏导:
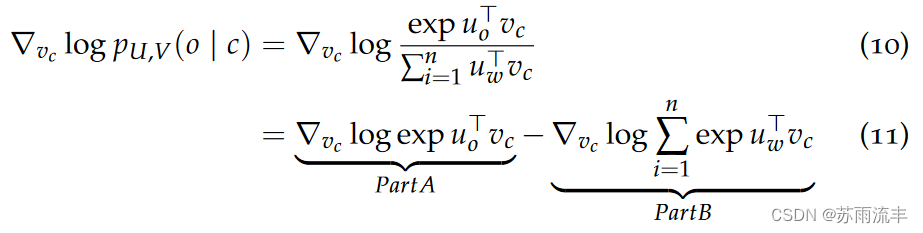
对于 part A, 由于 log 和 exp 运算抵消, 同时由向量偏导法则, partA =
u
o
u_o
uo
对于 part B, 有:
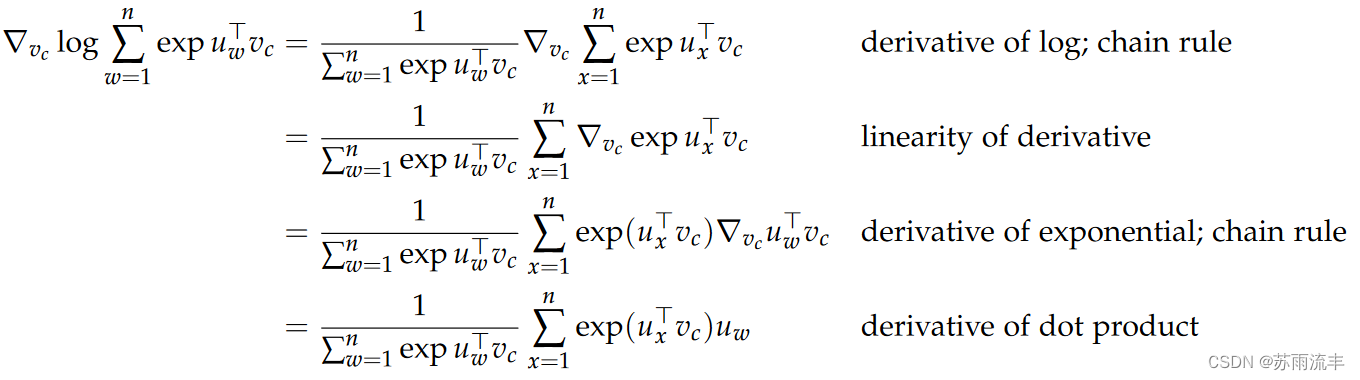
注意上式中末尾的
u
w
u_w
uw应为
u
x
u_x
ux
将这个式子变形:
P
a
r
t
B
=
∑
x
=
1
n
u
x
exp
(
u
x
T
v
c
)
∑
w
=
1
n
u
w
T
v
c
=
∑
x
=
1
n
u
x
p
(
u
x
∣
v
c
)
=
E
(
u
∣
v
c
)
PartB=\sum_{x=1}^{n}u_x\frac{\exp(u_x^Tv_c)}{\sum_{w=1}^{n}u_w^Tv_c}=\sum_{x=1}^{n}u_xp(u_x|v_c)=E(u|v_c)
PartB=x=1∑nux∑w=1nuwTvcexp(uxTvc)=x=1∑nuxp(ux∣vc)=E(u∣vc)
综述:
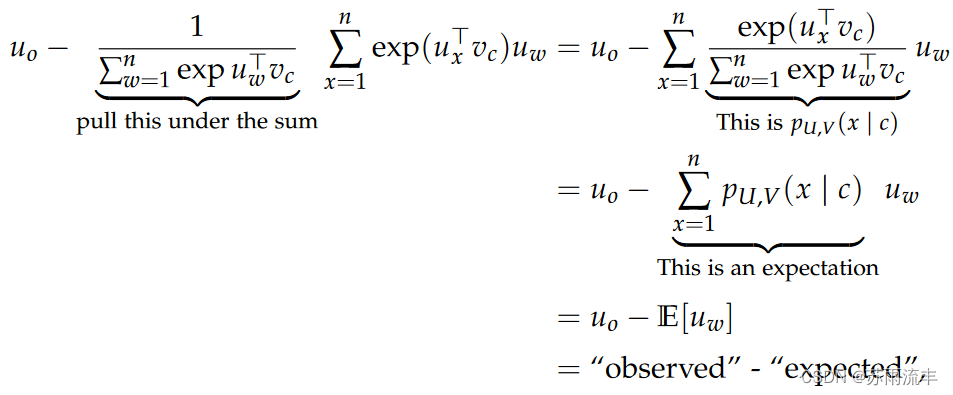
原文地址:https://blog.csdn.net/weixin_46866349/article/details/137271242
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!