电商数据集成之电商商品信息采集系统架构设计||电商API接口
一、引言
本架构设计文档旨在阐述基于 Selenium 的电商商品信息采集系统的整体架构,包括系统视图、逻辑视图、物理视图、开发视图和进程视图,并提供一个简单的采集电商商品信息的 demo。该系统通过模拟浏览器行为,实现对电商商品信息的自动化抓取,为数据分析、市场研究等提供数据支持。
京东获得JD商品详情 API 返回值说明
item_get-获得JD商品详情
jd.item_get
公共参数
| 名称 | 类型 | 必须 | 描述 |
|---|---|---|---|
| key | String | 是 | 调用key(必须以GET方式拼接在URL中) |
| secret | String | 是 | 调用密钥 |
| api_name | String | 是 | API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等] |
| cache | String | 否 | [yes,no]默认yes,将调用缓存的数据,速度比较快 |
| result_type | String | 否 | [json,jsonu,xml,serialize,var_export]返回数据格式,默认为json,jsonu输出的内容中文可以直接阅读 |
| lang | String | 否 | [cn,en,ru]翻译语言,默认cn简体中文 |
| version | String | 否 | API版本 |
请求参数
请求参数:num_iid=10335871600
参数说明:num_iid:JD商品ID
响应参数
Version: Date:
| 名称 | 类型 | 必须 | 示例值 | 描述 |
|---|---|---|---|---|
| item | item[] | 0 | 获得JD商品详情 |
二、系统视图
系统视图描述了系统的整体结构和功能模块。本采集系统主要包括以下几个模块:
(1)多终端接入
支持微信小程序、Android、IOS、PC 网页任意一个入口。
(2)用户界面模块
负责与用户进行交互,提供采集任务配置、启动、停止等操作界面。

(3)爬虫管理模块
负责调度和管理爬虫任务,包括任务队列、任务状态监控等。
(4)数据解析模块
负责对采集到的网页数据进行解析,提取商品信息。
(5)数据存储模块
负责将解析后的商品信息存储到数据库或文件中。
(6)代理管理模块
负责代理服务器的获取、验证和管理。
为爬虫任务提供可用的代理 IP,确保 IP 高可用。

监控代理服务器的状态,及时剔除不可用的代理。

三、逻辑视图
逻辑视图展示了系统内部的功能划分和模块间的交互关系,从用户视角描述系统有什么功能。本采集系统的逻辑视图如下:
(1)用户通过用户界面模块配置采集任务,包括目标 URL、采集深度、抓取字段等。
(2)用户界面模块将配置信息传递给爬虫管理模块,爬虫管理模块根据配置信息创建爬虫任务,并将其加入任务队列。
(3)爬虫管理模块调度 Selenium 驱动浏览器进行网页加载和渲染,模拟用户操作进行页面滚动、点击等。
(4)Selenium 将加载完成的页面数据返回给爬虫管理模块,爬虫管理模块将页面数据传递给数据解析模块。
(5)数据解析模块使用正则表达式或 XPath 等方法对页面数据进行解析,提取出商品信息。

(6)提取的商品信息被传递给数据存储模块,数据存储模块将其存储到数据库或文件中。
(7)代理池构建
代理管理模块首先会从各种来源(如免费代理网站、付费代理服务)获取代理 IP。
对获取的代理 IP 进行验证,确保其可用性和匿名性。
将验证通过的代理 IP 存入代理池,供爬虫任务使用。
(8)代理调度
当爬虫任务启动时,代理管理模块会从代理池中选取一个可用的代理 IP。
将选取的代理 IP 配置到 Selenium WebDriver中,确保爬虫任务通过该代理进行网页请求。
监控代理 IP 的使用情况,如请求次数、响应时间等,以便及时更换。
(9)代理维护
定期对代理池中的代理 IP 进行验证,剔除不可用的代理。
根据代理 IP 的使用情况,动态调整代理池的权重,优先使用性能更好的代理。
当代理池中的可用代理数量低于阈值时,自动从来源处获取新的代理 IP 进行补充。
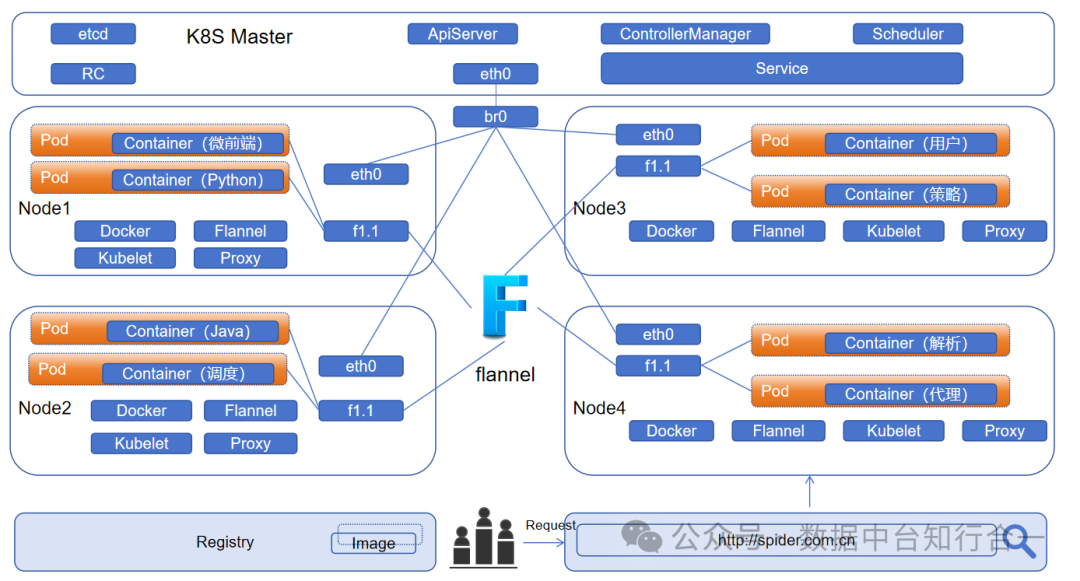
四、物理视图
物理视图描述了系统在实际环境中的部署情况,包括硬件、网络、软件等资源的配置。本采集系统的物理视图如下:
采用微服务架构,分布式部署,每个服务都实现容器化,整个微服务集群部署在 K8S 集群上,可以扩展支持多云部署。
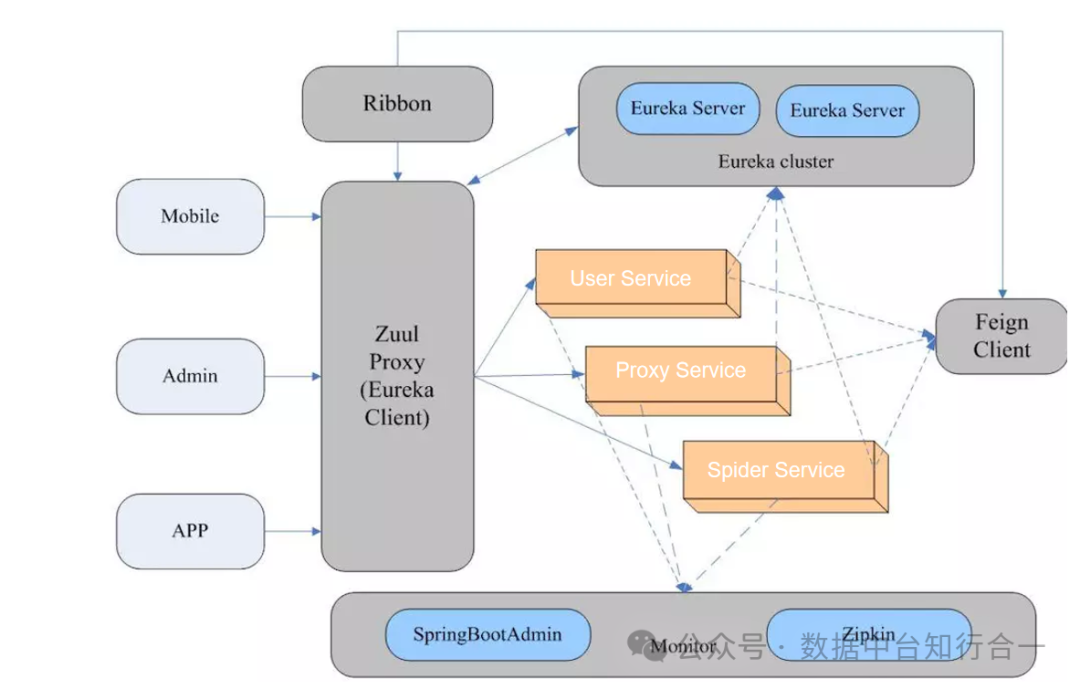
五、开发视图
开发视图展示了系统的代码结构和开发过程中的模块划分。本采集系统的开发视图如下:
整体采用微服务架构,容器化部署。
系统采用多语言开发,包括 Java、Python 语言进行开发,利用 Selenium 库模拟浏览器行为,进行网页数据的抓取。
系统代码分为多个模块和函数,每个模块和函数负责特定的功能,实现代码的高内聚和低耦合。
代码使用版本控制工具(如Git)进行管理,确保代码的可追溯性和可维护性。
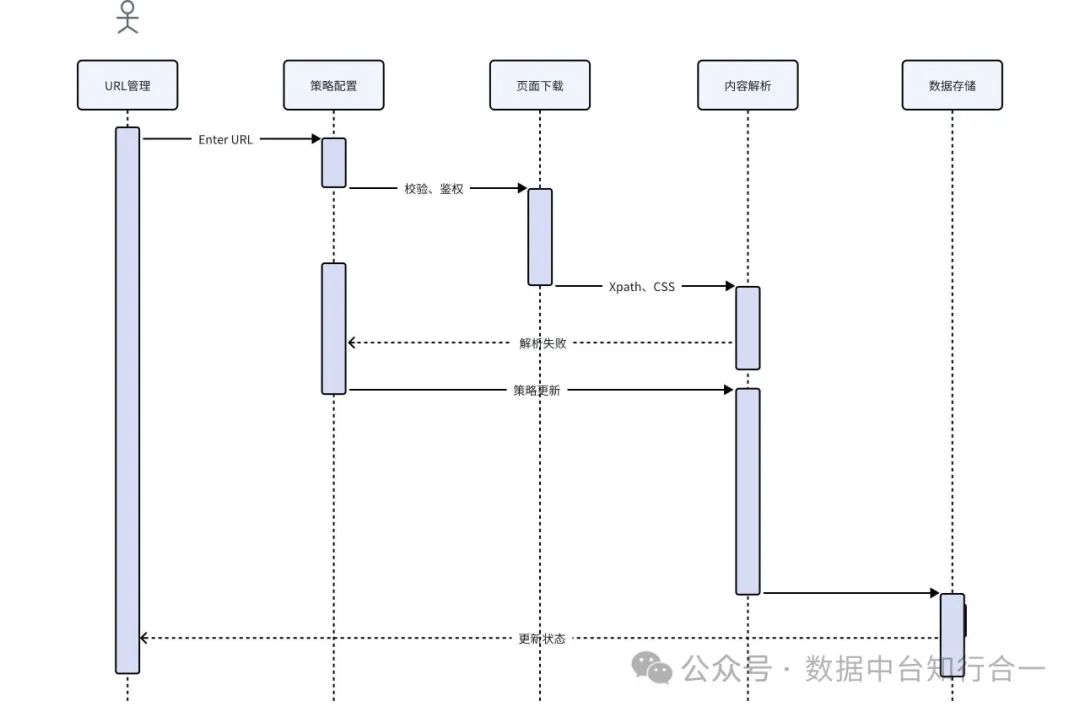
六、进程视图
系统启动后,主进程负责初始化系统环境和加载配置信息。
根据配置信息,主进程创建爬虫任务,并启动子进程执行爬虫任务。
每个爬虫任务对应一个子进程,子进程使用 Selenium 驱动浏览器进行网页加载和渲染,模拟用户操作进行页面抓取。
子进程将抓取到的页面数据传递给主进程进行解析和存储。
主进程负责监控子进程的运行状态,确保任务的正常执行。
七、Demo 示例
下面是一个简单的基于 Selenium 的电商商品信息采集 demo,用于演示系统的基本功能。
| from selenium import webdriver |
代码运行后:

我们成功获取到了需要提取的内容:
| title 跨境热销水波纹投影灯动态北极光卧室星空梦幻音乐户外露 price ¥60.00~¥130.00 volume 80+ |
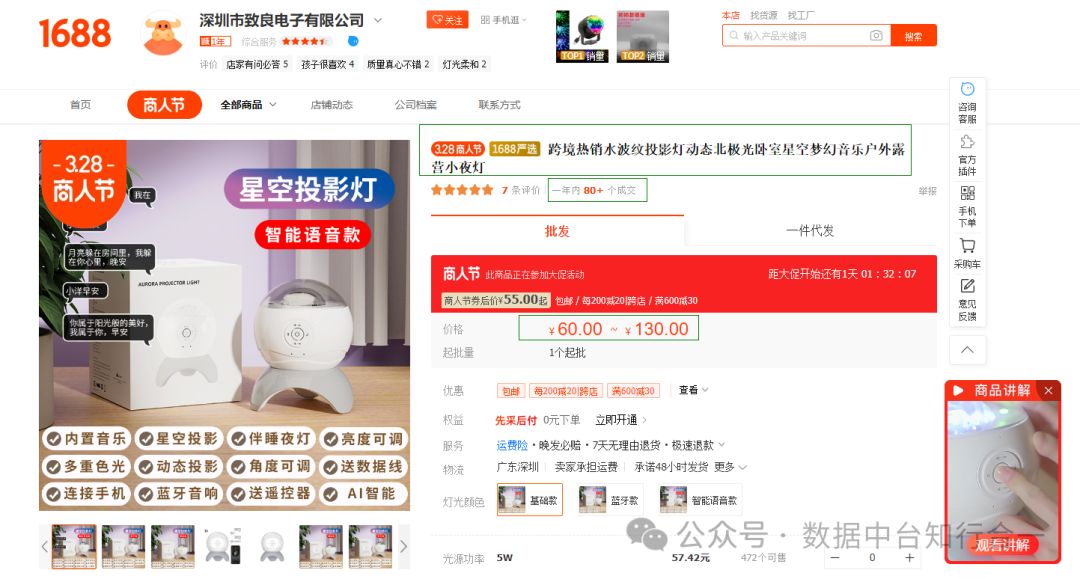
我们可以查看一下待爬取的网页:
原文地址:https://blog.csdn.net/2301_79478575/article/details/140587733
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!