数据结构:堆

这张网络上的图片很形象的展示了一棵具有多个分支的独特树木,其分支模式类似于(甚至于是完美)二叉树的结构。我们可以将这棵树的形态作为引入二叉树概念的一个隐喻。在二叉树中,每个节点最多有两个子节点,这与树木的分支方式相似,其中每个分支都可以进一步分为两个更小的分支。
二叉树是计算机科学中常用的数据结构,它的每个节点最多有两个子节点,通常被称为左子节点和右子节点。二叉树的这种结构使得它在执行搜索和排序操作时非常高效,也广泛应用于各种算法中,如二叉搜索树、堆和平衡二叉树等。
二叉树
- 定义:二叉树是一种数据结构,其中每个节点最多有两个子节点。
- 类型:
- 满二叉树:所有非叶节点都有两个子节点。
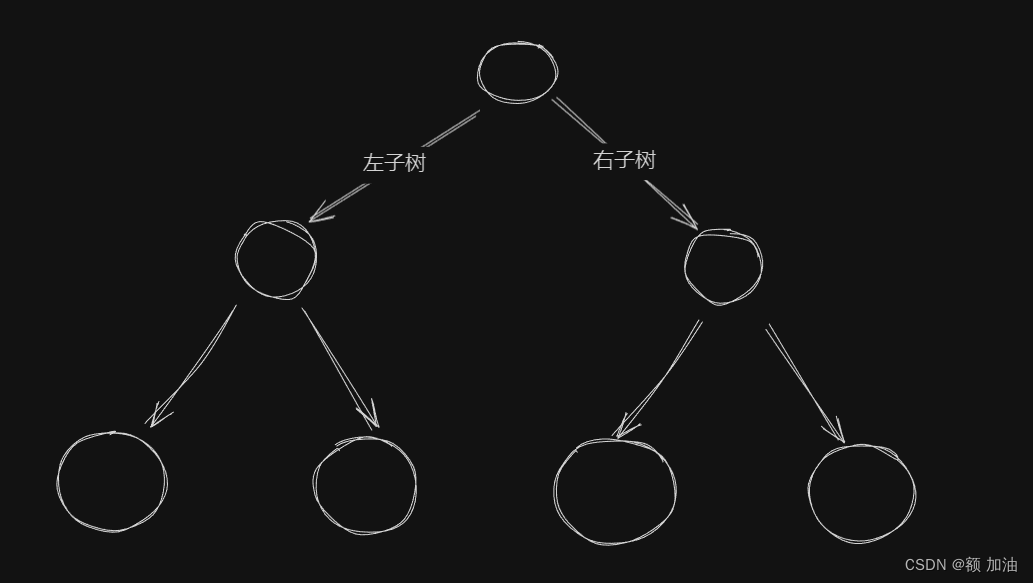
- 完全二叉树:除最后一层外,每层都被完全填满,且所有叶节点集中在左侧。
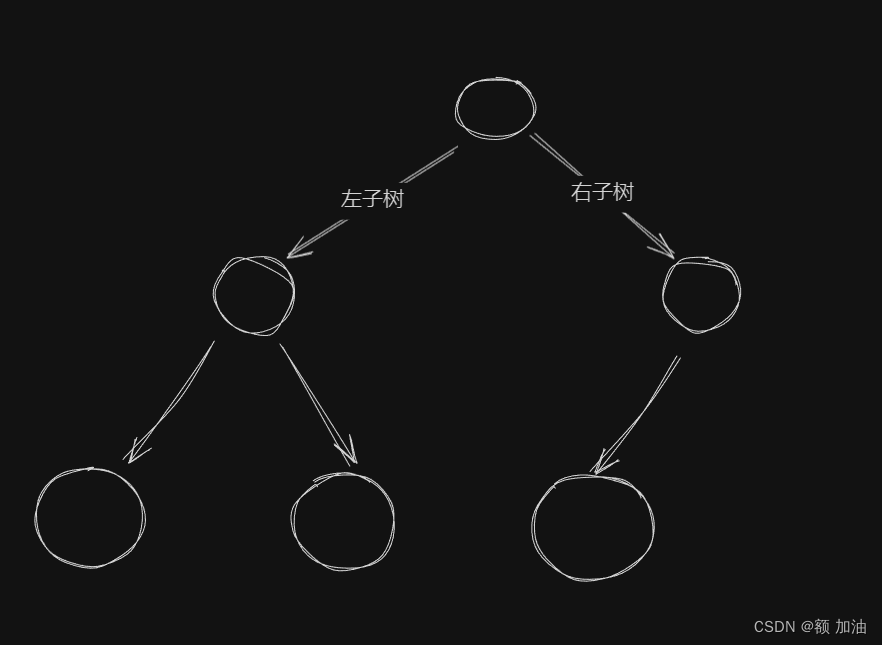
- 满二叉树节点个数与树高度的关系:
-
满二叉树的节点个数与树高度之间的计算关系可以通过以下公式表示:
-
节点个数: 对于高度为 ( h ) 的满二叉树,节点个数 ( n ) 为 ( 2^h - 1 )。
-
树高度: 如果已知节点个数 ( n ),树的高度 ( h ) 可以通过等比数列公式计算 来计算。这些公式说明,对于满二叉树,节点个数是树高度的指数函数,而树高度是节点个数的对数函数。这种关系在数据结构中非常重要,因为它影响树的平衡和搜索操作的效率。
- 术语:
- 根节点:没有父节点的顶部节点。
- 叶节点:没有子节点的节点。
- 高度:从根节点到任意节点的最长路径。

- 父节点: 一个节点,它有向下连接到子节点的链接。
- 左子节点: 父节点的左侧子节点。
- 右子节点: 父节点的右侧子节点。
堆
在数据结构的世界里,二叉树无疑是一个神奇而强大的存在。它以其独特的方式组织和存储数据,使得数据的处理变得高效而直观。而在二叉树的众多变种中,堆(Heap)以其特殊的性质和广泛的应用,成为了一个不可或缺的主角。
堆是一种特殊的完全二叉树,它满足一个基本条件:任何一个父节点的值都大于或等于(在最大堆中)或小于或等于(在最小堆中)其子节点的值。这个简单的规则赋予了堆一种强大的能力——快速找到最大或最小元素的能力。
堆的应用范围非常广泛,从操作系统的任务调度到数据库的查询优化,再到各类算法竞赛中的问题求解,堆的身影无处不在。堆排序(Heap Sort)和Top-K问题就是堆应用的经典案例。堆排序是一种高效的排序方法,它利用堆的性质,能够在O(nlogn)的时间复杂度内完成排序。而Top-K问题,即从一组数据中找出最大或最小的K个数,也可以通过维护一个大小为K的堆来高效解决。
那么,堆是如何实现的呢?
在计算机中,堆通常使用数组来表示。对于一个索引为i的节点,其左子节点的索引为2i+1,右子节点的索引为2i+2,父节点的索引为(i-1)/2(我们使用整形来计算,多余浮点数将会被计算机自动去除)。这样的存储方式使得堆的操作变得简单而高效。用数组的下标分别代替根节点与其子节点,用完全二叉树根节点与子节点的关系计算其节点下标

#pragma once
#include<iostream>
#include<cassert>
#include<cstdbool>
using namespace std;
typedef int Datatype;
class Heap
{
friend inline ostream& operator<<(ostream& out, const Heap& h);
public:c++
Heap(int capacity=4);
~Heap();
void Push(Datatype a);
Datatype TPop();
bool Empty();
private:
void adjustup(int child);
void adjustdown();
inline void swap(Datatype& q1, Datatype& q2)
{
Datatype temp = q1;
q1 = q2;
q2 = temp;
}
void New_capacity();
Datatype* heap;
int _size;
int _capacity;
};
inline ostream& operator<<(ostream& out, Heap& h)
{
while (!h.Empty())
{
out << h.TPop()<<" ";
}
out << endl;
return out;
}堆的插入操作
堆的插入操作基本上遵循以下步骤:
1. 将新元素添加到堆的末尾。
2. 将新元素与其父节点比较。
3. 如果新元素的值大于(或小于,取决于是最大堆还是最小堆)其父节点的值,则将它们交换。
4. 重复步骤2和3,直到新元素被放置到正确的位置,或者已经到达堆的顶部。
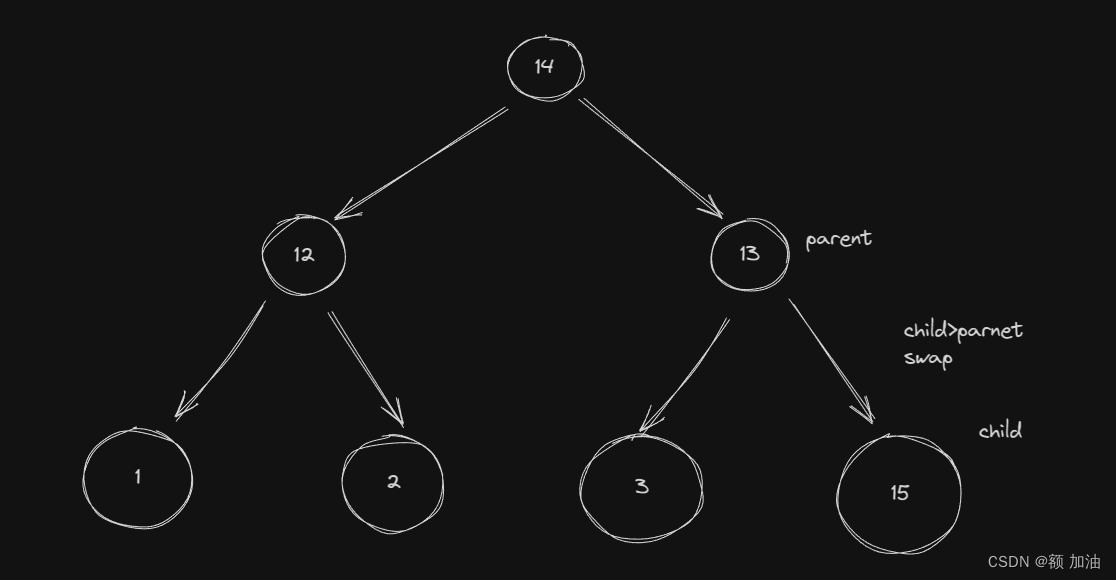 ,这样的交换,不会影响其他地方,由图可知,我们通过对插入元素的调正,将其放到合适的位置,来构成堆(大或者小)
,这样的交换,不会影响其他地方,由图可知,我们通过对插入元素的调正,将其放到合适的位置,来构成堆(大或者小)
void Heap::adjustup(int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (heap[parent] < heap[child])
{
swap(heap[parent] , heap[child]);
}
child = parent;
parent = (child - 1) / 2;
}
}
void Heap::Push(Datatype a)
{
if (_size == _capacity)
{
New_capacity();
}
heap[_size++] = a;
adjustup(_size-1);
}堆的插入操作的时间复杂度为O(log n),其中n是堆中元素的数量。这使得堆成为处理大量动态数据集时的理想选择。
堆的删除操作
在最大堆中,删除操作通常涉及移除根节点,即堆中的最大元素。删除根节点后,为了维持堆的性质,需要执行以下步骤:
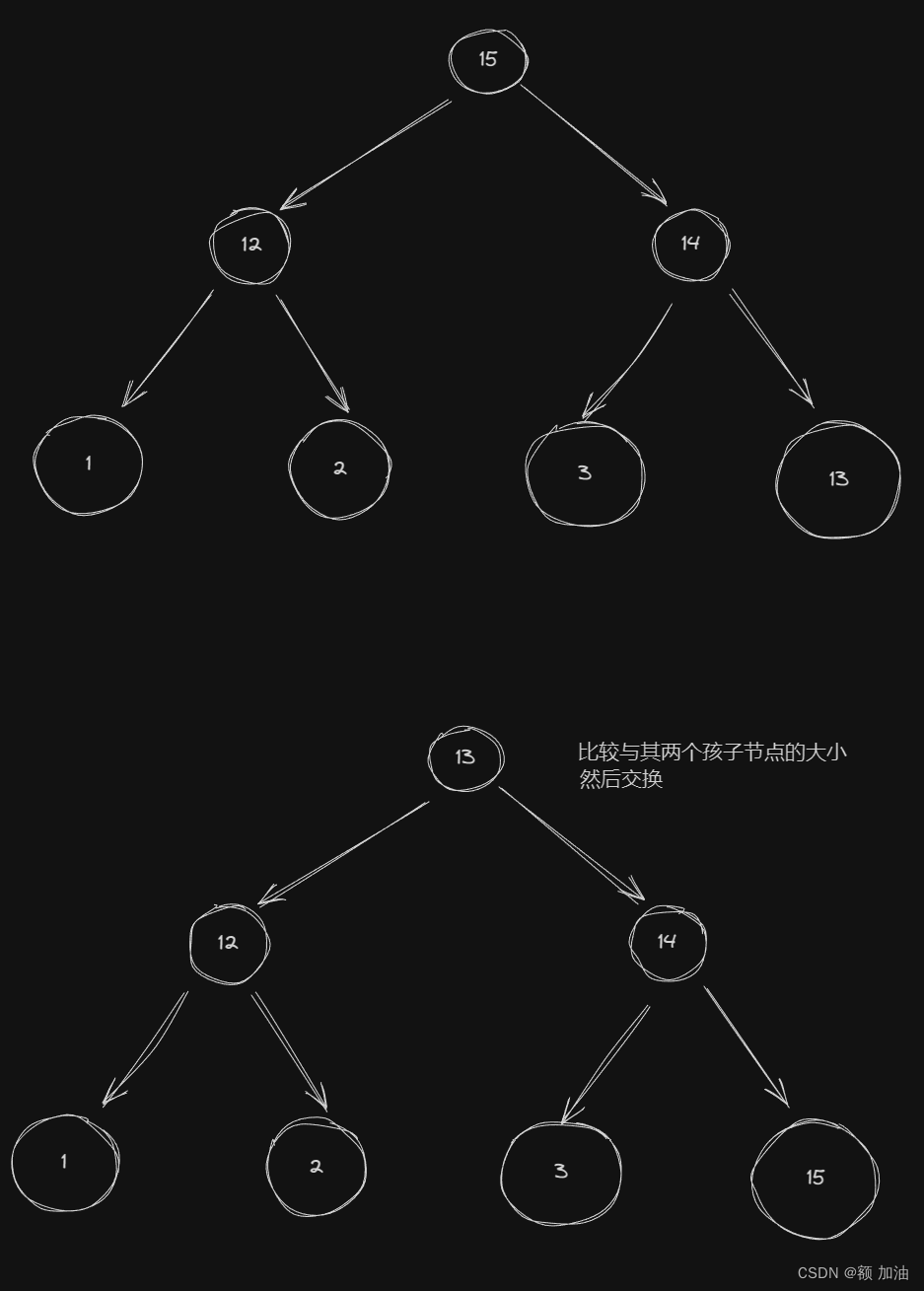
1. 将堆的最后一个元素移动到根节点位置。
2. 删除最后一个元素,减小堆的大小。
3. 对新的根节点执行向下调正,确保恢复堆的性质。
以下是一个简单的C++代码示例,展示了如何在最大堆中执行删除操作:
void Heap::adjustdown()
{
int parent = 0;
int child = parent * 2 + 1;
while (child < _size)//直到遍历完整个堆
{
if (child + 1 < _size && heap[child] < heap[child + 1])
{
child += 1;
}//先进性越界判断,在进行比较,防止越界,程序崩溃
if (heap[parent] < heap[child])
{
swap(heap[parent], heap[child]);
}
parent = child;
child = parent * 2 + 1;//更换孩子,父亲的节点下标
}
}
Datatype Heap::TPop()//输出堆顶数据,也就是最大或者最小数据
{
assert(!Empty());
Datatype temp = heap[0];
swap(heap[0], heap[--_size]);
adjustdown();
/*cout << temp;
return temp;*///调式用
}简易排序
我们可以通过每次将最大或者最小元素交换到最后,或者直接输出(因为每次输出的都是当前数据中最大或者最小的数据),然后整个数据就变的有序了,但是这并不是堆排序,堆排序将时间复杂度运用到极致。
根据上面代码我们可以得到
while (!h.Empty())
{
cout << h.TPop()<<" ";
}
cout << endl;
TOP_K 问题
当我们拥有百万级别的数据时,我们需要找到最大的那个值,或者前几个最大的值,如果我们使用排序,这个时间消耗和空间消耗时难以想象的但是我们可以使用堆,我们利用前10个数据建堆,堆顶就是最小的数据,如果后续数据纯在比他大的,那么就将堆顶数据改变,比他大的那个数据进堆,那么到最后,我们就得到了,10个最大的数据!!
我们先用文件操作写出10000个数据,然后再其中改动10个数据,将其大于100000,用于查看我们的程序是否正确,然后屏蔽掉文件写入数据的代码,防止重复写入

void data()
{
FILE* fp = fopen("data.txt", "w+");
if (fp == nullptr)
{
perror("foprn");
exit(-1);
}
for (int i = 0; i < 10000; i++)
{
int d = rand() % 100000;
fprintf(fp, "%d\n", d);
}
fclose(fp);
}
int main()
{
srand((unsigned int)time(nullptr));
data();
return 0;
}void top_k()
{
Heap top;
FILE* fp= fopen("data.txt", "r+");
int ch = 0;
for (int i = 0; i < 10; i++)
{
fscanf(fp, "%d ", &ch);
top.Push(ch);
}
int flag = 0;
while ((flag=fscanf(fp, "%d ", &ch))==1)//判断是否读完
{
top.TopPush(ch);
}
cout << top;
fclose(fp);
}
int main()
{
srand((unsigned int)time(nullptr));
/*data();*///写完数据后屏蔽
top_k();
return 0;
}堆的实现看似简单,但其背后蕴含着深刻的数据结构和算法原理。它不仅仅是一个数据结构,更是一种算法设计的哲学。通过堆,我们可以看到,如何通过简单的规则和高效的操作,来解决复杂的问题。
如果你对堆或者其他数据结构感兴趣,不妨深入学习和探索。在这个数据驱动的时代,数据结构和算法的知识将是你通往成功的重要钥匙。而堆,无疑是这把钥匙中的精华部分。让我们一起探索堆的奥秘,发现数据结构的美妙世界吧!。
原文地址:https://blog.csdn.net/includemainprinf/article/details/137756130
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!