【Redis】分布式锁及其他常见问题
分布式锁及其他常见问题
1. 我看你的项目都用到了 Redis,你在最近的项目的哪些场景下用到了 Redis 呢?
一定要结合业务场景来回答问题!要是没有不要硬讲,除非面试官问;

接下来面试官将深入发问。
- 你没用到的也可能会试探着去问;
Redis 分布式锁使用的场景?
分布式情况下的,或者集群情况下的,多个微服务操作同一对象,可能是相同操作(同时改),也可能是不同操作(一个删,一个改…)
- 定时任务
- 抢单/秒杀
- 密等性场景
2. 抢卷场景
2.1 分布式问题
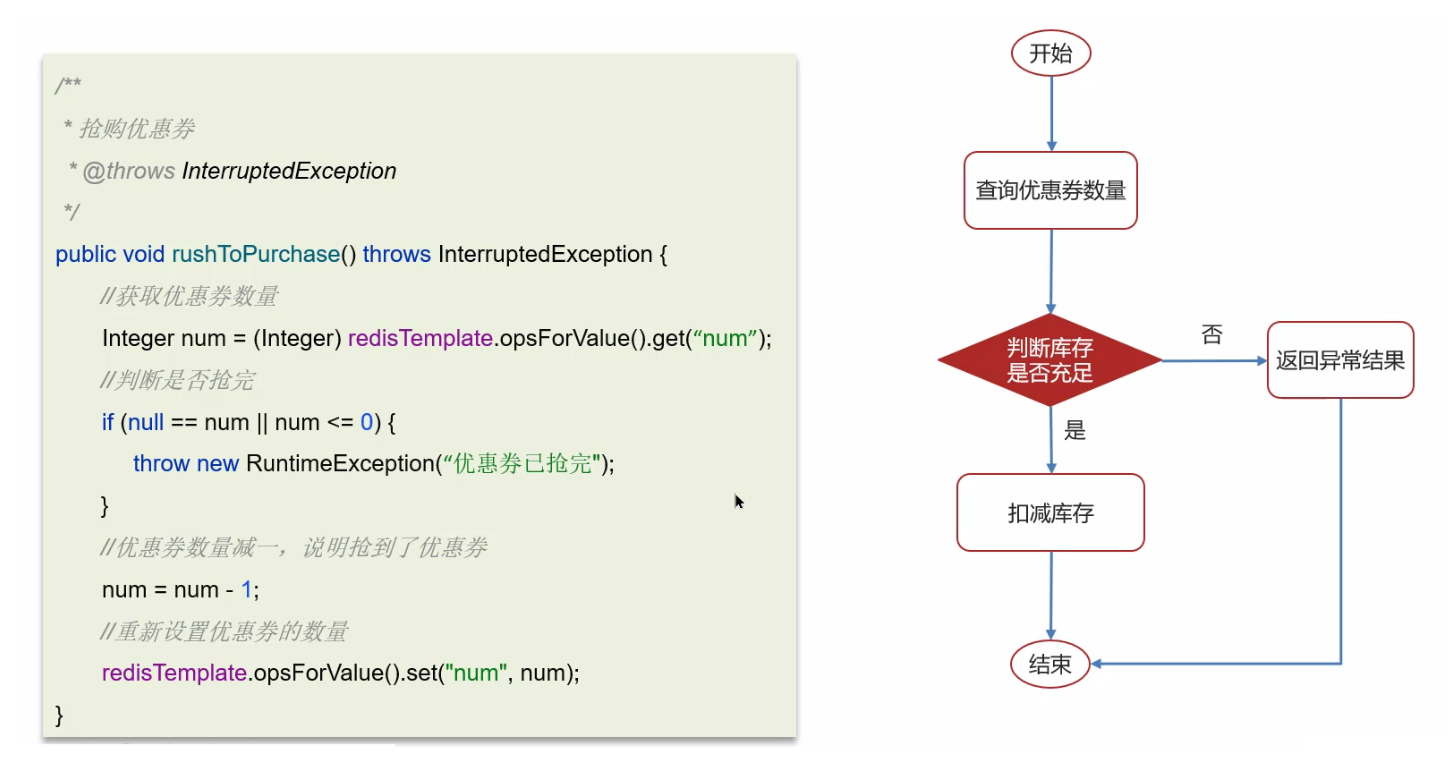
执行流程:
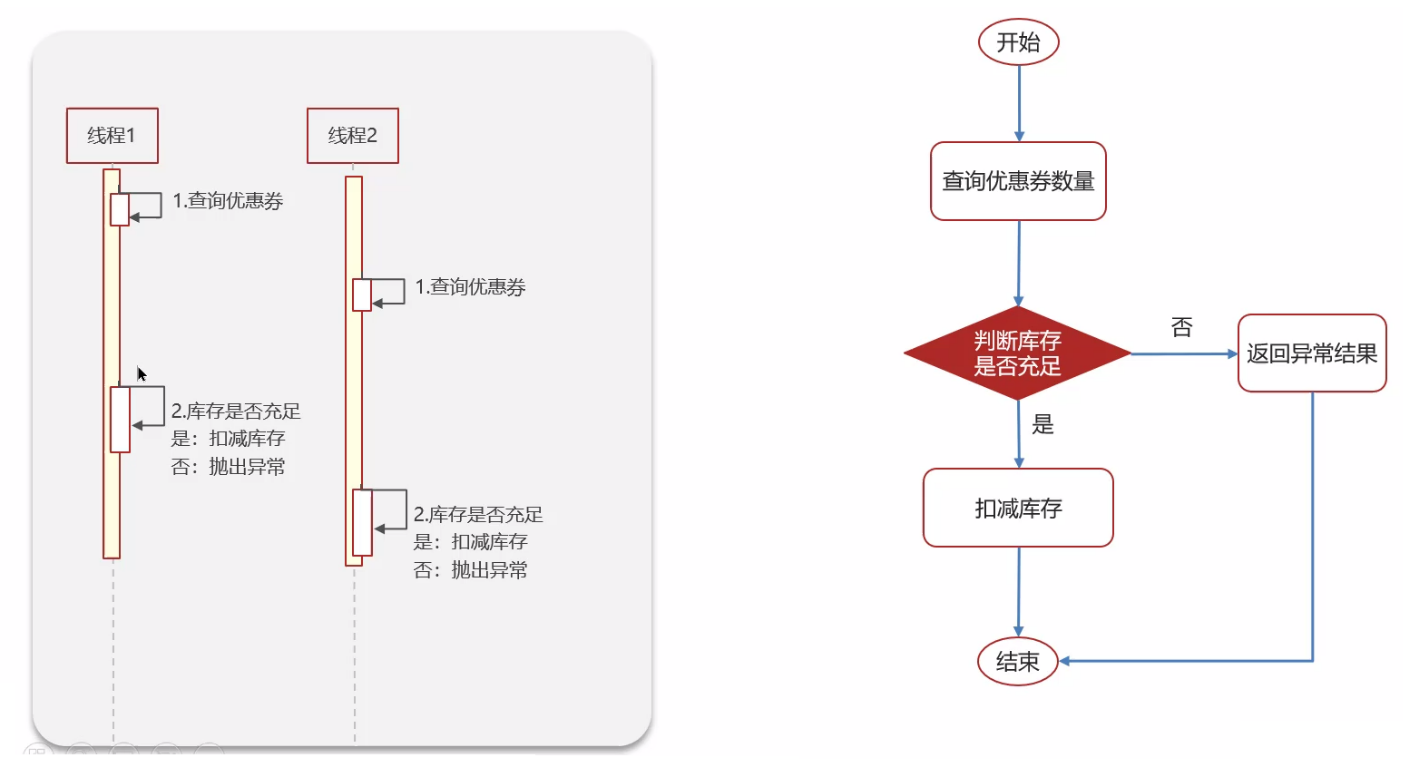
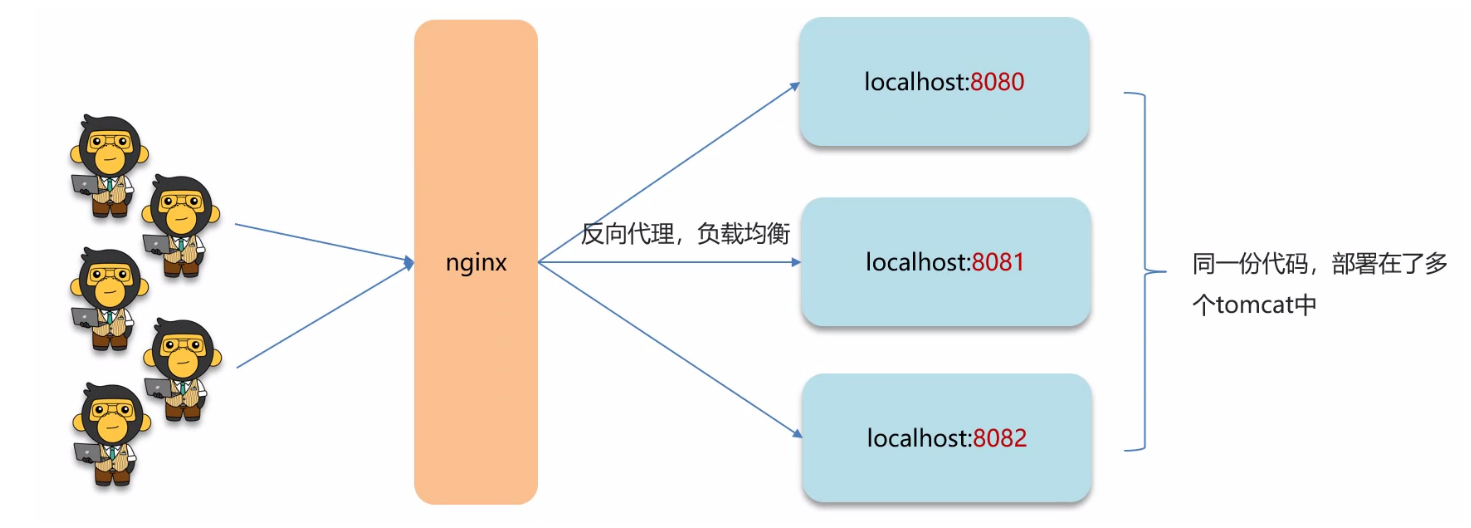
而如果是分布式的项目,就可能对服务进行集群部署:
2.2 synchronized 锁解决问题
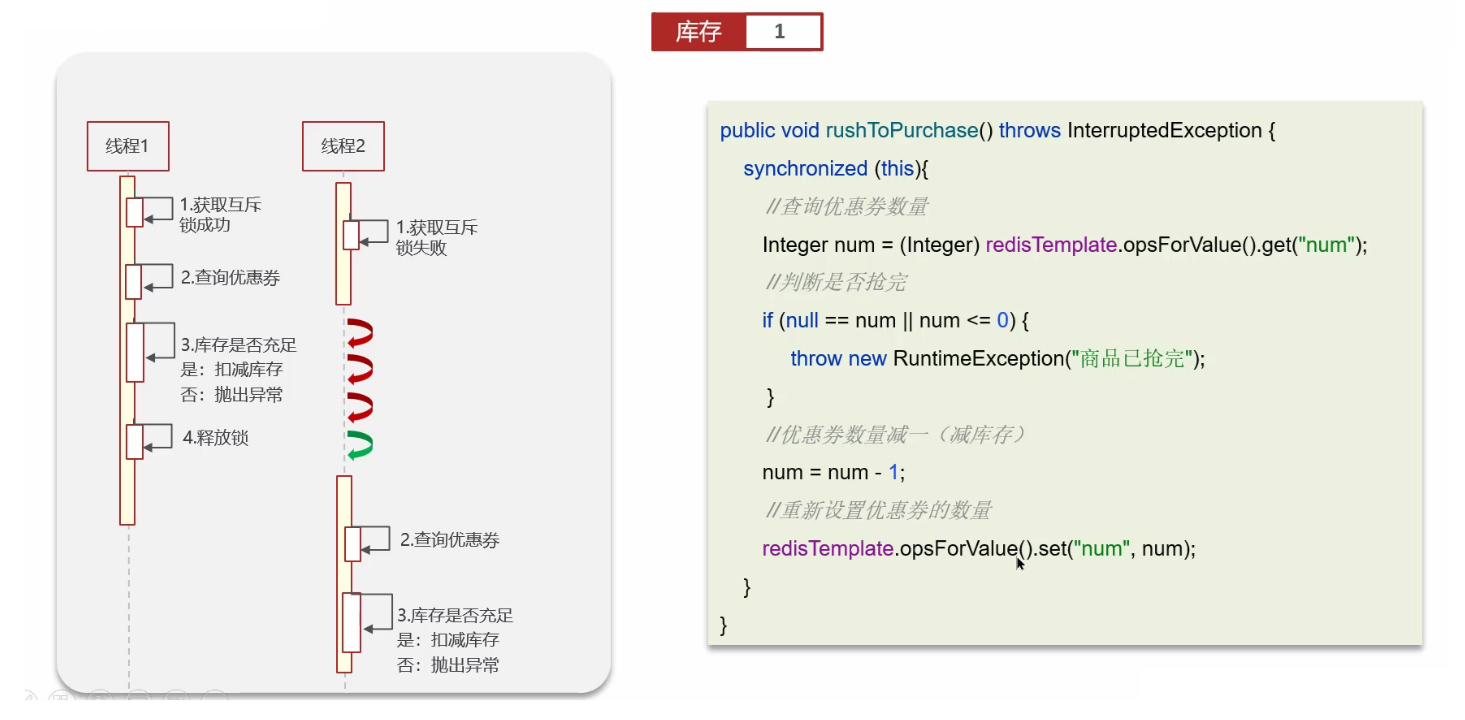
显然这解决不了分布式问题;
只能解决同个 Java 进程的多线程的问题,也就是处理同一个 Java 服务的多个请求的问题;
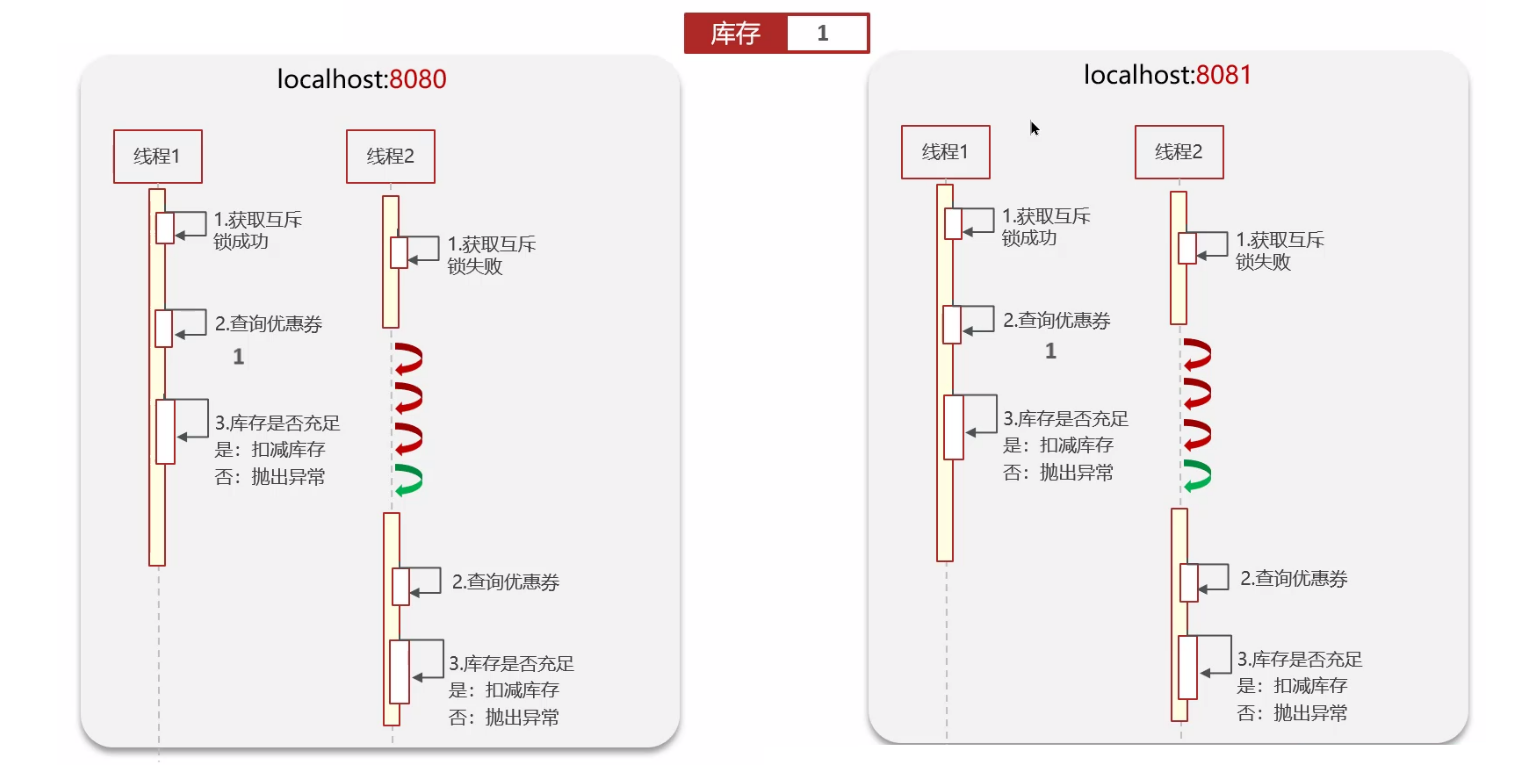
2.3 分布式锁解决问题
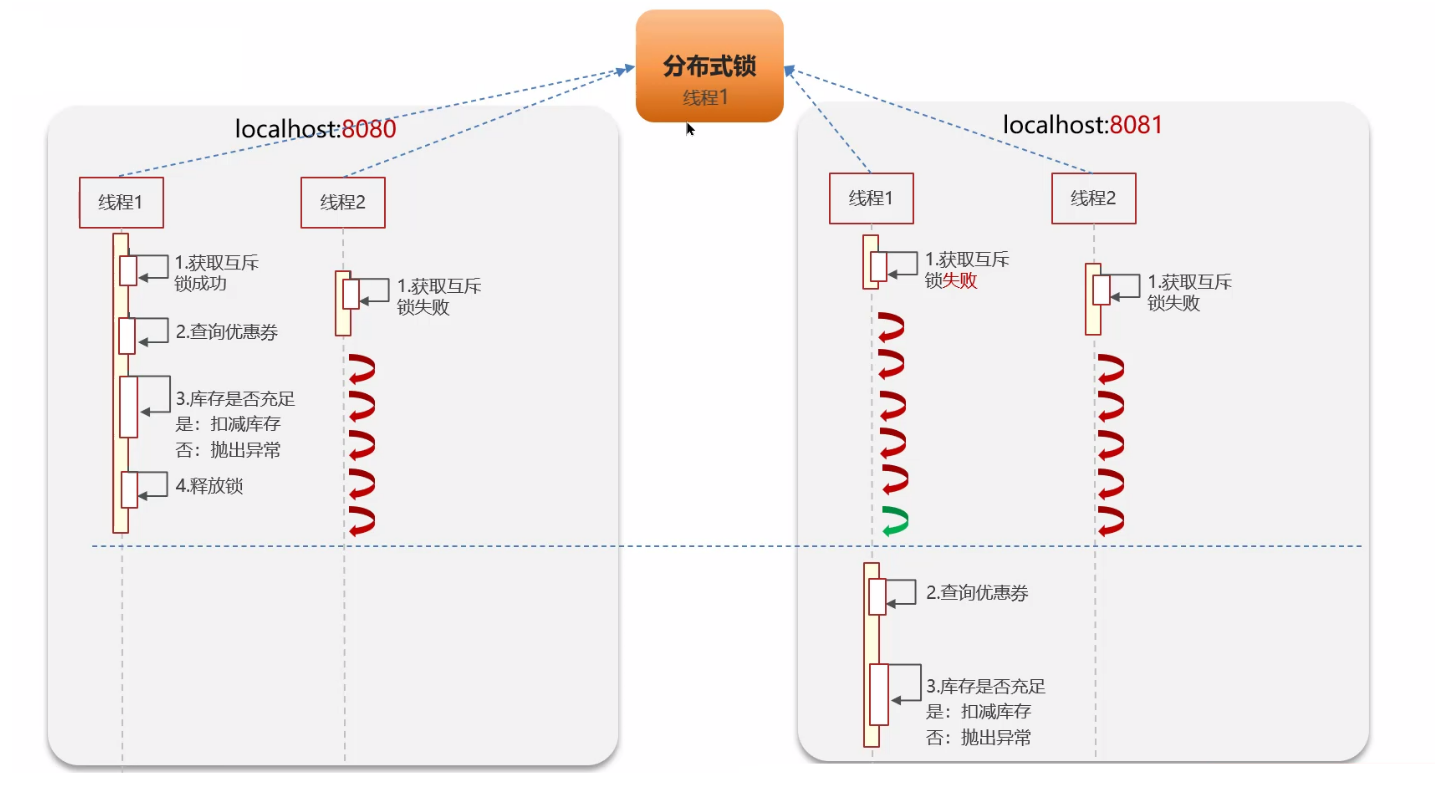
3. 分布式锁的实现原理
Redis 分布式锁其实就是“争夺一个 key 的定义”,主要利用 Redis 的 setnx 命令(SET if **not ex**ists 如果不存在,则设置)


小插曲:锁提前过期,但是业务未结束,锁岂不是可以被其他服务获取了?
其实这个问题可以通过给锁续期来解决,举个例子:
一个分布式锁有效时长是 5 秒,但是业务时长 7 秒,我们可以每隔一段时间,如每个 3 秒 就判断业务是否结束,如果结束了那就释放锁,如果没结束,就重置锁的有效时长,如重置为 5 秒;

4. 程序中怎么使用分布式锁?
分布式锁真的很灵活和精准!
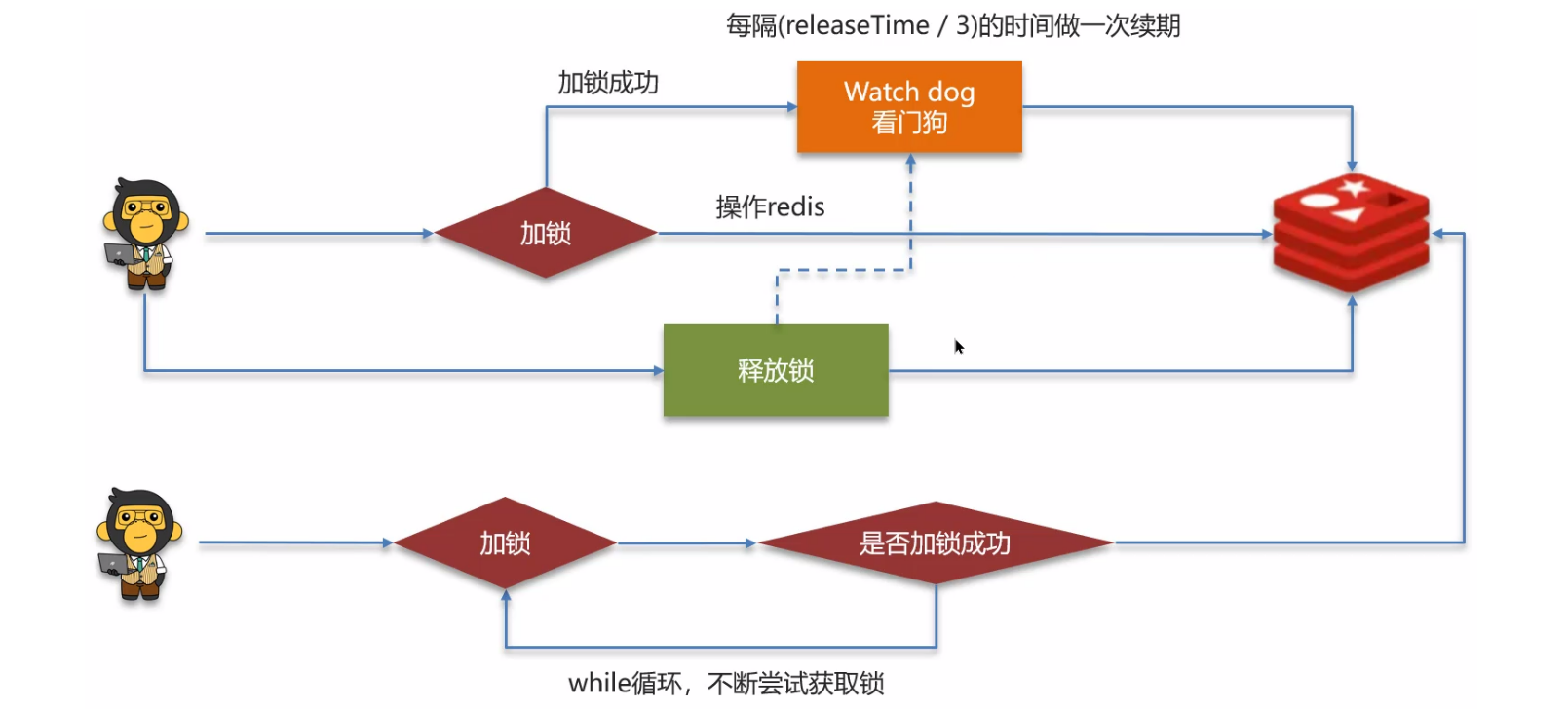
可以使用 redission 框架(加锁、设置过期时间等操作都是基于 lua 脚本,Redis可以识别的可保证原子性的脚本完成),执行流程如下:
示例代码:
- R 在 redisson 中值得就是 Redis 的 R;

RLock 锁是可以重入的锁

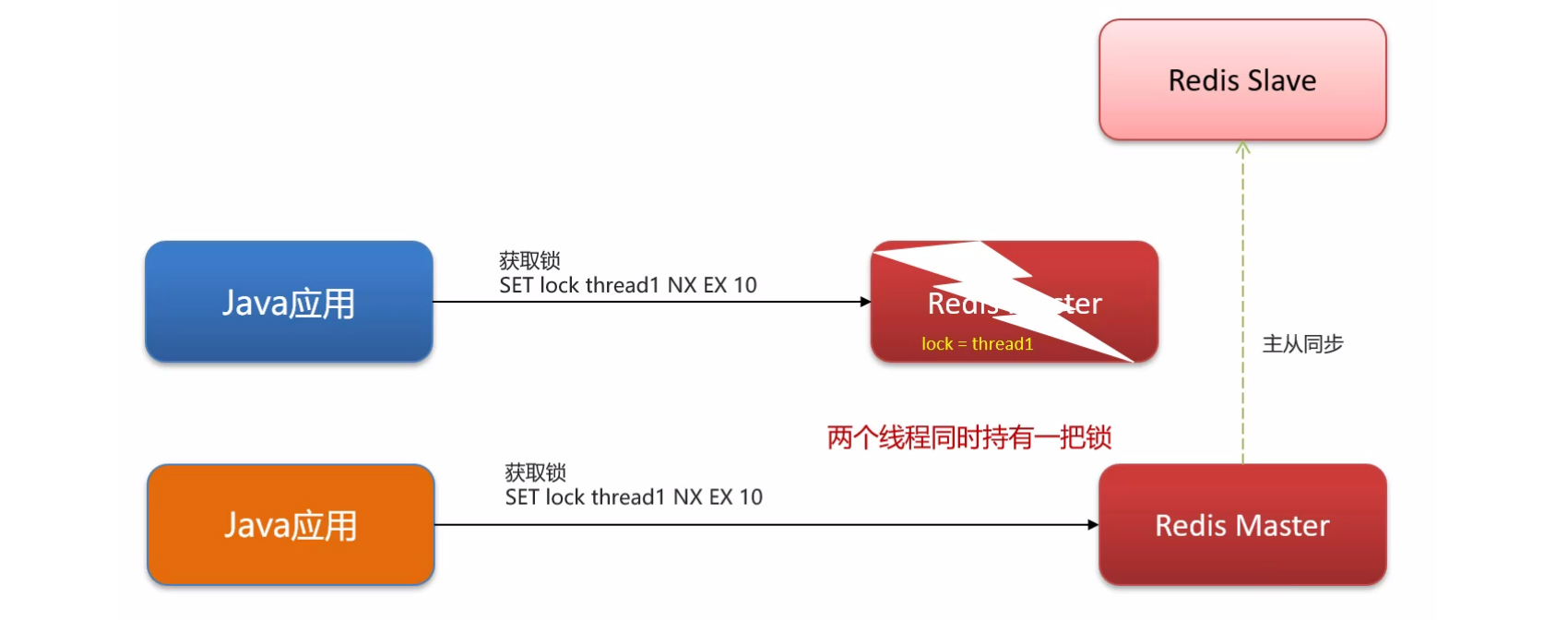
5. 分布式锁主从一致性的问题
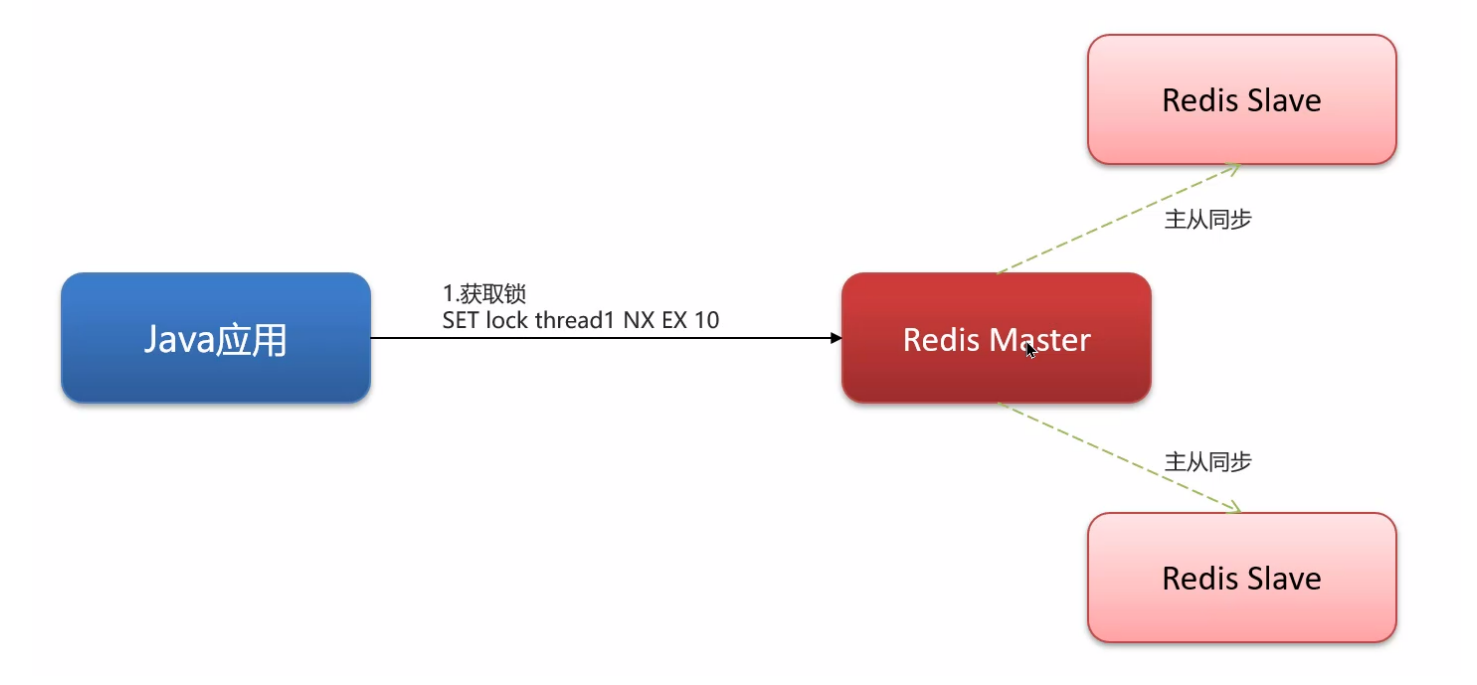
正常情况下,Redis 集群的主从会进行同步,所以不同的 Java 应用访问 Redis 集群的时候,是只有一个应用能获取一把锁;
但是,如果主节点在从节点同步之前挂了,从节点就变成了新的主节点,另一个 Java 应用尝试获取这把锁,发现可以获取成功,就出现了两个线程同时持有一把锁的情况了;
之后,两个线程就没有阻塞的同时进行了。
主从就不一致了,因为从节点只显示正常一个线程获得锁,但实际上是两个线程用了一把锁;
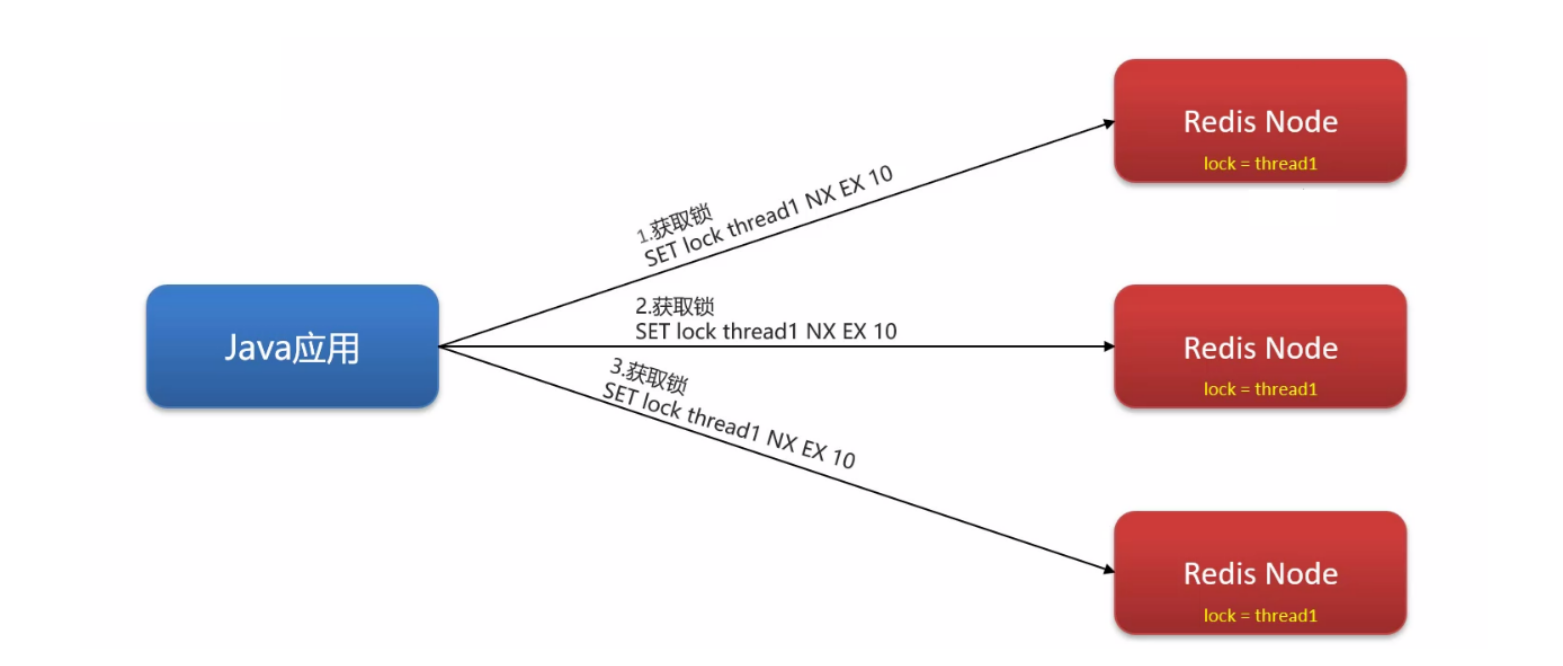
可以使用分布式锁的另一种实现:RedLock(**Red**is)
RedLock(红锁),在多个 Redis 实例上创建锁 (n / 2 + 1),避免在一个 Redis 实例上加锁:
缺点:
- 实现复杂
- 性能差
- 运维繁琐
如果非要解决这个问题,可以用 zookeeper(CP 思想)去解决,而 Redis (AP 思想)更适合根据具体业务实现最终一致性;
Redis 分布式锁,是如何实现的?
- 根据自己简历的项目进行描述分布式锁使用后的场景,如抢票、维持幂等性…
- 我们当时使用的是 redisson 实现的分布式锁,底层是 setnx 和 lua 脚本(保证原子性)
Redisson 实现的分布式锁是如何合理的控制锁的有效时长的?
- 在 redisson 的分布式锁中,提供了一个 ==WatchDog(看门狗)==一个线程获得锁成功以后 WatchDog 会给持有锁的线程**续期(默认是每个 10 秒续期一次)**
Redisson 的这个锁,是可重入锁么?
- 可以重入,多个锁重入需要判断是否是当前线程,在 Redis 中进行存储的时候使用 hash 结构,来存储==线程信息和重入的次数==;
Redisson 的这个锁,能处理主从数据一致的问题吗?
主从数据一致的问题:主节点在从节点同步之前宕机,从节点就被升级为主节点的数据不一致的问题;
处理不了,但是可以用 Redisson 提供的的==红锁来解决,但是这样的话,性能太低了==,如果是 AP,则为我们保证数据的最终一致性即可,如果业务要求 CP,建议采用 zookeeper 实现的分布式锁;
6. Redis 集群有哪些方案?
在 Redis 中提供了三种集群方案:
- 主从复制
- 哨兵模式
- 分片集群
有一些常见的问题:
- Redis 主从数据同步的流程是什么?
- 怎么保证 Redis 的高并发高可用?
- 你们是用 Redis 的单点还是集群,哪种集群?
- Redis 分片集群中数据是怎么存储和读取的?
- Redis 集群脑裂,该怎么解决呢?
6.1 主从复制
主从同步原理:
由于单点 Redis 的并发能力是有上限的,要进一步提高 Redis 的并发能力,就需要搭建主从集群,实现读写分离;
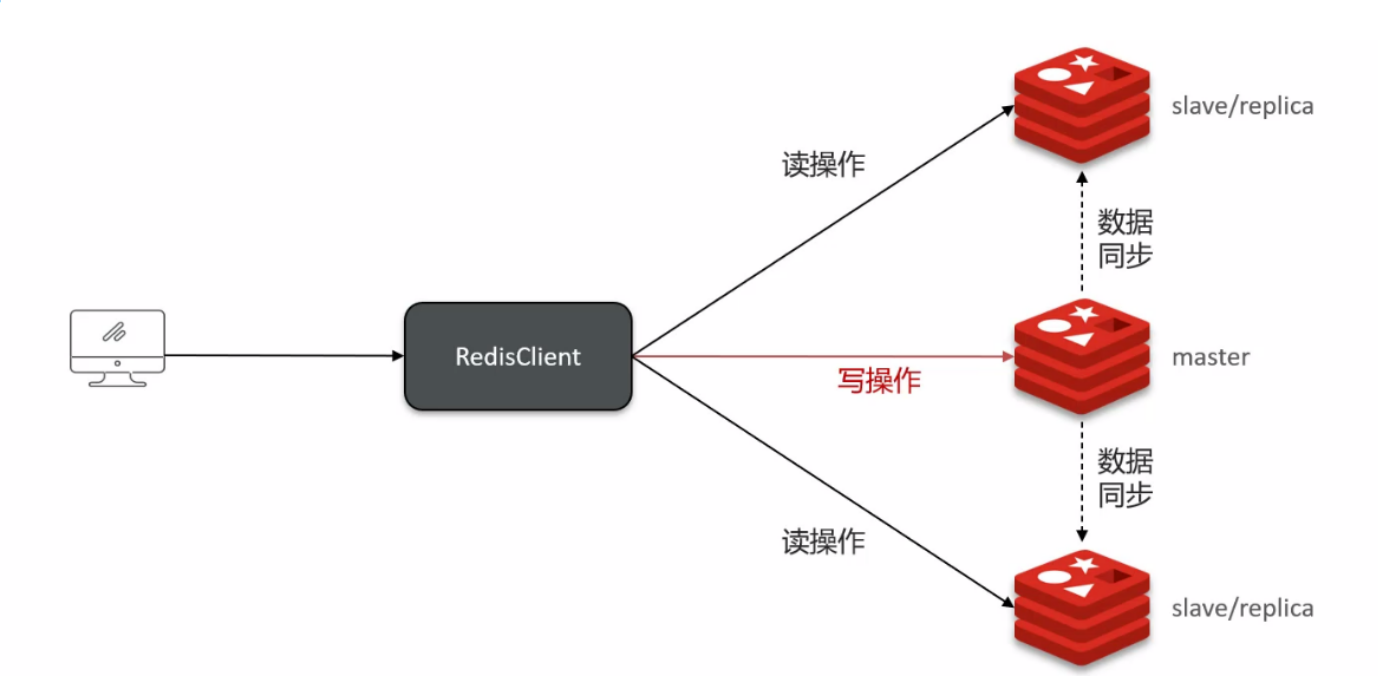
主从全量同步:
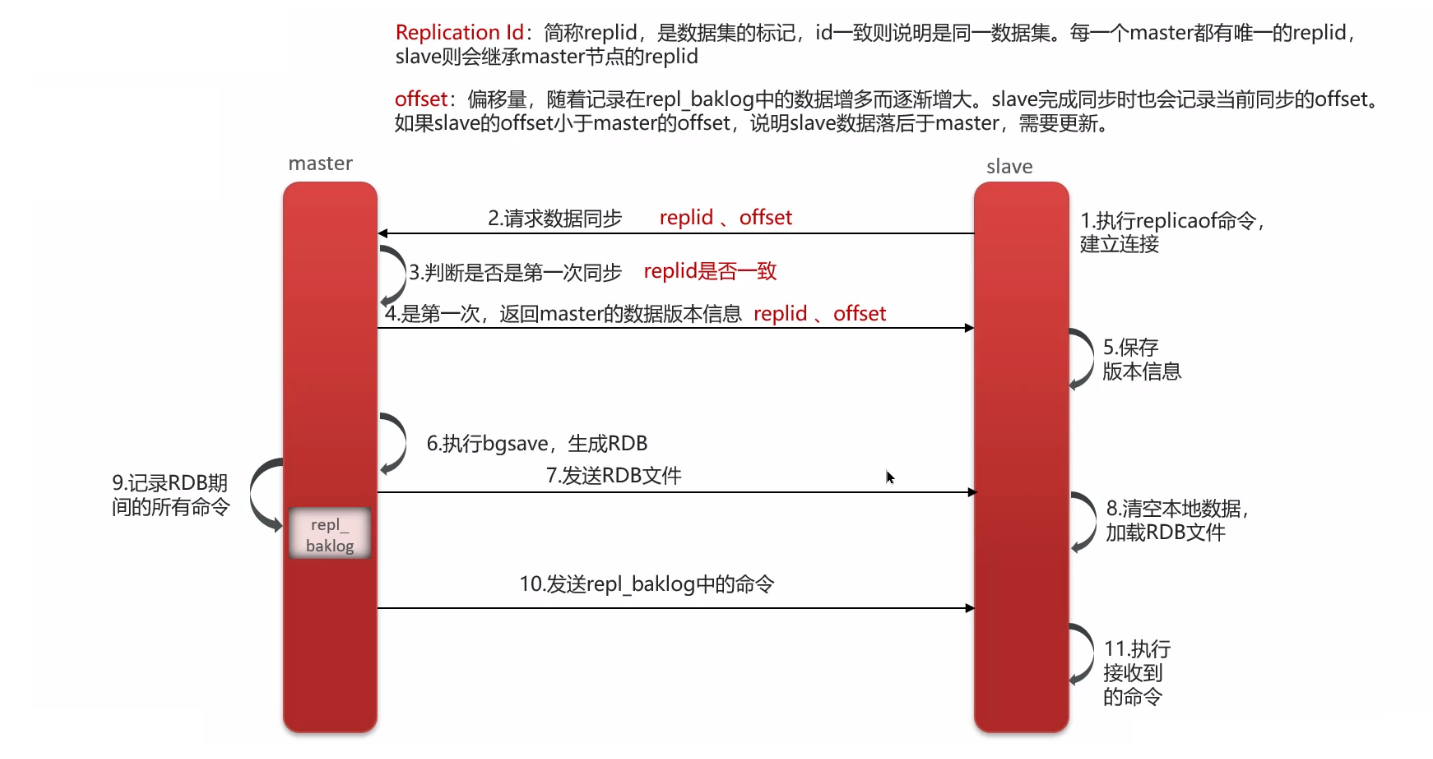
主从增量同步(slave 重启或后期数据变化)
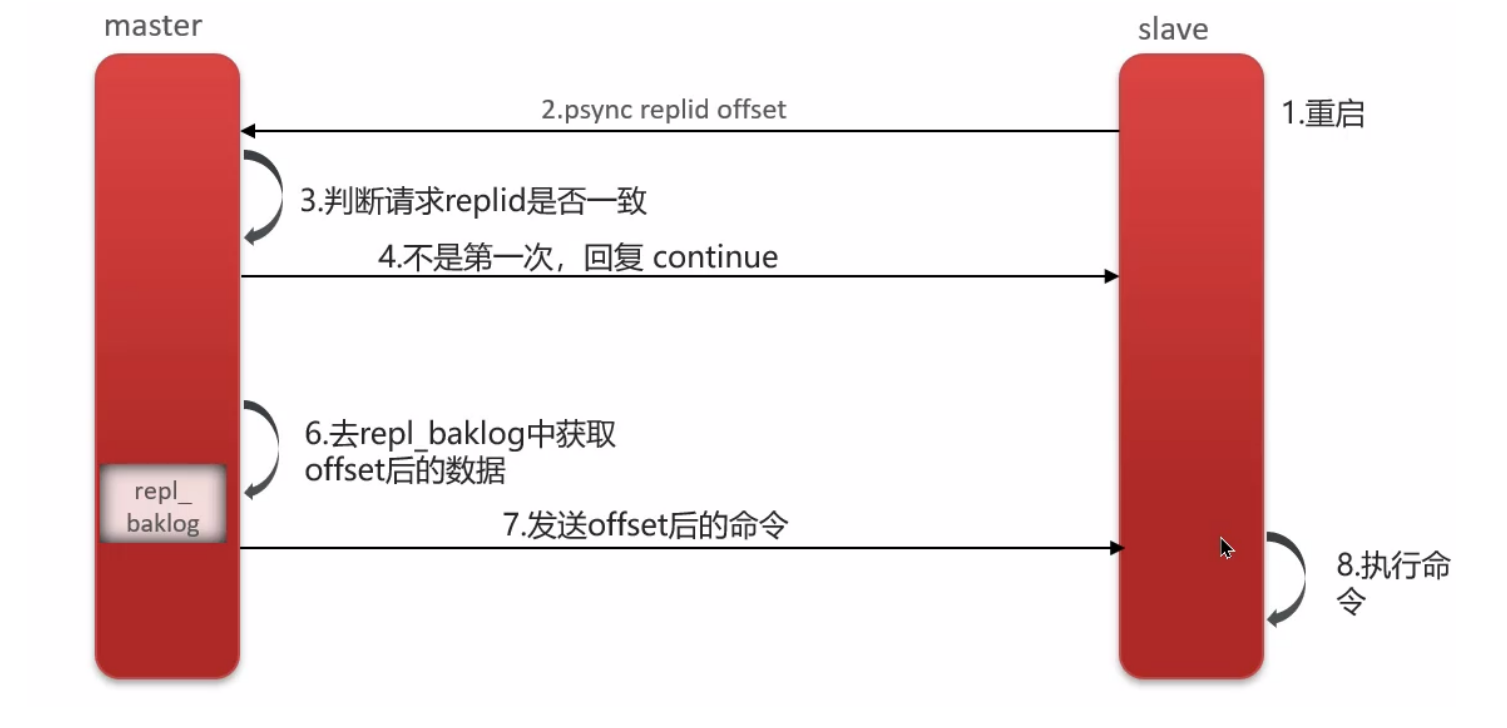
主从同步数据的流程:
- 从节点请求主节点同步数据(replication id、offset)
- replication id 用于判断是否是对应的主节点;
- 主节点判断是否是第一次请求(第一次就是全量同步),发送给从节点同步版本需要的信息(replication id、offset)
- 执行 bgsave,生成 rdb 文件后,发送给从节点去执行;
- 从节点清空数据,加载 rdb 文件(全量同步加载时间可能较长),期间主节点的新增数据以命令的方式记录在缓冲区(一个日志文件)
- 把生成之后的命令日志文件发送给从节点进行同步;
- 之后从节点重启或者日常的同步数据:
- 请求主节点同步数据(replication id、offset)
- 主节点判断是否是第一次请求(不是第一次就是增量同步),根据 offset 获取 offset 之后的命令文件,发送给从节点;
- 从节点执行命令进行数据同步;
6.2 哨兵模式
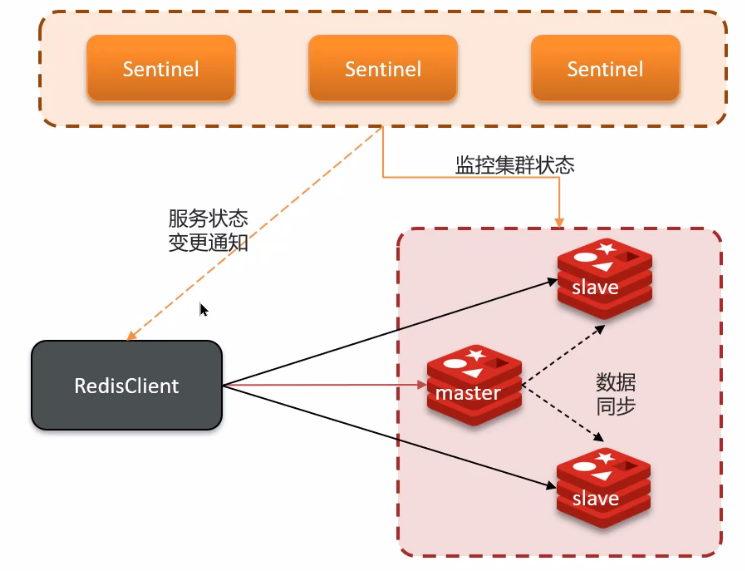
Redis 提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。哨兵的结构和作用如下:
- 监控:Sentinel 会不断检查您的主从系欸但是否按预取工作;
- 自动故障恢复:如果主节点故障,Sentinel 会选取一个从节点为新的主节点,故障实例恢复后作为从节点以新的主节点为主;
- 通知:Sentinel 充当 Redis 客户端的服务发现来源,当集群发生故障转移的时候,会将最新的信息推送给 Redis 客户端,也就是说之后的客户端能正确拉取 Redis 服务;
状态监控的相关细节:
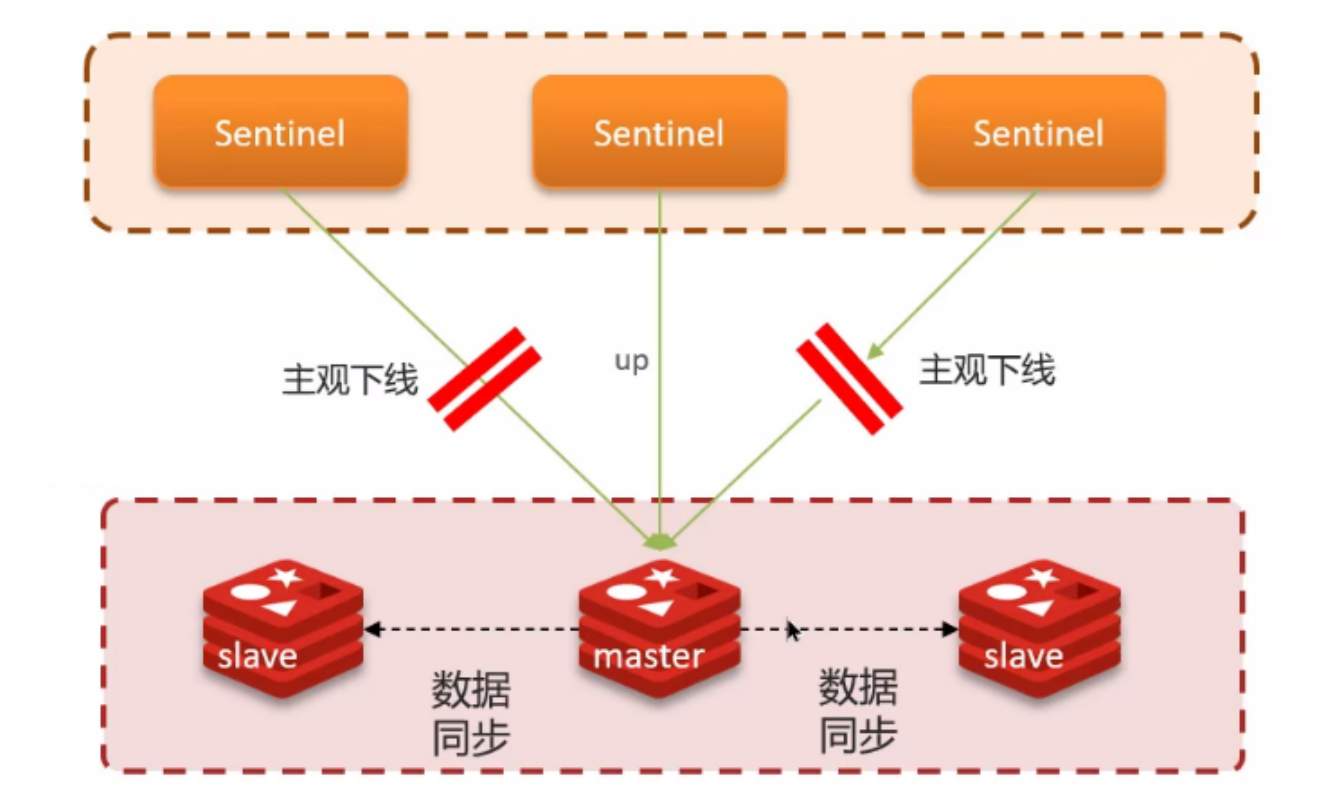
- Sentinel 基于心跳机制检测服务状态,每隔一秒向集群的每个实例发送 ping 命令;
- 主观下线:如果某个 Sentinel 节点发现某实例未在规定时间响应,则认为该实例主观下线;
- Sentinel 有集群,但是没有主从之分,没有“Sentinel 监控 Sentinel 的套娃”🤣
- 客观下线:若超过指定数量(quorum)的 Sentinel 主观认为该实例下线,则该实例客观下线;
- quorum 最好超过 Sentinel 实例数量的一半;
哨兵选主规则:
- 首先,判断主从节点断开时间长短,如果超过指定值就排除该从节点(主节点都挂了,从节点断开连接太慢,太迟钝的节点直接不要);
- 其次,判断从节点的 slave-priority 值,越小优先级越高;
- 如果 slave-priority 相等,则判断 offset 值,越大优先级越高(越大代表数据同步率高);
- 大部分情况下是通过这个判断出来的;
- 最后,判断从节点的运行 id 大小,越小优先级越高;
脑裂:
正常情况下:
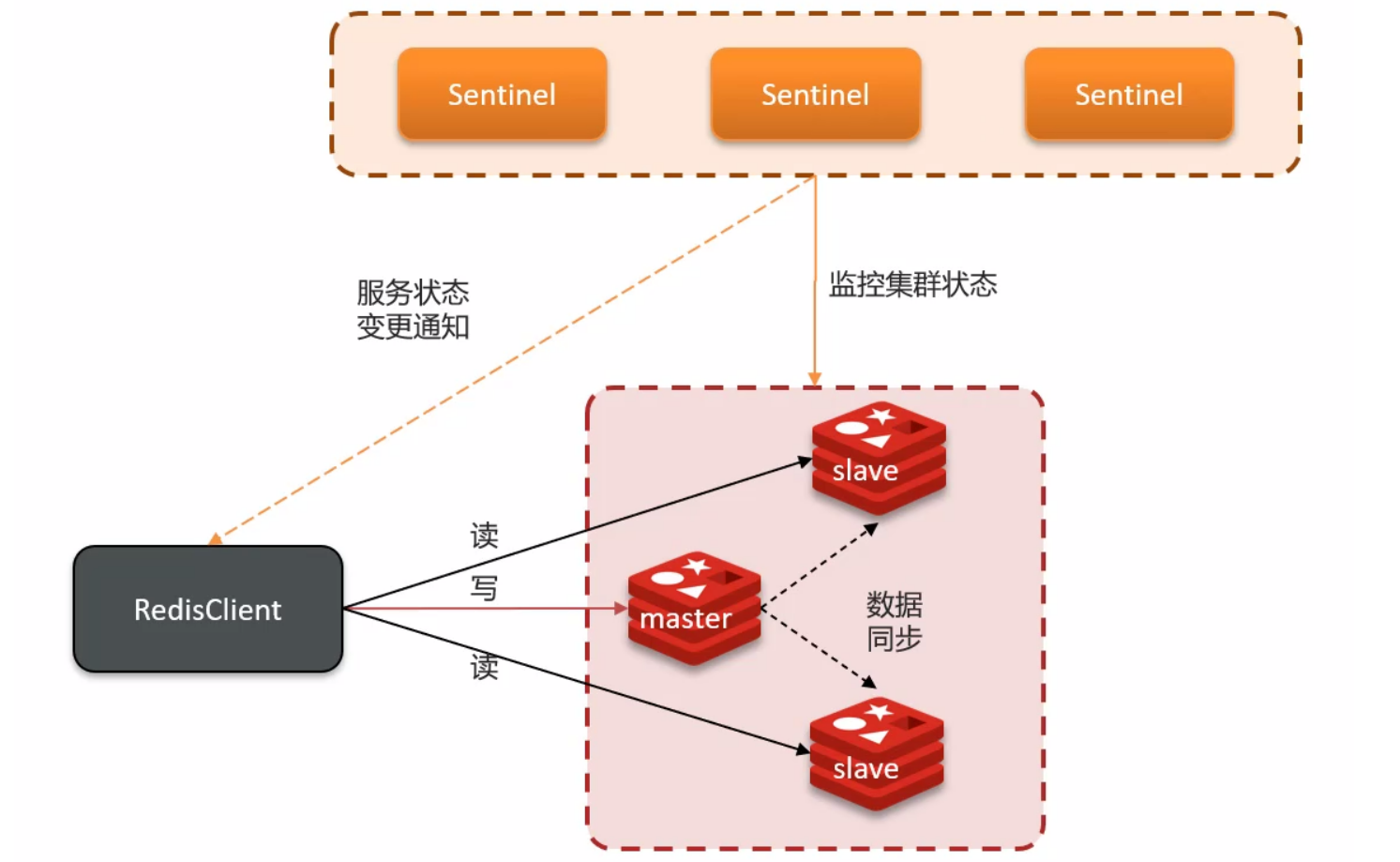
由于网络原因,主节点与哨兵在不同的网络分区,哨兵不再监控主节点,那哨兵就会觉得主节点挂了,重新选择一个主节点,那就同时存在两个主节点了!(也就是 Redis 的主节点大脑分裂了)
客户端连接的是旧的主节点,客户端会一直写入旧的主节点,因为旧的主节点没有从节点,期间客户端读的是旧的主节点,而新的主节点的从节点一直没有同步数据;
网络恢复前,旧的主节点也不知道新的主节点那边的数据;
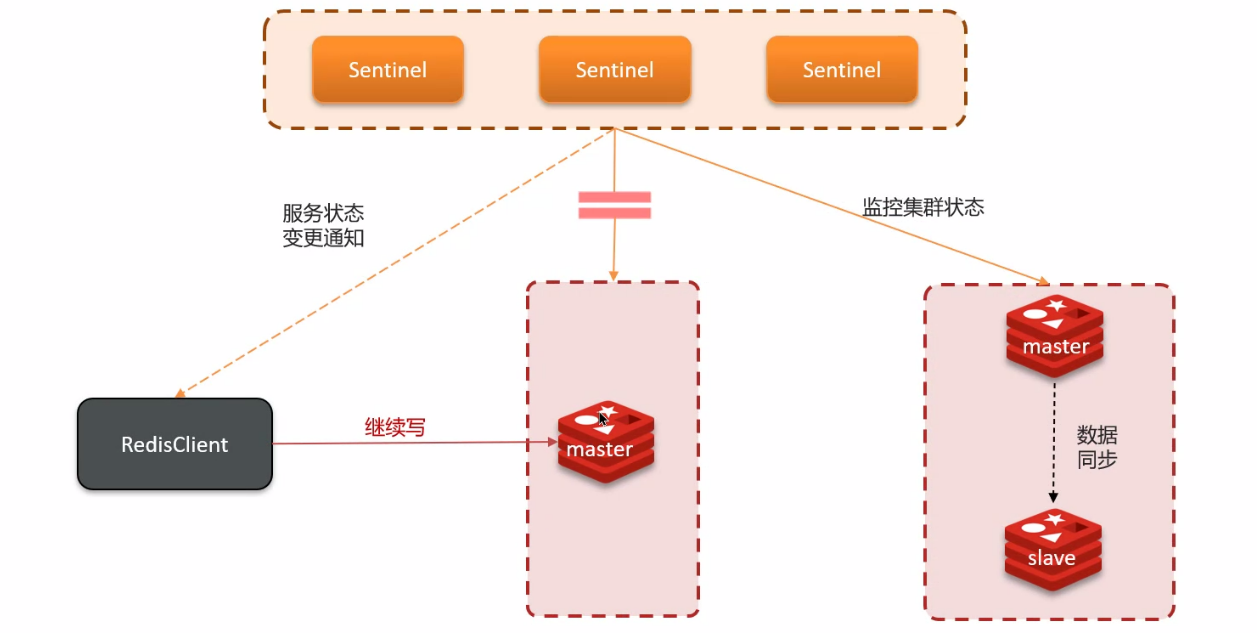
网络恢复后,会将旧的主节点强制转为从节点,会从新的主节点同步数据,那么期间旧的主节点的新增数据将直接丢失;
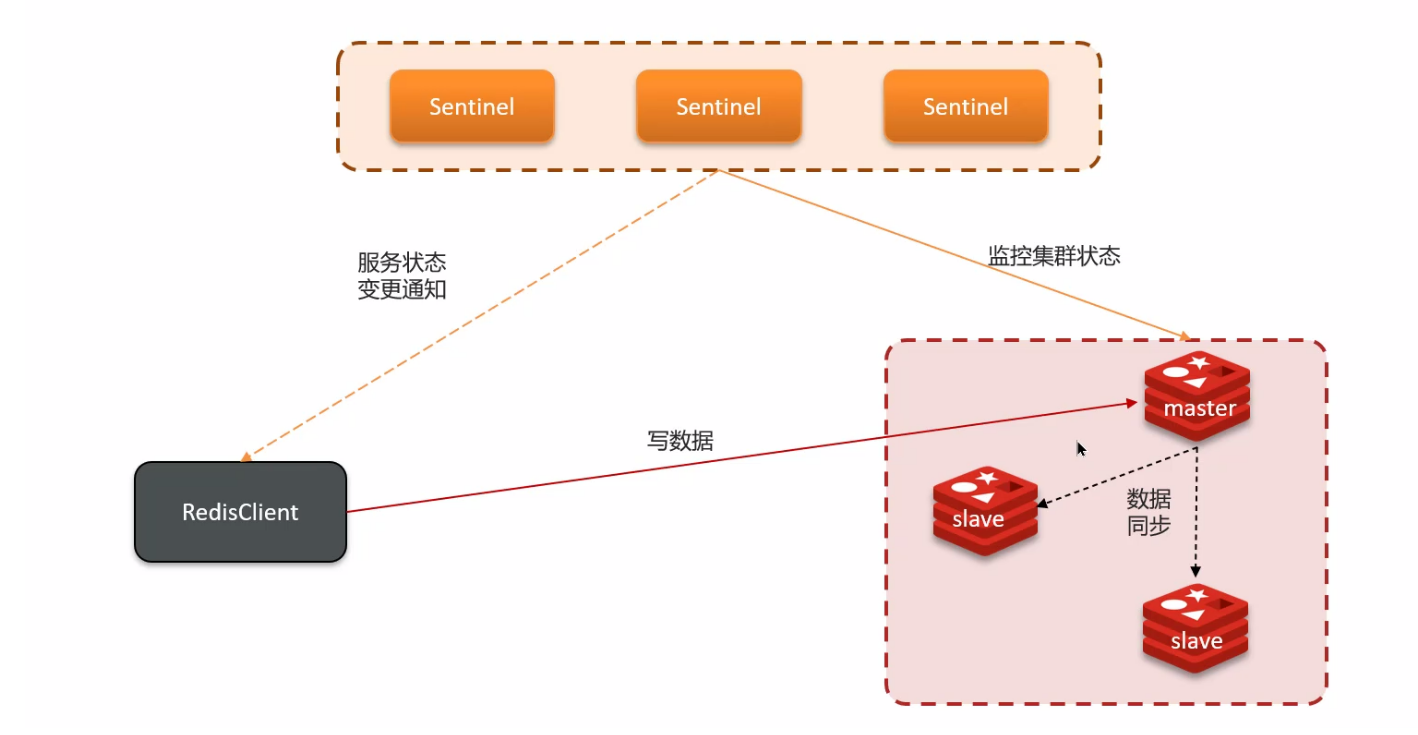
解决/缓解的方案:
- min-replicas-to-write 1 表示最少的从节点为一个
- 如果主节点没有从节点,不可信;
- min-replicas-max-lag 5 表示数据复制和同步的延迟不能超过 5 秒,否则拒绝请求;
- 也就是说,本次请求距离上次同步,不能超过 5 秒;
怎么保证 Redis 高并发下的高可用:
- 哨兵模式:实现主从集群的自动故障恢复(监控、自动故障恢复、通知)
规模不算很大的项目,用主从 + 哨兵就够了:一主一从一哨兵,顺便预防一下脑裂,单节点不超过 10 G 内存,如果 Redis 内存不足则可以给不同服务分配独立的 Redis 主从节点;
- 也就是一个需要很大的服务,单独去使用一个 Redis 主从集群,不与其他服务共用;
- 不同项目则一般用不同的 Redis,避免 key 冲突,当然同一个项目的服务也会出现冲突的问题,但是同一个项目较容易的去控制和管理;
Redis 集群脑裂的现象如何解决?
- 我们可以修改 Redis 的配置,可以设置最少的从节点数、缩短主从数据同步的延迟时间,达不到要求就拒绝请求,这样可以避免 Redis 大量数据的丢失;
6.3 分片执行
主从+哨兵可以解决高可用的高并发读的问题,但是依旧存在两个问题:
- 海量数据存储问题
- 高并发写的问题
使用分片集群可以解决上述问题,分片集群特征:
- 集群中有多个主节点,每个主节点保存不同数据;
- 每个主节点,可以有多个从节点(主从复制);
- 主节点之间相互通过心跳,检测彼此的健康状态(不需要通过哨兵);
- 客户端请求可以访问集群的容易节点,最终都会被转发给正确的节点;
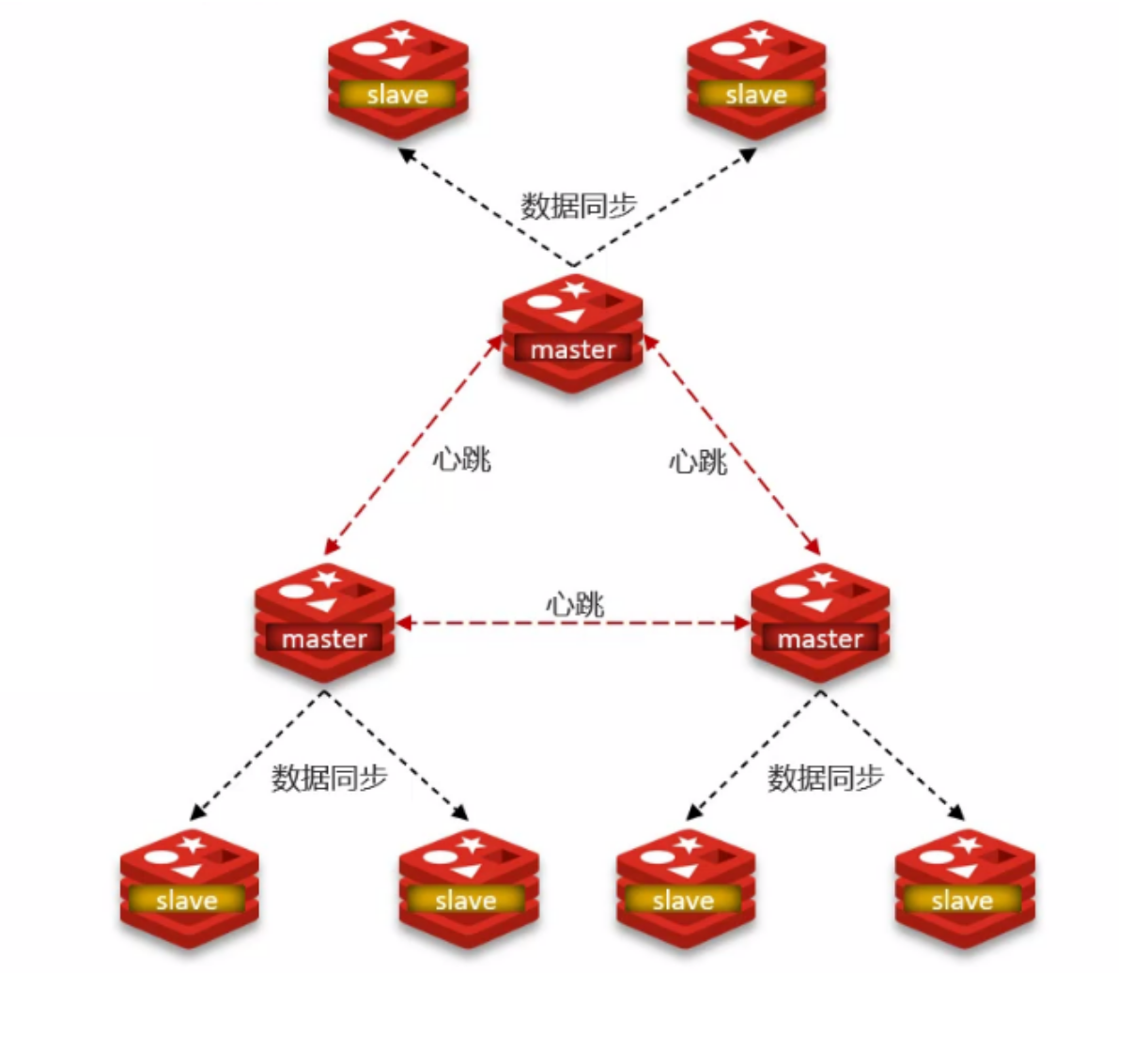
数据读写:
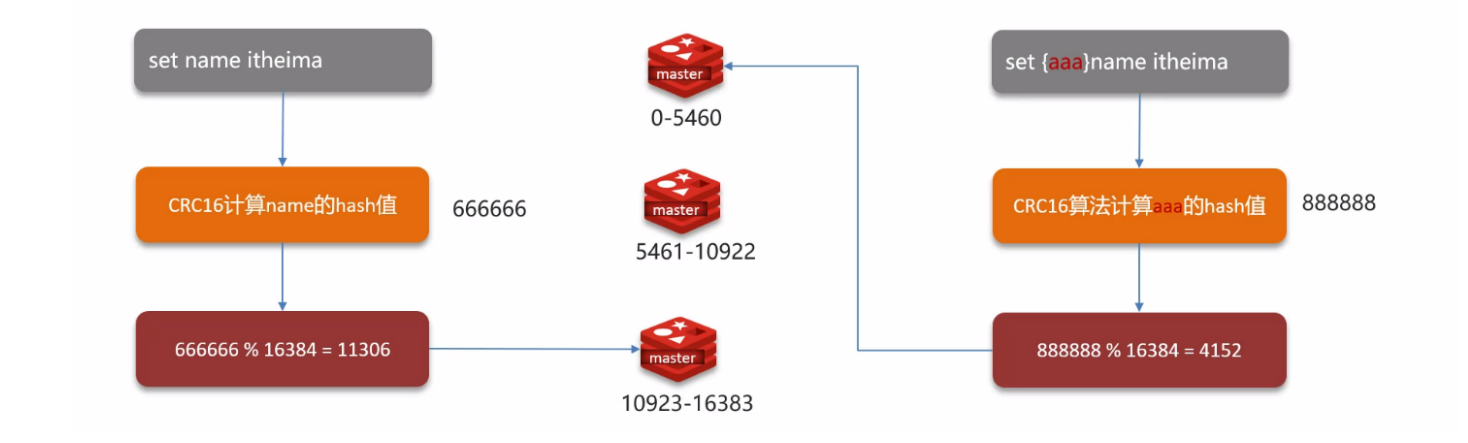
Redis 分片集群引入了哈希槽的概念,Redis 集群有 16384 个哈希槽,每个 key 通过 CRC 16 校验后对 16384 取模,取模的结果就是插槽,找到插槽对应的哈希槽实例,集群的每个节点负责一部分哈希槽;
- 读操作用同样的方式寻找 key 的插槽并找到对应的值;
补充:根据的是 key 的有效部分,如果 key 前面有大括号,大括号包裹的就是有效部分,否则 key 本身就是有效部分;还有就是,这个只是确定在哪个哈希槽,最终获取 key 的值还是要通过 key 本身,也就是获取值的时候还是要通过 {aaa}key;
7. Redis 是单线程的,但是为什么还是那么快

- Redis 是纯内存操作,执行速度非常快;
- 采用单线程,避免不必要的上下文切换,多线程还要考虑多线程安全问题,比如使用各种锁;
如果 Redis 底层用到锁,与用 Redis 分布式锁是不一样的;
Redis 分布式锁并不是解决 Redis 的线程安全问题,而是解决业务的线程安全问题,因为多次发送给 Redis 的操作不能保证原子性的,多线程的话可能会导致 Redis 操作的顺序里穿插了别的线程的 Redis 操作;
所以要用 Redis 事务保证一串 Redis 写操作的原子性:
redisTemplate.execute(new SessionCallback() { @Override public Object execute(RedisOperations redisOperations) throws DataAccessException { redisOperations.multi(); // runnable 方法中的 Redis 操作,得用这里同一个 redisTemplate 去操作 Redis 的代码才能被放入事务块 runnable.run(); return redisOperations.exec(); } });当然,如果是抢票之类的场景,还是要用 Redis 分布式锁;
- Redis 使用 I/O 多路复用模型,非阻塞 IO;
8. I/O 多路复用模型(了解)

原文地址:https://blog.csdn.net/Carefree_State/article/details/137385309
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!