【python爬虫】携程旅行景点游客数据分析与可视化
一.选题背景
随着旅游业的快速发展,越来越多的人选择通过互联网平台预订旅行产品,其中携程网作为国内领先的在线旅行服务提供商,拥有大量的旅游产品和用户数据。利用爬虫技术可以获取携程网上各个景点的游客数据,包括游客数量、游客来源地、游客年龄段、游客满意度等信息。通过分析这些数据,可以为景点的管理者提供客流量预测、市场分析、产品改进等方面的参考,也可以为旅游从业者提供市场营销、产品开发等方面的参考。因此,选题背景是基于爬虫技术获取携程网景点游客数据,分析这些数据对于旅游行业和景点管理的意义,为旅游行业的发展和景点的管理提供参考。
二.主题式网络爬虫设计方案
数据来源:三亚亚龙湾热带天堂森林公园游玩攻略简介,三亚亚龙湾热带天堂森林公园门票/地址/图片/开放时间/照片/门票价格【携程攻略】 (ctrip.com)
1.名称:携程旅行景点游客数据分析与可视化
2.爬取的数据内容:携程网旅游景点的用户评论内容、评论IP属地
3.爬虫设计方案概述:本次案例使用request对携程网景点页面进行爬取,使用xlutils对excel文件进行处理,之后使用pandas、pyecharts、jieba对数据进行可视化
4.技术难点:携程网上的景点数据庞大,需要爬虫技术能够高效地获取和处理大量数据,同时要考虑到数据更新的频率和实时性,也要预防访问检测。
三.主题式页面结构分析
1.页面结构
(1)搜索栏、导航栏位于页面顶部
(2)评论区位置包裹于页面中间部分(要爬取的部分)
(3)页面底部显示其它信息

2.页面结构解析

(1)<div id = "commentModule">评论区整体位置
(2)<div class="commentList">评论区内容列表
(3)<div class = "contentInfo">评论区评论信息元素
节点(标签)查找方法与遍历方法
for循环迭代遍历
四.网络爬虫设计
1.爬取到的数据

2.代码实现
将爬虫方法封装为类Spider_XieCheng,在对爬取到的数据进行逐条解析时顺便进行数据清洗
get_data方法:设置请求头以及规则和cookie,发起请求,获取响应数据
analyze_data方法:对传入的数据进行逐条解析,把IP属地的空值和特殊地区进行处理(提前进行数据清洗以方便后面数据可视化绘制地图)
save_excel方法:将传入的数据存储到excel
1 import requests
2 import xlrd, xlwt, os
3 from xlutils.copy import copy
4 import time
5
6 class Spider_XieCheng(object):
7 def __init__(self):
8 self.data_id = 0
9
10 #发起请求获取响应数据
11 def get_data(self):
12 pages = 100 # 页数设置(一页10个游客)
13 for page in range(1, int(pages) + 1):
14 url = 'https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList'
15 cookies = {
16 'MKT_CKID': '1701184519791.j1nes.9ll0',
17 'GUID': '09031019117090895670',
18 '_RSG': 'B2KZgmdz1O8o4Y4R.sklxB',
19 '_RDG': '28e94143a9de482aae2e935bd882f5ef15',
20 '_RGUID': '8601f67c-2a8d-408b-beef-bb6f9b122132',
21 '_bfaStatusPVSend': '1',
22 'UBT_VID': '1701184519782.37bb85',
23 'MKT_Pagesource': 'PC',
24 'nfes_isSupportWebP': '1',
25 '_ubtstatus': '%7B%22vid%22%3A%221701184519782.37bb85%22%2C%22sid%22%3A2%2C%22pvid%22%3A3%2C%22pid%22%3A600002501%7D',
26 '_bfaStatus': 'success',
27 'ibulanguage': 'CN',
28 'ibulocale': 'zh_cn',
29 'cookiePricesDisplayed': 'CNY',
30 'cticket': '0CDDE357337AEC6A065861D35A34D9162AA75BCB8063AE80366ACD8D40269DA2',
31 'login_type': '0',
32 'login_uid': 'CC94CD2D359B73CD9CC2E002839E204163EA360CBAD672051EAA872D50CC7913',
33 'DUID': 'u=0AE96CC05C93DD44B84C2281D96800D1&v=0',
34 'IsNonUser': 'F',
35 'AHeadUserInfo': 'VipGrade=0&VipGradeName=%C6%D5%CD%A8%BB%E1%D4%B1&UserName=&NoReadMessageCount=0',
36 '_resDomain': 'https%3A%2F%2Fbd-s.tripcdn.cn',
37 '_pd': '%7B%22_o%22%3A6%2C%22s%22%3A11%2C%22_s%22%3A0%7D',
38 '_ga': 'GA1.2.652696142.1702191431',
39 '_gid': 'GA1.2.323708382.1702191431',
40 '_RF1': '2409%3A895e%3Ab451%3A620%3A8c52%3Ad1d7%3Aa25d%3A6909',
41 '_ga_5DVRDQD429': 'GS1.2.1702191431.1.0.1702191431.0.0.0',
42 '_ga_B77BES1Z8Z': 'GS1.2.1702191431.1.0.1702191431.60.0.0',
43 'MKT_CKID_LMT': '1702191445465',
44 'Union': 'OUID=xc&AllianceID=4897&SID=799748&SourceID=&createtime=1702191446&Expires=1702796246013',
45 'MKT_OrderClick': 'ASID=4897799748&AID=4897&CSID=799748&OUID=xc&CT=1702191446014&CURL=https%3A%2F%2Fhotels.ctrip.com%2F%3Fallianceid%3D4897%26sid%3D799748%26ouid%3Dxc%26bd_creative%3D11072932488%26bd_vid%3D7491298425880010041%26keywordid%3D42483860484&VAL={"pc_vid":"1701184519782.37bb85"}',
46 '_jzqco': '%7C%7C%7C%7C1702191484275%7C1.256317328.1701184519797.1702191888543.1702192188644.1702191888543.1702192188644.0.0.0.17.17',
47 '_bfa': '1.1701184519782.37bb85.1.1702191890469.1702192248624.4.7.290510',
48 }
49 headers = {
50 'authority': 'm.ctrip.com',
51 'accept': '*/*',
52 'accept-language': 'zh-CN,zh;q=0.9',
53 'cache-control': 'no-cache',
54 'cookieorigin': 'https://you.ctrip.com',
55 'origin': 'https://you.ctrip.com',
56 'pragma': 'no-cache',
57 'referer': 'https://you.ctrip.com/',
58 'sec-ch-ua': '"Google Chrome";v="119", "Chromium";v="119", "Not?A_Brand";v="24"',
59 'sec-ch-ua-mobile': '?0',
60 'sec-ch-ua-platform': '"Windows"',
61 'sec-fetch-dest': 'empty',
62 'sec-fetch-mode': 'cors',
63 'sec-fetch-site': 'same-site',
64 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
65 }
66 params = {
67 '_fxpcqlniredt': '09031019117090895670',
68 'x-traceID': '09031019117090895670-1702192248633-2041426',
69 }
70 json_data = {
71 'arg': {
72 'channelType': 2,
73 'collapseType': 0,
74 'commentTagId': 0,
75 'pageIndex': page,
76 'pageSize': 10,
77 'poiId': 75910,
78 'sourceType': 1,
79 'sortType': 3,
80 'starType': 0,
81 },
82 'head': {
83 'cid': '09031019117090895670',
84 'ctok': '',
85 'cver': '1.0',
86 'lang': '01',
87 'sid': '8888',
88 'syscode': '09',
89 'auth': '',
90 'xsid': '',
91 'extension': [],
92 },
93 }
94 response = requests.post(url, params=params,cookies=cookies, headers=headers, json=json_data).json()
95 datas = response['result']['items']
96 # 对响应数据进行逐条解析
97 self.analyze_data(datas)
98 #print(f'***已累计采集景区“亚龙湾热带天堂森林公园”评论相关{page*10}个***')
99 time.sleep(1) #停顿1秒防备检测
100
101 #解析IP属地数据
102 def analyze_data(self,datas):
103 for data in datas:
104 self.data_id += 1
105 # 1、评论
106 content = data['content'].replace(' ', '').replace('\n', '')
107 # 评论相关省份
108 ipshudi = str(data['ipLocatedName']) + '省'
109 #提前为后续地图可视化进行数据清洗
110 if '澳门' in ipshudi:
111 ipshudi = '澳门特别行政区'
112 if '中国香港' in ipshudi:
113 ipshudi = '香港特别行政区'
114 if 'None' in ipshudi:
115 ipshudi = '设置了隐私'
116 dict = {
117 '序号': self.data_id,
118 '评论':content,
119 '游客IP属地': ipshudi
120 }
121 #打印记录
122 #print(dict)
123 data = {
124 '亚龙湾热带天堂森林公园评论相关数据': [self.data_id,content,ipshudi]
125 }
126 self.save_excel(data)
127
128 #储存数据至Excel方便后续数据可视化的数据源提取
129 def save_excel(self, data):
130 if not os.path.exists('亚龙湾热带天堂森林公园评论相关数据.xls'):
131 # 1、创建 Excel 文件
132 wb = xlwt.Workbook(encoding='utf-8')
133 # 2、创建新的 Sheet 表
134 sheet = wb.add_sheet('亚龙湾热带天堂森林公园评论相关数据', cell_overwrite_ok=True)
135 # 3、设置 Borders边框样式
136 borders = xlwt.Borders()
137 borders.left = xlwt.Borders.THIN
138 borders.right = xlwt.Borders.THIN
139 borders.top = xlwt.Borders.THIN
140 borders.bottom = xlwt.Borders.THIN
141 borders.left_colour = 0x40
142 borders.right_colour = 0x40
143 borders.top_colour = 0x40
144 borders.bottom_colour = 0x40
145 style = xlwt.XFStyle() # Create Style
146 style.borders = borders # Add Borders to Style
147 # 4、写入时居中设置
148 align = xlwt.Alignment()
149 align.horz = 0x02 # 水平居中
150 align.vert = 0x01 # 垂直居中
151 style.alignment = align
152 # 5、设置表头信息, 遍历写入数据, 保存数据
153 header = (
154 '序号','评论','游客IP属地')
155 for i in range(0, len(header)):
156 sheet.col(i).width = 2560 * 3
157 # 行,列, 内容, 样式
158 sheet.write(0, i, header[i], style)
159 wb.save('亚龙湾热带天堂森林公园评论相关数据.xls')
160 # 判断工作表是否存在
161 if os.path.exists('亚龙湾热带天堂森林公园评论相关数据.xls'):
162 # 打开工作薄
163 wb = xlrd.open_workbook('亚龙湾热带天堂森林公园评论相关数据.xls')
164 # 获取工作薄中所有表的个数
165 sheets = wb.sheet_names()
166 for i in range(len(sheets)):
167 for name in data.keys():
168 worksheet = wb.sheet_by_name(sheets[i])
169 # 获取工作薄中所有表中的表名与数据名对比
170 if worksheet.name == name:
171 # 获取表中已存在的行数
172 rows_old = worksheet.nrows
173 # 将xlrd对象拷贝转化为xlwt对象
174 new_workbook = copy(wb)
175 # 获取转化后的工作薄中的第i张表
176 new_worksheet = new_workbook.get_sheet(i)
177 for num in range(0, len(data[name])):
178 new_worksheet.write(rows_old, num, data[name][num])
179 new_workbook.save('亚龙湾热带天堂森林公园评论相关数据.xls')
180
181 if __name__ == '__main__':
182 x=Spider_XieCheng()
183 x.get_data()
五、数据可视化
数据清洗:
这里数据清洗由上面定义的类中的analyze_data方法来完成, 在逐条解析数据时对特殊地区进行格式化名称,以方便下面的pycharts Map绘制使用,下方为Spider_XieCheng类中的analyze_data方法
1 def analyze_data(self,datas):
2 for data in datas:
3 self.data_id += 1
4 # 1、评论
5 content = data['content'].replace(' ', '').replace('\n', '')
6 # 评论相关省份
7 ipshudi = str(data['ipLocatedName']) + '省'
8 #提前为后续地图可视化进行数据清洗
9 if '澳门' in ipshudi:
10 ipshudi = '澳门特别行政区'
11 if '中国香港' in ipshudi:
12 ipshudi = '香港特别行政区'
13 if 'None' in ipshudi:
14 ipshudi = '设置了隐私'
15 dict = {
16 '序号': self.data_id,
17 '评论':content,
18 '游客IP属地': ipshudi
19 }
20 #打印记录
21 #print(dict)
22 data = {
23 '亚龙湾热带天堂森林公园评论相关数据': [self.data_id,content,ipshudi]
24 }
25 self.chucun_excel(data)
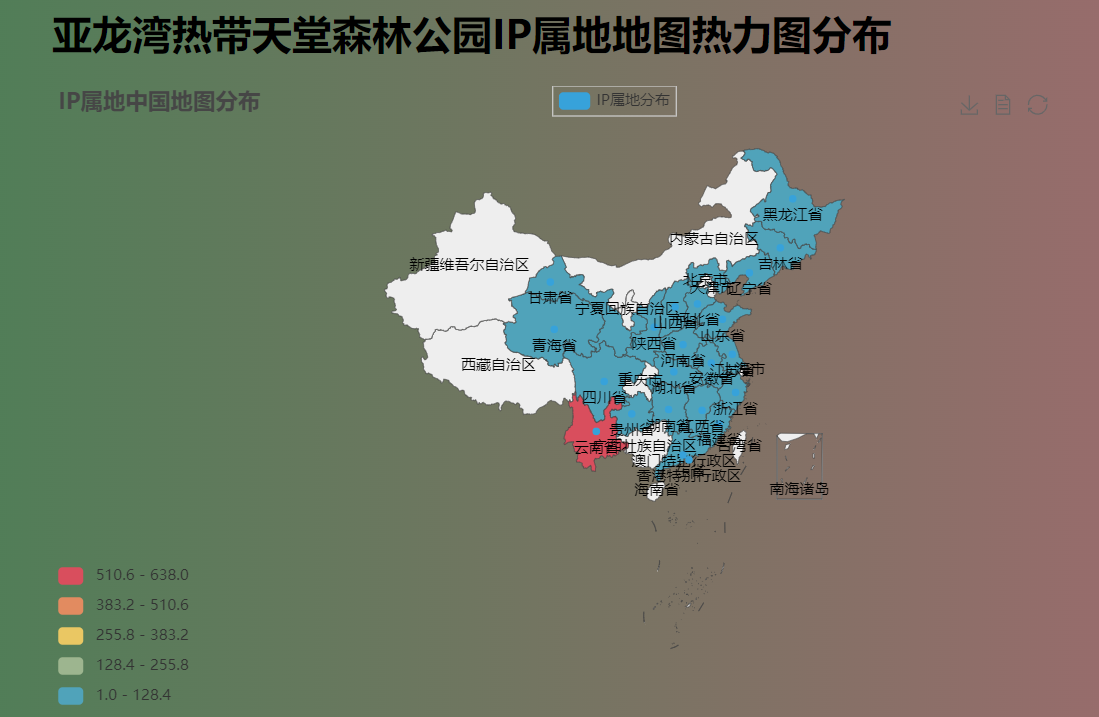
1.将评论的游客IP进行汇总并使用地图热力图绘制
地图热力图,通过热力图可以看出来自云南省游客的评论最多
数据视图

代码实现
1 from pyecharts.charts import Map
2 from pyecharts.globals import ThemeType
3 from pyecharts.charts import WordCloud
4 from pyecharts import options as opts
5 from pyecharts.globals import SymbolType
6 import jieba
7 import pandas as pd
8 from collections import Counter
9
10 class visualization_xc(object):
11 #数据分析可视化
12 def analysis(self):
13 # 读取数据
14 file_path = '亚龙湾热带天堂森林公园评论相关数据.xls'
15 data = pd.read_excel(file_path)
16 # 处理数据:统计每个省份的 IP 数量
17 province_counts = data['游客IP属地'].value_counts().to_dict()
18 # 创建地图
19 map_ = Map(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
20 # 将数据添加到地图
21 map_.add("IP属地分布", [list(z) for z in province_counts.items()], "china")
22 map_.set_global_opts(
23 title_opts=opts.TitleOpts(title="IP属地中国地图分布"),
24 visualmap_opts=opts.VisualMapOpts(max_=max(province_counts.values()), min_=min(province_counts.values()),is_piecewise=True),
25 tooltip_opts=opts.TooltipOpts(is_show=True, formatter="{b}: {c} 人"),
26 toolbox_opts=opts.ToolboxOpts(
27 is_show=True,
28 feature={
29 "saveAsImage": {}, # 保存为图片
30 "dataView": {}, # 数据视图工具,可以查看数据并进行简单编辑
31 "restore": {}, # 配置项还原
32 "refresh": {} # 刷新
33 }
34 )
35 )
36 map_html_content = map_.render_embed()
2.对评论的内容数据分词并创建词云图
词云图,通过词云图可以看出导游为出现最多的关键词

词云图数据视图

代码实现
1 from pyecharts.charts import Map
2 from pyecharts.globals import ThemeType
3 from pyecharts.charts import WordCloud
4 from pyecharts import options as opts
5 from pyecharts.globals import SymbolType
6 import jieba
7
8 class visualization_xc(object):
9 #数据分析可视化
10 def analysis(self):
11 data = pd.read_excel(file_path)
12 data['评论'].fillna('', inplace=True)
13 content = data['评论'].tolist()
14 seg_list = [jieba.lcut(text) for text in content]
15 words = [word for seg in seg_list for word in seg if len(word) > 1]
16 word_counts = Counter(words)
17 word_cloud_data = [(word, count) for word, count in word_counts.items()]
18 # 创建词云图
19 wordcloud = (
20 WordCloud(init_opts=opts.InitOpts(bg_color='#b9986d'))
21 .add("", word_cloud_data, word_size_range=[20, 100], shape=SymbolType.DIAMOND,
22 word_gap=5, rotate_step=45,
23 textstyle_opts=opts.TextStyleOpts(font_family='cursive', font_size=15))
24 .set_global_opts(
25 title_opts=opts.TitleOpts(title="亚龙湾热带天堂森林公园词云图", pos_top="5%", pos_left="center"),
26 toolbox_opts=opts.ToolboxOpts(
27 is_show=True,
28 feature={
29 "saveAsImage": {},
30 "dataView": {},
31 "restore": {},
32 "refresh": {}
33 }
34 )
35
36 )
37 )
38 wordcloud_html_content = wordcloud.render_embed()
完整源代码如下:
1 import requests
2 import xlrd, xlwt, os
3 from xlutils.copy import copy
4 import time
5
6 class XiShuangBanLa(object):
7 def __init__(self):
8 self.data_id = 0
9
10 #发起请求获取响应数据
11 def get_data(self):
12 pages = 100 # 页数设置(一页10个游客)
13 for page in range(1, int(pages) + 1):
14 url = 'https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList'
15 cookies = {
16 'MKT_CKID': '1701184519791.j1nes.9ll0',
17 'GUID': '09031019117090895670',
18 '_RSG': 'B2KZgmdz1O8o4Y4R.sklxB',
19 '_RDG': '28e94143a9de482aae2e935bd882f5ef15',
20 '_RGUID': '8601f67c-2a8d-408b-beef-bb6f9b122132',
21 '_bfaStatusPVSend': '1',
22 'UBT_VID': '1701184519782.37bb85',
23 'MKT_Pagesource': 'PC',
24 'nfes_isSupportWebP': '1',
25 '_ubtstatus': '%7B%22vid%22%3A%221701184519782.37bb85%22%2C%22sid%22%3A2%2C%22pvid%22%3A3%2C%22pid%22%3A600002501%7D',
26 '_bfaStatus': 'success',
27 'ibulanguage': 'CN',
28 'ibulocale': 'zh_cn',
29 'cookiePricesDisplayed': 'CNY',
30 'cticket': '0CDDE357337AEC6A065861D35A34D9162AA75BCB8063AE80366ACD8D40269DA2',
31 'login_type': '0',
32 'login_uid': 'CC94CD2D359B73CD9CC2E002839E204163EA360CBAD672051EAA872D50CC7913',
33 'DUID': 'u=0AE96CC05C93DD44B84C2281D96800D1&v=0',
34 'IsNonUser': 'F',
35 'AHeadUserInfo': 'VipGrade=0&VipGradeName=%C6%D5%CD%A8%BB%E1%D4%B1&UserName=&NoReadMessageCount=0',
36 '_resDomain': 'https%3A%2F%2Fbd-s.tripcdn.cn',
37 '_pd': '%7B%22_o%22%3A6%2C%22s%22%3A11%2C%22_s%22%3A0%7D',
38 '_ga': 'GA1.2.652696142.1702191431',
39 '_gid': 'GA1.2.323708382.1702191431',
40 '_RF1': '2409%3A895e%3Ab451%3A620%3A8c52%3Ad1d7%3Aa25d%3A6909',
41 '_ga_5DVRDQD429': 'GS1.2.1702191431.1.0.1702191431.0.0.0',
42 '_ga_B77BES1Z8Z': 'GS1.2.1702191431.1.0.1702191431.60.0.0',
43 'MKT_CKID_LMT': '1702191445465',
44 'Union': 'OUID=xc&AllianceID=4897&SID=799748&SourceID=&createtime=1702191446&Expires=1702796246013',
45 'MKT_OrderClick': 'ASID=4897799748&AID=4897&CSID=799748&OUID=xc&CT=1702191446014&CURL=https%3A%2F%2Fhotels.ctrip.com%2F%3Fallianceid%3D4897%26sid%3D799748%26ouid%3Dxc%26bd_creative%3D11072932488%26bd_vid%3D7491298425880010041%26keywordid%3D42483860484&VAL={"pc_vid":"1701184519782.37bb85"}',
46 '_jzqco': '%7C%7C%7C%7C1702191484275%7C1.256317328.1701184519797.1702191888543.1702192188644.1702191888543.1702192188644.0.0.0.17.17',
47 '_bfa': '1.1701184519782.37bb85.1.1702191890469.1702192248624.4.7.290510',
48 }
49 headers = {
50 'authority': 'm.ctrip.com',
51 'accept': '*/*',
52 'accept-language': 'zh-CN,zh;q=0.9',
53 'cache-control': 'no-cache',
54 'cookieorigin': 'https://you.ctrip.com',
55 'origin': 'https://you.ctrip.com',
56 'pragma': 'no-cache',
57 'referer': 'https://you.ctrip.com/',
58 'sec-ch-ua': '"Google Chrome";v="119", "Chromium";v="119", "Not?A_Brand";v="24"',
59 'sec-ch-ua-mobile': '?0',
60 'sec-ch-ua-platform': '"Windows"',
61 'sec-fetch-dest': 'empty',
62 'sec-fetch-mode': 'cors',
63 'sec-fetch-site': 'same-site',
64 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
65 }
66 params = {
67 '_fxpcqlniredt': '09031019117090895670',
68 'x-traceID': '09031019117090895670-1702192248633-2041426',
69 }
70 json_data = {
71 'arg': {
72 'channelType': 2,
73 'collapseType': 0,
74 'commentTagId': 0,
75 'pageIndex': page,
76 'pageSize': 10,
77 'poiId': 75910,
78 'sourceType': 1,
79 'sortType': 3,
80 'starType': 0,
81 },
82 'head': {
83 'cid': '09031019117090895670',
84 'ctok': '',
85 'cver': '1.0',
86 'lang': '01',
87 'sid': '8888',
88 'syscode': '09',
89 'auth': '',
90 'xsid': '',
91 'extension': [],
92 },
93 }
94 response = requests.post(url, params=params,cookies=cookies, headers=headers, json=json_data).json()
95 datas = response['result']['items']
96 # 对响应数据进行逐条解析
97 self.analyze_data(datas)
98 #print(f'***已累计采集景区“亚龙湾热带天堂森林公园”评论相关{page*10}个***')
99 time.sleep(1) #停顿1秒防备检测
100
101 #解析IP属地数据
102 def analyze_data(self,datas):
103 for data in datas:
104 self.data_id += 1
105 # 1、评论
106 content = data['content'].replace(' ', '').replace('\n', '')
107 # 评论相关省份
108 ipshudi = str(data['ipLocatedName']) + '省'
109 #提前为后续地图可视化进行数据清洗
110 if '澳门' in ipshudi:
111 ipshudi = '澳门特别行政区'
112 if '中国香港' in ipshudi:
113 ipshudi = '香港特别行政区'
114 if 'None' in ipshudi:
115 ipshudi = '设置了隐私'
116 dict = {
117 '序号': self.data_id,
118 '评论':content,
119 '游客IP属地': ipshudi
120 }
121 #打印记录
122 #print(dict)
123 data = {
124 '亚龙湾热带天堂森林公园评论相关数据': [self.data_id,content,ipshudi]
125 }
126 self.chucun_excel(data)
127
128 #储存数据至Excel方便后续数据可视化的数据源提取
129 def chucun_excel(self, data):
130 if not os.path.exists('亚龙湾热带天堂森林公园评论相关数据.xls'):
131 # 1、创建 Excel 文件
132 wb = xlwt.Workbook(encoding='utf-8')
133 # 2、创建新的 Sheet 表
134 sheet = wb.add_sheet('亚龙湾热带天堂森林公园评论相关数据', cell_overwrite_ok=True)
135 # 3、设置 Borders边框样式
136 borders = xlwt.Borders()
137 borders.left = xlwt.Borders.THIN
138 borders.right = xlwt.Borders.THIN
139 borders.top = xlwt.Borders.THIN
140 borders.bottom = xlwt.Borders.THIN
141 borders.left_colour = 0x40
142 borders.right_colour = 0x40
143 borders.top_colour = 0x40
144 borders.bottom_colour = 0x40
145 style = xlwt.XFStyle() # Create Style
146 style.borders = borders # Add Borders to Style
147 # 4、写入时居中设置
148 align = xlwt.Alignment()
149 align.horz = 0x02 # 水平居中
150 align.vert = 0x01 # 垂直居中
151 style.alignment = align
152 # 5、设置表头信息, 遍历写入数据, 保存数据
153 header = (
154 '序号','评论','游客IP属地')
155 for i in range(0, len(header)):
156 sheet.col(i).width = 2560 * 3
157 # 行,列, 内容, 样式
158 sheet.write(0, i, header[i], style)
159 wb.save('亚龙湾热带天堂森林公园评论相关数据.xls')
160 # 判断工作表是否存在
161 if os.path.exists('亚龙湾热带天堂森林公园评论相关数据.xls'):
162 # 打开工作薄
163 wb = xlrd.open_workbook('亚龙湾热带天堂森林公园评论相关数据.xls')
164 # 获取工作薄中所有表的个数
165 sheets = wb.sheet_names()
166 for i in range(len(sheets)):
167 for name in data.keys():
168 worksheet = wb.sheet_by_name(sheets[i])
169 # 获取工作薄中所有表中的表名与数据名对比
170 if worksheet.name == name:
171 # 获取表中已存在的行数
172 rows_old = worksheet.nrows
173 # 将xlrd对象拷贝转化为xlwt对象
174 new_workbook = copy(wb)
175 # 获取转化后的工作薄中的第i张表
176 new_worksheet = new_workbook.get_sheet(i)
177 for num in range(0, len(data[name])):
178 new_worksheet.write(rows_old, num, data[name][num])
179 new_workbook.save('亚龙湾热带天堂森林公园评论相关数据.xls')
180
181 if __name__ == '__main__':
182 x=XiShuangBanLa()
183 x.get_data()
184
185
186
187 from pyecharts.charts import Map
188 from pyecharts.globals import ThemeType
189 from pyecharts.charts import WordCloud
190 from pyecharts import options as opts
191 from pyecharts.globals import SymbolType
192 import jieba
193 import pandas as pd
194 from collections import Counter
195
196 class visualization_xc(object):
197 #数据分析可视化
198 def analysis(self):
199 # 读取数据
200 file_path = '亚龙湾热带天堂森林公园评论相关数据.xls'
201 data = pd.read_excel(file_path)
202 # 处理数据:统计每个省份的 IP 数量
203 province_counts = data['游客IP属地'].value_counts().to_dict()
204 # 创建地图
205 map_ = Map(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
206 # 将数据添加到地图
207 map_.add("IP属地分布", [list(z) for z in province_counts.items()], "china")
208 map_.set_global_opts(
209 title_opts=opts.TitleOpts(title="IP属地中国地图分布"),
210 visualmap_opts=opts.VisualMapOpts(max_=max(province_counts.values()), min_=min(province_counts.values()),is_piecewise=True),
211 tooltip_opts=opts.TooltipOpts(is_show=True, formatter="{b}: {c} 人"),
212 toolbox_opts=opts.ToolboxOpts(
213 is_show=True,
214 feature={
215 "saveAsImage": {}, # 保存为图片
216 "dataView": {}, # 数据视图工具,可以查看数据并进行简单编辑
217 "restore": {}, # 配置项还原
218 "refresh": {} # 刷新
219 }
220 )
221 )
222 map_html_content = map_.render_embed()
223 # 替换为实际的 Excel 文件路径和列名
224 excel_path = '亚龙湾热带天堂森林公园评论相关数据.xls'
225 column_name = '游客IP属地'
226 # 读取数据
227 df = pd.read_excel(excel_path)
228 # 统计每个省份的出现次数
229 province_count = df[column_name].value_counts().reset_index()
230 province_count.columns = ['IP属地', '数量']
231 # 转换为 HTML 表格
232 html_table = province_count.to_html(index=False, classes='table table-striped')
233
234 data = pd.read_excel(file_path)
235 data['评论'].fillna('', inplace=True)
236 content = data['评论'].tolist()
237 seg_list = [jieba.lcut(text) for text in content]
238 words = [word for seg in seg_list for word in seg if len(word) > 1]
239 word_counts = Counter(words)
240 word_cloud_data = [(word, count) for word, count in word_counts.items()]
241 # 创建词云图
242 wordcloud = (
243 WordCloud(init_opts=opts.InitOpts(bg_color='#b9986d'))
244 .add("", word_cloud_data, word_size_range=[20, 100], shape=SymbolType.DIAMOND,
245 word_gap=5, rotate_step=45,
246 textstyle_opts=opts.TextStyleOpts(font_family='cursive', font_size=15))
247 .set_global_opts(title_opts=opts.TitleOpts(title="亚龙湾热带天堂森林公园词云图", pos_top="5%", pos_left="center"),
248 toolbox_opts=opts.ToolboxOpts(
249 is_show=True,
250 feature={
251 "saveAsImage": {},
252 "dataView": {},
253 "restore": {},
254 "refresh": {}
255 }
256 )
257
258 )
259 )
260 wordcloud_html_content = wordcloud.render_embed()
261
262 complete_html = f"""
263 <html>
264 <head>
265 <title>亚龙湾热带天堂森林公园</title>
266 <meta charset="UTF-8">
267 <meta name="viewport" content="width=device-width, initial-scale=1.0">
268 <style>
269 .table-container {{
270 max-height: 400px;
271 overflow: auto;
272 }}
273 table {{
274 width: 100%;
275 border-collapse: collapse;
276 }}
277 th, td {{
278 border: 1px solid black;
279 padding: 8px;
280 text-align: left;
281 }}
282 </style>
283 </head>
284 <body style="background: linear-gradient(to right, #4f7e57,#c76079 ); ">
285 <div class="one" style="display: flex; justify-content: center; flex-wrap: wrap; height: 100%;">
286 <div style="margin: 10px; padding: 10px;">
287 <h1>亚龙湾热带天堂森林公园评论相关游客IP属地词频统计表</h1>
288 <div class="table-container">{html_table}</div>
289 </div>
290 <div style="margin: 10px; padding: 10px;">
291 <h1>亚龙湾热带天堂森林公园IP属地地图热力图分布</h1>
292 {map_html_content}
293 </div>
294 <h1>亚龙湾热带天堂森林公园评论词云</h1>
295 <div>{wordcloud_html_content}</div>
296 </div>
297 </body>
298 </html>
299 """
300 # 写入页面
301 with open("亚龙湾热带天堂森林公园可视化.html", "w", encoding="utf-8") as file:
302 file.write(complete_html)
303
304 if __name__ == '__main__':
305 x=visualization_xc()
306 x.analysis()
六、总结
游客信息汇总:
携程网爬虫技术的应用可以帮助我们获取大量的景点游客数据,包括游客数量、游客来源地、游客年龄段、游客满意度等信息。通过对这些数据进行分析和可视化,可以为旅游行业和景点管理提供重要的参考和决策支持。
景点评价分析:
利用爬虫技术获取携程网景点游客数据后,可以通过数据分析工具对数据进行清洗、整理和分析,从中挖掘出有价值的信息。比如可以通过数据分析得出不同景点的高峰游客时间、热门景点的游客来源地分布、游客对景点的评价等内容。同时,利用数据可视化技术,可以将这些分析结果以图表、地图等形式直观展现,帮助管理者更直观地了解景点的客流情况、市场需求和用户满意度等信息。
原文地址:https://blog.csdn.net/GR001009/article/details/143024139
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!