【YOLO v5 v7 v8 小目标改进】RFB:组合不同大小的卷积核和扩张卷积来模拟人类视觉感受野的多尺度特性
RFB:组合不同大小的卷积核和扩张卷积来模拟人类视觉感受野的多尺度特性
提出背景
当前表现最好的目标检测器依赖于深层CNN骨干网络,如ResNet-101和Inception,它们受益于强大的特征表示,但代价是高计算成本。
相反,一些轻量级模型的检测器能够实现实时处理,但它们的准确性都不咋地。
作者提出了一种用于快速且准确的目标检测的方法,旨在通过增强轻量级CNN网络的深层特征来解决当前深层网络模型计算成本高和推理速度慢的问题。
RFB 原理
RFB模块,即Receptive Field Block模块,是一种用于增强轻量级卷积神经网络(CNN)特征表示的网络结构。
它的设计灵感来自于人类视觉系统的感受野(Receptive Field),特别是感受野的大小和偏心率(即感受野中心与视网膜中心的距离)随视网膜位置变化的特性。RFB模块通过模拟这种特性来增强特征的区分能力和鲁棒性,尤其是对于位置的轻微偏移。
-
人类视觉系统在处理这类任务时,会更加关注图像中的某些区域,特别是那些对当前任务更重要的区域。
-
当你在街道上,专注于识别远处的交通标志时,你的视觉系统会自然地调整,使得感受野在那个特定区域变得更大,以便捕获更多的上下文信息,即使标志本身较小也能被准确识别。
-
同时,对于图像中心附近的对象(如近处的行人),感受野则会相对较小,以捕获更细致的特征,如脸部特征或衣物纹理,从而提高对行人的识别准确性。
RFB 模拟过程:
-
多分支池化,实现多尺度特征捕获:使用不同大小的卷积核和池化层来捕捉不同尺度的特征。
这样可以模拟不同大小的感受野,从而更好地捕捉图像中的详细信息。
模型能够同时捕获图像中的粗糙和细致特征。
这就像人眼能够同时注意到远处交通标志的整体形状(粗糙特征)和近处行人脸部的细节(细致特征)。
-
扩张卷积(Dilated Convolution)模拟偏心率调整:通过增加卷积核元素之间的间隔来扩大感受野,而不增加参数数量或计算量。
通过扩张卷积(dilated convolution),调整卷积核的采样范围,增大感受野而不增加参数数量,以捕捉更广泛的上下文信息。
这使得模型能够更有效地处理图像边缘或角落部分的对象,增强了对于位置变化的鲁棒性。
-
特征重组和整合,实现动态感受野调整:通过对不同分支的输出进行组合和调整,生成最终的特征表示。
使用扩张卷积层而不是固定的池化策略。
固定池化策略限制了感受野大小的多样性,影响特征的融合。
这一步骤确保了模型可以利用来自不同感受野的信息,提高模型的识别能力。
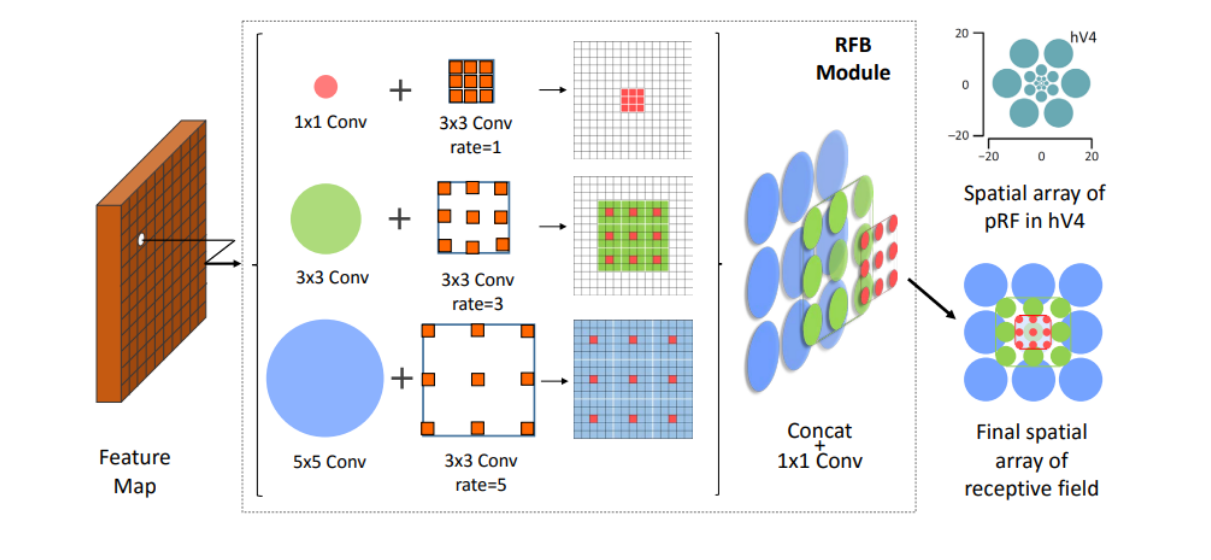
这图是RFB模块的构建方式,通过结合不同核大小和扩张卷积层的多分支,来模拟人类视觉系统中的感受野。
不同大小的核对应不同大小的感受野,而扩张卷积层则用于调整这些感受野的偏心率。
这些分支最后通过连接操作和1x1卷积层结合起来,形成最终的感受野空间数组,类似于图1中展示的人类视觉系统中的感受野。
空间感受野结构
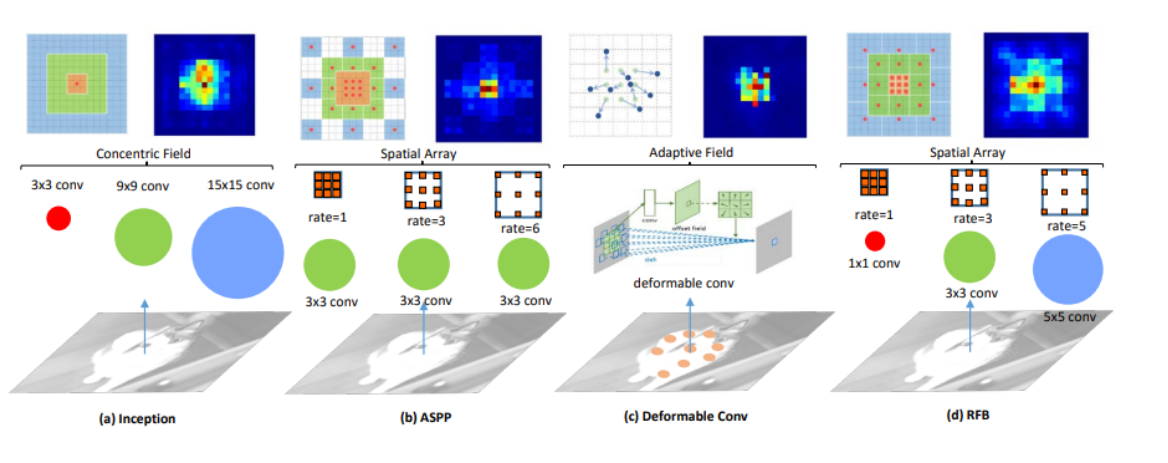
在原文中,展示的四种不同的空间感受野结构意味着:
-
Inception(图 3a):
- Inception模块使用多个大小不同的卷积核同时工作,从而能够在同一层内捕获不同尺度的特征。
- 这允许模型同时理解图像中的大范围模式和小范围的细节。
-
ASPP(图 3b):
- Atrous Spatial Pyramid Pooling(ASPP)结构通过使用不同扩张率的卷积层,可以在不同尺度上捕捉特征。
- 这样做可以增加感受野的大小,同时不增加计算成本,能够更好地处理图像中的多尺度对象。
-
Deformable Convolution(图 3c):
- 可变形卷积网络通过允许卷积核的形状根据输入数据动态变化来捕捉不规则的特征。
- 这种灵活性允许模型更好地适应物体的形状和大小,提高了模型对不同对象的适应能力。
-
RFB(图 3d):
- RFB结构结合了Inception和ASPP的优点,使用不同扩张率的卷积核来模拟人类视觉中感受野的大小和偏心率变化。
- 这种设计在保持参数数量不变的情况下,使感受野更加多样化和精细化,提高了模型的准确性和对小物体及其上下文的识别能力。
每种结构都有其特定的优势,而RFB模块试图将这些优势集成到一个更加高效和精确的检测框架中。
- 相比于Inception模块,RFB模块提供了更精细的控制感受野尺度的方法,不仅通过多分支结构捕获多尺度特征,还通过扩张卷积调整感受野的大小。
- 与ASPP相比,RFB不仅利用了扩张卷积来增加感受野,还特别设计了多分支结构来模拟感受野的尺寸和位置变化,更符合人类视觉感受野的实际分布。
- 不同于可变形卷积网络(Deformable Convolutional Networks)只在局部自适应调整感受野,RFB考虑了整个视网膜映射的规律,力求在全局范围内优化感受野的大小和形状。
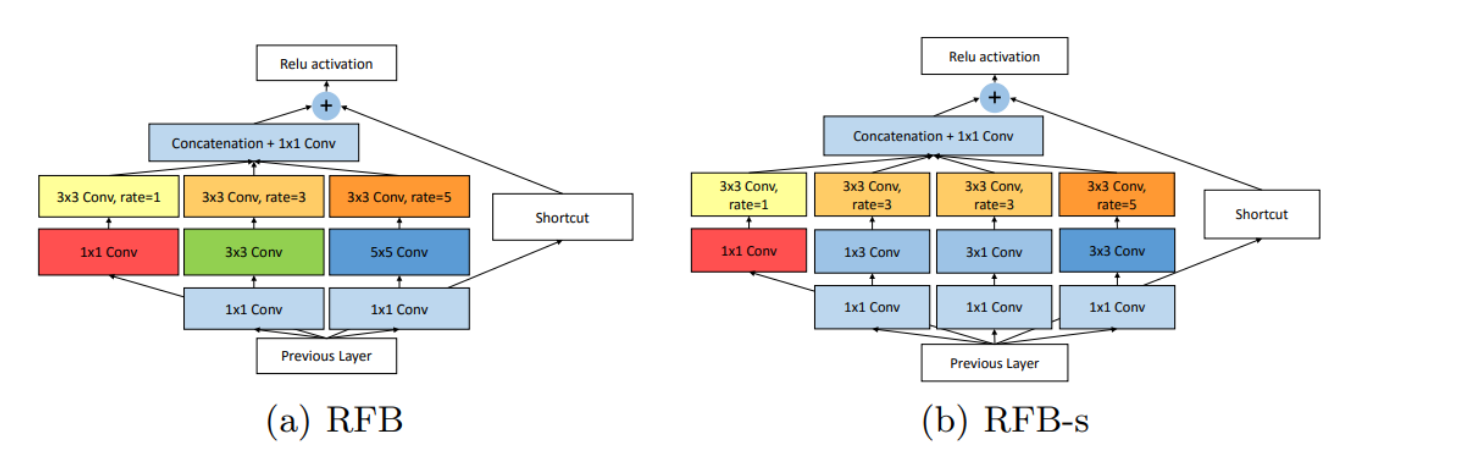
RFB模块的设计,上文已描述。
RFB-s是RFB的一个变体,它专门设计来模拟人类视网膜图谱中较小的感受野。
它主要用于网络中更浅的层,因为这些层更接近原始图像,能够捕捉更精细的图像细节。
-
更多的分支:RFB-s使用了更多的分支,每个分支有更小的卷积核。这样可以提高对小尺寸特征的敏感性,对应于视网膜中心区域的细节捕捉能力。
-
较小的卷积核:较小的卷积核允许RFB-s模块有较小的感受野,更适合捕获小物体或图像中的细节特征。
-
步长为2的操作:在特征图上使用步长为2的RFB模块可以减少输出特征图的空间尺寸,从而减少模型的参数数量和计算负担。这种设置有助于加速模型的计算,同时仍然允许模型利用RFB模块提供的感受野多样性。
当这些模块应用于conv4_3特征图后时,它们提供了一个精细的感受野结构来增强后续层的特征表示。
在目标检测中,这意味着模型可以更有效地识别和定位图像中的小物体,同时还能快速处理图像,使其非常适用于需要实时处理的应用场景,如视频监控或自动驾驶汽车。
RFB 通过组合不同大小的卷积核和扩张卷积来模拟人类视觉感受野的多尺度特性,与其他方法(如Inception模块、ASPP等)相比,RFB特别强调通过这种组合来精细调整感受野的大小和偏心率,以优化对复杂背景下小目标的检测性能。
RFB-Net
RFB-Net 网络架构流程:
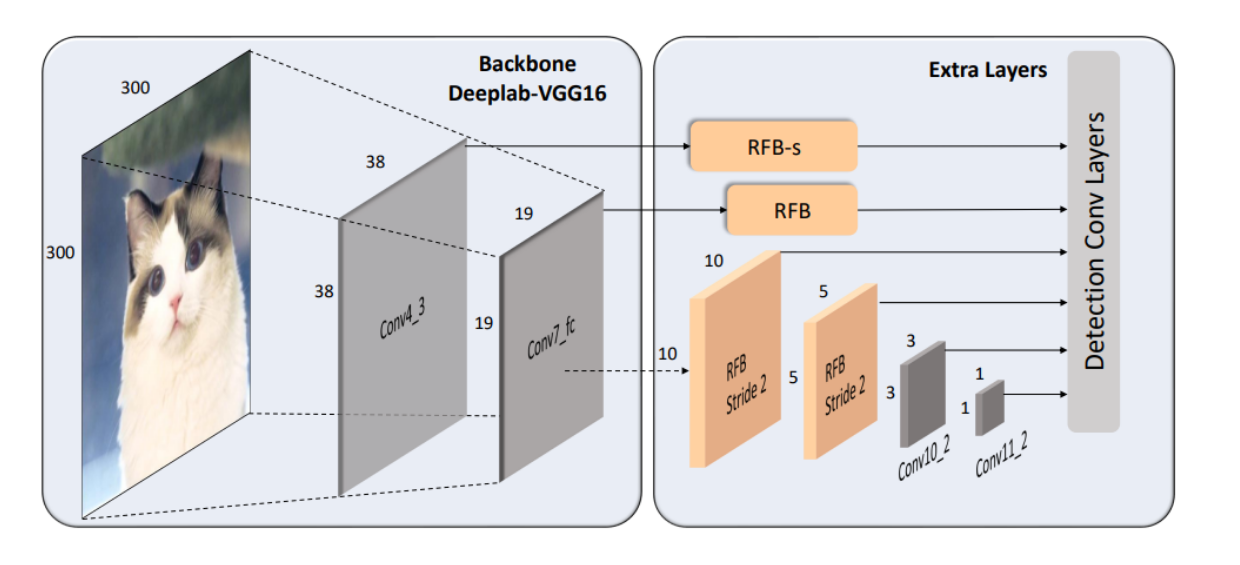
其中 conv4_3 特征图后接 RFB-s 模块,该模块具有较小的感受野,且使用步长为2的RFB模块来减少参数量,而保持原有RFB模块的多核心卷积层。
在RFB Net中,conv4_3这一层特征图上的锚点框数量被增加,以期望通过更多的候选框来提高网络对小目标的检测性能。
这种调整反映了一个通用的观点,即增加对小物体的敏感性可以通过在低层特征图上引入更多的锚点框来实现。
问题:优化小目标的检测精度
解法:
-
增加低层特征图的默认锚点框数量
-
之所以增加锚点框,是因为小目标在低层特征图上更为明显,增加锚点框能够提供更多的正样本,从而提高小目标的检测精度。
问题:高性能的目标检测模型往往需要复杂的网络结构来提高准确率,但这样做的代价是计算成本高和推理速度慢,这对于需要实时处理的应用场景(如自动驾驶车辆的物体识别)是不可接受的。
SSD 是一种流行的单阶段目标检测模型,以其速度快和效率高而著称。
解法:
- 通过在SSD(一种轻量级且能实时处理的目标检测模型)的顶部集成RFB模块,可以在不显著增加计算负担的情况下,显著提升模型的检测性能。
- 这样,RFB Net能够快速准确地检测图像中的物体,同时保持较低的计算成本和高速的推理能力。
将RFB模块集成到SSD顶层的过程如下:
-
选择集成位置:首先确定在SSD网络结构中哪些层之后集成RFB模块。
通常,这些位置选在特征提取网络的后面几层,因为这些层的特征图包含了丰富的语义信息,适合进行进一步的增强。
-
设计RFB模块:根据SSD的特定需求设计RFB模块。
这包括确定分支的数量、卷积核的大小、扩张率等参数。
设计的目标是在不显著增加计算负担的情况下,最大化特征的区分能力和鲁棒性。
-
集成RFB模块:在选定的层后面添加RFB模块。
这意味着原有的特征图会首先通过RFB模块进行处理,然后再继续后续的检测流程。
-
调整检测头:由于引入了RFB模块,可能需要对SSD原有的检测头(即用于分类和定位的卷积层)进行一定的调整,以适应新的特征表示。
-
训练和优化:最后,需要使用标注数据重新训练和优化整个模型,确保RFB模块能够有效提升目标检测的性能。
通过上述步骤,RFB Net能够结合SSD的高效处理速度和RFB模块的强大特征表示能力,实现快速且准确的目标检测。
小目标涨点
更新中…
YOLO v5 魔改
YOLO v7 魔改
YOLO v8 魔改
原文地址:https://blog.csdn.net/qq_41739364/article/details/136375312
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!