面试官:你给我手撕一个布隆过滤器吧
前言
说来话长,话来说长。前些天我投了一些日常实习的简历,结果足足等了两个礼拜才收到面试通知,看来如今的行情确实是挺紧张的。当时我是满怀信心去的,心想这次一定要好好拷打面试官一番,结果没想到,自我介绍刚一结束,面试官就要开始拷打我了,直接让我手撕布隆过滤器?我当时心里可真是:我勒个豆啊(此处省略无数心里话)。虽然我对它的原理是了解的,但之前还真没有亲手写过。就这样,我开始了这次的手撕布隆过滤器之旅。不过话说回来,虽然非常离谱,但这种经历也算是某种成长吧,毕竟理论和实践之间总是有些距离的。
一、什么是布隆过滤器
【面试官】:布隆过滤器是什么?你给我讲讲吧。
【自信的我开始吟唱】:
-
布隆过滤器是一种基于哈希算法的位数组数据结构,主要用于高效地检测一个元素是否在一个集合中。尽管它可以极大地节省存储空间,但由于其允许一定的误报率(即可能会错误地报告一个元素存在于集合中),因此在使用时需要权衡误报的可能性。
-
当数据量增加时,传统的集合数据结构(如哈希表或列表)会占用大量的内存。而布隆过滤器通过使用多个哈希函数和一个固定长度的位数组来减少内存使用。其主要用途在于能够快速地判断某项元素是否属于特定集合,特别适用于需要快速去重检查的场景,并且它还可以有效地防止缓存穿透攻击。
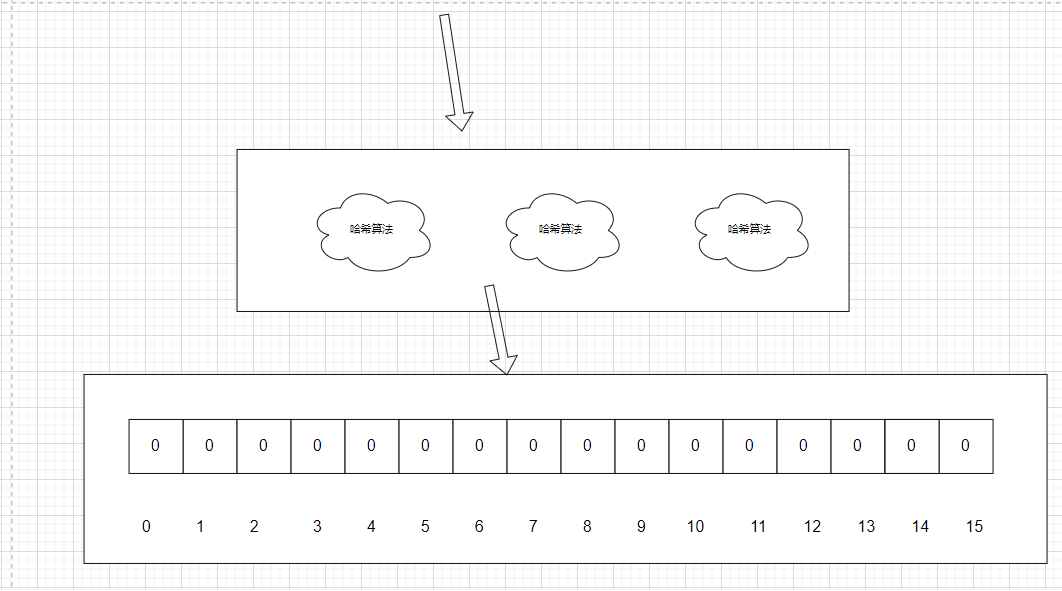
二、实现原理
【面试官点点头,心里暗想着必须要拷打到你】:你跟我讲讲它是如何实现的吧。
【无比自信的我】:
- 底层原理是通过一个bitmap二进制位数组表示集合来实现的。数组初始位都是0,当添加元素时,会通过多个哈希函数将元素映射到位数组中的多个位置,并将这些位设为1。需要查询某个元素是否存在布隆过滤器时,只需对该元素进行多次哈希,并判断位数组对应位置上的位是否为1即可。
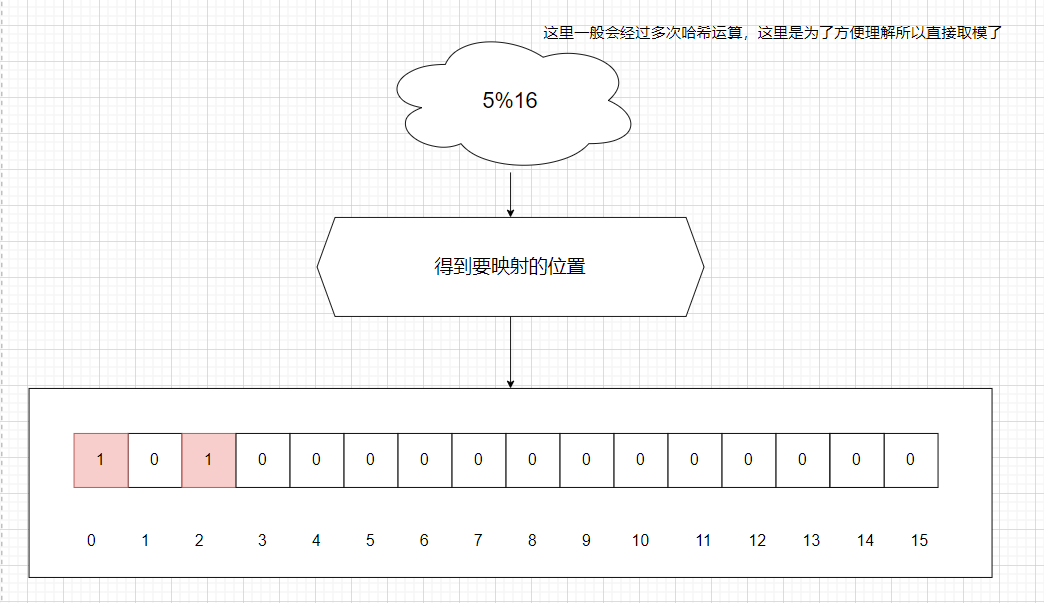
三、问题
3.1、 误判率
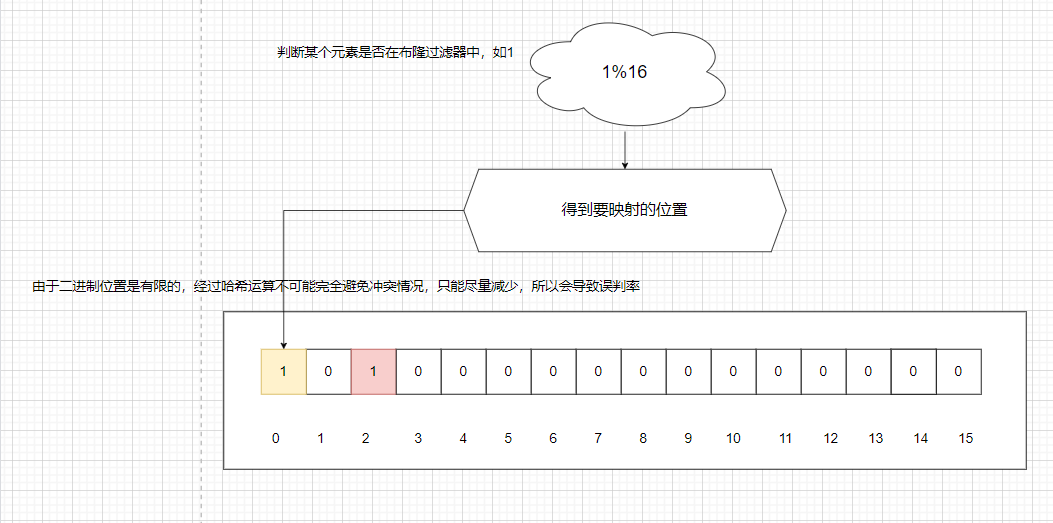
【面试官追问】:那它二进制位数组,不会有不同元素映射到相同的位置吗?
【我】:
- 这种情况发生是因为哈希函数的冲突,使得不同元素被映射到相同的位置,导致布隆过滤器的误判率问题。如下图所示:
- 对于误判率,有一个公式可以计算:k:哈希次数,n:元素个数,m:bit数组长度
p ( n , m , k ) = ( 1 − e − k n / m ) k p(n,m,k) = (1 - e^{-kn/m})^k p(n,m,k)=(1−e−kn/m)k
同时还有一个便捷的网站方便我们计算:https://hur.st/bloomfilter/
使用方法如下:

- 通过上述公式我们知道,为了降低误判率,可以采取以下措施:
- 增加位数组大小:如果位数组的大小增加,哈希函数分布的碰撞概率降低,从而降低误判率。
- 增加哈希函数数量:通过对元素值进行多次哈希操作,得到相对离散的值,但过多的哈希函数会导致效率下降。
- 控制插入元素的数量:布隆过滤器的容量是有限的,超过容量后误判率会快速升高。因此,通过限制数据量在布隆过滤器某一阈值比例内,可以保持较低的误判率。尽管如此,布隆过滤器占用的空间相较于其他数据结构还是非常小的。
3.2、 不可删除
【面试官】:除了这个,布隆过滤器还有什么问题吗?
【我】:
- 布隆过滤器的另一个缺点是无法删除元素。一旦某个元素被添加,无法准确将其从位数组中移除,否则可能会影响其他元素的判定。但是,有一种改进版本的布隆过滤器,称为计数布隆过滤器或动态布隆过滤器(如布谷鸟过滤器),可以在一定程度上解决这一问题。
四、使用场景
【面试官,心想答得还不错,基本都覆盖了】:那你说说布隆过滤器有哪些使用场景吧。
【我】:
- 常用的话,一般有以下几个场景:
- 快速判重:在大规模数据处理场景中,布隆过滤器可以快速判定某个数据是否已经出现,例如用于网页爬虫中避免抓取重复的网页。
- 缓存穿透:布隆过滤器可以用于防止缓存穿透。当查询的数据不在缓存中,也不在数据库中时,直接利用布隆过滤器判断该数据是否存在,从而减少对数据库的压力。
- 推荐系统中的候选生成:在推荐系统中,布隆过滤器可以用来排除已经推荐过的项目,从而提高推荐的多样性和新颖性。
- 恶意域名检测:在网络安全领域,可以使用布隆过滤器来存储已知的恶意域名列表,快速判断新遇到的域名是否可能存在安全风险。
- 大数据预筛选:在处理大规模数据集时,布隆过滤器可用于预筛选,减少后续处理的数据量,提高处理效率。
五、如何使用
【面试官】:那你讲讲你在项目中是如何实现的吧。
【我】:
-
布隆过滤器在 Guava 和 Redisson 中都已经有了实现(这些实现可以直接在网上找到教程,这里就不做具体演示了),我们在使用时可以直接使用这些现有的实现类。
-
由于我在多个服务下需要实现分布式的共享布隆过滤器数据,所以我选择了使用 Redis 实现布隆过滤器。这样可以确保多个服务之间能够共享布隆过滤器的状态,从而提高系统的整体性能和一致性。如果是单机环境下,直接使用 Guava 的实现即可。
六、Java 手撕
【面试官,心想竟然难不倒你】:那你Java手撕一个吧。
【我】:啊?(然后默默开启了手撕)
在使用Java实现布隆过滤器时,可以借助 BitSet 或自定义的 BitMap 来存储位数组。同时,多个哈希函数可以通过 MessageDigest 或其他常见的哈希库来实现。以下是一个Java布隆过滤器的示例实现概述:
package com.example.provider.utils;
import java.util.BitSet;
import java.util.Random;
public class BloomFilter {
// 一个位数组,用于存储数据
private final BitSet bitSet;
// 位数组的大小
private final int bitSetSize;
// 使用的哈希函数数量
private final int numHashFunctions;
private final Random random;
// 布隆过滤器构造函数
public BloomFilter(int capacity, int numHashFunctions) {
this.bitSetSize = capacity;
this.numHashFunctions = numHashFunctions;
this.bitSet = new BitSet(bitSetSize);
this.random = new Random();
}
/** 添加元素到布隆过滤器
* - 将元素通过多个哈希函数进行散列。
* - 将这些哈希值映射到位数组中对应的索引位置,并将这些位置的值设为1。
* @param value
*/
public void add(String value) {
for (int i = 0; i < numHashFunctions; i++) {
int hash = hash(value, i);
bitSet.set(Math.abs(hash % bitSetSize), true);
}
}
/** 检查元素是否存在
* - 将元素通过同样的哈希函数散列。
* - 检查这些散列值对应的位数组位置是否都为1,
* 如果是,则说明元素可能存在(但不保证);如果有任意位置为0,则说明元素一定不存在。
* @param value
* @return
*/
public boolean mightContain(String value) {
for (int i = 0; i < numHashFunctions; i++) {
int hash = hash(value, i);
if (!bitSet.get(Math.abs(hash % bitSetSize))) {
return false;
}
}
return true;
}
// 哈希函数,用于生成多个不同的哈希值
private int hash(String value, int seed) {
random.setSeed(value.hashCode() + seed);
return random.nextInt();
}
// 测试布隆过滤器
public static void main(String[] args) {
int capacity = 1000; // 位数组大小
int numHashFunctions = 5; // 使用的哈希函数数量
BloomFilter bloomFilter = new BloomFilter(capacity, numHashFunctions);
// 添加元素
bloomFilter.add("apple");
bloomFilter.add("banana");
// 检查元素是否存在
System.out.println(bloomFilter.mightContain("apple")); // 可能存在
System.out.println(bloomFilter.mightContain("banana")); // 可能存在
System.out.println(bloomFilter.mightContain("grape")); // 一定不存在
}
}
七、总结
【最后,面试官】:时间差不多够了,我们面试就到此为止吧,你先回去等通知吧。
【我】:???
通过本文,相信大家已经了解了布隆过滤器的基本概念及其在面试中的应用技巧。我们再来谈谈布隆过滤器的设计吧, 它巧妙地利用了位数组和哈希函数的特点,通过将元素映射到位数组中,实现了内存的有效利用。这种设计不仅减少了内存占用,还提高了查询速度,非常适合需要快速去重检查的场景。
最后,本文到这里就结束了,希望能对你有所帮助。如果觉得内容有用,请给予支持。另外,有兴趣的话可以进一步了解布谷鸟过滤器等改进版本,它们在某些场景下提供了更为灵活的解决方案。
原文地址:https://blog.csdn.net/qq_62074445/article/details/143064018
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!