MatSci-LLM ——潜力和挑战以及大规模语言模型在材料科学中的应用
概述
大规模语言模型的出现正在从根本上改变技术开发和研究的方式。大规模语言模型不仅对自然语言处理领域产生了重大影响,而且对许多相关领域也产生了重大影响,例如从文本生成图像的计算机视觉(Zhang 等人,2023 年)。因此,将大规模语言模型的能力融入各行各业的工作正在加速进行。
例如,医疗保健(He 等人,2023 年)、法律(Dahl 等人,2024 年)、金融(Wu 等人,2023 年a)和软件工程(Fan 等人,2023 年)领域的任务自动化。
其中值得一提的是将大规模语言建模应用于材料科学。这加快了新材料的发现、合成和分析,从而为解决当代复杂的社会问题提供了巨大的可能性,如气候变化和能源安全、可持续农业和制造业、个性化医疗设备,以及获取更强大的计算系统。
最近的研究表明,大规模语言模型在化学(Jablonka 等人,2023 年)和生物学各领域(Lin 等人,2023 年;Hsu 等人,2022 年;Xu 等人,2023 年;Cui 等人,2023 年;Dalla-Torre 等人,2023 年)的应用日益增多,但在材料科学领域的应用却进展缓慢。但其在材料科学中的应用仍然缓慢。
本文分析了当前材料科学领域大规模语言建模所面临的挑战,整理并提出了材料科学大规模语言模型(MatSci-LLM)的要求。论文还提供了一个路线图,展示了 MatSci-LLM 在材料科学领域发展中的具体应用。
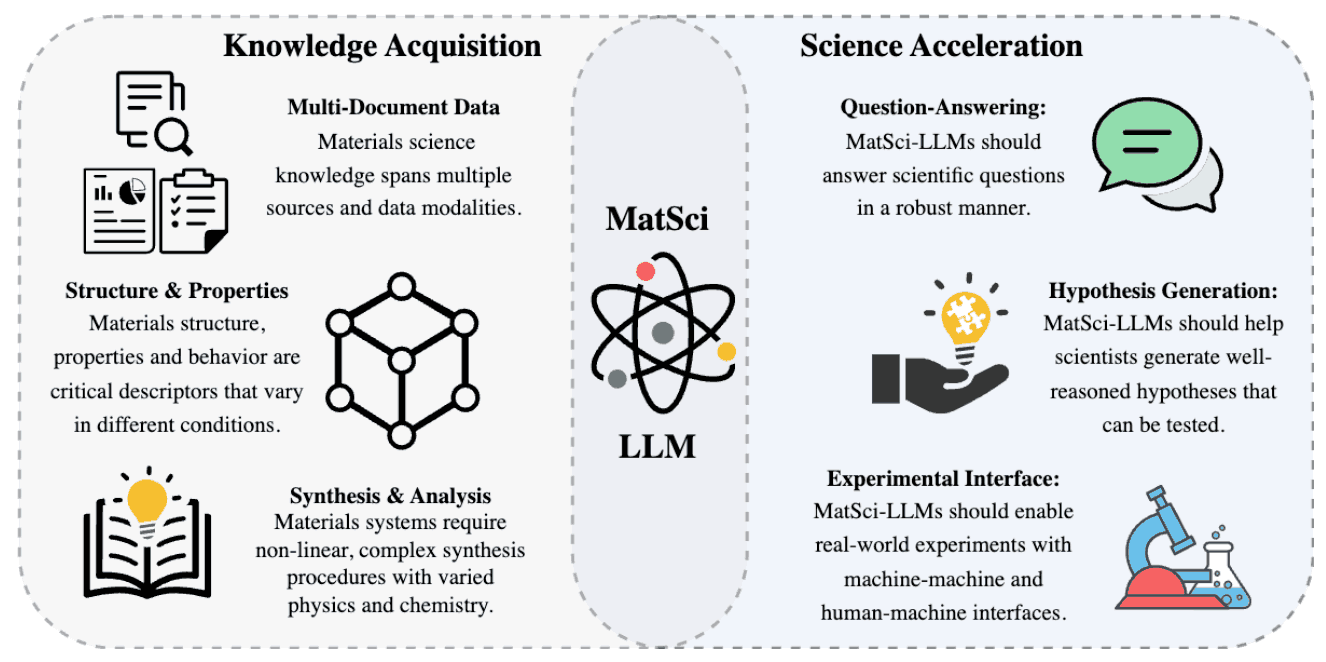
材料科学中大规模语言模型的失败
论文显示了大规模语言模型在材料科学领域应用的巨大潜力。然而,了解它们在实际应用中的局限性也很重要。论文举例说明了大规模语言模型在问题解答、代码生成、同源表达提取、摘要分类和材料文献的成分提取等任务中的失败案例,说明了开发稳健的 MatSci-LMs 的必要性。
GPT-4 和 LLaMA-2 是著名的高性能大规模语言模型,是在大量公共文本数据的基础上训练出来的。因此,它们被认为从维基百科和其他公共资源中掌握了一定的材料科学知识。
因此,Zaki 等人(2024 年)创建了一个数据集,其中包括 650 个要求具备本科生水平知识的问题,他们用这个数据集来评估大规模语言模型中材料科学领域的知识。
结果表明,通过使用思维链(CoT)推理,GPT-4 的正确答题率达到了 62%,但在数字类型的问题上表现不佳,只有 39%。这表明,目前的大规模语言模型在分配适当的数值、整合上下文和解决原始问题方面表现不佳。
此外,与人类在同一测试中的表现相比,GPT-4 CoT 优于其他基线,但与表现最佳的人类相比,它只达到了约 50%,未能超过测试通过阈值。
他们还发现,大规模语言模型擅长的任务之一是代码生成,但在一项与材料科学相关的代码生成任务中,GPT-4 的准确率仅为 71% Zaki 等人(2024 年)详细分析了表现不佳的问题和代码生成任务,发现大规模语言模型在解决复杂数值问题方面表现不佳,原因包括错误的数值赋值、单位转换错误以及单位转换过程中丢失常数。大规模语言模型在理解三维结构相关信息方面表现不佳,特别是与晶体结构和材料相关的对称性被误解,导致得出错误结论。研究发现
由此可见,目前的大规模语言模型在材料科学的实际应用中还需要进一步改进。通过学习更多特定领域的信息并提高推理能力,大规模语言模型可以成为一种实用工具。
基于材料科学领域特定语言的大规模语言建模基础设施
材料科学领域与物理学、化学和生物学等各种工程学科密切相关,因此需要技术的深度和广度。因此,特定领域的语言模型对于克服材料科学领域特有的挑战至关重要。本文也论述了特定领域语言模型在材料科学中的重要性。
虽然化学中存在诸如 IUPAC 命名法(Hellwich et al.例如,NaAlSi2O8、Na2O.Al2O3.2SiO2 和 SiO2-0.5Na2O-0.5Al2O3 在不同情况下代表同一种材料。此外,有时还使用特定领域的名称,如用 "苏打 "或 "石灰 "表示 Na2CO3 或 CaCO3。在水泥化学中,C-S-H 指的是硅酸钙水合物,而标准化学符号指的是碳、硫和氢。可以看出,材料科学的符号多种多样,需要基于特定领域的学习,才能在适当的语境中理解大规模语言模型。
此外,研究论文中可能会遗漏某些信息。这些信息是以参考文献的形式提供的,例如 “断裂模拟是使用 Griffith 等人的论文中描述的方法进行的”,“断裂模拟是使用 Griffith 等人的论文中描述的方法进行的”。在材料科学文献中,根据其他论文描述实验和模拟方案、材料成分和合成条件是很常见的。因此,大规模语言建模要求能够从多个来源收集信息,并对信息进行适当的上下文关联和解释。
在材料科学中,文字通常用来表示三维或二维结构。晶体结构使用 Wyckoff 位置来表示(Aroyo 等人,2006 年),而在晶体学中,4 毫米表示晶体结构,在一般文献中有时也用作距离单位。晶体也以 CIF(晶体信息文件)格式表示,其中包含详细的晶体数据。然而,目前的大规模语言模型无法读取、解释和生成 CIF 文件。这是发现新材料的一大限制。
此外,材料信息可以用多种方式表示,如文本、表格、图表和视频。虽然在提取信息,尤其是表格形式的信息方面取得了进展(Gupta 等人,2023 年;Zhao 等人,2023 年),但根据提取的数据将知识注入大规模语言模型的方式仍面临挑战。材料特性通常以科学单位进行描述,需要将表格和文本联系起来才能获得准确的信息。
材料特性还可以用拉曼分析、X 射线衍射 (XRD) 和扫描电子显微照等实验结果的图解来表示。例如,要解释 "图 XY(a)中的 X 射线衍射图样表明该样品是无定形的 "这句话,需要同时理解文字和图表。大规模语言模型要正确学习这些信息,需要大量的图像和相应的文本。
其他材料科学信息可能以文字、图表、表格和视频相结合的方式呈现,这就需要进一步研究大型语言模型,以便将这些信息恰当地联系起来。例如,材料失效模式、晶体生长和热反应可能会以视频形式呈现。大规模语言模型整合和解释这些信息的能力是未来的一项重要挑战。
在材料科学的应用中,克服这些挑战将使其成为更加有用的工具。
建立多模态材料科学语料库
语言模型的性能在很大程度上取决于用于训练的数据集的质量。因此,数据集的创建是促进计算机视觉、图学习和自然语言处理等各种深度学习领域取得进展的关键因素。特别是在材料科学领域,文本在特定领域的高度可变性以及多模态语言模型的开发,要求开发结合了图、表和图像等其他模态的数据集。这样就可以用多种模式表示科学信息,从而建立更强大的语言模型。
用于训练材料科学大型语言模型的黄金标准数据主要包含在爱思唯尔、英国皇家学会、美国学会和施普林格-自然等著名编辑机构的同行评议出版物中。然而,获取宝贵的文本数据十分困难,因为这些出版物大多收费,而且限制公众访问。因此,GPT-4 和 LLaMa 等通用语言模型不太可能获得这些数据,这也是它们在材料科学任务中表现不佳的原因。通过各种预印本服务器和门户网站(如 Semantic Scholar),科学文本数据正朝着开放访问的方向发展,但这些来源的数据需要清理等。
许多知名期刊提供基于付费订阅的文本和数据挖掘 API,但机器可读格式仅限于 21 世纪出版的手稿;许多 20 世纪以前的出版物只能以 PDF 或扫描文件的形式提供,机器可读性较差。这是因为 20 世纪以前出版的科学文献没有机读格式。因此,20 世纪以前的科学数据很少可用于大规模语言模型的训练。此外,许多同行评审期刊不允许进行文本和数据挖掘,也没有这方面的框架。来自预印本服务器的数据在应用于训练之前也需要大量的清理工作。
当数据来自多种来源或模式(如表格、文本、图像、视频、代码等)时,每种模式都需要有合适的描述。例如,硅 CIF 文件需要对其文件中包含的信息进行详细描述,这样大规模语言模型不仅能理解 CIF 格式,还能学会如何解释这些信息。然而,目前还没有这种大规模的注释,需要专家输入才可靠。
要将多个实体的数据正确连接起来,以便在相关上下文中一起阅读,并非易事。例如,手稿中对图或表的描述可能跨越多个段落,并散布在补充材料中。这就需要开发尊重数据集和上下文的学习方案,而不是标准的机器学习方法。
根据同行评审出版物编制数据集的另一个挑战是使用外部参考文献。手稿中会引用多篇文献来支持当前的研究。因此,训练数据必须适当考虑外部参考文献,减少错觉,并提供有理有据的假设。许多大型语言模型在被要求提供参考文献时都会产生错觉,在生成科学手稿时可能会产生虚构的参考文献。这说明有必要在训练数据中适当加入外部参考文献。
应对这些挑战需要出版商、政府、行业和学术界之间的密切合作。MatSci-LLM 还需要新的机器学习解决方案。例如,需要计算机视觉技术将扫描文件转换为文本,同时尊重其原始格式,还需要新的方法来处理外部参考资料和多模态数据。这些解决方案的影响可能超出材料科学领域,也可能影响到较早的历史文献的数字化,如历史、法律和金融文件。
MatSci-LLM 应用路线图
MatSci-LLM 在材料设计端到端自动化中的应用提供了非常令人兴奋的机会。自动化材料设计可以加速对材料科学中复杂问题的理解。下图概述了以 MatSci-LLM 为核心的端到端材料发现框架。
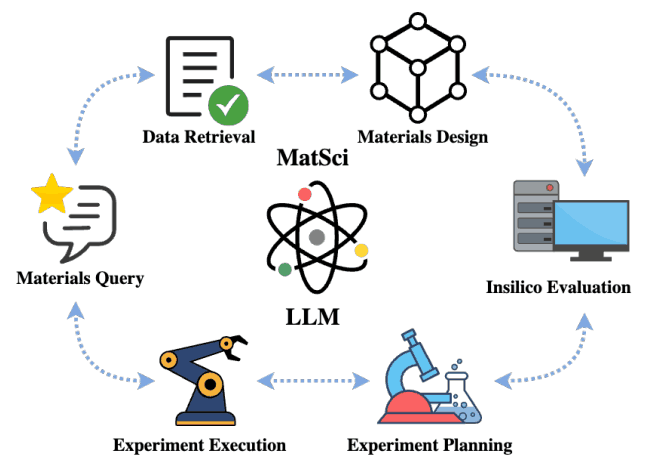
MatSci-LLM 有可能提供三项突破性功能:第一,通过自动生成知识库,增强材料科学知识并提高人类理解能力;第二,自动人工智能辅助材料生成和模拟高精度的第二,自动人工智能辅助材料生成和模拟高精度第三,实现现实世界材料合成和表征的自动化实验室。
最近的研究利用大规模语言模型将特定领域的知识以结构化的形式外部化,从而扩大了科学知识的可用性。例如,Cox 等人生成了 15000 多个蛋白质编码数据库的注释,Buehler 将大规模语言模型中的知识外部化为结构化的知识图谱。这样,科学家就可以利用这些知识加深理解,并在必要时进行修正和调整。这样的知识库是材料科学与技术各领域工程应用的宝贵资源。
MatSci-LLM 在提供人机界面方面也有很大潜力。自然语言的易用性以及理解和生成大规模语言模型文本的能力有望简化复杂的科学流程。例如,代码生成可用于协助发现新材料和执行模拟工作流程:在布勒的研究中,大规模语言模型以 SMILES 符号生成了新的分子化合物,并询问代理执行相关计算,从而产生了聚合物材料的展示了端到端的设计。这样,MatSci-LLM 也可以作为生成新材料的模型,在补充现有技术的同时提出新的材料解决方案。
将模拟材料带入现实,并使实验和模拟结果相匹配,是端到端材料设计的最终目标,而 MatSci-LLM 是加速实验设计和执行的强大工具。最近的研究利用人机界面来发现和合成复杂的材料系统。此外,还开发了自动、自驱动的材料实验室。这使得 MatSci-LLM 能够促进参与实验执行的不同机器之间的协作,从而进一步加快材料开发过程。
此外,MatSci-LLM 还为人类科学家提供了一个使用自然语言定义设计要求的界面。这样,实验工作流就可以通过大型语言模型和增强型工具来执行。如下图所示(转载于下),MatSci-LLM 执行实验工作流的能力使材料发现周期完全自动化,从而能够在现实世界中创造所需的材料。
总结
如上图所示,通过端到端自动化、发现新的物理和化学关系并用人类知识加以补充,循环有可能为各种材料带来有影响力的科学发现。
然而,本文所描述的大规模语言模型在材料科学中的应用也有其自身的挑战,要使 MatSci-LLM 成为有效的科学助手,还需要进一步的研究。在机器学习、材料仿真、材料合成、材料表征和机器人学等多个学科的交界处取得进展,对于发展有用的研究也至关重要。这是一个值得期待未来进展的领域。
注:
源码地址:https://github.com/m3rg-iitd/matsci-llm
论文地址:https://arxiv.org/abs/2402.05200
原文地址:https://blog.csdn.net/matt45m/article/details/143667757
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!