神经网络的矢量化,训练与激活函数
我们现在再回到我们的神经元部分,来看我们如何用python进行正向传递。
单层的正向传递:
我们回到我们的线性回归的函数。我们每个神经元通过上述的方法,就可以得到我们的激发值,从而可以继续进行下一层。

我们用这个方法就可以得到我们的激发值,以及输出值。
我们用更加简便的python编码。
 我们先把我们需要用到的特征值w,b写成矩阵。
我们先把我们需要用到的特征值w,b写成矩阵。
def dense(a_in, W, b, g):
units = W.shape[1]
a_out = np.zeros(units)
for j in range(units):
w = W[:, j]
z = np.dot(w, a_in) + b[j]
a_out[j] = g(z)
return a_out我们在下面继续每一层,正向传递。
def sequential (x):
a1 = dense(x, W, b )
a2 = dense(a1, W, b )
a3 = dense(a2, W, b )
a4 = dense(a3, W, b )
f_x = a4
return f_x这样子我们就可以进行一个完整的神经网络。
Ai中的ANI和AGI
实际上,我们的AI分为两个部分,第一部分叫做ANI,也就是人工狭义智能,它也就是现在我们很多人在研究的部分,而AGI被称为是人工智能,它是更加贴近于我们人的AI。
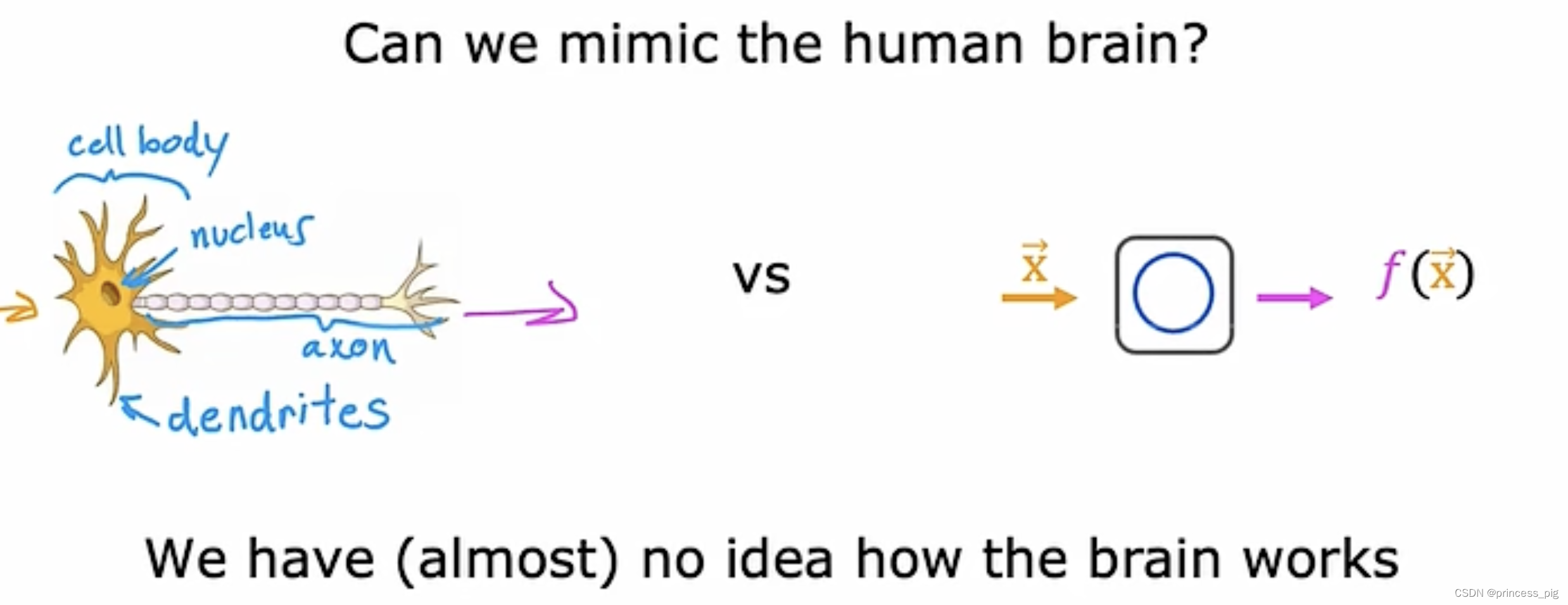
但是我们对于人脑的研究也并不完全,导致我们做出的根据神经元做出的结构也远不能达到人工智能的标准。
神经网络的矢量化实现:
在神经网络的矢量化,可以让我们的正向传统更加的简便。与我们之前的用循环的方式不同的是,
W = np.array([[1, -3, 5],
[2, -4, 6]])
b = np.array([[1, 1, 2]])
a_in = np.array([[2, -4]])
def dense(a_in, W, b, g):
units = W.shape[1]
a_out = np.zeros(units)
for j in range(units):
w = W[:, j]
z = np.dot(w, a_in) + b[j]
a_out[j] = g(z)
return a_out上述的是之前我们使用循环写成的一个神经层的输入与输出。
W = np.array([[1, -3, 5],
[2, -4, 6]])
b = np.array([[1, 1, 2]])
a_in = np.array([[2, -4]])
def dense(a_in, W, b, g):
#通过我们的矩阵乘法,我们可以得到我们需要的矩阵
Z = np.matmul(a_in,W) + b
#使用我们的激发函数,得到我们的输出,也是一个矩阵
A_out = g(Z)
#返回我们的矩阵
return A_out
[[1,-1]]我们把我们在循环的方法换成了我们的矢量相乘的方法,这个方法很好的帮我们的代码得到了大量的简便。
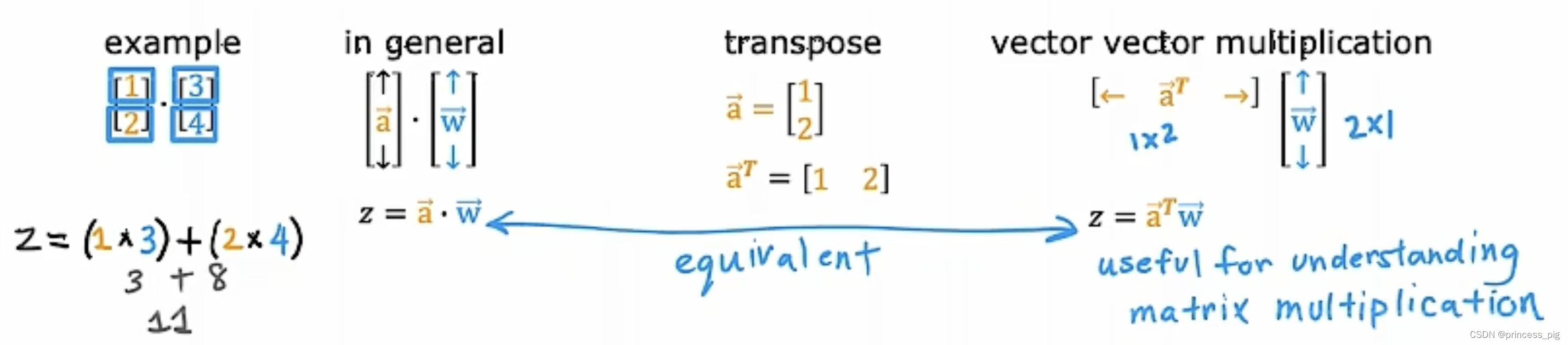
向量的基本性质:
这部分不做过多的解释。


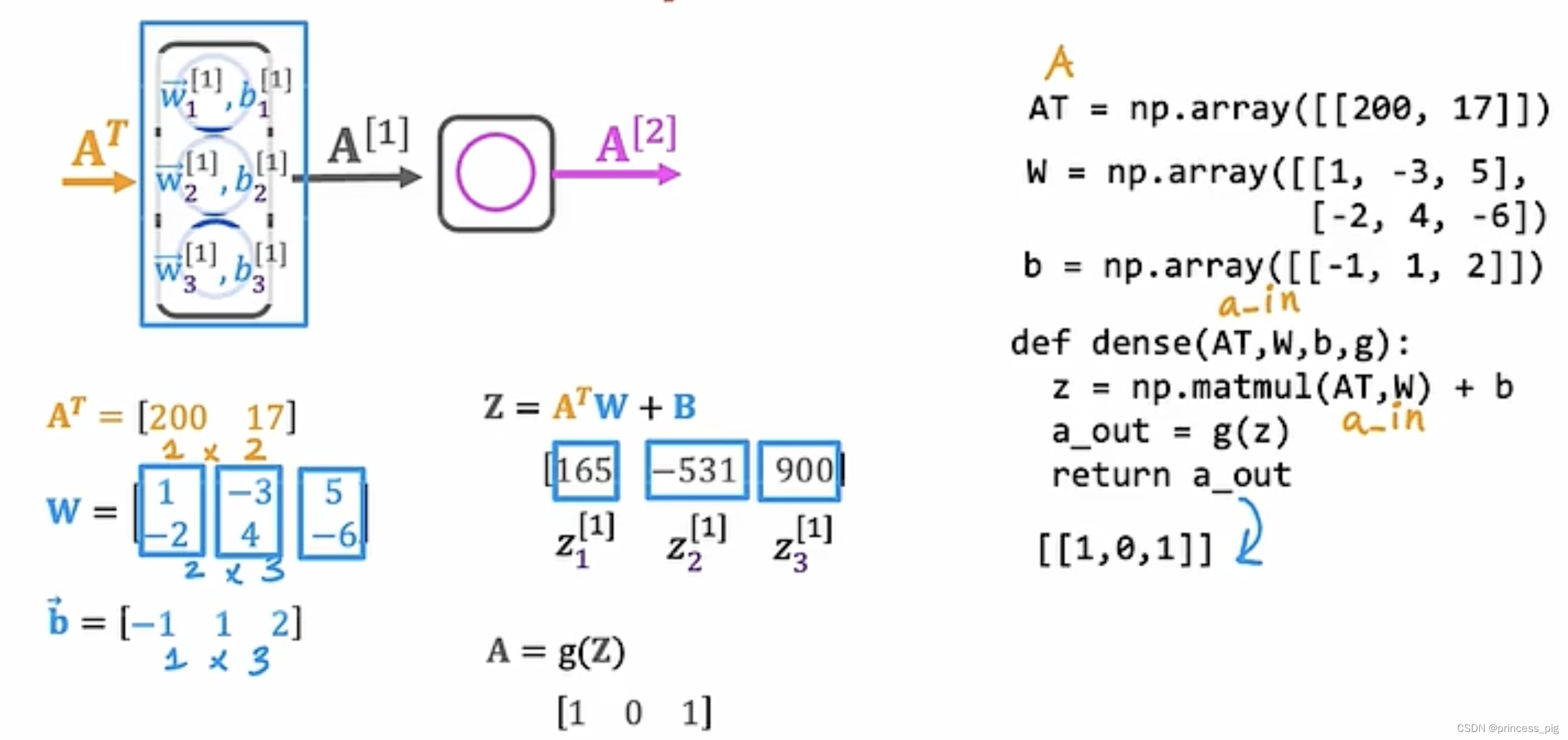
用程序写矩阵乘法:
A = np.array([[1,-1,-0.1],
[2,-2,-0.2]])
AT = np.array([[1,2],
[-1,-2],
[-0.1,-0.2]])
#用T来进行转制
AT = A.T
W = np.array([[3,5,7,9],
[2,4,8,0]])
#矩阵乘法
Z = np.matmul(AT,W)
#也可以用@
z = AT @ W
 训练神经网络:
训练神经网络:
我们在训练神经网络中,主要有三步骤:
1.计算推理,2. 利用特定的损失函数编译模型,3.训练模型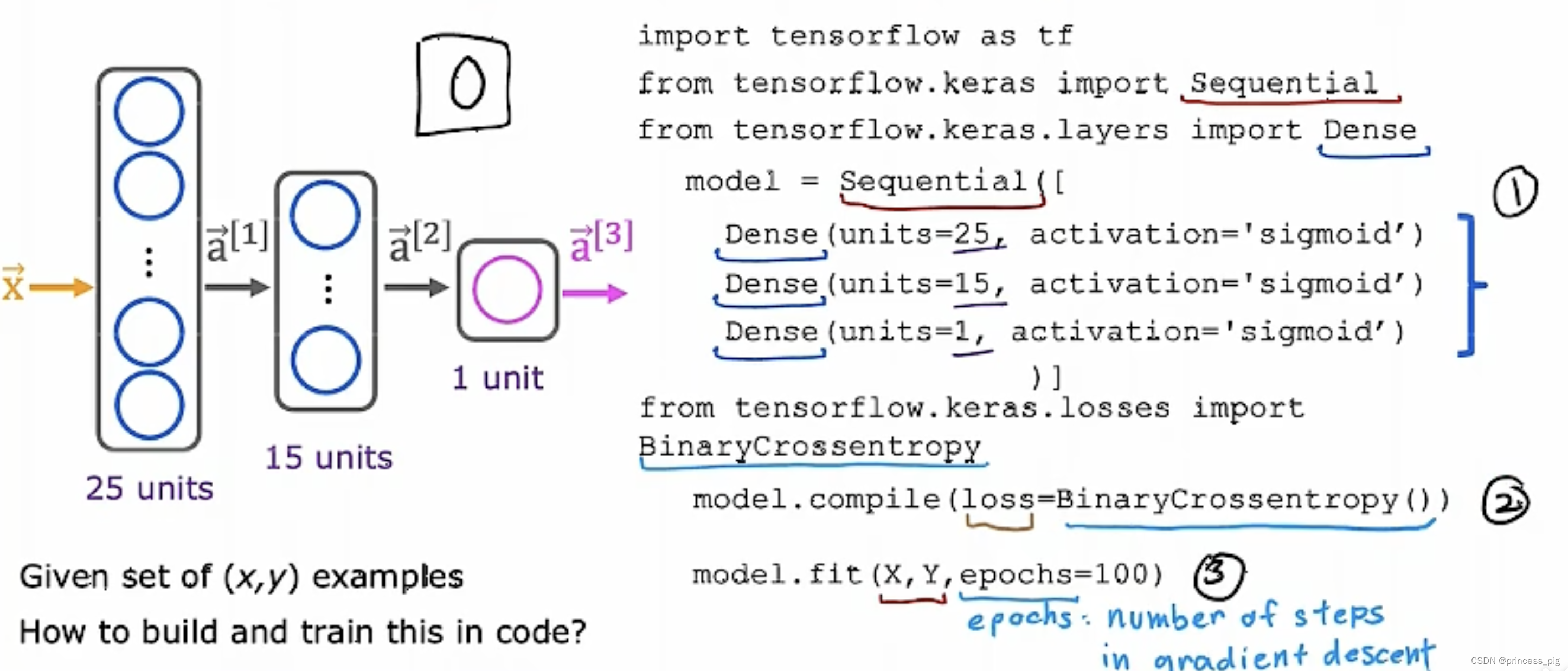

接下来,我们从逻辑回归的 角度去寻找我们如何在tensor flow来训练我们的神经网络。
第一步创建模型:
import tensorflow as tf
import numpy as np
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
model = Sequential([
Dense(units=25, activation="sigmoid"),
Dense(units=15, activation="sigmoid"),
Dense(units=1, activation="sigmoid")
])
第二步指定损失函数:
我们在这里用到一个函数叫做:BinaryCrossentropy(),它作为我们的逻辑函数的损失函数。
from tensorflow.keras.losses import BinaryCrossentropy
model.compile(loss=BinaryCrossentropy())当然,这个是用于我们的逻辑回归的,当我们只需要解决回归问题时,我们用到的是MeanSquaredError()这个方法。
from tensorflow.keras.losses import MeanSquaredError
model.compile(loss=MeanSquaredError())
第三步梯度下降,最小化成本函数:
在这里我们为了去训练我们的数据,我们用到的是逆向传递的算法。也就是我们的fit()函数 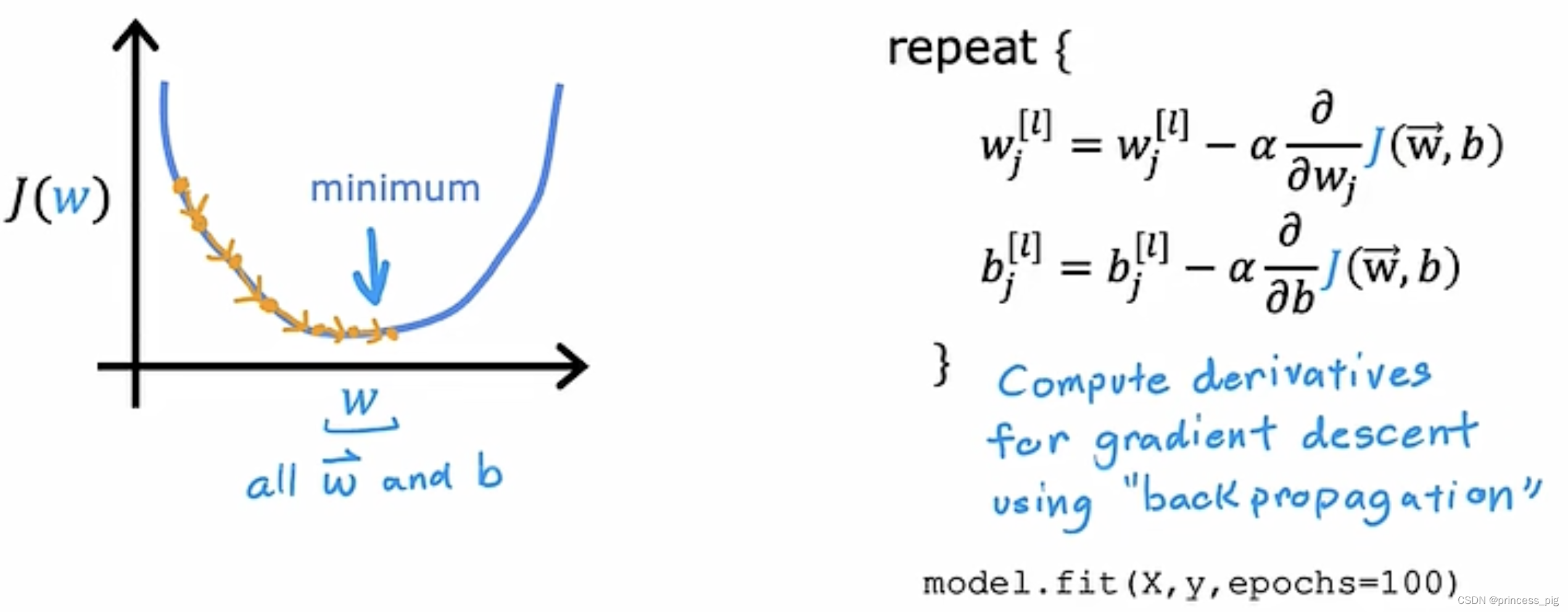
model.fit(X,y,epochs=100)epochs指的是进行100训练。
不同的激活函数:

我们在这里介绍了一个RELU的激活函数:简单来说它就是我们的取0和Z中的最大值 。
还有一个是我们的,它似乎和加上这个激活函数的效果没有任何变化,所以它也被我们叫做线性激活函数。
上图三个激活函数,是我们使用的比较多的。
选择激活函数:
选择我们对应的激活函数,我们主要观察的就是我们的所要求得的值的范围。
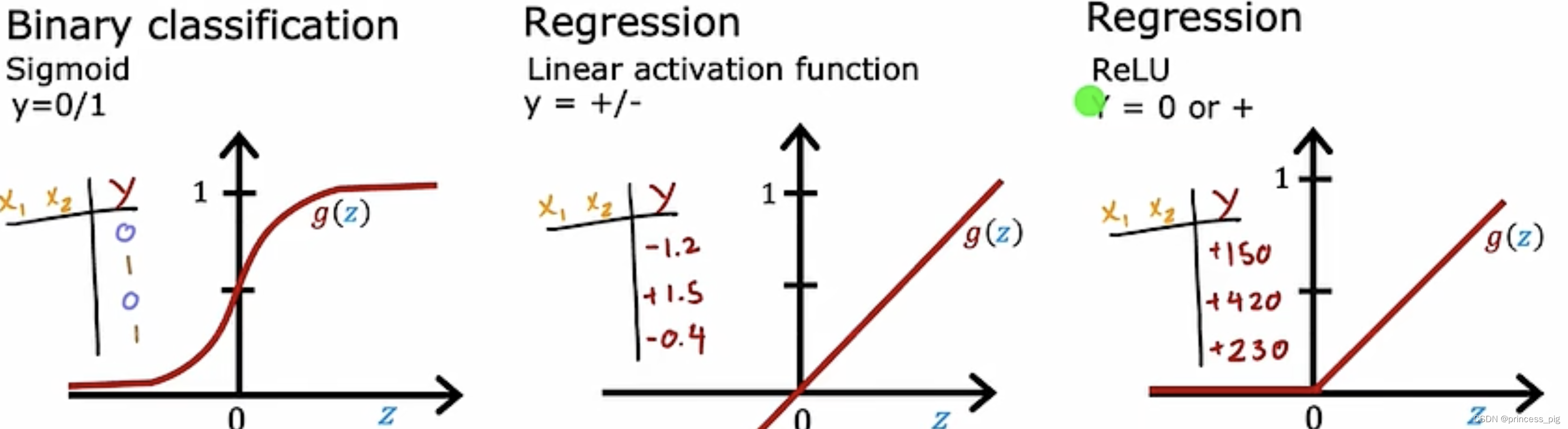
比如:我们用到了我们的sigmoid函数 ,就用在我们需要得到1或着0时,而我们的线性激活函数,则用在我们输出无论正负的范围,而我们的ReLu函数,则是对于大于0的部分。
在我们使用我们的激活函数时,函数的平坦度会影响我们梯度下降的速度,会导致我们的成本函数取到最小值的时间变长,但我们用ReLu函数则在代码运行时,更加的快。
所以,最好的方式就是在隐藏层,我们更多是使用我们的ReLu函数,因为它的下降更加的快,对于我们函数的运行有好处,而在最后输出层,我们则可以根据我们的需要选择我们的激活函数。
Dense(units=25, activation="linear"),
Dense(units=15, activation="relu"),
Dense(units=1, activation="sigmoid")这是三个不同的激活函数的写法。
为什么我们一定要用到激活函数呢?
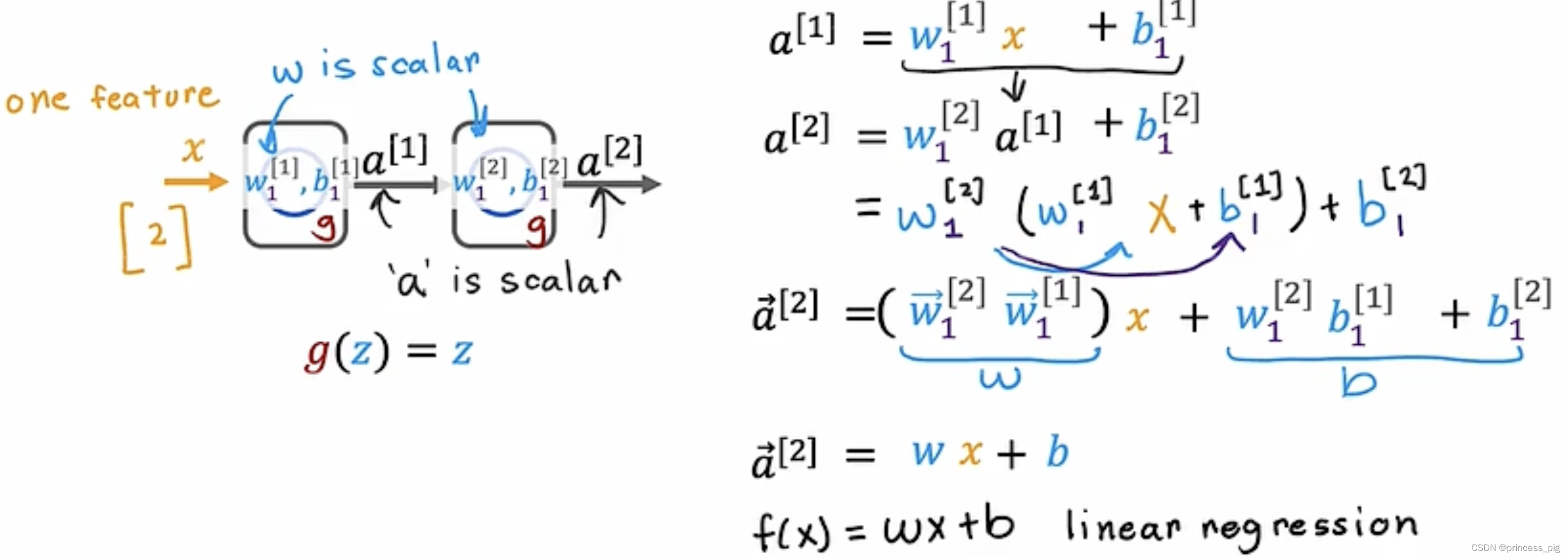
看一下,以下的推导,我们会发现无论是多少层的隐藏层和输出层,经过化简之后,我们得到的依旧是一个线性回归的式子,这样我们就可以只使用我们的线性回归就可以完成这个模型。所以在这里有一个共识就是不要在我们的隐藏层里使用我们的线性激活函数。
原文地址:https://blog.csdn.net/princess_pig/article/details/136543771
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!