CUDA编程模型
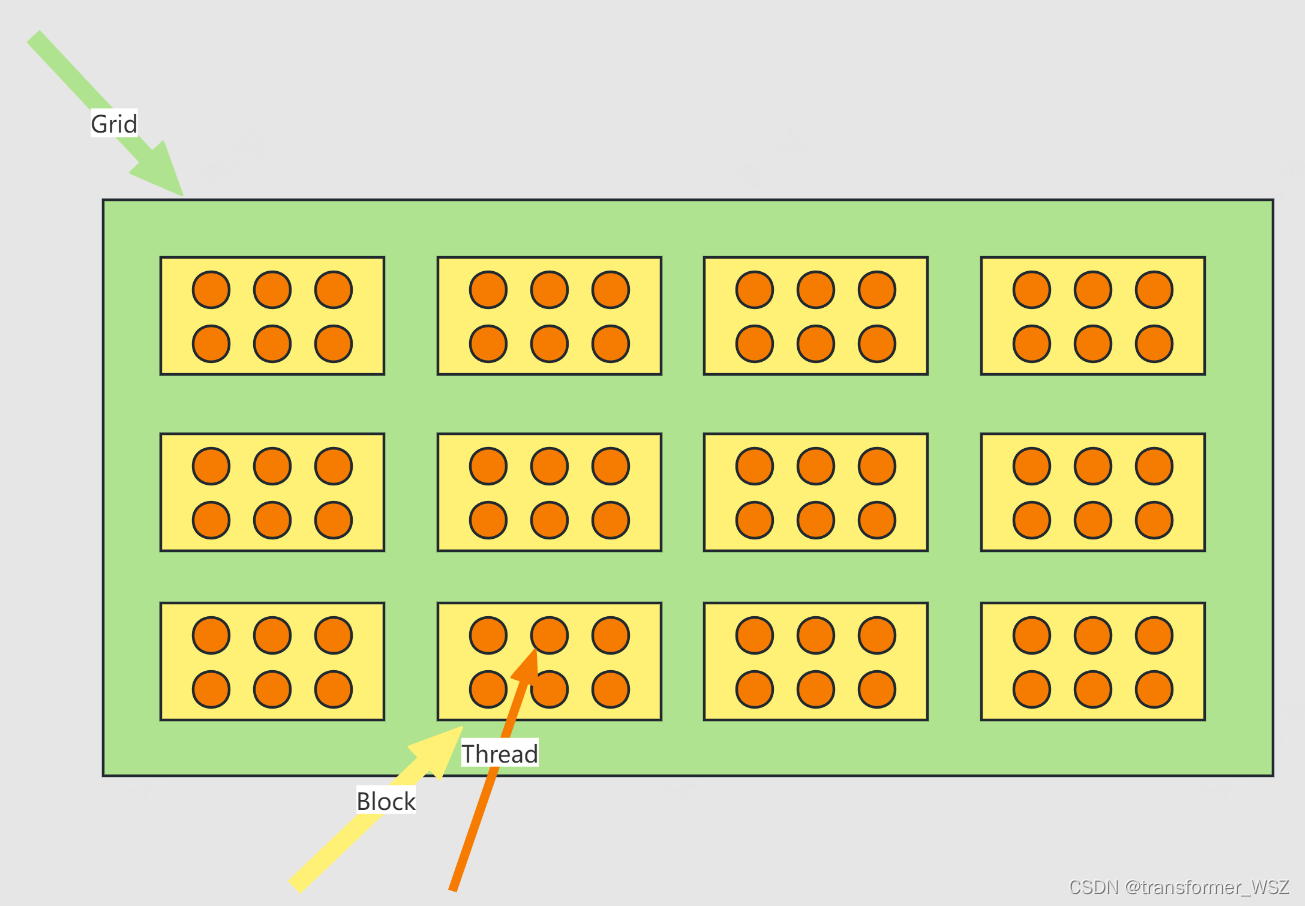
参照数学坐标系,grid的规格是 ( 4 , 3 ) (4,3) (4,3) ,block的规格是 ( 3 , 2 ) (3,2) (3,2)
对于CUDA编程模型,本质上还是要掌握并行编程思想。每一个矩阵元素运算,都是由一条线程执行。我们要做的就是找到线程坐标位置及其对应的矩阵元素,然后执行计算逻辑。
下面是一个二维矩阵相加示例:
cudastart.h
#ifndef CUDASTART_H
#define CUDASTART_H
#define CHECK(call)\
{\
const cudaError_t error=call;\
if(error!=cudaSuccess)\
{\
printf("ERROR: %s:%d,",__FILE__,__LINE__);\
printf("code:%d,reason:%s\n",error,cudaGetErrorString(error));\
exit(1);\
}\
}
#include <time.h>
#ifdef _WIN32
#include <windows.h>
#else
#include <sys/time.h>
#endif
double cpuSecond()
{
struct timeval tp;
gettimeofday(&tp,NULL);
return((double)tp.tv_sec+(double)tp.tv_usec*1e-6);
}
void initialData(float* ip,int size)
{
time_t t;
srand((unsigned )time(&t));
for(int i=0;i<size;i++)
{
ip[i]=(float)(rand()&0xffff)/1000.0f;
}
}
void initDevice(int devNum)
{
int dev = devNum;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp,dev));
printf("Using device %d: %s\n",dev,deviceProp.name);
CHECK(cudaSetDevice(dev));
}
void checkResult(float * hostRef,float * gpuRef,const int N)
{
double epsilon=1.0E-8;
for(int i=0;i<N;i++)
{
if(abs(hostRef[i]-gpuRef[i])>epsilon)
{
printf("Results don\'t match!\n");
printf("%f(hostRef[%d] )!= %f(gpuRef[%d])\n",hostRef[i],i,gpuRef[i],i);
return;
}
}
printf("Check result success!\n");
}
#endif
sum_martix.cu
#include <cuda_runtime.h>
#include <stdio.h>
#include "cudastart.h"
// CPU对照组,用于对比加速比
void sumMatrix2DonCPU(float *MatA, float *MatB, float *MatC, int nx, int ny)
{
float *a = MatA;
float *b = MatB;
float *c = MatC;
for (int j = 0; j < ny; j++)
{
for (int i = 0; i < nx; i++)
{
c[i] = a[i] + b[i];
}
c += nx;
b += nx;
a += nx;
}
}
// 核函数,每一个线程计算矩阵中的一个元素。
__global__ void sumMatrix(float *MatA, float *MatB, float *MatC, int nx, int ny)
{
int ix = threadIdx.x + blockDim.x * blockIdx.x;
int iy = threadIdx.y + blockDim.y * blockIdx.y;
// 找到该线程的坐标位置
int idx = ix + iy * nx;
if (ix < nx && iy < ny)
{
MatC[idx] = MatA[idx] + MatB[idx];
}
}
// 主函数
int main(int argc, char **argv)
{
// 设备初始化
printf("strating...\n");
initDevice(0);
// 输入二维矩阵,4096*4096,单精度浮点型。
int nx = 1 << 12;
int ny = 1 << 13;
int nBytes = nx * ny * sizeof(float);
// Malloc,开辟主机内存
float *A_host = (float *)malloc(nBytes);
float *B_host = (float *)malloc(nBytes);
float *C_host = (float *)malloc(nBytes);
float *C_from_gpu = (float *)malloc(nBytes);
initialData(A_host, nx * ny);
initialData(B_host, nx * ny);
// cudaMalloc,开辟设备内存
float *A_dev = NULL;
float *B_dev = NULL;
float *C_dev = NULL;
CHECK(cudaMalloc((void **)&A_dev, nBytes));
CHECK(cudaMalloc((void **)&B_dev, nBytes));
CHECK(cudaMalloc((void **)&C_dev, nBytes));
// 输入数据从主机内存拷贝到设备内存
CHECK(cudaMemcpy(A_dev, A_host, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(B_dev, B_host, nBytes, cudaMemcpyHostToDevice));
// 二维线程块,32×32
dim3 block(32, 32);
// 二维线程网格,128×128
dim3 grid((nx - 1) / block.x + 1, (ny - 1) / block.y + 1);
printf("grid.x %d, grid.y %d\n", grid.x, grid.y);
// 测试GPU执行时间
double gpuStart = cpuSecond();
// 将核函数放在线程网格中执行
sumMatrix<<<grid, block>>>(A_dev, B_dev, C_dev, nx, ny);
CHECK(cudaDeviceSynchronize());
double gpuTime = cpuSecond() - gpuStart;
printf("GPU Execution Time: %f sec\n", gpuTime);
// 在CPU上完成相同的任务
cudaMemcpy(C_from_gpu, C_dev, nBytes, cudaMemcpyDeviceToHost);
double cpuStart = cpuSecond();
sumMatrix2DonCPU(A_host, B_host, C_host, nx, ny);
double cpuTime = cpuSecond() - cpuStart;
printf("CPU Execution Time: %f sec\n", cpuTime);
// 检查GPU与CPU计算结果是否相同
CHECK(cudaMemcpy(C_from_gpu, C_dev, nBytes, cudaMemcpyDeviceToHost));
checkResult(C_host, C_from_gpu, nx * ny);
cudaFree(A_dev);
cudaFree(B_dev);
cudaFree(C_dev);
free(A_host);
free(B_host);
free(C_host);
free(C_from_gpu);
cudaDeviceReset();
return 0;
}
编译 sum_martix.cu 文件并执行程序:
nvcc -o sum_matrix sum_martix.cu && ./sum_matrix
参考
原文地址:https://blog.csdn.net/transformer_WSZ/article/details/136360049
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!