代码随想录 | Day36 | 动态规划 :整数拆分&不同的二叉搜索树
代码随想录 | Day36 | 动态规划 :整数拆分&不同的二叉搜索树
动态规划学习:
1.思考回溯法(深度优先遍历)怎么写
注意要画树形结构图
2.转成记忆化搜索
看哪些地方是重复计算的,怎么用记忆化搜索给顶替掉这些重复计算
3.把记忆化搜索翻译成动态规划
基本就是1:1转换
343.整数拆分
思路分析:
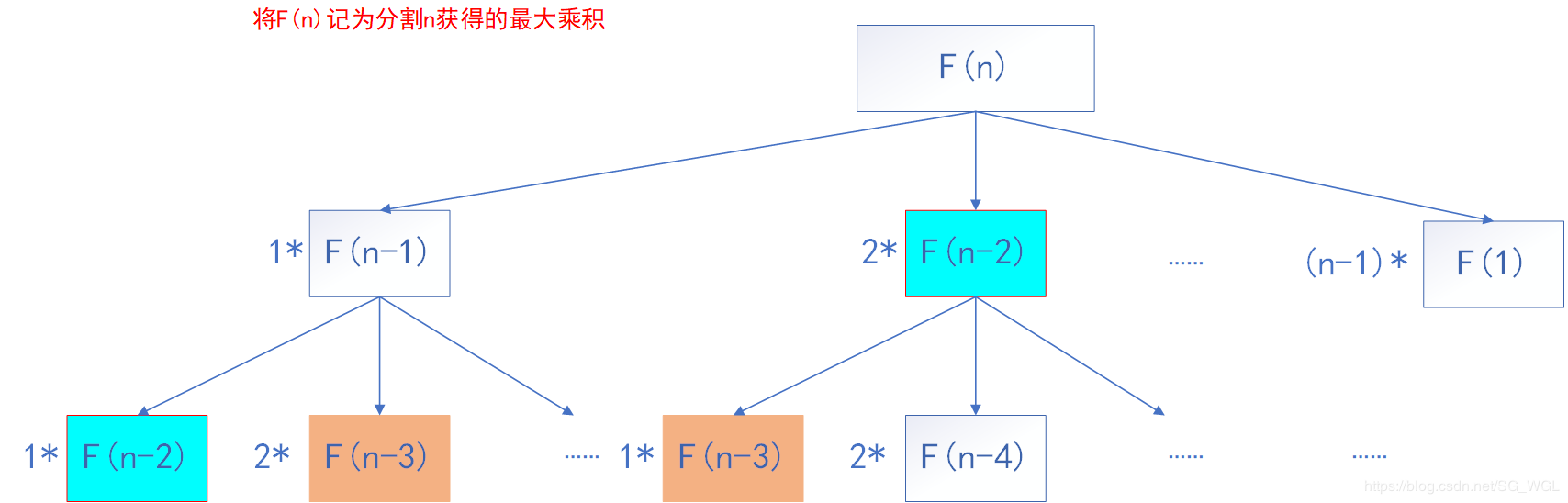
我们要把n分解,就把f(n)当做是分解后返回的乘积结果
那很明显,f(n)可以分为
{i*f(n-i) | 1<i<n-1} f(n-1)会继续分,和图中一样
然后我们会从中选一个最大的出来,作为我们的结果返回
而这里我们会注意到
i*f(n-i)需要和i*(n-i)比大小,我们要选择那个大的,决定我们是否要继续分解下去
如果说没有分解过的后者已经比前者大了,那就没必要分解了,直接返回大的就行
举个例子:
当i是1而n是3
i*f(n-i)=1*f(2)=1*1=1
i*(n-i)=1*2=2
由此我们得到了本层逻辑的大概框架
i*f(n-i)和i*(n-i)比大小,我们挑一个大的进行返回
1.回溯 DFS
1.返回值和参数
dfs就是前面的f,我们要向上返回分解n-i后的结果f(n-i)即dfs(n-i)所以返回值为int
传入值就为n,就是要分解的那个数
int dfs(int n)
2.终止条件
dfs(2)=1,因为2只能拆成1*1
而dfs(1)和dfs(0)都没办法拆分,不需要考虑,或者都返回1也是可以的
if(n==2)
return 1;
3.本层逻辑
这里就是上面思路部分说的
i*f(n-i)和i*(n-i)比大小,我们挑一个大的进行返回
max(i*(n-i),i*dfs(n-i))
而res记录的是树形结构同一层中的最大值,也是我们要向上层返回的最后结果,因为最大的乘以最大的肯定还是最大的,因此我们要再套一个max
int res=-1;
for(int i=1;i<n;i++)
res=max(res,max(i*(n-i),i*dfs(n-i)));
完整代码:
当然,这是超时的
class Solution {
public:
int dfs(int n)
{
if(n==2)
return 1;
int res=-1;
for(int i=1;i<n;i++)
res=max(res,max(i*(n-i),i*dfs(n-i)));
return res;
}
int integerBreak(int n) {
return dfs(n);
}
};
//lambda
class Solution {
public:
int integerBreak(int n) {
function<int(int)> dfs=[&](int n)->int{
if(n==2)
return 1;
int res=-1;
for(int i=1;i<n;i++)
res=max(res,max(i*(n-i),i*dfs(n-i)));
return res;
};
return dfs(n);
}
};
这是笔者第一次写的dfs,能过就是不好改成备忘录,故不做讲解,感兴趣的小伙伴看看就好
class Solution {
public:
int res=INT_MIN;
void dfs(int n,int sum,int index)
{
if(n<=1)
return ;
for(int i=index;i<n;i++)
{
int temp=sum*i*(n-i);
res=max(res,temp);
dfs(n-i,sum*i,i);
}
}
int integerBreak(int n) {
dfs(n,1,1);
return res;
}
};
2.记忆化搜索
加入dp数组作为备忘录,初始化dp为-1
每次返回都给dp赋值之后再返回。加个if判断,碰到不是-1的说明被计算过了,直接用
因为每次的返回值其实都是拆分以后要往上返回的结果,就是f(n-i)
举个例子,n=10,i=3
那我们f(n-i)=f(10-3)=f(7),也就是dfs(7)的返回值就是dp[7],就是7的拆分后能达到的最大值,所以就要把这个记录下来
class Solution {
public:
int dfs(int n,vector<int>& dp)
{
if(n==2)
return dp[n]=1;
int res=-1;
for(int i=1;i<n;i++)
{
if(dp[n-i]!=-1)
res=max(res,max(i*(n-i),i*dp[n-i]));
else
res=max(res,max(i*(n-i),i*dfs(n-i,dp)));
}
return dp[n]=res;
}
int integerBreak(int n) {
vector<int> dp(n+1,-1);
return dfs(n,dp);
}
};
//lambda
class Solution {
public:
int integerBreak(int n) {
vector<int> dp(n+1,-1);
function<int(int)> dfs=[&](int n)->int{
if(n==2)
return dp[n]=1;
int res=-1;
for(int i=1;i<n;i++)
{
if(dp[n-i]!=-1)
res=max(res,max(i*(n-i),i*dp[n-i]));
else
res=max(res,max(i*(n-i),i*dfs(n-i)));
}
return dp[n]=res;
};
return dfs(n);
}
};
3.动态规划
怎么由记忆搜索改到动态规划呢?
首先dp数组和下标含义就是dp[i]就是i拆分后的最大值
而上面递归函数里面有一个for循环,那说明我们再函数中应该再加一层循环,用来循环递归函数的参数n,笔者使用j代替参数n
每次返回之前都会把返回值给记录一下,其实当时的返回值就是当时的dp[n],也就是说外层循环变量j顶替的就是n的角色,所以
dp[n]=res=dp[j]
直接把res的地方都替换成为dp[j]。这样就完成了从记忆搜索到递推的转变
1.确定dp数组以及下标的含义
dp数组和下标含义就是dp[i]就是i拆分后的最大值
2.确定递推公式
忘记了原因的请看思路分析部分
dp[j]顶替的是dp[n]即res的位置
dp[j]=max(dp[j],max(i*(j-i),i*dp[j-i]));
3.dp数组如何初始化
初始化为负数就行,因为要得到最大值
dp[2]=1是2拆分后的结果已知,就是1
vector<int> dp(n+1,-1);
dp[2]=1;
4.确定遍历顺序
后续结果需要依赖前面的计算结果,故使用从前往后遍历
注意一个小细节是这里的j可以取到n,dfs的参数也可以取到n,只是咱们在主函数第一次传入的就是n,大家可能没有注意这一点少写了等号导致错误。
for(int j=3;j<=n;j++)
for(int i=1;i<j;i++)
dp[j]=max(dp[j],max(i*(j-i),i*dp[j-i]));
完整代码
class Solution {
public:
int integerBreak(int n) {
vector<int> dp(n+1,-1);
dp[2]=1;
for(int j=3;j<=n;j++)
for(int i=1;i<j;i++)
dp[j]=max(dp[j],max(i*(j-i),i*dp[j-i]));
return dp[n];
}
};
96.不同的二叉搜索树
思路分析:
我们可以分别以 1,2,3,……,n 为根结点,对于一棵树,我们可以递归的构造树的左右子树,而本题求解的是二叉搜索树的种数,那么假设左子树有 x 种,右子树有 y 种,可能的二叉搜索树就有 x×y 种,举个例子,要求结点数量为3的二叉搜索树的种数:
总数=以1为根结点的二叉搜索树数量+以2为根结点的二叉搜索树数量+以3为根结点的二叉搜索树数量
以1为根结点的二叉搜索树数量=左子树搜索树数量(0个节点)+右子树搜索树数量(2个节点)
以2为根结点的二叉搜索树数量=左子树搜索树数量(1个节点)+右子树搜索树数量(1个节点)
以3为根结点的二叉搜索树数量=左子树搜索树数量(2个节点)+右子树搜索树数量(0个节点)
如果是n的话那就是
总数=以1为根结点的二叉搜索树数量+以2为根结点的二叉搜索树数量+以3为根结点的二叉搜索树数量+…+以n为根结点的二叉搜索树数量
所以我们肯定需要一个for循环来遍历1~~n
1.回溯 DFS
1.返回值和参数
很明显我们传入的n表示我们算上n结点一共有几个结点
返回值就返回n个结点有多少种可能的二叉搜索树
int dfs(int n)
2.终止条件
当我们传的节点只有1个或者0个,那就返回1,这种情况只会有一种搜索树
if(n<=1)
return 1;
3.本层逻辑
for循环遍历从1到我们传入的n
而dfs是得出子树的搜索树数量
左子树l有i个节点,右子树r就是n-i-1个节点
那么对于以i为根结点的二叉搜索树一共有l*r种搜索树
而sum是把以1~~n为根结点的各种情况下的i累加起来得到一个总数
最后返回我们得到的总数sum
int sum=0;
for(int i=0;i<n;i++)
{
int l=dfs(i);
int r=dfs(n-i-1);
sum+=l*r;
//sum+=dfs(i)+dfs(n-i-1);
}
return sum;
完整代码:
class Solution {
public:
int dfs(int n)
{
if(n<=1)
return 1;
int sum=0;
for(int i=0;i<n;i++)
{
int l=dfs(i);
int r=dfs(n-i-1);
sum+=l*r;
//sum+=dfs(i)+dfs(n-i-1);
}
return sum;
}
int numTrees(int n) {
return dfs(n);
}
};
class Solution {
public:
int numTrees(int n) {
function<int(int)> dfs=[&](int n)->int{
if(n<=1)
return 1;
int sum=0;
for(int i=0;i<n;i++)
{
int l=dfs(i);
int r=dfs(n-i-1);
sum+=l*r;
//sum+=dfs(i)+dfs(n-i-1);
}
return sum;
};
return dfs(n);
}
};
2.记忆化搜索
其实写dfs的时候就想顺手把记忆数组给加上了。
加入dp数组作为备忘录,初始化dp为-1。
每次返回都给dp赋值之后再返回。加个if判断,碰到不是-1的说明被计算过了,直接用。
class Solution {
public:
int dfs(int n,vector<int> &dp)
{
if(n<=1)
return dp[n]=1;
if(dp[n]!=-1)
return dp[n];
int sum=0;
for(int i=0;i<n;i++)
sum+=dfs(i,dp)*dfs(n-i-1,dp);
return dp[n]=sum;
}
int numTrees(int n) {
vector<int> dp(n+1,-1);
return dfs(n,dp);
}
};
//lambda
class Solution {
public:
int numTrees(int n) {
vector<int> dp(n+1,-1);
function<int(int)> dfs=[&](int n)->int{
if(n<=1)
return dp[n]=1;
if(dp[n]!=-1)
return dp[n];
int sum=0;
for(int i=0;i<n;i++)
sum+=dfs(i)*dfs(n-i-1);
return dp[n]=sum;
};
return dfs(n);
}
};
3.动态规划
怎么由记忆搜索改到动态规划呢?
首先dp数组和下标含义是dp[i]就是有i个结点的话能有多少种搜索树的数量
和上一题一样,上面递归函数里面有一个for循环,那说明我们再函数中应该再加一层循环,用来循环递归函数的参数n,笔者使用j代替参数n
每次返回之前都会把返回值给记录一下,其实当时的返回值就是当时的dp[n],也就是说外层循环变量j顶替的就是n的角色,所以
dp[n]=sum=dp[j]
直接把sum的地方都替换成为dp[j]。这样就完成了从记忆搜索到递推的转变
1.确定dp数组以及下标的含义
首先dp数组和下标含义是dp[i]就是有i个结点的话能有多少种搜索树的数量
2.确定递推公式
忘记了原因的请看思路分析部分
dp[j]顶替的是dp[n]即sum的位置
dp顶替dfs的位置
sum+=dfs(i)*dfs(n-i-1);
dp[j]+=dp[i]*dp[j-i-1];
3.dp数组如何初始化
初始化为0,因为我们要进行累加求搜索树类型的总数
如果只有0个或者1个节点那就是1种搜索树类型,初始化为1
(0的话说明,n个全在右子树)
vector<int> dp(n+1,0);
dp[0]=1;
dp[1]=1;
4.确定遍历顺序
后续结果需要依赖前面的计算结果,故使用从前往后遍历
for(int j=2;j<=n;j++)
for(int i=0;i<j;i++)
dp[j]+=dp[i]*dp[j-i-1];
完整代码
class Solution {
public:
int numTrees(int n) {
vector<int> dp(n+1,0);
dp[0]=1;
dp[1]=1;
for(int j=2;j<=n;j++)
for(int i=0;i<j;i++)
dp[j]+=dp[i]*dp[j-i-1];
return dp[n];
}
};
原文地址:https://blog.csdn.net/m0_74795952/article/details/143372507
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!