AAAI 2024|ETH轻量化Transformer最新研究,浅层MLP完全替换注意力模块提升性能

论文题目: Rethinking Attention: Exploring Shallow Feed-Forward Neural Networks as an Alternative to Attention Layers in Transformers
论文链接: https://arxiv.org/abs/2311.10642
代码仓库: GitHub - vulus98/Rethinking-attention: My implementation of the original transformer model (Vaswani et al.). I've additionally included the playground.py file for visualizing otherwise seemingly hard concepts. Currently included IWSLT pretrained models.
目前,在大型语言模型(LLMs)和AIGC的双重浪潮席卷之下,AI迎来了前所未有的发展机遇。一时间,深度模型训练框架、AI算力等等已经成为社区的热点话题。作为LLMs和AIGC的基础算法backbone,Transformer模型已经成为目前最为关键的基础研究方向,对Transformer现有的注意力机制原理进行探索,并提出优化简化的方案,是目前研究的热点。
本文介绍一篇来自苏黎世联邦理工学院(ETH Zurich)的最新Transformer优化工作,目前该文已被人工智能顶级会议AAAI 2024录用。本文的核心出发点是,能否使用更加轻量经济的前馈神经网络(MLP)来替代Transformer中笨重的自注意力层,并通过知识蒸馏的方式使用原始模块进行迁移训练,作者将优化后的模型称为”attentionless Transformers“。作者在IWSLT2017等数据集上的实验验证了attentionless Transformer可以达到与原始架构相当的性能,同时进行了一系列消融实验表明,如果正确的配置参数,浅层MLP完全具有模拟注意力机制的潜力。
01. 引言
Vaswani等人在2017年发表的Transformer结构[1]从根本上改变了sequence-to-sequence建模任务的格局,从那时起,Attention Is All You Need。此外,原始Transformer论文还为机器翻译这一基础NLP任务设定了全新的基准(使用BLEU分数作为评价指标)。后续有很多工作对Transformer结构的原理进行探索,人们认为,Transformer的注意力机制能够在时序数据中建立长期依赖关系,使其能够关注序列中的每个元素,这是之前的网络架构在没有大量计算开销的情况下难以实现的效果。为了进一步缩小注意力机制的资源消耗,本文作者提出了一个大胆的设想,能否直接用更轻量的浅层MLP来模拟注意力机制的计算,虽然缺乏在理论上的推理证明,但本文通过实验表明,这种替代方式是完全有效的。
02. 本文方法
原始的Transformer架构由一系列的编码器和解码器块堆叠而成。其中编码器层有一个自注意力块,而解码器层包含自注意力块和交叉注意力块。本文针对注意力块提出了四种不同程度的MLP替换模式,这四种替换模式如下图所示。
(1)注意力层替换(Attention Layer Replacement,ALR):仅用MLP替换多头注意力(MHA)块,保留残差连接和归一化层。
(2)残差连接替换的注意力层(Attention Layer with Residual Connection Replacement,ALRR):MHA模块以及残差连接被MLP替换,这种方式可以直接消除 Transformer 中的残差连接。
(3)注意力头分离替换(Attention Separate heads Layer Replacement,ASLR):ALR的变体,该方法用单独的MLP替换MHA模块的每个单独头。
(4)编码器层替换(Encoder Layer Replacement,ELR):完全使用MLP替换编码器层。
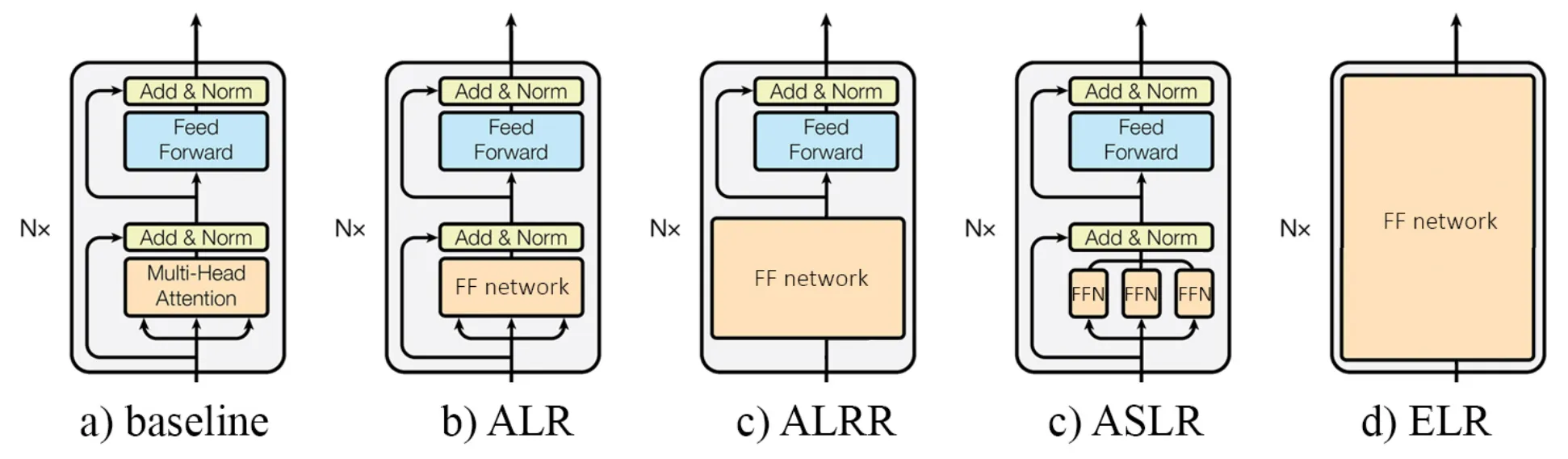
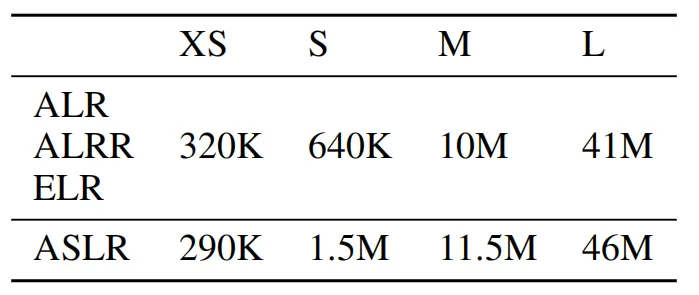
其中 ALR 和 ALRR 的设计灵感是将注意力层的性能提升与残差连接的性能提升分离开来,而ASLR则是用来模拟多头注意力层中每个单独头的操作,即直接使用MLP来代替多头注意力(MHA)。而ELR作为最高的抽象级别,直接将整个编码器块替换为MLP网络,这本质上颠覆了原始编码器架构,将Transformer转换为纯MLP结构。这种替换方式对模型整体参数规模的影响非常显著,下表展示了以上四种方式在XS、S、M和L四种尺寸下的参数大小。
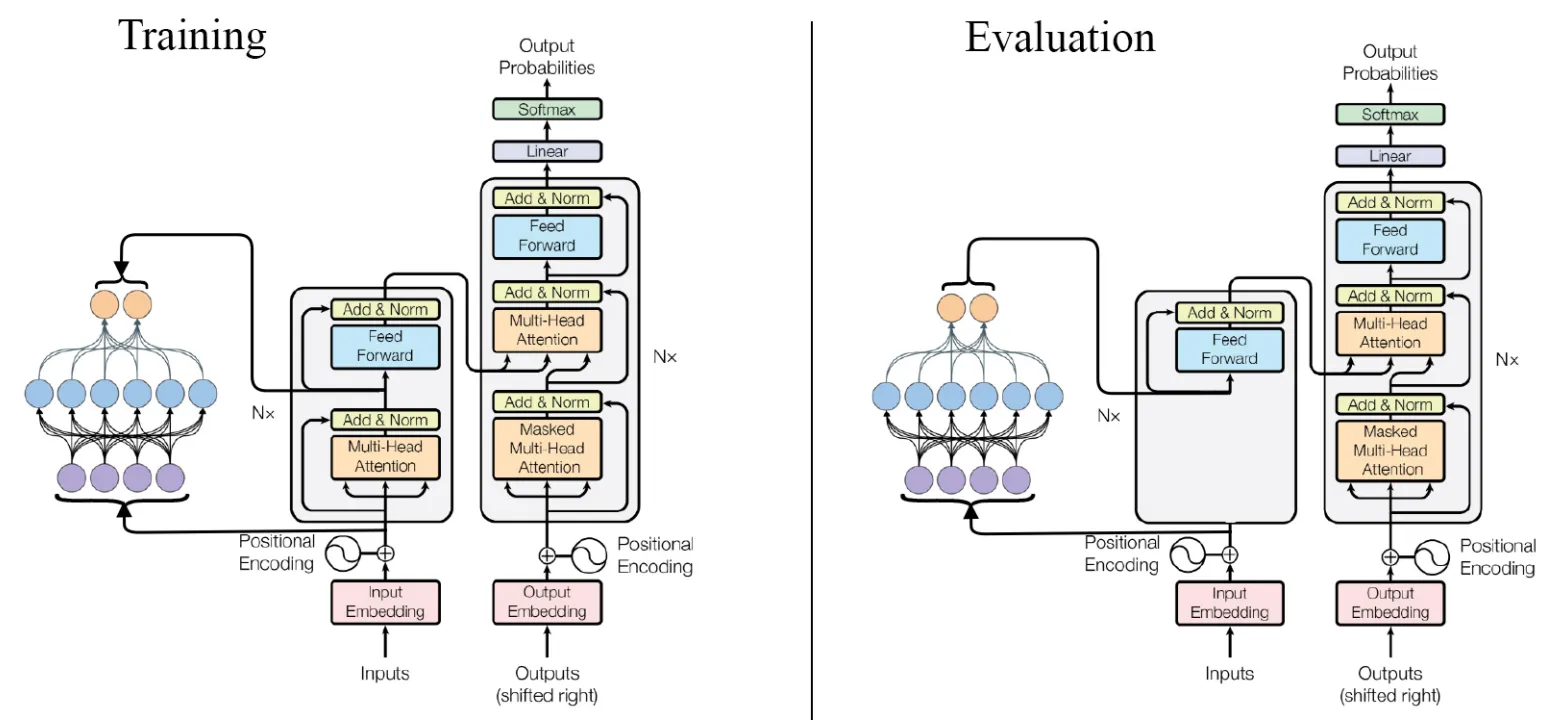
作者以ALRR模式作为样例,首先训练了原始6层编码器和6层解码器的Transformer模型作为MLP网络的教师模型,为了提高训练速度,作者将原始嵌入长度从512减少到128,这样做对模型BLEU分数的影响并不大,但其需要的计算需求会显著降低,此时模型的训练和推理流程如下图所示,使用其他三种模式的训练流程与此类似。
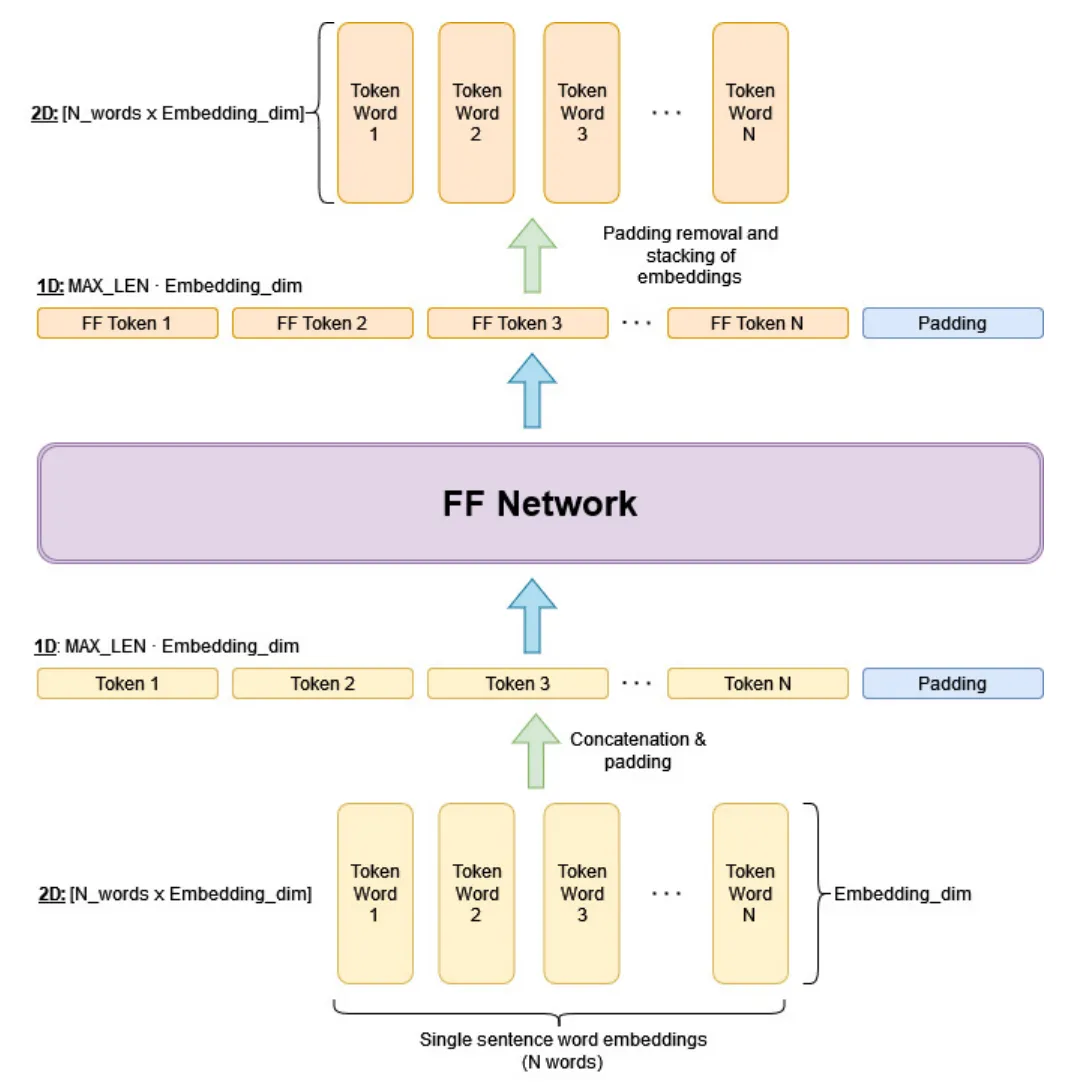
在进行知识蒸馏之前,需要从原始Transformer模型中提取中间激活值,并且对其进行额外的调整,如下图所示,首先需要在每个注意力层中将句子的输入单词表示转换为由输入表示提取的值的线性组合,随后,MLP网络需要将句子的串联单词表示作为输入,并在一次前向传播中生成更新的单词表示作为输出。为了处理不同长度的输入句子,作者直接将所有句子填充到最大固定长度,并用零屏蔽填进行占位。
当模型蒸馏结束后,直接将ALRR简化块插入到Transformer架构中替换之前的冗余层,在替换时,需要考虑对编码器中的注意力层和解码器的注意力层进行区别处理,主要区别在于,解码器中的MLP替换网络需要遵循因果Mask机制,即只有句子中前面的单词才能影响当前单词的语义,而编码器中的替换不需要考虑这一点。
03. 实验效果
本文的实验主要在 IWSLT2017 数据集上进行,该数据集提供了多个语言翻译子集,包括法语-英语(F2E)、英语-法语(E2F)、德语-英语(G2E)和英语-德语(E2G)子集,这些子集平均含有 200000 个训练句子和 1000 个测试句子。翻译后的评价指标选取BLEU分数,BLEU可以衡量模型输出结果与人类专家翻译的直观比较,下表展示了基线Transformer模型(原始模型)在四个翻译子集上的平均效果。

随后作者将本文提出的四种MLP替换模式一一进行了实验,下表首先展示了ALR(仅替换多头注意力层)模式的实验结果,其中“Enc”代表编码器,“Dec”代表解码器,“SA”代表自注意力,“CA”代表交叉注意力,E-D代表同时对编码器和解码器进行替换。从表中可以分析得出,在ALR模式下,“Dec CA”(解码器中的交叉注意力)的BLEU分数较低。
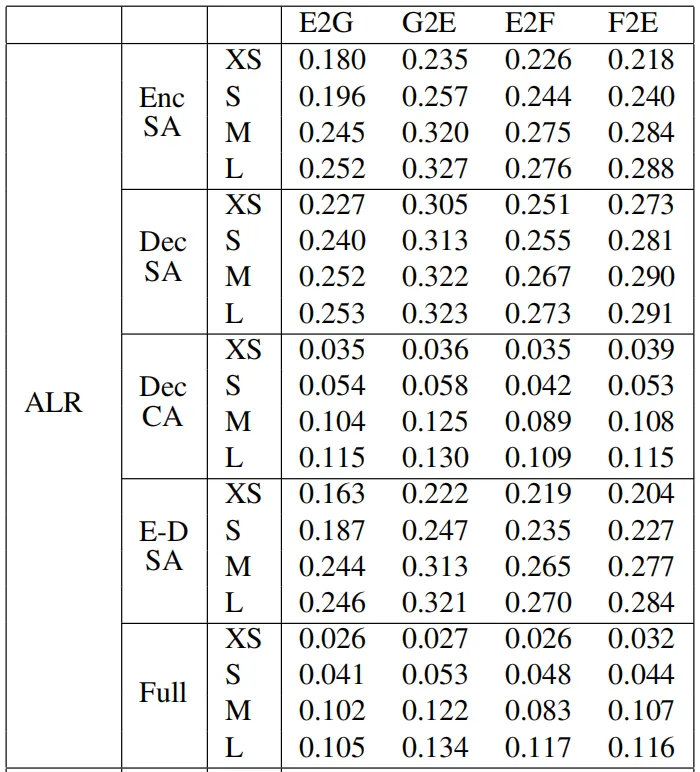
下表展示了其他三种模式:ALRR、ASLR和ELR替换后的实验效果,由于这三种模式不涉及对解码器注意力层的替换,因此模型的整体表现较好。
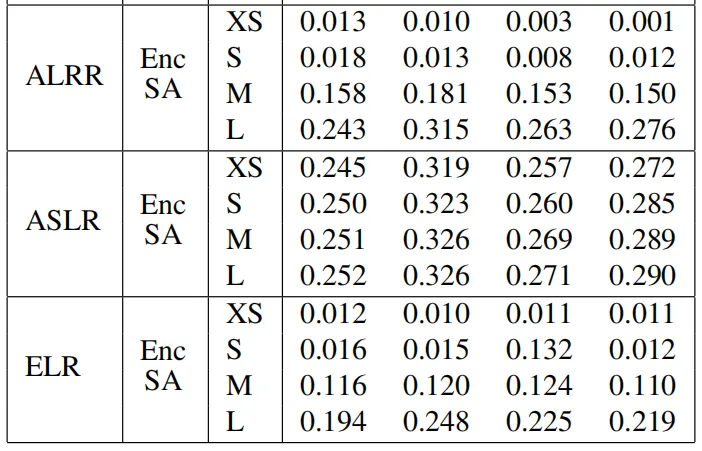
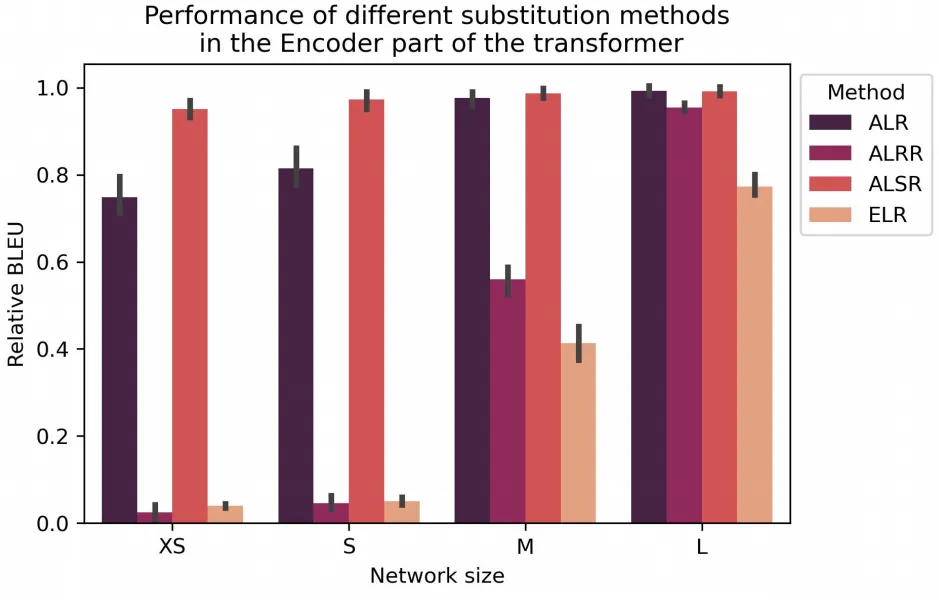
下图展示了四种替换模式与原始基线Transformer模型的BLEU分数差距,与基线相比,所有提出的替换模式都取得了有竞争力的结果,在四种替换模式中,ELR 表现最差,这是由于ELR的构建过于简单。
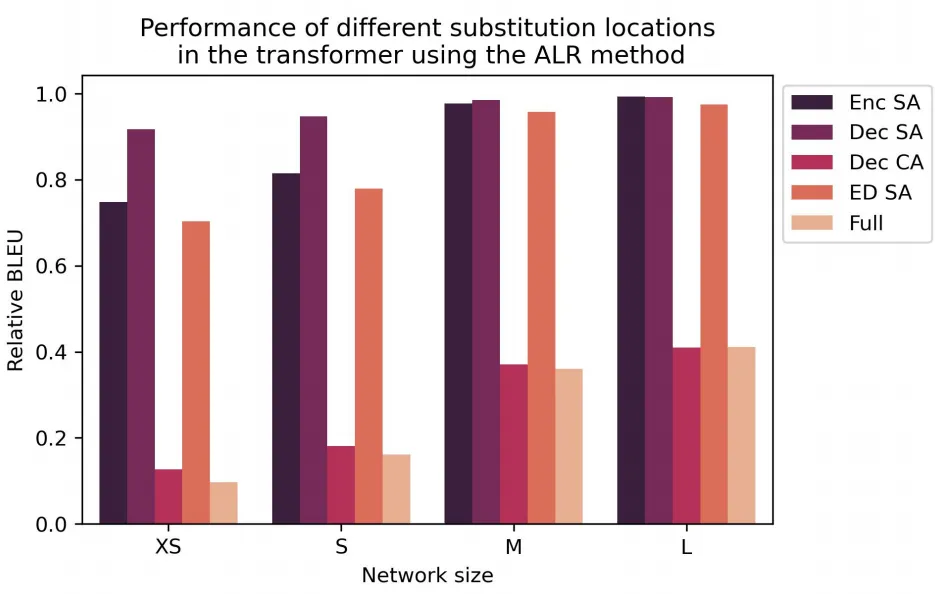
此外,作者还对ALR替换模式在Transformer中的各种替换位置进行了消融实验,如下图所示。ALR在解码器自注意力层中的替换展现出了较好的性能,而在交叉注意力块的表现较差,作者分析造成这种现象的原因是ALR简单的前向传播结构缺乏描述交叉注意力中复杂的映射交互能力,因此,目前想直接使用MLP完全替换交叉注意力层仍然无法实现,同时还有一个缺陷,当使用ALR替换时,模型将只能接受固定长度的序列作为输入,而失去原本的灵活性。
作者还提到,如果能够在对MLP替换层进行知识蒸馏的基础上,引入更加高级的参数搜索策略(例如使用贝叶斯优化)进一步优化MLP层的超参数,有可能会提升模型整体的性能,同时可以进一步缩减MLP替换层的参数量。此外,另一个潜在的研究方向就是对MLP层进行针对性设计,使其模拟交叉注意力模块中的复杂建模能力。
04. 总结
本文介绍了一种简单直接的Transformer架构优化方法,以Transformer模型中的核心操作自注意力(SA)和交叉注意力层(CA)为优化目标,直接使用简单高效的MLP层进行替换。根据替换抽象程度和模型参数缩减规模,作者提出了四种替换模式:ALR、ALRR、ASLR和ELR,然后通过知识蒸馏技术将原始Transformer模型的拟合能力迁移到这些轻量化的MLP层中。作者通过在基础NLP翻译基准上的实验表明,Transformer模型完全可以在Attention Free的情况下正常运作,但是需要保留原始的交叉注意力层。
参考
[1] Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, L.; and Polosukhin, I. 2017. Attention Is All You Need. arXiv:1706.03762.
原文地址:https://blog.csdn.net/hanseywho/article/details/135450280
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!