真实线上DB存储架构升级实战
前言
交易系统1.0的存储架构采用了单库单表,随着业务快速发展,订单量从日单量十万级别快速增长到日单量百万级别,预计在未来两三个月就存储就会出现瓶颈,DB存储架构升级迫在眉睫。
交易系统如何做到平滑迁移?
由于面对业务场景是交易系统,即使是业务低峰期,业务也无法接受临时停服,基于此背景下,设计了如下一套不停服下的数据平滑迁移工具。
平滑迁移流程设计
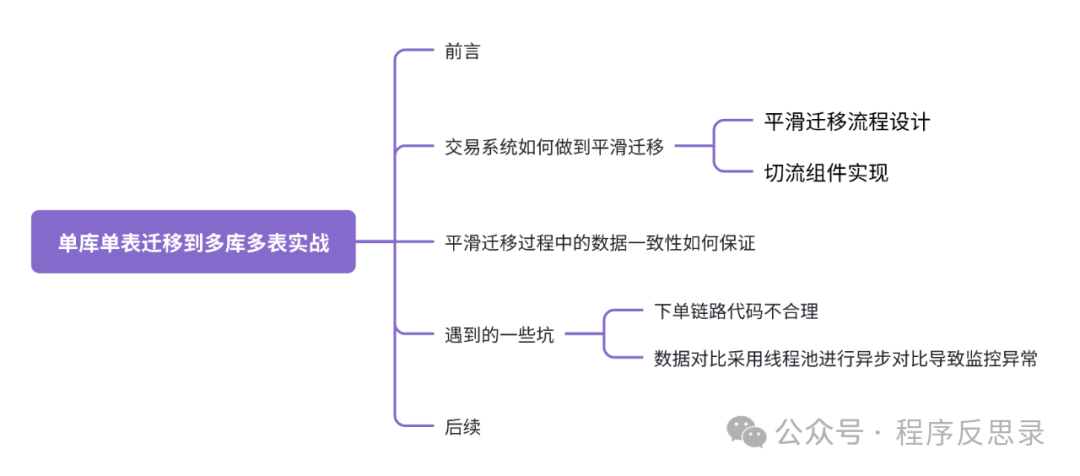
由于面对的业务场景是交易系统,即使是业务低峰期,依旧有交易在不断产生,所以对于线上DB停写从业务角度是不能接受的,同时如何实现新旧数据源的灵活切换、切换前的充分验证及观测,以及切换后如果出现问题如何快速回滚,基于这些问题设计了一套双写双读流程。
切换前充分验证和可观测性: 在整个切换过程中的关键环节都增加监控数据埋点上报,从而实现整个操作过程的可观测,也保证了在每一个环境切换前的充分验证。
动态配置下发: 将切换过程中需要调整的参数全部写入动态配置中心(比如Nacos),并为每个动态下发参数设计灰度放量的过程,比如基于用户尾号放量、基于租户维度放量等,保证在切换过程中的影响范围做到可控。
具体操作流程如下:
a). 对业务代码进行改造上线,使得具备双写读旧数据源的能力,通过Grafana监控读写曲线及异常监控等指标。
b). 通过离线任务或者DBA提供的数据同步组件,将旧数据源的数据开始全量同步。
c). 待全量数据同步完成后,通过动态配置中心开始逐步放量,将双写读旧数据源切换到双写读新数据源,同时通过Grafana监控读写曲线及异常监控等指标.
d). 灰度一段时间后,若未发现异常时,在通过动态配置中心逐步灰度切换到单写读新数据源,最后下线旧数据源。在第3、4步骤切换过程中一旦发现问题立刻对动态配置进行回滚。
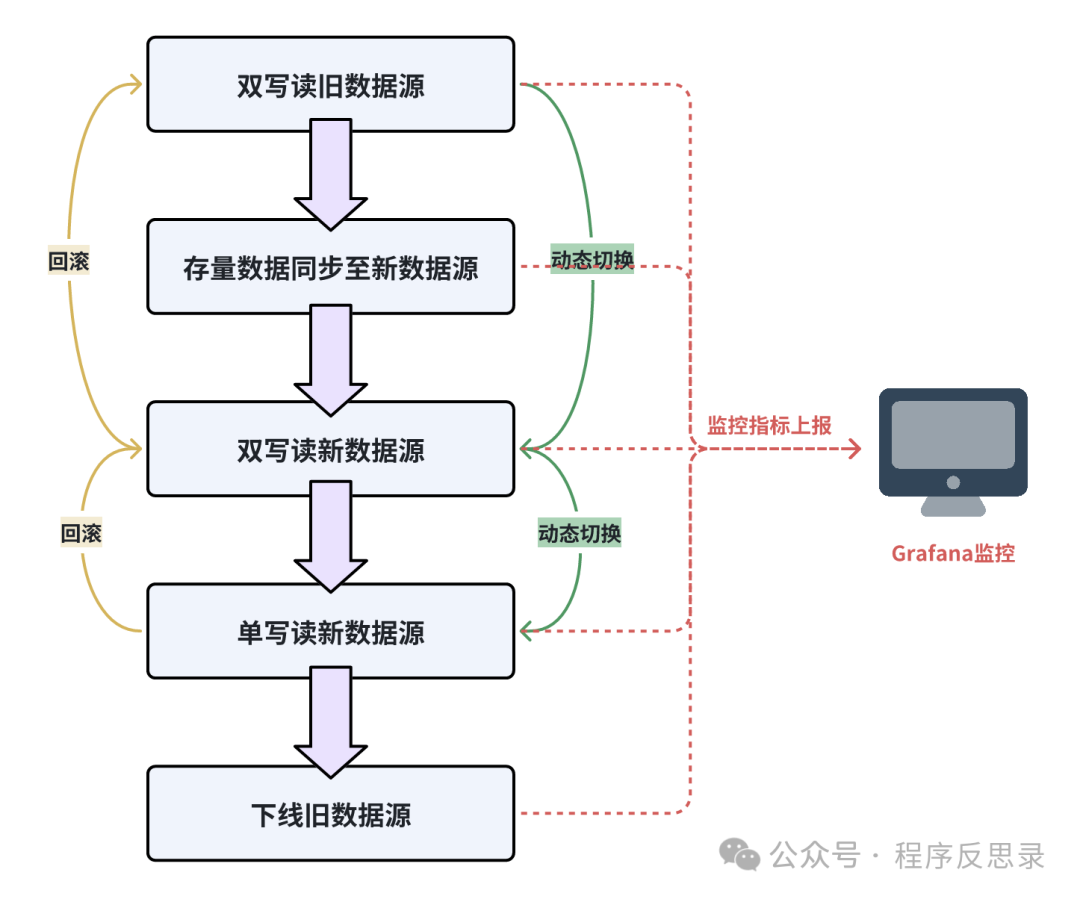
切流组件实现
平滑切流组件的执行流程图如下图所示:
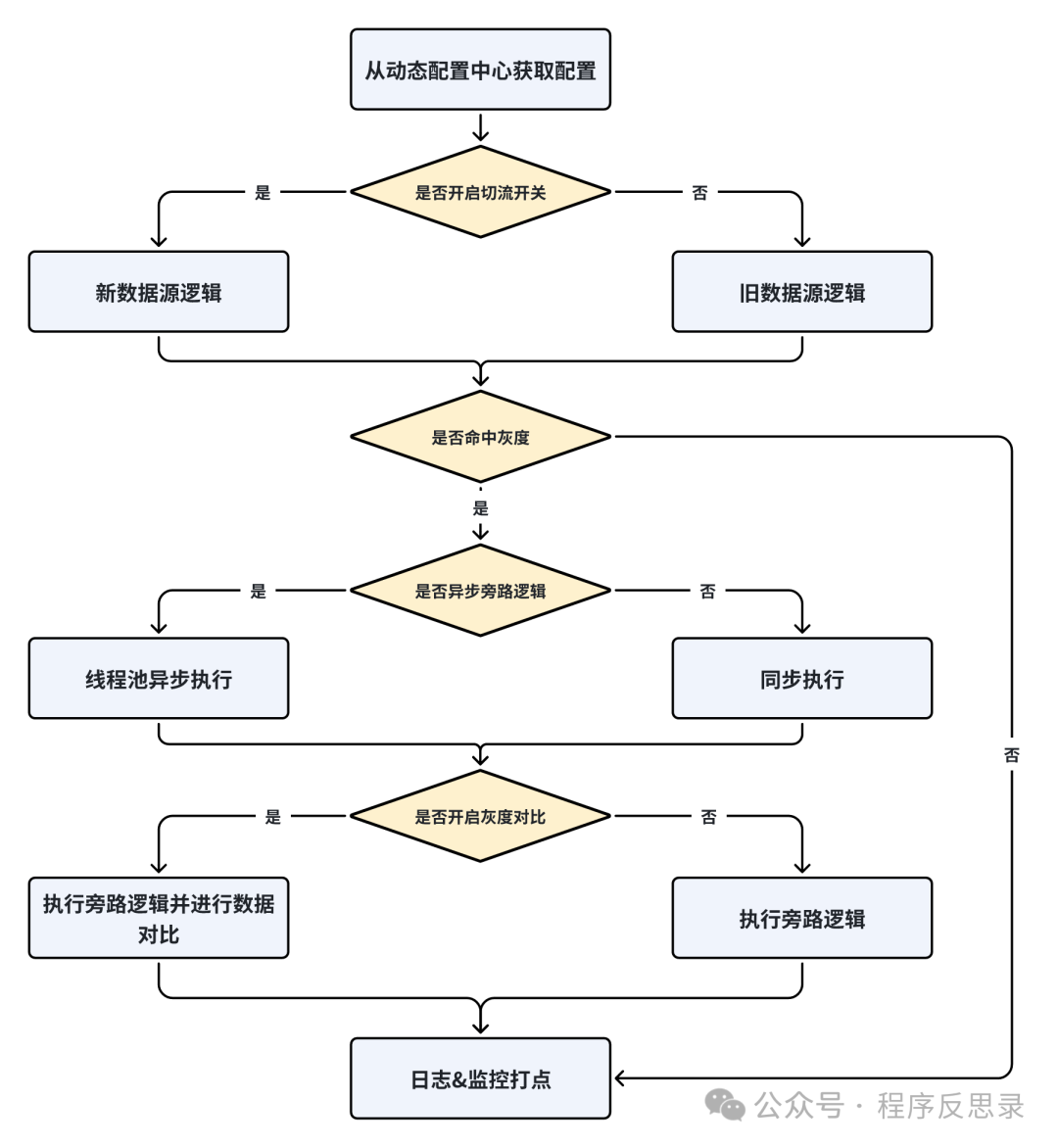
对应的核心执行代码如下:
public T call() {
try {
// 1. 灰度开关关闭,走老逻辑
if (Objects.isNull(shardConfig)) {
return oldCall.call();
}
Callable<T> mainCall = oldCall;
Callable<T> subCall = newCall;
// 2. 业务是否使用新数据源数据返回的结果
if (shardConfig.isUseNewResult()) {
mainCall = newCall;
subCall = oldCall;
}
// 未命中灰度,则直接返回主逻辑结果
if (!isGray()) {
return result;
}
// 是否开启异步数据对比旁路逻辑
if (shardConfig.isAsync()) {
Callable<T> finalSubCall = subCall;
Thread thread = new Thread(() -> {
process(finalSubCall, result);
});
EXECUTOR_SERVICE.submit(thread);
} else {
// 同步链路数据对比
process(subCall, result);
}
return result;
} catch (Exception e) {
throw new RuntimeException("call error");
}
}
/**
* 对新逻辑返回的结果和旧逻辑返回的数据进行对比
* @param subCall 子逻辑结果
* @param result 主逻辑结果
*/
private void process(Callable<T> subCall, T result){
// TODO 对新逻辑返回的结果和旧逻辑返回的数据进行对比
try {
T subReuslt = subCall.call();
boolean isSame = shardComparator.compare(result, subReuslt);
if (!isSame) {
// TODO 上报对比异常监控
PerfHelper.report("methodName", methodName);
}
} catch (Exception e) {
LOGGER.error("compare exception");
}
}
private boolean isGray() {
// TODO 业务灰度规则
return true;
}交易系统平滑迁移过程中的数据一致性如何保证?
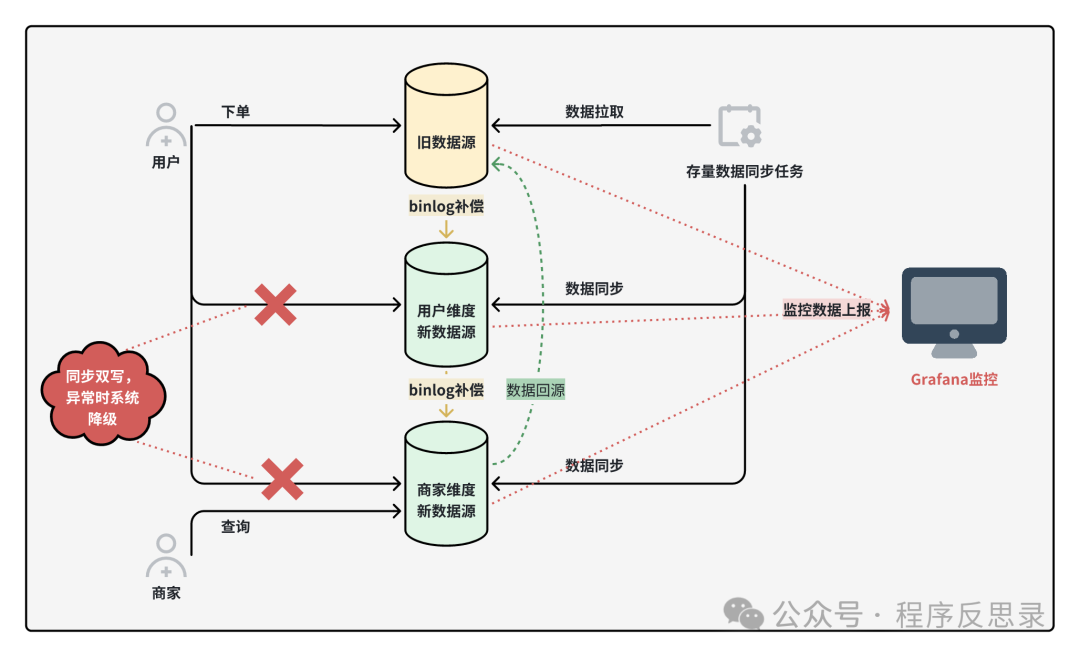
用户下单后需要冗余三个视角维度的数据,对于C端用户视角的数据一致性,采用双写+binlog补偿+定时任务兜底;对于B端商家视角的数据一致性,使用双写+binlog补偿+定时任务兜底+数据回源四种手段保证数据一致性。最后通过数据流对账+可视化监控来实时观测数据不一致的情况,并对异常数据进行手动修复。
遇到的一些坑
下单链路代码不合理
从单库单表切换到分库分表后,通过监控发现读新数据源数据对比错误量放大,原因是原来的下单链路存在:更新完DB后立马查询,由于主从数据同步还未完成导致无法查询到最新数据。
解决思路: 调整业务逻辑
数据对比采用线程池进行异步对比导致监控异常
起初使用线程池进行异步对比,是为了尽量不影响主链路耗时,但由于线程池使用姿势不太合理,导致实际发生比对时新旧数据源已经不一致,其根本原因是由于异步延迟执行导致。
解决思路: 1. 数据对比改为同步执行,主链路耗时无明显劣化,业务可接受;2. 动态调整线程池参数,使得异步任务执行更快处理(该方法尝试后,发现错误量有所下降,但未完全消除。
后续
本文介绍了一个线上交易系统从单库单表架构升级为多库多表过程中,如何实现不停服平滑迁移的方案,同时在整个迁移过程中实现了可观测、可回滚。
随着订单量持续增长,后续B端商家侧的数据逐渐出现了数据倾斜、大账单等问题,后续有机会再介绍这些问题的解决思路和治理方案。
做一个有深度的技术人
原文地址:https://blog.csdn.net/ShiLuoHeroKing/article/details/143497635
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!