【Java豆瓣电影爬虫】——抓取电影详情和电影短评数据 -
一直想做个这样的爬虫:定制自己的种子,爬取想要的数据,做点力所能及的小分析。正好,这段时间宝宝出生,一边陪宝宝和宝妈,一边把自己做的这个豆瓣电影爬虫的数据采集部分跑起来。现在做一个概要的介绍和演示。
动机
采集豆瓣电影数据包括电影详情页数据和电影的短评数据。
电影详情页如下图所示
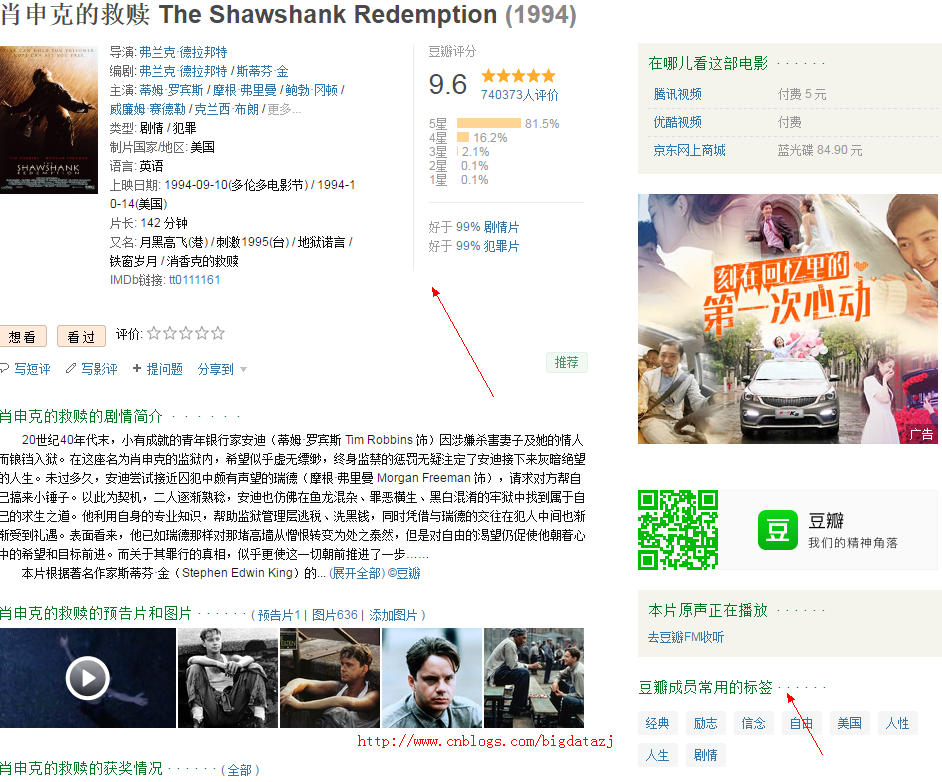
需要保存这些详情字段如导演、编剧、演员等还有图中右下方的标签。
短评页面如下图所示
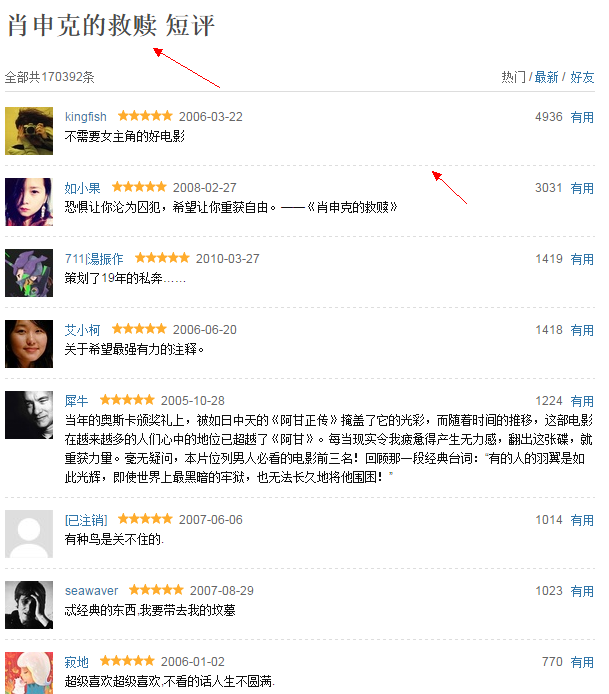
需要保存的字段有短评所属的电影名称,每条评论的详细信息如评论人名称、评论内容等。
数据库设计
有了如上的需求,需要设计表,其实很简单,只需要一张电影详情表movie和一张电影短评表comments,另外还需要一张存储网页提取的超链接的记录表record。
movie表
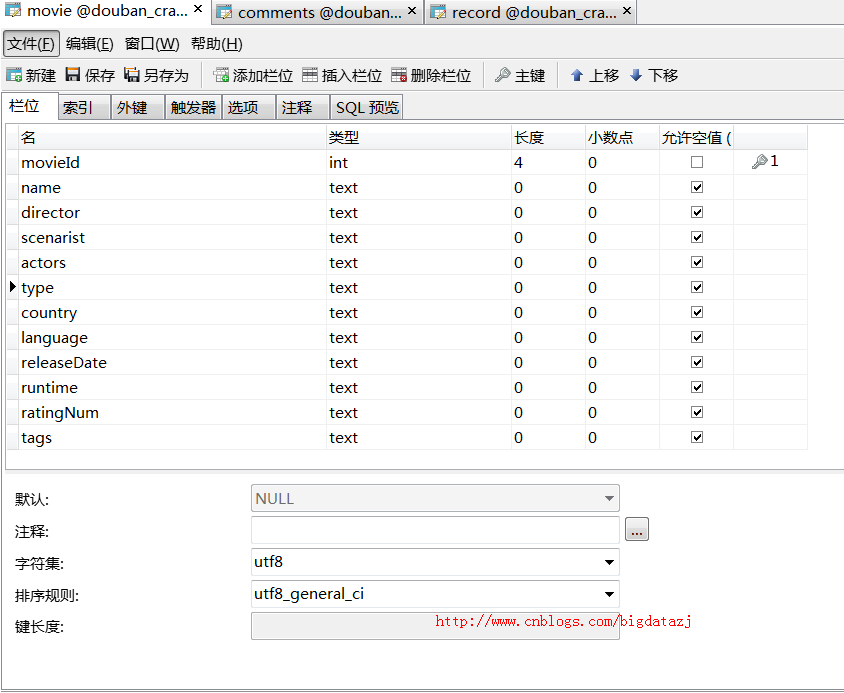
- movieId:主键,自增长
- Name:电影名
- Director:导演
- Scenarist:编剧
- Actors:主演
- Type:类型
- Country:制片国家/地区
- Language:语言
- releaseData: 上映日期
- Runtime: 片长
- ratingNum:豆瓣评分
- Tags:标签
comments表
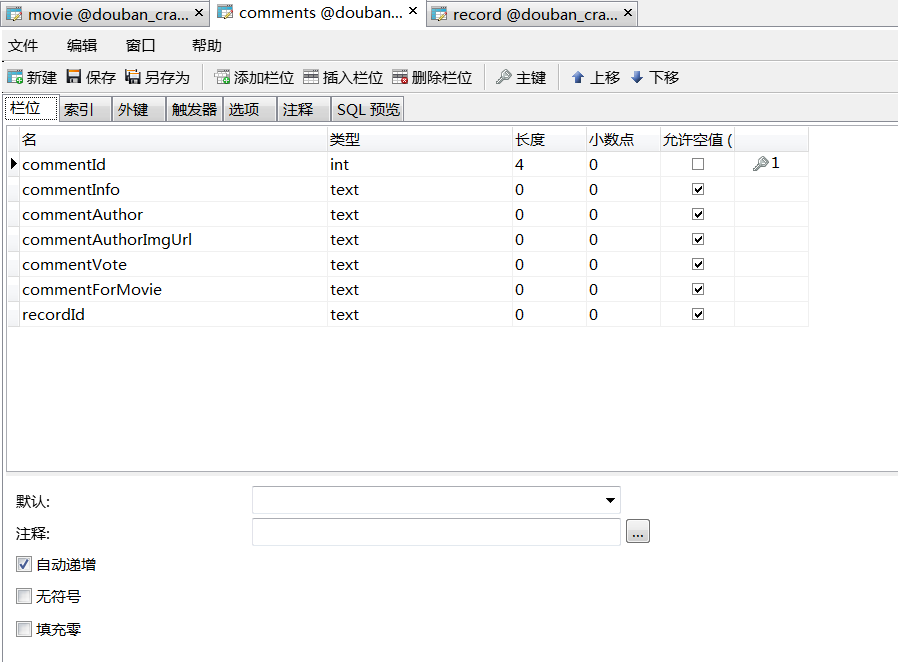
- commentId:主键,自增长
- commentInfo:评论内容
- commentAuthor:评论者
- commentAuthorImgUrl:评论者头像链接
- commentVote:评论点赞数
- commentForMovie:评论的电影名
- recordId:链接record表,暂时未用到
record表

- recordId:主键,自增长
- URL:爬取解析的超链接
- Crawled:是否被爬过
注意:数据库设计是在不断调整的,比如之前设计了一张tags表,用于存储每部电影的标签,经过调整发现直接放到movie中作为一个字段更加方便,又比如comments表中,commentForMovie是后来加上的,方便查找当前的评论针对哪部电影。
使用的技术
语言:Java(语言是一门工具,网上用python,java,nodejs比较多)
数据库:Mysql(轻便易用)
解析页面:Jsoup(比较熟悉httpparser,虽然功能强大,但是稍显繁琐,这里用Jsoup,因为其为类javascript语法)、正则表达式(对于一些结构比较奇怪的dom结构,采用了正则表达式的方式来提取信息,其实也可以用xpath,但是xpath极易受dom结构变化而失效)
比如对于网页源码如下
<!DOCTYPE html>
<html lang="zh-cmn-Hans" class="ua-windows ua-webkit">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<meta name="renderer" content="webkit">
<meta name="referrer" content="always">
<title>
肖申克的救赎 (豆瓣)
</title>
.....
<meta name="keywords" content="肖申克的救赎,The Shawshank Redemption,肖申克的救赎影评,剧情介绍,电影图片,预告片,影讯,在线购票,论坛,肖申克的救赎在线观看,肖申克的救赎高清,肖申克的救赎在线播放">
<meta name="description" content="肖申克的救赎电影简介和剧情介绍,肖申克的救赎影评、图片、预告片、影讯、论坛、在线购票、肖申克的救赎在线观看、高清、在线播放">
.........
<div id="info">
<span ><span class='pl'>导演</span>: <span class='attrs'><a href="/celebrity/1047973/" rel="v:directedBy">弗兰克·德拉邦特</a></span></span><br/>
<span ><span class='pl'>编剧</span>: <span class='attrs'><a href="/celebrity/1047973/">弗兰克·德拉邦特</a> / <a href="/celebrity/1049547/">斯蒂芬·金</a></span></span><br/>
<span class="actor"><span class='pl'>主演</span>: <span class='attrs'><a href="/celebrity/1054521/" rel="v:starring">蒂姆·罗宾斯</a> / <a href="/celebrity/1054534/" rel="v:starring">摩根·弗里曼</a> / <a href="/celebrity/1041179/" rel="v:starring">鲍勃·冈顿</a> / <a href="/celebrity/1000095/" rel="v:starring">威廉姆·赛德勒</a> / <a href="/celebrity/1013817/" rel="v:starring">克兰西·布朗</a> / <a href="/celebrity/1010612/" rel="v:starring">吉尔·贝罗斯</a> / <a href="/celebrity/1054892/" rel="v:starring">马克·罗斯顿</a> / <a href="/celebrity/1027897/" rel="v:starring">詹姆斯·惠特摩</a> / <a href="/celebrity/1087302/" rel="v:starring">杰弗里·德曼</a> / <a href="/celebrity/1074035/" rel="v:starring">拉里·布兰登伯格</a> / <a href="/celebrity/1099030/" rel="v:starring">尼尔·吉恩托利</a> / <a href="/celebrity/1343305/" rel="v:starring">布赖恩·利比</a> / <a href="/celebrity/1048222/" rel="v:starring">大卫·普罗瓦尔</a> / <a href="/celebrity/1343306/" rel="v:starring">约瑟夫·劳格诺</a> / <a href="/celebrity/1315528/" rel="v:starring">祖德·塞克利拉</a></span></span><br/>
<span class="pl">类型:</span> <span property="v:genre">剧情</span> / <span property="v:genre">犯罪</span><br/>
<span class="pl">制片国家/地区:</span> 美国<br/>
<span class="pl">语言:</span> 英语<br/>
<span class="pl">上映日期:</span> <span property="v:initialReleaseDate" content="1994-09-10(多伦多电影节)">1994-09-10(多伦多电影节)</span> / <span property="v:initialReleaseDate" content="1994-10-14(美国)">1994-10-14(美国)</span><br/>
<span class="pl">片长:</span> <span property="v:runtime" content="142">142 分钟</span><br/>
<span class="pl">又名:</span> 月黑高飞(港) / 刺激1995(台) / 地狱诺言 / 铁窗岁月 / 消香克的救赎<br/>
<span class="pl">IMDb链接:</span> <a href="http://www.imdb.com/title/tt0111161" target="\_blank" rel="nofollow">tt0111161</a><br>
</div>
</div>
<div id="interest\_sectl">
<div class="rating\_wrap clearbox" rel="v:rating">
<div class="rating\_logo">豆瓣评分</div>
<div class="rating\_self clearfix" typeof="v:Rating">
<strong class="ll rating\_num" property="v:average">9.6</strong>
<span property="v:best" content="10.0"></span>
<div class="rating\_right ">
<div class="ll bigstar50"></div>
<div class="rating\_sum">
<a href="collections" class="rating\_people"><span property="v:votes">740373</span>人评价</a>
</div>
</div>
</div>
<span class="stars5 starstop" title="力荐">
5星
</span>
<div class="power" style="width:64px"></div>
<span class="rating\_per">81.5%</span>
<br />
<span class="stars4 starstop" title="推荐">
4星
</span>
<div class="power" style="width:12px"></div>
<span class="rating\_per">16.2%</span>
<br />
<span class="stars3 starstop" title="还行">
3星
</span>
<div class="power" style="width:1px"></div>
<span class="rating\_per">2.1%</span>
<br />
<span class="stars2 starstop" title="较差">
2星
</span>
<div class="power" style="width:0px"></div>
<span class="rating\_per">0.1%</span>
<br />
<span class="stars1 starstop" title="很差">
1星
</span>
<div class="power" style="width:0px"></div>
<span class="rating\_per">0.1%</span>
<br />
</div>
<div class="rating\_betterthan">
好于 <a href="/typerank?type\_name=剧情&type=11&interval\_id=100:90&action=">99% 剧情片</a><br/>
好于 <a href="/typerank?type\_name=犯罪&type=3&interval\_id=100:90&action=">99% 犯罪片</a><br/>
</div>
</div>
</div>
.........
<!-- sindar19a-docker-->
<script>\_SPLITTEST=''</script>
</body>
</html>
可以通过如下代码来解析相应字段(其中有用Jsoup和正则表达式的)
for (Element info : infos) {
if (info.childNodeSize() > 0) {
String key = info.getElementsByAttributeValue("class", "pl").text();
if ("导演".equals(key)) {
movie.setDirector(info.getElementsByAttributeValue("class", "attrs").text());
} else if ("编剧".equals(key)) {
movie.setScenarist(info.getElementsByAttributeValue("class", "attrs").text());
} else if ("主演".equals(key)) {
movie.setActors(info.getElementsByAttributeValue("class", "attrs").text());
} else if ("类型:".equals(key)) {
movie.setType(doc.getElementsByAttributeValue("property", "v:genre").text());
} else if ("制片国家/地区:".equals(key)) {
Pattern patternCountry = Pattern.compile(".制片国家/地区:</span>.+\[\\\\u4e00-\\\\u9fa5\]+.+\[\\\\u4e00-\\\\u9fa5\]+\\\\s+<br>");
Matcher matcherCountry = patternCountry.matcher(doc.html());
if (matcherCountry.find()) {
movie.setCountry(matcherCountry.group().split("</span>")\[1\].split("<br>")\[0\].trim());// for example: >制片国家/地区:</span> 中国大陆 / 香港 <br>
}
} else if ("语言:".equals(key)) {
Pattern patternLanguage = Pattern.compile(".语言:</span>.+\[\\\\u4e00-\\\\u9fa5\]+.+\[\\\\u4e00-\\\\u9fa5\]+\\\\s+<br>");
Matcher matcherLanguage = patternLanguage.matcher(doc.html());
if (matcherLanguage.find()) {
movie.setLanguage(matcherLanguage.group().split("</span>")\[1\].split("<br>")\[0\].trim());
}
} else if ("上映日期:".equals(key)) {
movie.setReleaseDate(doc.getElementsByAttributeValue("property", "v:initialReleaseDate").text());
} else if ("片长:".equals(key)) {
movie.setRuntime(doc.getElementsByAttributeValue("property", "v:runtime").text());
}
}
}
movie.setTags(doc.getElementsByClass("tags-body").text());
movie.setName(doc.getElementsByAttributeValue("property", "v:itemreviewed").text());
movie.setRatingNum(doc.getElementsByAttributeValue("property", "v:average").text());
对于服务端返回不同状态的http status,本程序对于如304,401,403,404等都采取了丢弃处理,不作解析。
效果展示

record表记录
movie表记录
comments表记录
以上只是一个爬取数据的后台实现雏形,还有很多细节的问题需要解决。后期可能会补上环境搭建以及遇到的问题和解决方法相关的文章。
Java豆瓣电影爬虫——使用Word2Vec分析电影短评数据
程序爬取控制在豆瓣可接受范围内,不会给豆瓣服务器带来很大的压力,写此程序也是个人把玩,绝无恶意,万望豆瓣君谅解_
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。


四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、100道Python练习题
检查学习结果。


最后,如果你也想自学Python,可以关注我。我会把踩过的坑分享给你,让你不要踩坑,提高学习速度,这套资料涵盖了诸多学习内容:开发工具,基础视频教程,项目实战源码,51本电子书籍,100道练习题等。相信可以帮助大家在最短的时间内,能达到事半功倍效果,用来复习也是非常不错的。

原文地址:https://blog.csdn.net/2401_85855266/article/details/143804837
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!