基于 YOLOv9 的自定义数据集目标检测
点击下方卡片,关注“小白玩转Python”公众号
在本指南中,我们将展示使用自定义数据集训练 YOLOv9 模型的过程。具体而言,我们将提供一个示例,重点介绍训练一个视觉模型来识别篮球场上的篮球运动员。但是,这个指南是多功能的,允许您将其应用于您选择的任何数据集。
什么是 YOLOv9?
随着计算机视觉技术不断发展,YOLOv9 出现作为最新的进展,由 Chien-Yao Wang、I-Hau Yeh 和 Hong-Yuan Mark Liao 开发。这三位研究人员在该领域有着丰富的历史,曾为前几个模型的开发做出贡献,如 YOLOv4、YOLOR 和 YOLOv7。YOLOv9 不仅延续了前辈们的传统,还引入了重大创新,树立了目标检测能力的新标准。
YOLOv9 是一种先进的目标检测模型,代表了计算机视觉技术的重大进步。它是 “You Only Look Once” (YOLO) 系列中的最新版本,以其在图像中检测对象的高速度和准确性而闻名。YOLOv9 的独特之处在于它融合了可编程梯度信息(PGI)和引入了广义高效层聚合网络(GELAN)这两项开创性创新,旨在提高模型性能和效率。
准确性和性能
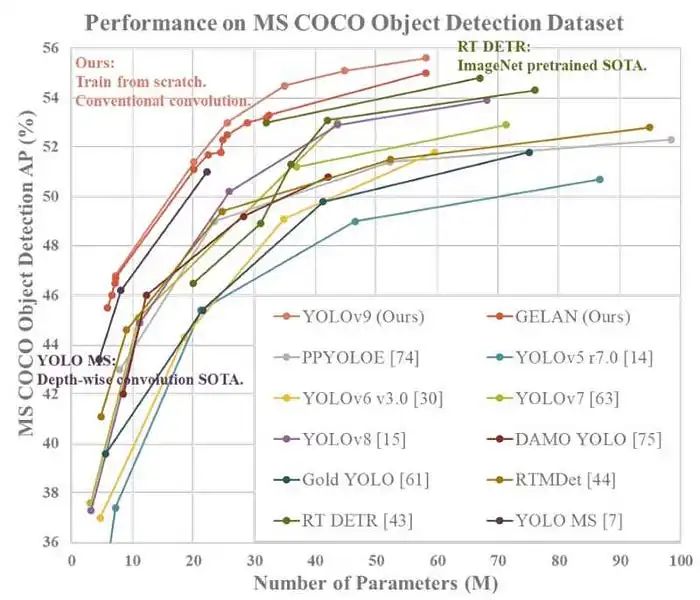
MSCOCO 数据集上实时目标检测器的比较
YOLOv9 模型有四个变体,根据参数计数进行分类:
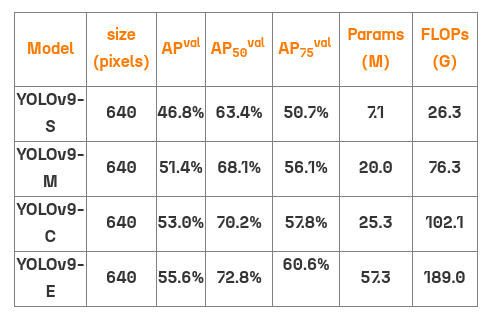
截至最新更新,YOLOv9-S 和 YOLOv9-M 模型的权重尚未公布。模型尺寸的差异满足了一系列应用需求,从边缘设备的轻量级模型到高性能计算环境中更全面的模型。
在性能方面,YOLOv9 在目标检测领域树立了新的标准。尽管尺寸最小的模型配置受限,但在 MS COCO 数据集的验证集上实现了令人印象深刻的 46.8% AP(平均精度)。同时,最大的模型变体 v9-E 具有惊人的 55.6% AP,确立了目标检测性能的新标杆。这一精度的飞跃展示了 YOLOv9 创新优化策略的有效性。
架构和创新
YOLOv9 架构通过融合可编程梯度信息(PGI)和一种称为广义高效层聚合网络(GELAN)的新网络架构,引入了目标检测领域的重大进步。以下是这些关键组件的解释:
可编程梯度信息(PGI)
PGI 是一个旨在解决深度神经网络中数据丢失挑战的新概念。在传统架构中,随着信息通过多个层,部分信息会丢失,导致学习和模型性能效率降低。PGI 允许在训练过程中更精确地控制梯度,确保关键信息得以保留并更有效地利用。这导致了更好的学习结果和模型精度。
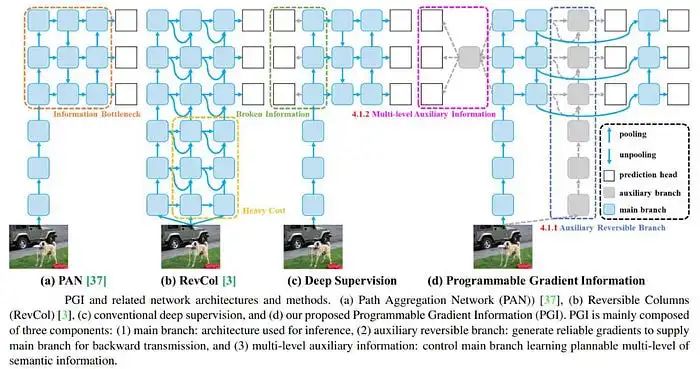
广义高效层聚合网络(GELAN)
GELAN 在 YOLOv9 架构中代表了一个重大创新。它旨在通过优化网络中不同层的信息聚合和处理方式来增强模型的性能和效率。GELAN 的关键重点是最大化参数利用率,确保模型可以在不增加计算资源或模型尺寸的情况下实现更高的准确性。
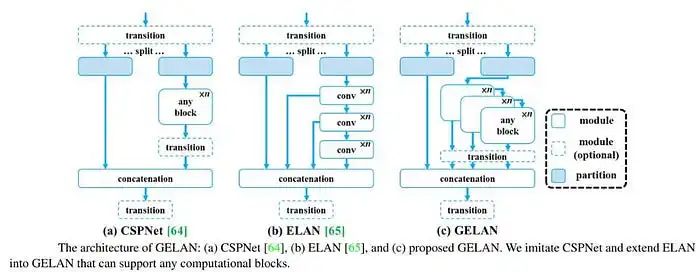
该架构使 YOLOv9 能够以更高的精度和效率处理目标检测任务,树立了计算机视觉深度学习模型性能的新标杆。在 YOLOv9 中结合 PGI 和 GELAN 代表了一种全面提升神经网络学习能力的方法,重点不仅在于模型的深度或宽度,还在于它在整个训练过程中如何有效地学习和保留信息。
这导致了一个不仅高度精确而且在计算资源方面高效的模型,使其适用于从边缘设备到基于云的系统的各种应用。
轻松在自定义数据集上训练
YOLOv9 Ikomia API 允许使用最少的编码训练和推断 YOLOv9 对象检测器。
设置
首先,重要的是要在虚拟环境中安装 API [3]。这种设置确保了平稳高效地开始使用 API 的功能。
pip install ikomia数据集
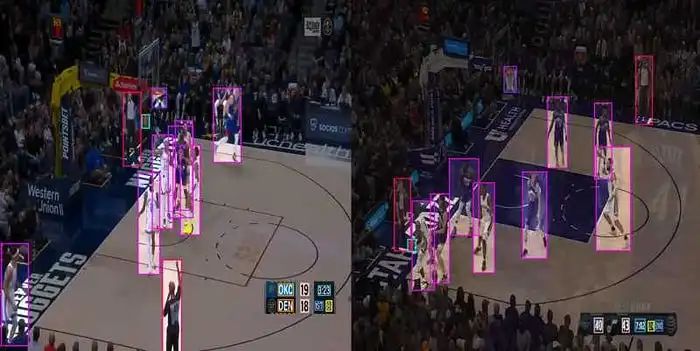
对于本教程,我们使用了 Roboflow 的篮球数据集 [4],其中包含 539 张图像,用于说明我们自定义 YOLOv9 对象检测模型的训练。数据集包含九个标签:
真实物体:球员、裁判、篮筐、球
电视屏幕信息:球队名称、球队得分、剩余时间、周期、投篮时钟
这些标签涵盖了篮球比赛中篮球场上的有形物体和通常在电视屏幕上显示的数字信息,为篮球比赛中的对象检测提供了全面的方法。
代码详情
from ikomia.dataprocess.workflow import Workflow
import os
#----------------------------- Step 1 -----------------------------------#
# Create a workflow which will take your dataset as input and
# train a YOLOv9 model on it
#------------------------------------------------------------------------#
wf = Workflow()
#----------------------------- Step 2 -----------------------------------#
# First you need to convert the COCO format to IKOMIA format.
# Add an Ikomia dataset converter to your workflow.
#------------------------------------------------------------------------#
dataset = wf.add_task(name="dataset_coco")
dataset.set_parameters({
"json_file":"Path/To/Dataset/train/_annotations.coco.json",
"image_folder":"Path/To/Dataset/train",
"task":"detection",
"output_folder":os.getcwd()+"/dataset"
})
#----------------------------- Step 3 -----------------------------------#
# Then, you want to train a YOLOv9 model.
# Add YOLOv9 training algorithm to your workflow
#------------------------------------------------------------------------#
train = wf.add_task(name="train_yolo_v9", auto_connect=True)
train.set_parameters({
"model_name":"yolov9-c",
"epochs":"50",
"batch_size":"8",
"train_imgsz":"640",
"test_imgsz":"640",
"dataset_split_ratio":"0.8",
"output_folder":os.getcwd(),
})
#----------------------------- Step 4 -----------------------------------#
# Execute your workflow.
# It automatically runs all your tasks sequentially.
#------------------------------------------------------------------------#
wf.run()以下是可配置参数:
model_name(str)-默认值 'yolov9-c':要训练的模型体系结构。应该是以下之一: yolov9-s(即将推出)/yolov9-m(即将推出)/yolov9-c/yolov9-e
train_imgsz(int)-默认值 '640':训练图像的大小。
test_imgsz(int)-默认值 '640':评估图像的大小。
epochs(int)-默认值 '50':对训练数据集的完整通过次数。
batch_size(int)-默认值 '8':在更新模型之前处理的样本数。
dataset_split_ratio(float)-默认值 '0.9':将数据集分割为训练和评估集的比率[0, 1]。
output_folder(str,可选):模型将保存的路径。
config_file(str,可选):超参数配置文件的路径.yaml。
dataset_folder(str,可选):重新格式化的数据集将保存的路径
model_weight_file(str,可选):预训练模型权重的路径。可以用来微调模型。
使用 NVIDIA L4 24GB GPU,50 个周期的训练过程大约需要 50 分钟完成。一旦您的模型完成了训练阶段,您可以通过分析 YOLOv9 训练过程生成的图表来评估其性能。这些可视化表示了各种关键指标,有助于理解您的对象检测模型的有效性。
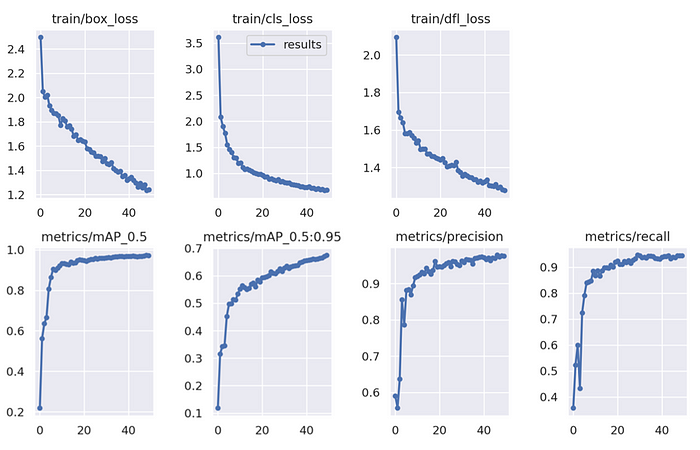

总之,这些图表表明随着训练的进行,模型学习和提高了检测和分类对象的能力。高精度以及不断增加的召回率和 mAP 值表明模型表现良好。但是,我们可以看到模型会受益于更长的训练时间。
微调 YOLOv9 模型
我们可以使用 “infer_yolo_v9” 算法测试我们的自定义模型。默认情况下,算法使用 COCO 预训练的 Yolov9-c 模型,但我们可以通过相应地指定 “model_weight_file” 和 “class_file” 参数来应用我们经过微调的模型。
from ikomia.dataprocess.workflow import Workflow
from ikomia.utils.displayIO import display
# Create your workflow for YOLO inference
wf = Workflow()
# Add the YOLOv9 algorithm to your workflow
yolov9 = wf.add_task(name="infer_yolo_v9", auto_connect=True)
yolov9.set_parameters({
"model_weight_file":"Path/To/[Timestramp]/weights/best.pt",
"class_file":"Path/To/[Timestramp]/classes.yaml",
"conf_thres":"0.3",
"iou_thres":"0.25"
})
# Run on your image
wf.run_on(url="https://pbs.twimg.com/ext_tw_video_thumb/1660454979298115585/pu/img/A_Jrl2uawkkDi_Kf.jpg")
# wf.run_on(path=os.getcwd()+"/test/youtube-128_jpg.rf.2723e31eec77e1ff7b73c45c625082f6.jpg")
# Get the object detection image output
img_bbox = yolov9.get_image_with_graphics()
# Display
display(img_bbox)
我们的模型成功识别了球员、裁判和篮筐、球队得分、周期和剩余时间。
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除
原文地址:https://blog.csdn.net/weixin_38739735/article/details/137701625
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!