分布式ID项目实战
一、订单场景
1、扫码付款
二维码本质是一个字符串,聚合码的本质是一个链接地址。
实现原理:当客户用APP扫码后,网站就会判断客户的扫码环境(微信、支付宝、云闪付等)
判断扫码环境原理:根据打开链接浏览器的HTTP header。任何浏览器打开http链接时,请求的header都有User-Agent(UA、用户代理)信息。
UA是一个特殊字符串头,服务器依次识别出客户使用的操作系统及版本、CPU类型、浏览器及版本、浏览器语言等。

动态生成的二维码预先绑定用户所选的商品信息和价格,根据用户所选的商品动态更新,这样处理支持一码多平台调支付,用户扫码后,服务端通过前端获取用户UID,结合二维码绑定商品信息,生成订单,发送支付信息到第三方(微信、支付宝),第三方生成支付订单推送给用户设备支付。
2、订单号
订单号在实际的业务中作为一个订单的唯一标识码存在。实现场景:
- 对订单进行操作,如线下收款,订单核销。
- 下单、改单、成单、退单、售后等系统内部的订单流程处理和跟进。
订单号的设计上需体现几个特性:
-
不允许修改任意一个字符就能查询到另一个订单信息。
-
不能有明显的整体规律
-
编号不能透露公司的运营情况,比如流水号等信息,以及客户的个人及商业信息
-
常见的电商平台订单号大多数是纯数字(int 比 varchase类型查询效率高)
-
订单号不宜过长,允许携带一些公开的信息(时间、星期、类型等等)
3、优惠券和兑换券
有些场景适合ID即使生成,比如电商平台购物领取的优惠券,只需在用户领取时分配优惠券信息即可。超市卡、京东卡等预先生成卡劵具备以下特性:
-
优惠券体量大,以万为单位,通常10w级别以上
-
不可破解、仿制券码等
-
用后核销
-
兑换券属于广撒网的策略,利用率低,也就不适合数据库进行存储(占空间,有效数据少)
设计一种有效的兑换码生成策略,支持预先生成,支持校验,内容简洁,生成的兑换码都具有唯一性。
既然是一种编解码规则,那么需要约定编码空间(也就是用户看到的组成兑换码的字符),编码空间由字符 a-z,A-Z,数字 0-9 组成,为了增强兑换码的可识别度,剔除大写字母 O 以及 I,可用字符如下所示,共 60 个字符:
abcdefghijklmnopqrstuvwxyzABCDEFGHJKLMNPQRSTUVWXZY0123456789兑换码要求近可能简洁,那么设计时就需要考虑兑换码的字符数,假设上限为 12 位,而字符空间有 60 位,那么可以表示的空间范围为 60^12=130606940160000000000000(也就是可以 12 位的兑换码可以生成天量)
兑换码组成分析
兑换码可以预先生成,并且不需要额外的存储空间保存这些信息,每一个优惠方案都有独立的一组兑换码(指运营同学组织的每一场运营活动都有不同的兑换码,不能混合使用, 例如双 11 兑换码不能使用在双 12 活动上),每个兑换码有自己的编号,防止重复,为了保证兑换码的有效性,对兑换码的数据需要进行校验,当前兑换码的数据组成如下所示:
优惠方案 ID + 兑换码序列号 i + 校验码
编码方案
- 兑换码序列号 i,代表当前兑换码是当前活动中第 i 个兑换码,兑换码序列号的空间范围决定了优惠活动可以发行的兑换码数目,当前采用 30 位 bit 位表示,可表示范围:1073741824(10 亿个券码)。
- 优惠方案 ID, 代表当前优惠方案的 ID 号,优惠方案的空间范围决定了可以组织的优惠活动次数,当前采用 15 位表示,可以表示范围:32768(考虑到运营活动的频率,以及 ID 的初始值 10000,15 位足够,365 天每天有运营活动,可以使用 54 年)。
- 校验码,校验兑换码是否有效,主要为了快捷的校验兑换码信息的是否正确,其次可以起到填充数据的目的,增强数据的散列性,使用 13 位表示校验位,其中分为两部分,前 6 位和后 7 位。
深耕业务还会有区分通用券和单独券的情况,分别具备以下特点,技术实现需要因地制宜地思考。
- 通用券:多个玩家都可以输入兑换,然后有总量限制,时间限制。
- 单独券:运营同学可以在后台设置兑换码的奖励物品、期限、个数,然后由后台生成兑换码的列表,兑换之后核销。
二、Tracing
1、日志追踪
在分布式服务架构下,一个 Web 请求从网关流入,有可能会调用多个服务对请求进行处理,拿到最终结果。这个过程中每个服务之间的通信又是单独的网络请求,无论请求经过的哪个服务出了故障或者处理过慢都会对前端造成影响。
处理一个 Web 请求要调用的多个服务,为了能更方便的查询哪个环节的服务出现了问题,为整个系统引入分布式链路跟踪。
在分布式链路跟踪中有两个重要的概念:跟踪(trace)和 跨度( span)。trace 是请求在分布式系统中的整个链路视图,span 则代表整个链路中不同服务内部的视图,span 组合在一起就是整个 trace 的视图。
在整个请求的调用链中,请求会一直携带 traceid 往下游服务传递,每个服务内部也会生成自己的 spanid 用于生成自己的内部调用视图,并和 traceid 一起传递给下游服务。
2、TraceId生成规则
如果每个 trace 中的 ID 都需要请求公共的 ID 服务生成,纯纯的浪费网络带宽资源。且会阻塞用户请求向下游传递,响应耗时上升,增加了没必要的风险。所以需要服务器实例最好可以自行计算 tracid,spanid。
产生规则:服务器 IP + ID 产生的时间 + 自增序列 + 当前进程号 ,比如:
0ad1348f1403169275002100356696
前 8 位 0ad1348f 即产生 TraceId 的机器的 IP,这是一个十六进制的数字,每两位代表 IP 中的一段,我们把这个数字,按每两位转成 10 进制即可得到常见的 IP 地址表示方式 10.209.52.143。
后面的 13 位 1403169275002 是产生 TraceId 的时间。之后的 4 位 1003 是一个自增的序列,从 1000 涨到 9000,到达 9000 后回到 1000 再开始往上涨。最后的 5 位 56696 是当前的进程 ID,为了防止单机多进程出现 TraceId 冲突的情况,所以在 TraceId 末尾添加了当前的进程 ID。
3、SpanId生成规则
span 是层的意思,比如在第一个实例算是第一层, 请求代理或者分流到下一个实例处理,就是第二层,以此类推。通过层,SpanId 代表本次调用在整个调用链路树中的位置。
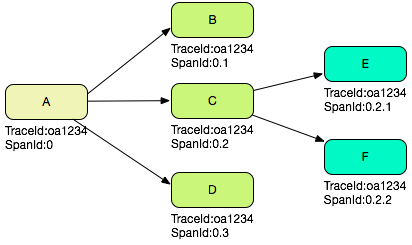
假设一个 服务器实例 A 接收了一次用户请求,代表是整个调用的根节点,那么 A 层处理这次请求产生的非服务调用日志记录 spanid 的值都是 0,A 层需要通过 RPC 依次调用 B、C、D 三个服务器实例,那么在 A 的日志中,SpanId 分别是 0.1,0.2 和 0.3,在 B、C、D 中,SpanId 也分别是 0.1,0.2 和 0.3;如果 C 系统在处理请求的时候又调用了 E,F 两个服务器实例,那么 C 系统中对应的 spanid 是 0.2.1 和 0.2.2,E、F 两个系统对应的日志也是 0.2.1 和 0.2.2。
根据上面的描述可以知道,如果把一次调用中所有的 SpanId 收集起来,可以组成一棵完整的链路树。
spanid 的生成本质:在跨层传递透传的同时,控制大小版本号的自增来实现的。
三、短网址
主要功能:网址缩短与还原。相较于长网址,短网址在电子邮箱、社交网络、手机上传播更方便,避免折行或超出字符限制。
常用的 ID 生成服务比如:MySQL ID 自增、 Redis 键自增、号段模式,生成的 ID 都是一串数字。短网址服务把客户的长网址转换成短网址,
实际是在 dwz.cn 域名后面拼接新产生的数字类型 ID,直接用数字 ID,网址长度也有些长,服务可以通过数字 ID 转更高进制的方式压缩长度。这种算法在短网址的技术实现上越来越多了起来,它可以进一步压缩网址长度。转进制的压缩算法在生活中有广泛的应用场景。
原文地址:https://blog.csdn.net/m0_74119287/article/details/143751919
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!