Redis遇到Hash冲突怎么办?
这是小伙伴之前遇到的一个面试题,感觉也是一个经典八股,和大伙分享下。
一 什么是 Hash 冲突
Hash 冲突,也称为 Hash 碰撞,是指不同的关键字通过 Hash 函数计算得到了相同的 Hash 地址。
Hash 冲突在 Hash 表中是不可避免的,因为 Hash 表的地址空间有限,而可能的关键字数量是无限的。
为了解决 Hash 冲突,有几种常见的方法:
-
链地址法(Chaining):这是最常用的方法之一,每个 Hash 表的桶(bucket)都维护一个链表,所有散列到同一个位置的元素都存储在这个链表中。当发生冲突时,新元素被添加到该链表的末尾。这种方法的优点是操作简单,插入、查找和删除的时间复杂度为 O(1),但当链表长度较长时,查找效率会降低,并且需要额外的内存空间来存储链表结构。
-
开放寻址法(Open Addressing):这种方法也称为闭散列,当发生 Hash 冲突时,会顺序地查找下一个可用的数组位置,直到找到一个空闲位置为止。开放寻址法有几种变体,包括线性探测、二次探测和伪随机探测。线性探测法是最简单的形式,它按顺序检查下一个空闲位置。二次探测法在发生冲突时,在表的左右进行跳跃式探测。伪随机探测法则使用伪随机数序列来确定下一个探查位置。
-
再 Hash 法(Rehashing):这种方法同时构造多个不同的 Hash 函数,当发生冲突时,使用第二个 Hash 函数计算地址,直到找到一个不发生冲突的位置。这种方法不易产生聚集,但增加了计算时间。
-
建立公共溢出区:将 Hash 表分为基本表和溢出表,将发生冲突的元素都存放在溢出表中。这种方法可以减少冲突,但需要额外的存储空间。
不同的编程语言在面临这个问题时也都采取了不同策略,例如:
- Python 采用开放寻址。字典 dict 使用伪随机数进行探测。
- Java 采用链式地址。自 JDK1.8 以来,当 HashMap 内数组长度达到 64 且链表长度达到 8 时,链表会转换为红黑树以提升查找性能。
- Go 采用链式地址。Go 规定每个桶最多存储 8 个键值对,超出容量则连接一个溢出桶;当溢出桶过多时,会执行一次特殊的等量扩容操作,以确保性能。
小伙伴们需要先熟悉这些解决方案,因为 Redis 中的解决方案无外乎就是这四种方案中的某几种。
二 Redis 中的 Hash
Redis 中的 Hash 数据结构在底层使用了两种不同的数据结构来存储键值对:
-
压缩列表(ziplist):当 Hash 表中的元素数量较少,并且每个元素的值都小于特定阈值(例如,值的长度小于 64 字节)时,Redis 会使用压缩列表来存储 Hash 表。压缩列表是一种内存高效的数据结构,它将所有的元素存储在一块连续的内存空间中,这样可以减少内存碎片和内存分配次数。但是,当元素数量增加或者单个元素的大小超过阈值时,压缩列表的性能会下降,因为它需要频繁地进行内存重新分配和数据复制。
-
Hash 表(hash table):当 Hash 表中的元素数量较多,或者元素的大小超过压缩列表的阈值时,Redis 会使用一个普通的 Hash 表来存储数据。这个 Hash 表由数组和链表组成,每个数组的索引位置上可以存储多个元素,这些元素通过链表连接起来。当 Hash 表中的元素数量增加到一定程度时,Redis 会进行 rehash 操作,即创建一个新的更大的 Hash 表,并将旧表中的所有元素重新映射到新表中。
Redis 会根据 Hash 表的大小和元素的数量自动在这两种数据结构之间进行切换,以保证性能和内存效率。这种动态的数据结构选择机制使得 Redis 的 Hash 数据结构既灵活又高效。
从上面的介绍中小伙伴们其实能看到,Redis 在处理 Hash 冲突的时候,用到了两种不同的方案:
- 链地址法
- rehash
三 Redis 如何解决 Hash 冲突
根据前面的介绍,小伙伴们已经明白了 Redis 在处理 Hash 冲突的时候,用到了两种不同的方案:链地址法和 rehash。
第一种链地址法大家应该是比较熟悉的,我们 Java 里边早期的 HashMap 就是这样的,具体数据结构如下图:
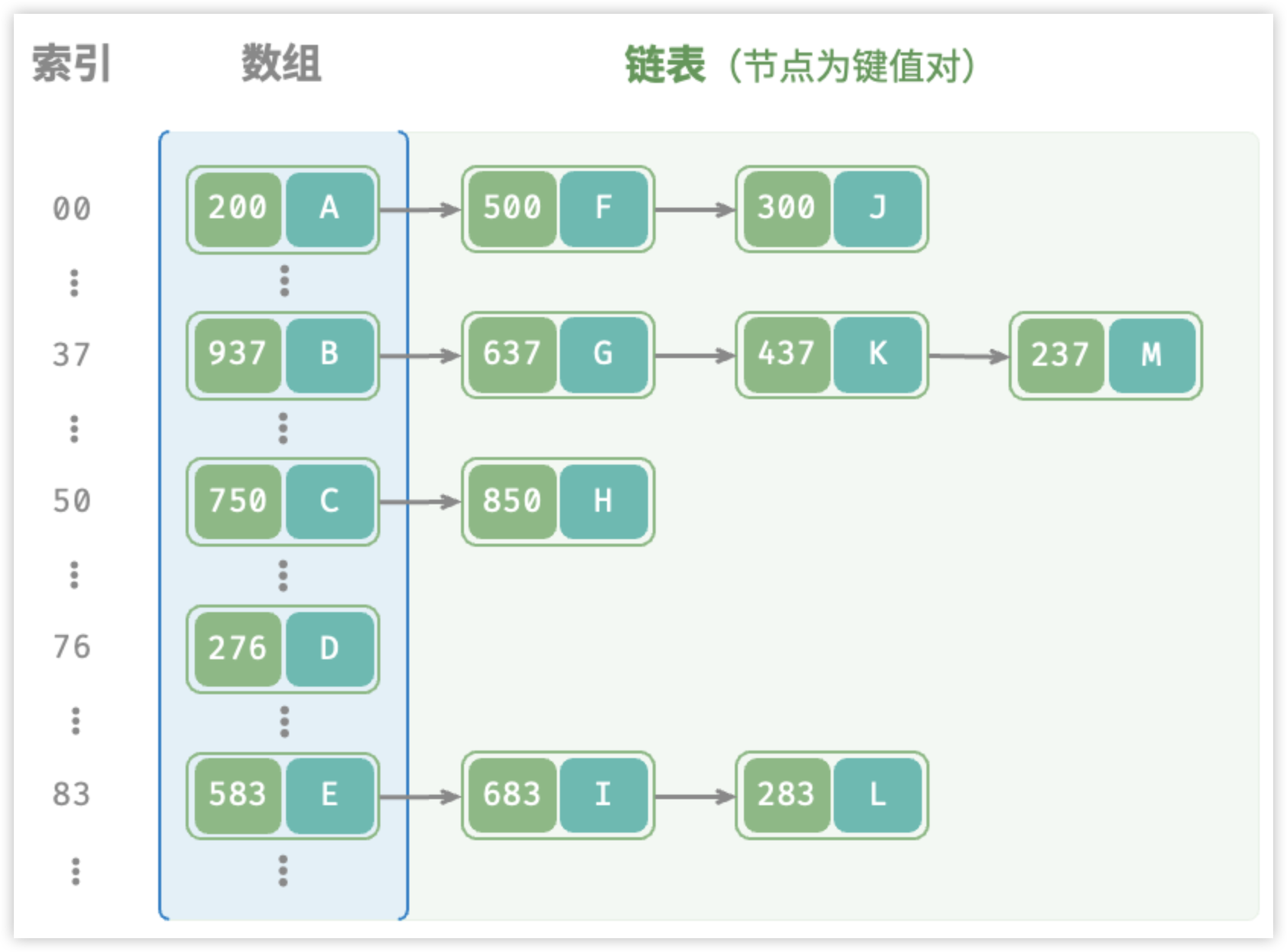
不过链地址法有一个弊端,就是如果出现大量的 key 冲突导致链表过长,此种情况下会导致数据的检索效率变慢,这不符合 Redis 高性能的人设,那怎么办呢?
为了保持高效,Redis 会对 Hash 表做 rehash 操作,也就通过增加 Hash 桶来减少冲突。为了 rehash 更高效,Redis 还默认使用了两个全局 Hash 表,一个用于当前使用,称为主 Hash 表,一个用于扩容,称为备用 Hash 表。
具体来说,在 Hash 表扩容时,Redis 首先会创建一个新的 Hash 表,该 Hash 表的大小是原有 Hash 表的两倍,然后将原有 Hash 表中的键值对逐一迁移到新的 Hash 表中。
在迁移过程中,Redis 会为每个被迁移的键值对计算出其在新 Hash 表中的位置,并将其插入到相应的位置上。在迁移完成后,Redis 会将新 Hash 表作为当前 Hash 表,用于存储新的键值对,同时释放旧 Hash 表的内存。
由于迁移过程是逐步进行的,因此在迁移过程中,既可以对新 Hash 表进行写入操作,也可以对旧 Hash 表进行读取操作,从而保证了 Redis 服务的正常运行。
四 小结
Redis 通过链地址法解决 Hash 冲突,并通过渐进式 rehash 保持 Hash 表的性能。
链地址法实现简单且在负载因子较低时性能较好,但在负载因子较高时性能会下降。渐进式 rehash 通过分批次迁移数据,避免了 rehash 过程中的服务阻塞,从而保持了系统的高性能和高可用性。
通过以上机制,Redis 在处理 Hash 冲突时能够有效地平衡性能和复杂度,确保在各种使用场景下都能提供高效的数据存储和检索服务。
原文地址:https://blog.csdn.net/u012702547/article/details/143067861
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!