人体三维重建【文章调研汇总】Humans
三维重建【文章调研汇总】
- 【ECCV 2020 (oral)】NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
- 【ACM_2023】3D Gaussian Splatting for Real-Time Radiance Field Rendering
- 【arxiv 2024.02】ImplicitDeepfake: Plausible Face-Swapping through Implicit Deepfake Generation using NeRF and Gaussian Splatting
- 【CVPR 2024】GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians
- 【arxiv 2024.01】En3D: An Enhanced Generative Model for Sculpting 3D Humans from 2D Synthetic Data
- 【ICCV 2023】ReFit: Recurrent Fitting Network for 3D Human Recovery
- 【ICCV 2023】Humans in 4D: Reconstructing and Tracking Humans with Transformers
- 【CVPR 2018】End-to-end Recovery of Human Shape and Pose
- 【CVPR2020】VIBE: Video Inference for Human Body Pose and Shape Estimation
- 【ICCV 2019】Learning to Reconstruct 3D Human Pose and Shape via Model-fitting in the Loop
- 【2015】SMPL: A Skinned Multi-Person Linear Model
- 【ICCV 2021】ROMP:Monocular, One-stage, Regression of Multiple 3D People
- 【CVPR 2024】HumanRef: Single Image to 3D Human Generation via Reference-Guided Diffusion
- 【arxiv 2024.02】HumanSplat: Generalizable Single-Image Human Gaussian Splatting with Structure Priors
- 【CVPR 2024】GART: Gaussian Articulated Template Models
- xxx 【arxiv 2024.02】
- 【CVPR 2024】MeshPose: Unifying DensePose and 3D Body Mesh reconstruction
- 【arxiv 2024.06】MeshAnything: Artist-Created Mesh Generation with Autoregressive Transformers
- 【arxiv 2024.06】Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion Models
- 【arxiv 2024.06】A Survey on 3D Human Avatar Modeling -- From Reconstruction to Generation
- xxx 【arxiv 2024.02】
- xxx 【arxiv 2024.02】
- xxx 【arxiv 2024.02】
- xxx 【arxiv 2024.02】
- xxx 【arxiv 2024.02】
- xxx 【arxiv 2024.02】
- xxx 【arxiv 2024.02】
- xxx 【arxiv 2024.02】
- xxx 【arxiv 2024.02】
数据集
LSP, LSP-extended【lustered pose and nonlinear appearance models for human pose estimation】
MPII【2d human pose estimation: New benchmark and state of the art analysis】
MS COCO【Microsoft coco: Commonobjects in context.】
Human3.6M 【Human3.6M: Large scale datasets and predictive methods
for 3D human sensing in natural environments. 】
MPI-INF-3DHP 【Vnect: Real-time 3d human pose estimation with a single rgb camera】
指标
MPJPE(Mean Per-Joint Position Error)
MPJPE直接衡量了预测关节坐标与真实关节坐标之间的欧几里得距离的平均值。具体来说,对于每一个关节j,其误差定义为两者坐标的欧氏距离,然后对所有关节的误差求平均值。公式可表示为:
MPJPE = 1 J ∑ j = 1 J ∥ p j pred − p j gt ∥ 2 \text{MPJPE} = \frac{1}{J} \sum_{j=1}^{J} \| \mathbf{p}_j^{\text{pred}} - \mathbf{p}_j^{\text{gt}} \|_2 MPJPE=J1j=1∑J∥pjpred−pjgt∥2
其中, p j pred 和 p j gt \mathbf{p}_j^{\text{pred}} 和 \mathbf{p}_j^{\text{gt}} pjpred和pjgt 分别代表第j个关节的预测坐标和真实坐标, J J J 是关节的总数。MPJPE越低,表示预测的姿态越接近真实姿态。
PA-MPJPE(Procrustes Aligned Mean Per-Joint Position Error)
PA-MPJPE则是在计算误差之前,首先对预测的姿态进行了最佳比例的刚体变换(包括旋转、平移和缩放),这一过程通常通过Procrustes分析实现,目的是为了消除全局旋转和平移的影响,以及可能的比例差异,从而更加专注于评估姿态结构本身的准确性。经过对齐后,再计算MPJPE。这意味着PA-MPJPE衡量的是姿态结构的相似度,而非简单的位置偏差。
Procrustes分析是一种统计方法,它能找到两组数据间最优的一致性变换,包括旋转、平移和缩放,使它们之间的距离最小化。在人体姿态估计中,这通常意味着找到一种变换,使得对齐后的预测姿态尽可能地匹配真实姿态。
总的来说,MPJPE提供了关节位置直接的绝对误差,而PA-MPJPE给出了在考虑了全局变换影响下的姿态结构的相对评估,后者在比较不同姿态估计方法时更能反映其在姿态估计结构上的精确度。这两种度量方式都是评价算法性能的重要工具,但选择哪种取决于评估的具体需求,比如是否关心全局姿态的差异。
Percentage of Correct Keypoints (PCK)
关键点正确率(Percentage of Correct Keypoints,简称PCK)是人体姿态估计和物体检测领域常用的评估指标之一,尤其适用于评价关键点定位的准确性。该指标衡量的是预测的关键点中有多少落在了与真实标注位置之间的一个预设阈值距离之内。
- 定义:
PCK指标计算的是被正确检测出的关键点数量占总关键点数量的百分比,这里的“正确检测”指的是预测的关键点位置与真实位置之间的距离小于或等于一个给定的误差阈值(通常以关节或者像素为单位)。这个阈值通常是根据任务的具体要求和难度来设定的,例如,在某些研究中,该阈值可能是关节长度的一定比例(如10%),或者固定数量的像素。
PCK = Number of keypoints detected within threshold Total number of keypoints × 100 % \text{PCK} = \frac{\text{Number of keypoints detected within threshold}}{\text{Total number of keypoints}} \times 100\% PCK=Total number of keypointsNumber of keypoints detected within threshold×100%
- 特点:
- 鲁棒性:PCK相对于绝对误差度量(如MPJPE)更加关注关键点定位的定性结果,对小的全局偏移不敏感。
- 直观性:能够直观地反映出模型在关键点检测任务上的成功率。
- 灵活性:通过调整阈值,PCK可以适应不同精度要求的评估场景。
PCK及其变体(如PCKh,其中h代表根据关节长度进行归一化的阈值)广泛应用于评估人体姿态估计系统的性能,特别是在存在尺度变化、姿态多变和遮挡等问题的复杂场景中。
Per Vertex Error (PVE).
Per Vertex Error (PVE) 是一种用于评估3D重建、形状拟合或姿态估计等计算机视觉和图形学任务中模型精确度的指标。这个术语特指每顶点误差,意味着它是针对模型中每个顶点位置的预测误差进行度量。
在具体应用中,比如对人体姿态估计,如果有一个算法预测了一组3D人体关节的位置,而我们有一组对应的地面真实(ground-truth)关节位置,PVE可以通过计算每个预测关节位置与真实关节位置之间的距离(通常采用欧几里得距离)来量化误差。然后,所有顶点(或关键点)的这种距离误差可以取平均值,得到平均每顶点误差,或者进行其他统计分析(如中位数、误差分布等),以全面了解模型预测的准确性。
PVE的计算公式可以表示为:
PVE = 1 N ∑ i = 1 N ∣ ∣ v i predicted − v i ground_truth ∣ ∣ 2 \text{PVE} = \frac{1}{N} \sum_{i=1}^{N} ||\mathbf{v}_i^\text{predicted} - \mathbf{v}_i^\text{ground\_truth}||_2 PVE=N1∑i=1N∣∣vipredicted−viground_truth∣∣2
其中, N N N 是顶点(或关键点)的总数, v i predicted \mathbf{v}_i^\text{predicted} vipredicted 和 v i ground_truth \mathbf{v}_i^\text{ground\_truth} viground_truth 分别表示第 i i i个顶点的预测位置和真实位置, ∣ ∣ ⋅ ∣ ∣ 2 ||\cdot||_2 ∣∣⋅∣∣2 表示欧几里得范数,即两点之间的直线距离。
PVE的优点在于它直观地反映了模型在点云级别上的表现,能够帮助研究者或开发者了解算法在重建几何形状方面的精确程度。然而,它也可能受到数据中的异常值影响,因此在某些情况下,研究者可能会使用其他稳健统计量来辅助评估。此外,对于包含大量顶点的复杂模型,PVE可能需要与其他度量(如部分重叠度量、体积误差等)结合使用,以获得更全面的性能评估。
Acceleration error
【Learning 3D human dynamics from video.】
在3D人体姿态评估中,加速度误差(Acceleration Error)是一种评估方法,用于量化预测的3D人体关节运动序列与真实运动序列之间在加速度层面上的差异。特别是在针对3DPW(3D Pose and Shape Reconstruction from a Single Image)这类数据集的分析中,该指标尤为重要,因为它能够提供关于动作动态一致性方面的信息。
具体来说,加速度误差是通过计算预测的3D关节序列在每一时间点的加速度与相应地面真实(ground-truth)加速度之间的差值来得到的,这些差值进一步用来评估整体的预测准确性。计算通常涉及以下步骤:
-
获取关节轨迹:首先从预测的和真实的3D人体关节序列中提取各关节随时间变化的位置。
-
计算速度:对每个关节的位置序列进行一阶微分,得到各个关节的速度随时间的变化情况。
-
计算加速度:接着,对速度序列进行一阶微分,得到关节的加速度序列。这一步骤是核心,因为加速度反映了运动的变化率,能够捕捉动作的动态特性。
-
计算误差:对于每个时间点t,计算预测的加速度 a predicted , t \mathbf{a}_{\text{predicted},t} apredicted,t与真实加速度 a gt , t \mathbf{a}_{\text{gt},t} agt,t之间的差异(通常使用欧几里得距离),即误差 ∥ a predicted , t − a gt , t ∥ 2 \|\mathbf{a}_{\text{predicted},t} - \mathbf{a}_{\text{gt},t}\|_2 ∥apredicted,t−agt,t∥2。
-
汇总误差:最后,对所有时间点的误差求平均,得到平均加速度误差(通常单位为mm/s²),以此作为评估模型在捕捉动作动态变化能力上的指标。
加速度误差越小,说明模型预测的人体运动在动态特性上与真实运动更加吻合,这对于需要精确模拟人体动作流畅性、力量感和自然度的应用(如动画制作、体育分析、虚拟现实等)尤为重要。
【ECCV 2020 (oral)】NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Authors: Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng
Abstract We present a method that achieves state-of-the-art results for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views. Our algorithm represents a scene using a fully-connected (non-convolutional) deep network, whose input is a single continuous 5D coordinate (spatial location $(x,y,z)$ and viewing direction $(\theta, \phi)$) and whose output is the volume density and view-dependent emitted radiance at that spatial location. We synthesize views by querying 5D coordinates along camera rays and use classic volume rendering techniques to project the output colors and densities into an image. Because volume rendering is naturally differentiable, the only input required to optimize our representation is a set of images with known camera poses. We describe how to effectively optimize neural radiance fields to render photorealistic novel views of scenes with complicated geometry and appearance, and demonstrate results that outperform prior work on neural rendering and view synthesis. View synthesis results are best viewed as videos, so we urge readers to view our supplementary video for convincing comparisons.【Paper】 > 【Github_Code】 > 【Project】 > 【中文解读】
【ACM_2023】3D Gaussian Splatting for Real-Time Radiance Field Rendering
Authors: Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis
Abstract Radiance Field methods have recently revolutionized novel-view synthesis of scenes captured with multiple photos or videos. However, achieving high visual quality still requires neural networks that are costly to train and render, while recent faster methods inevitably trade off speed for quality. For unbounded and complete scenes (rather than isolated objects) and 1080p resolution rendering, no current method can achieve real-time display rates. We introduce three key elements that allow us to achieve state-of-the-art visual quality while maintaining competitive training times and importantly allow high-quality real-time (>= 30 fps) novel-view synthesis at 1080p resolution. First, starting from sparse points produced during camera calibration, we represent the scene with 3D Gaussians that preserve desirable properties of continuous volumetric radiance fields for scene optimization while avoiding unnecessary computation in empty space; Second, we perform interleaved optimization/density control of the 3D Gaussians, notably optimizing anisotropic covariance to achieve an accurate representation of the scene; Third, we develop a fast visibility-aware rendering algorithm that supports anisotropic splatting and both accelerates training and allows realtime rendering. We demonstrate state-of-the-art visual quality and real-time rendering on several established datasets.【Paper_arxiv】 > 【Github_Code】 > 【Project】 > 【中文解读】
引入了三个关键要素,能够在保持有竞争力的训练时间的同时实现最先进的视觉质量,并且重要的是允许以 1080p 分辨率进行高质量实时(≥ 30 fps)新颖的视图合成。首先,从相机校准期间产生的稀疏点开始,用 3D 高斯表示场景,保留连续体积辐射场的所需属性以进行场景优化,同时避免在空白空间中进行不必要的计算;其次,对 3D 高斯进行交错优化/密度控制,特别是优化各向异性协方差以实现场景的准确表示;第三,开发了一种快速可见性感知渲染算法,该算法支持各向异性泼溅,既加速训练又允许实时渲染。
【arxiv 2024.02】ImplicitDeepfake: Plausible Face-Swapping through Implicit Deepfake Generation using NeRF and Gaussian Splatting
Authors: Georgii Stanishevskii, Jakub Steczkiewicz, Tomasz Szczepanik, Sławomir Tadeja, Jacek Tabor, Przemysław Spurek
Abstract Numerous emerging deep-learning techniques have had a substantial impact on computer graphics. Among the most promising breakthroughs are the recent rise of Neural Radiance Fields (NeRFs) and Gaussian Splatting (GS). NeRFs encode the object's shape and color in neural network weights using a handful of images with known camera positions to generate novel views. In contrast, GS provides accelerated training and inference without a decrease in rendering quality by encoding the object's characteristics in a collection of Gaussian distributions. These two techniques have found many use cases in spatial computing and other domains. On the other hand, the emergence of deepfake methods has sparked considerable controversy. Such techniques can have a form of artificial intelligence-generated videos that closely mimic authentic footage. Using generative models, they can modify facial features, enabling the creation of altered identities or facial expressions that exhibit a remarkably realistic appearance to a real person. Despite these controversies, deepfake can offer a next-generation solution for avatar creation and gaming when of desirable quality. To that end, we show how to combine all these emerging technologies to obtain a more plausible outcome. Our ImplicitDeepfake1 uses the classical deepfake algorithm to modify all training images separately and then train NeRF and GS on modified faces. Such relatively simple strategies can produce plausible 3D deepfake-based avatars.【Paper】 > 【Github_Code】 > 【Project无】
本文介绍了一种新颖的方法 ImplicitDeepfake,该方法使用传统的 Deepfake 算法分别更改 NeRF 和 GS 的训练图像。随后,NeRF 和 GS 分别在修改后的面部图像上进行训练,生成可用作 3D avatars的逼真且可信的深度伪造品。如结果所示,GS 产生更清晰的渲染,而前者偶尔会产生模糊的渲染。我们将这些影响归因于 2D Deepfake 模型引入的微小不一致。总体而言,GS 表现出比 NeRF 更强的看待不一致的能力。
【CVPR 2024】GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians
Authors: Shenhan Qian, Tobias Kirschstein, Liam Schoneveld, Davide Davoli, Simon Giebenhain, Matthias Nießner
Abstract We introduce GaussianAvatars, a new method to create photorealistic head avatars that are fully controllable in terms of expression, pose, and viewpoint. The core idea is a dynamic 3D representation based on 3D Gaussian splats that are rigged to a parametric morphable face model. This combination facilitates photorealistic rendering while allowing for precise animation control via the underlying parametric model, e.g., through expression transfer from a driving sequence or by manually changing the morphable model parameters. We parameterize each splat by a local coordinate frame of a triangle and optimize for explicit displacement offset to obtain a more accurate geometric representation. During avatar reconstruction, we jointly optimize for the morphable model parameters and Gaussian splat parameters in an end-to-end fashion. We demonstrate the animation capabilities of our photorealistic avatar in several challenging scenarios. For instance, we show reenactments from a driving video, where our method outperforms existing works by a significant margin.【Paper】 > 【Github_Code】 > 【Project】
问题只有头部
【arxiv 2024.01】En3D: An Enhanced Generative Model for Sculpting 3D Humans from 2D Synthetic Data
Authors: Yifang Men1, Biwen Lei1, Yuan Yao1, Miaomiao Cui1, Zhouhui Lian2, Xuansong Xie1
Abstract We present En3D, an enhanced generative scheme for sculpting high-quality 3D human avatars. Unlike previous works that rely on scarce 3D datasets or limited 2D collections with imbalanced viewing angles and imprecise pose priors, our approach aims to develop a zero-shot 3D generative scheme capable of producing visually realistic, geometrically accurate and content-wise diverse 3D humans without relying on pre-existing 3D or 2D assets. To address this challenge, we introduce a meticulously crafted workflow that implements accurate physical modeling to learn the enhanced 3D generative model from synthetic 2D data. During inference, we integrate optimization modules to bridge the gap between realistic appearances and coarse 3D shapes. Specifically, En3D comprises three modules: a 3D generator that accurately models generalizable 3D humans with realistic appearance from synthesized balanced, diverse, and structured human images; a geometry sculptor that enhances shape quality using multi-view normal constraints for intricate human anatomy; and a texturing module that disentangles explicit texture maps with fidelity and editability, leveraging semantical UV partitioning and a differentiable rasterizer. Experimental results show that our approach significantly outperforms prior works in terms of image quality, geometry accuracy and content diversity. We also showcase the applicability of our generated avatars for animation and editing, as well as the scalability of our approach for content-style free adaptation.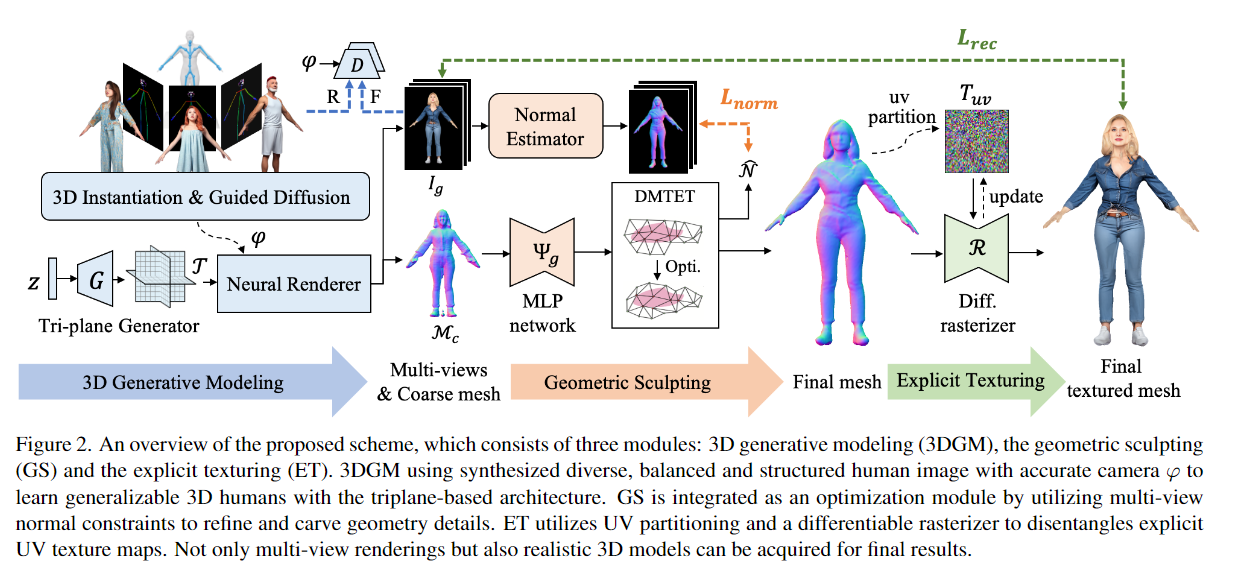
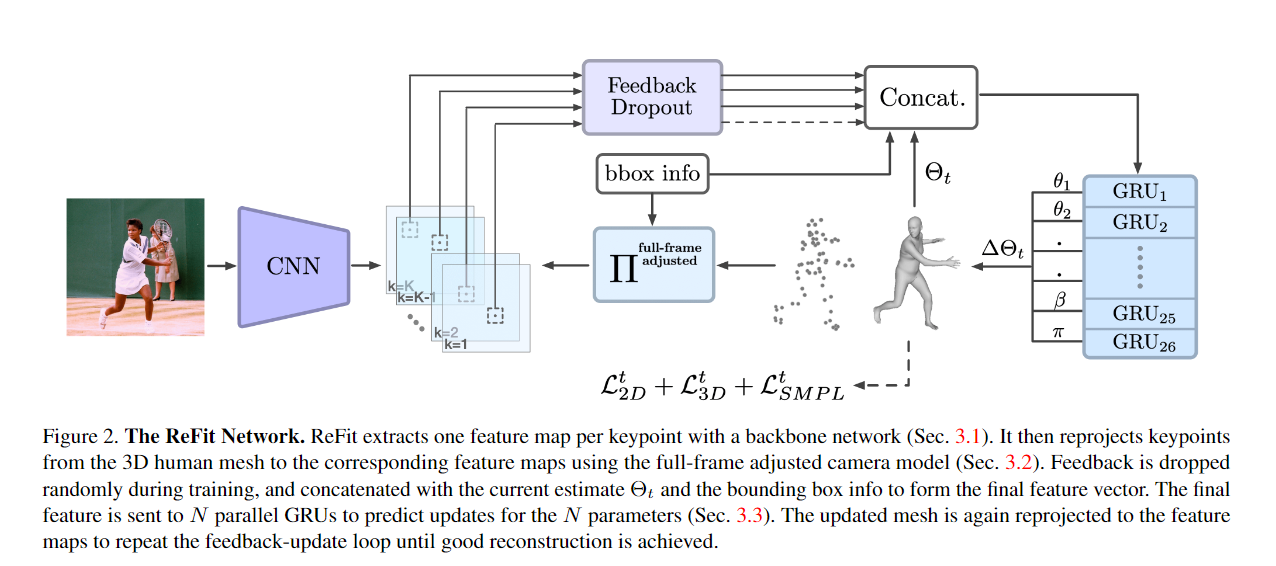
【ICCV 2023】ReFit: Recurrent Fitting Network for 3D Human Recovery
宾夕法尼亚大学
Authors: Yufu Wang, Kostas Daniilidis
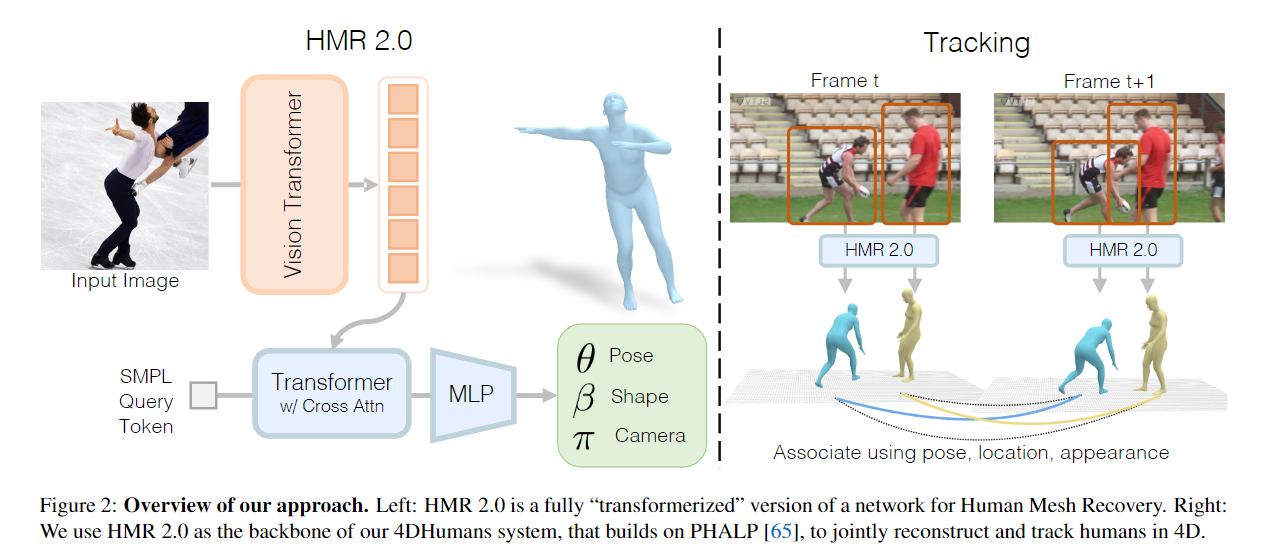
【ICCV 2023】Humans in 4D: Reconstructing and Tracking Humans with Transformers
加州大学伯克利分校
Authors: Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, Jitendra Malik
【Paper】 > 【Github_Code】 > 【Project】
Transformer SMPL HMR 2.0
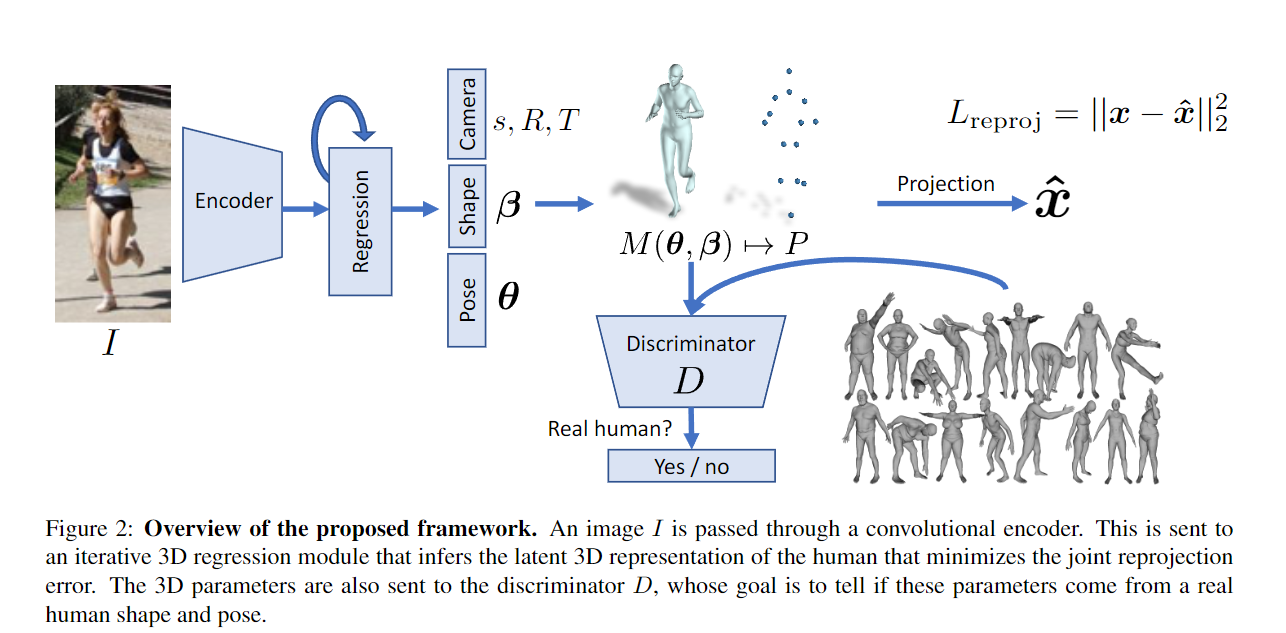
【CVPR 2018】End-to-end Recovery of Human Shape and Pose
Authors: Angjoo Kanazawa, Michael J. Black, David W. Jacobs, Jitendra Malik
Abstract We describe Human Mesh Recovery (HMR), an end-to-end framework for reconstructing a full 3D mesh of a human body from a single RGB image. In contrast to most current methods that compute 2D or 3D joint locations, we produce a richer and more useful mesh representation that is parameterized by shape and 3D joint angles. The main objective is to minimize the reprojection loss of keypoints, which allow our model to be trained using images in-the-wild that only have ground truth 2D annotations. However, the reprojection loss alone leaves the model highly under constrained. In this work we address this problem by introducing an adversary trained to tell whether a human body parameter is real or not using a large database of 3D human meshes. We show that HMR can be trained with and without using any paired 2D-to-3D supervision. We do not rely on intermediate 2D keypoint detections and infer 3D pose and shape parameters directly from image pixels. Our model runs in real-time given a bounding box containing the person. We demonstrate our approach on various images in-the-wild and out-perform previous optimization based methods that output 3D meshes and show competitive results on tasks such as 3D joint location estimation and part segmentation.【Paper】 > 【Github_Code】 > 【Project】
HMR
【CVPR2020】VIBE: Video Inference for Human Body Pose and Shape Estimation
Authors: Muhammed Kocabas, Nikos Athanasiou, Michael J. Black
Abstract Human motion is fundamental to understanding behavior. Despite progress on single-image 3D pose and shape estimation, existing video-based state-of-the-art methods fail to produce accurate and natural motion sequences due to a lack of ground-truth 3D motion data for training. To address this problem, we propose Video Inference for Body Pose and Shape Estimation (VIBE), which makes use of an existing large-scale motion capture dataset (AMASS) together with unpaired, in-the-wild, 2D keypoint annotations. Our key novelty is an adversarial learning framework that leverages AMASS to discriminate between real human motions and those produced by our temporal pose and shape regression networks. We define a temporal network architecture and show that adversarial training, at the sequence level, produces kinematically plausible motion sequences without in-the-wild ground-truth 3D labels. We perform extensive experimentation to analyze the importance of motion and demonstrate the effectiveness of VIBE on challenging 3D pose estimation datasets, achieving state-of-the-art performance.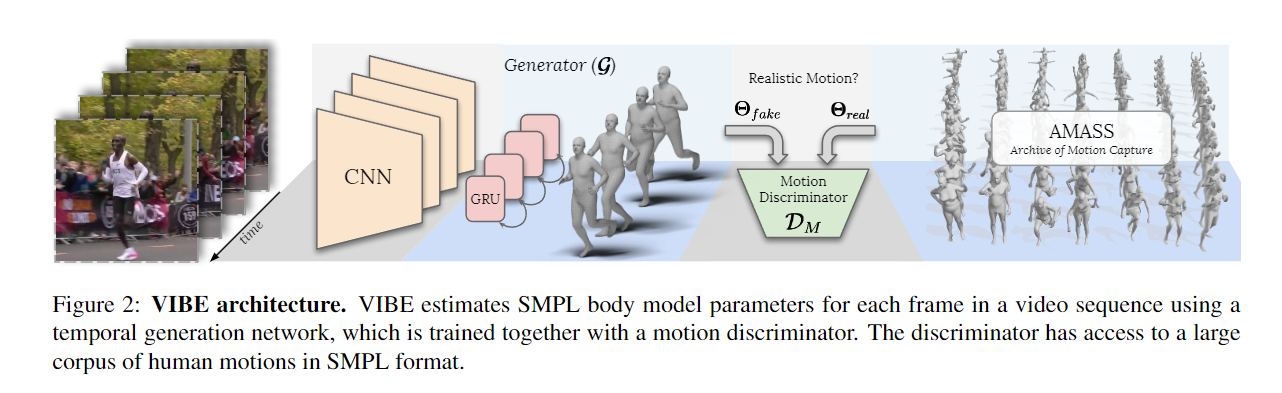
【ICCV 2019】Learning to Reconstruct 3D Human Pose and Shape via Model-fitting in the Loop
Authors: Nikos Kolotouros, Georgios Pavlakos, Michael J. Black, Kostas Daniilidis
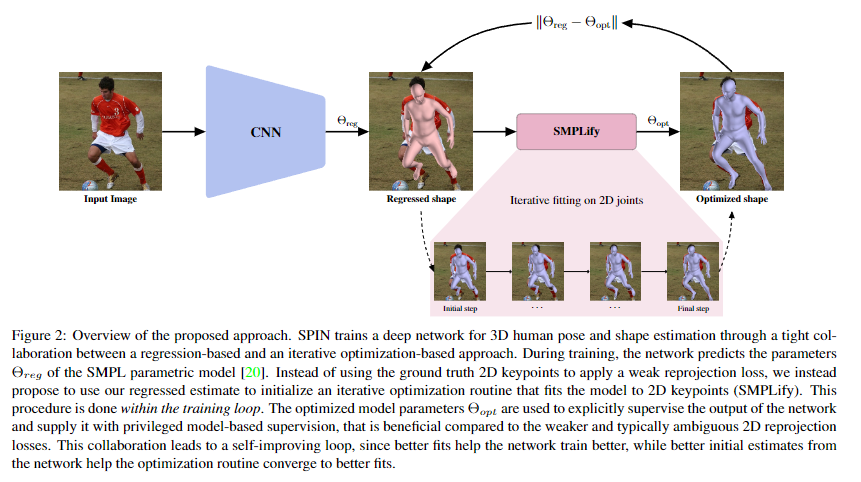
Abstract Model-based human pose estimation is currently approached through two different paradigms. Optimization-based methods fit a parametric body model to 2D observations in an iterative manner, leading to accurate image-model alignments, but are often slow and sensitive to the initialization. In contrast, regression-based methods, that use a deep network to directly estimate the model parameters from pixels, tend to provide reasonable, but not pixel accurate, results while requiring huge amounts of supervision. In this work, instead of investigating which approach is better, our key insight is that the two paradigms can form a strong collaboration. A reasonable, directly regressed estimate from the network can initialize the iterative optimization making the fitting faster and more accurate. Similarly, a pixel accurate fit from iterative optimization can act as strong supervision for the network. This is the core of our proposed approach SPIN (SMPL oPtimization IN the loop). The deep network initializes an iterative optimization routine that fits the body model to 2D joints within the training loop, and the fitted estimate is subsequently used to supervise the network. Our approach is self-improving by nature, since better network estimates can lead the optimization to better solutions, while more accurate optimization fits provide better supervision for the network. We demonstrate the effectiveness of our approach in different settings, where 3D ground truth is scarce, or not available, and we consistently outperform the state-of-the-art model-based pose estimation approaches by significant margins.【Paper】 > 【Github_Code】 > 【Project】
SPIN - SMPL oPtimization IN the loop
【2015】SMPL: A Skinned Multi-Person Linear Model
Authors: Matthew Loper
Abstract We present a learned model of human body shape and pose-dependent shape variation that is more accurate than previous models and is compatible with existing graphics pipelines. Our Skinned Multi-Person Linear model (SMPL) is a skinned vertex-based model that accurately represents a wide variety of body shapes in natural human poses. The parameters of the model are learned from data including the rest pose template, blend weights, pose-dependent blend shapes, identity-dependent blend shapes, and a regressor from vertices to joint locations. Unlike previous mod- els, the pose-dependent blend shapes are a linear function of the elements of the pose rotation matrices. This simple formulation enables training the entire model from a relatively large number of aligned 3D meshes of different people in different poses. We quantitatively evaluate variants of SMPL using linear or dual-quaternion blend skinning and show that both are more accurate than a Blend-SCAPE model trained on the same data. We also extend SMPL to realistically model dynamic soft-tissue deformations. Because it is based on blend skinning, SMPL is compatible with existing rendering engines and we make it available for research purposes.【Paper】 > 【Github_Code】 > 【Project无】
【ICCV 2021】ROMP:Monocular, One-stage, Regression of Multiple 3D People
Authors: Yu Sun, Qian Bao, Wu Liu, Yili Fu, Michael J. Black, Tao Mei
Abstract This paper focuses on the regression of multiple 3D people from a single RGB image. Existing approaches predominantly follow a multi-stage pipeline that first detects people in bounding boxes and then independently regresses their 3D body meshes. In contrast, we propose to Regress all meshes in a One-stage fashion for Multiple 3D People (termed ROMP). The approach is conceptually simple, bounding box-free, and able to learn a per-pixel representation in an end-to-end manner. Our method simultaneously predicts a Body Center heatmap and a Mesh Parameter map, which can jointly describe the 3D body mesh on the pixel level. Through a body-center-guided sampling process, the body mesh parameters of all people in the image are easily extracted from the Mesh Parameter map. Equipped with such a fine-grained representation, our one-stage framework is free of the complex multi-stage process and more robust to occlusion. Compared with state-of-the-art methods, ROMP achieves superior performance on the challenging multi-person benchmarks, including 3DPW and CMU Panoptic. Experiments on crowded/occluded datasets demonstrate the robustness under various types of occlusion. The released code is the first real-time implementation of monocular multi-person 3D mesh regression.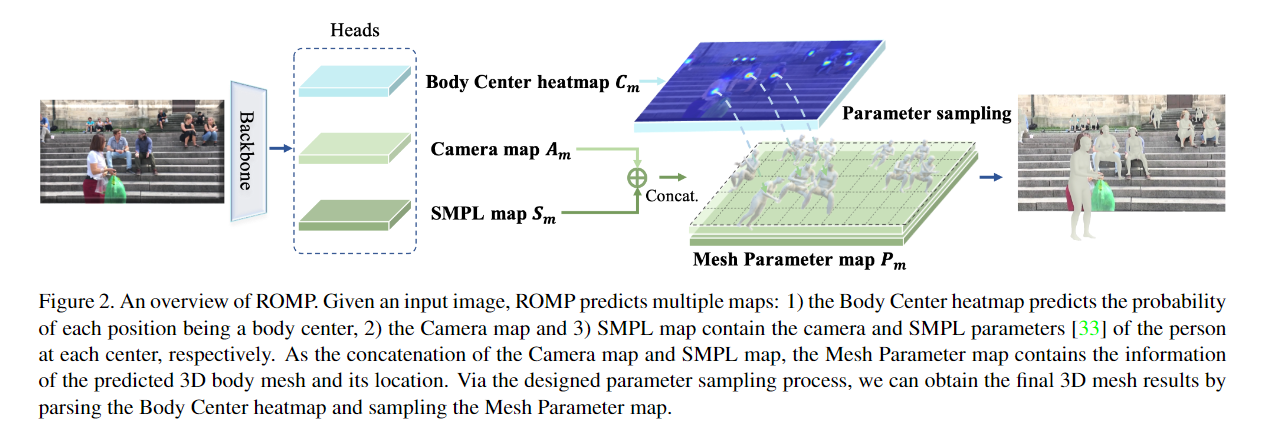
【CVPR2022】BEV:Putting People in their Place: Monocular Regression of 3D People in Depth
Authors: Yu Sun, Wu Liu, Qian Bao, Yili Fu, Tao Mei, Michael J. Black
Abstract Given an image with multiple people, our goal is to directly regress the pose and shape of all the people as well as their relative depth. Inferring the depth of a person in an image, however, is fundamentally ambiguous without knowing their height. This is particularly problematic when the scene contains people of very different sizes, e.g. from infants to adults. To solve this, we need several things. First, we develop a novel method to infer the poses and depth of multiple people in a single image. While previous work that estimates multiple people does so by reasoning in the image plane, our method, called BEV, adds an additional imaginary Bird's-Eye-View representation to explicitly reason about depth. BEV reasons simultaneously about body centers in the image and in depth and, by combing these, estimates 3D body position. Unlike prior work, BEV is a single-shot method that is end-to-end differentiable. Second, height varies with age, making it impossible to resolve depth without also estimating the age of people in the image. To do so, we exploit a 3D body model space that lets BEV infer shapes from infants to adults. Third, to train BEV, we need a new dataset. Specifically, we create a "Relative Human" (RH) dataset that includes age labels and relative depth relationships between the people in the images. Extensive experiments on RH and AGORA demonstrate the effectiveness of the model and training scheme. BEV outperforms existing methods on depth reasoning, child shape estimation, and robustness to occlusion. The code and dataset are released for research purposes.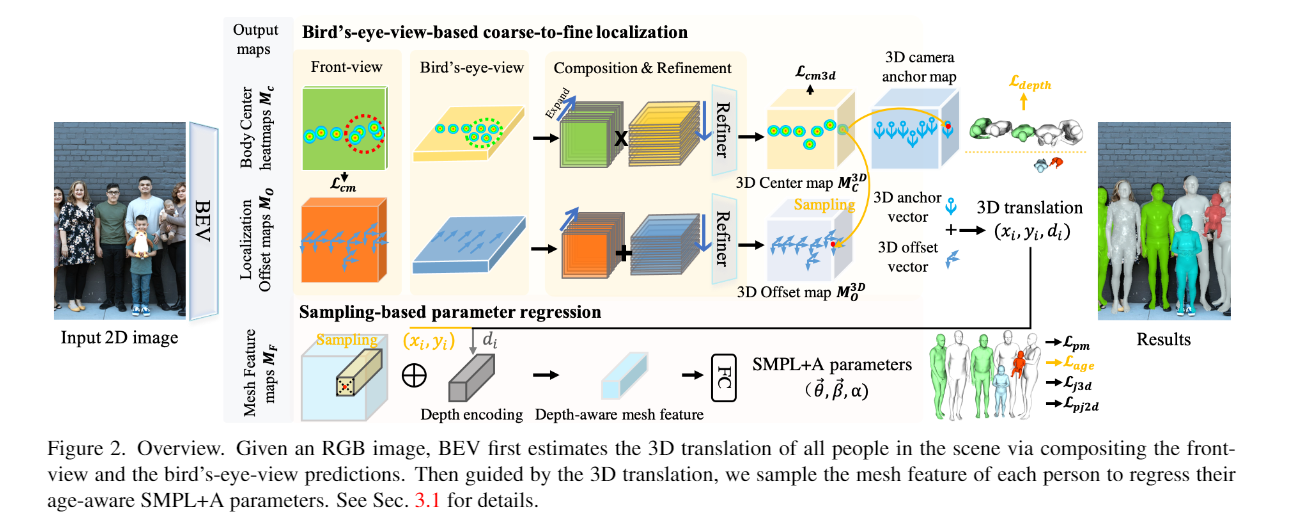
【CVPR2023】TRACE: 5D Temporal Regression of Avatars with Dynamic Cameras in 3D Environments
Authors: Yu Sun, Qian Bao, Wu Liu, Tao Mei, Michael J. Black
Abstract Although the estimation of 3D human pose and shape (HPS) is rapidly progressing, current methods still cannot reliably estimate moving humans in global coordinates, which is critical for many applications. This is particularly challenging when the camera is also moving, entangling human and camera motion. To address these issues, we adopt a novel 5D representation (space, time, and identity) that enables end-to-end reasoning about people in scenes. Our method, called TRACE, introduces several novel architectural components. Most importantly, it uses two new "maps" to reason about the 3D trajectory of people over time in camera, and world, coordinates. An additional memory unit enables persistent tracking of people even during long occlusions. TRACE is the first one-stage method to jointly recover and track 3D humans in global coordinates from dynamic cameras. By training it end-to-end, and using full image information, TRACE achieves state-of-the-art performance on tracking and HPS benchmarks. The code and dataset are released for research purposes.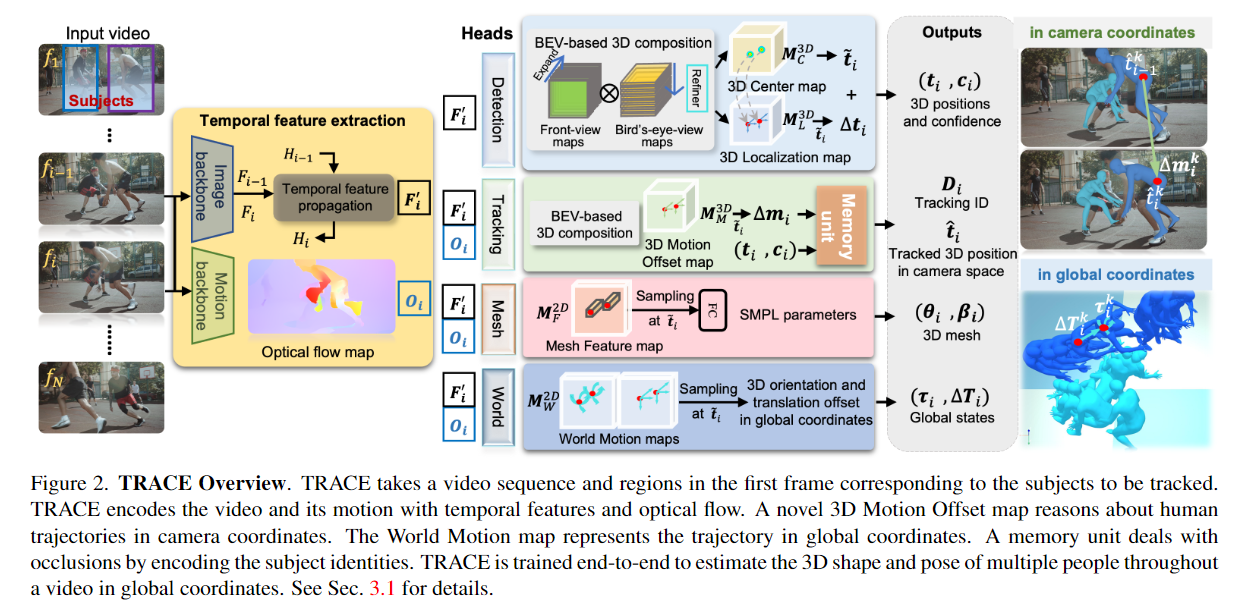
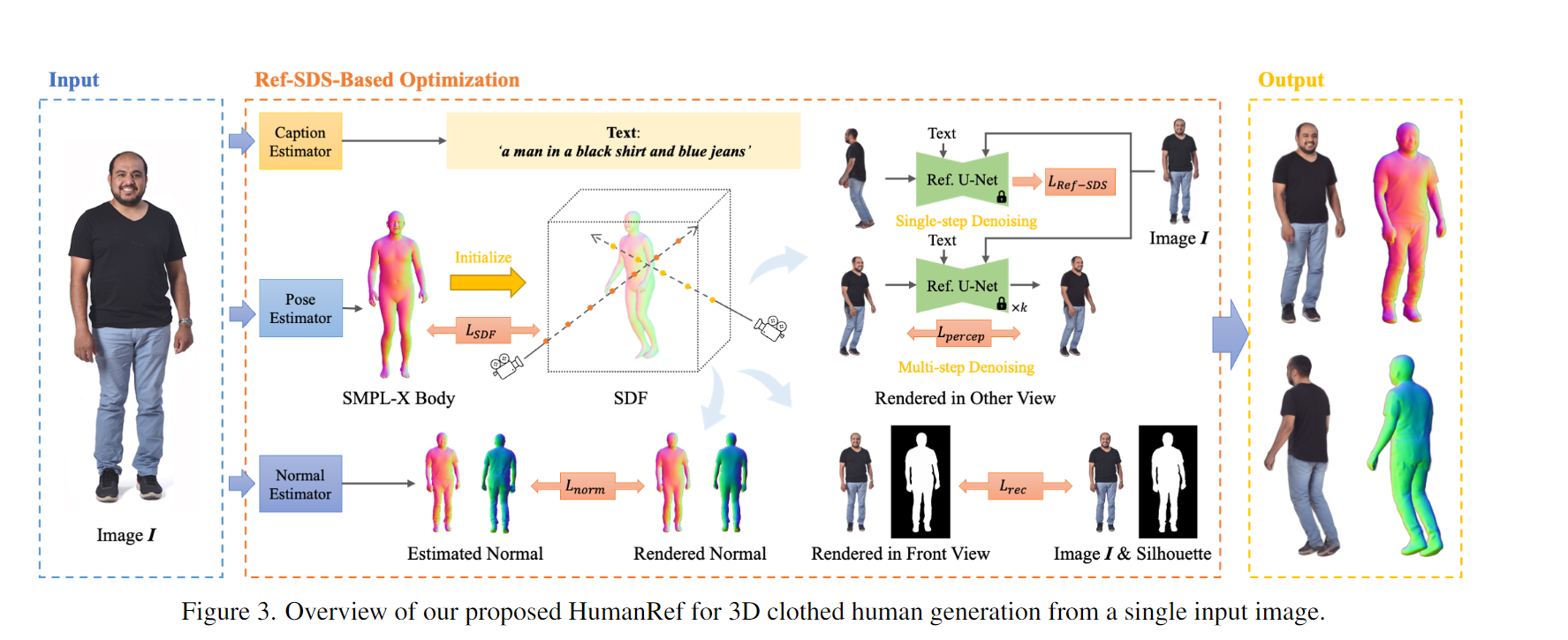
【CVPR 2024】HumanRef: Single Image to 3D Human Generation via Reference-Guided Diffusion
Authors: Jingbo Zhang, Xiaoyu Li, Qi Zhang, Yanpei Cao, Ying Shan, Jing Liao
Abstract Generating a 3D human model from a single reference image is challenging because it requires inferring textures and geometries in invisible views while maintaining consistency with the reference image. Previous methods utilizing 3D generative models are limited by the availability of 3D training data. Optimization-based methods that lift text-to-image diffusion models to 3D generation often fail to preserve the texture details of the reference image, resulting in inconsistent appearances in different views. In this paper, we propose HumanRef, a 3D human generation framework from a single-view input. To ensure the generated 3D model is photorealistic and consistent with the input image, HumanRef introduces a novel method called reference-guided score distillation sampling (Ref-SDS), which effectively incorporates image guidance into the generation process. Furthermore, we introduce region-aware attention to Ref-SDS, ensuring accurate correspondence between different body regions. Experimental results demonstrate that HumanRef outperforms state-of-the-art methods in generating 3D clothed humans with fine geometry, photorealistic textures, and view-consistent appearances.【Paper】 > 【Github_Code】 > 【Project】 > 【中文解读】
【arxiv 2024.02】HumanSplat: Generalizable Single-Image Human Gaussian Splatting with Structure Priors
Authors: Panwang Pan, Zhuo Su, Chenguo Lin, Zhen Fan, Yongjie Zhang, Zeming Li, Tingting Shen, Yadong Mu, Yebin Liu
Abstract Despite recent advancements in high-fidelity human reconstruction techniques, the requirements for densely captured images or time-consuming per-instance optimization significantly hinder their applications in broader scenarios. To tackle these issues, we present HumanSplat which predicts the 3D Gaussian Splatting properties of any human from a single input image in a generalizable manner. In particular, HumanSplat comprises a 2D multi-view diffusion model and a latent reconstruction transformer with human structure priors that adeptly integrate geometric priors and semantic features within a unified framework. A hierarchical loss that incorporates human semantic information is further designed to achieve high-fidelity texture modeling and better constrain the estimated multiple views. Comprehensive experiments on standard benchmarks and in-the-wild images demonstrate that HumanSplat surpasses existing state-of-the-art methods in achieving photorealistic novel-view synthesis.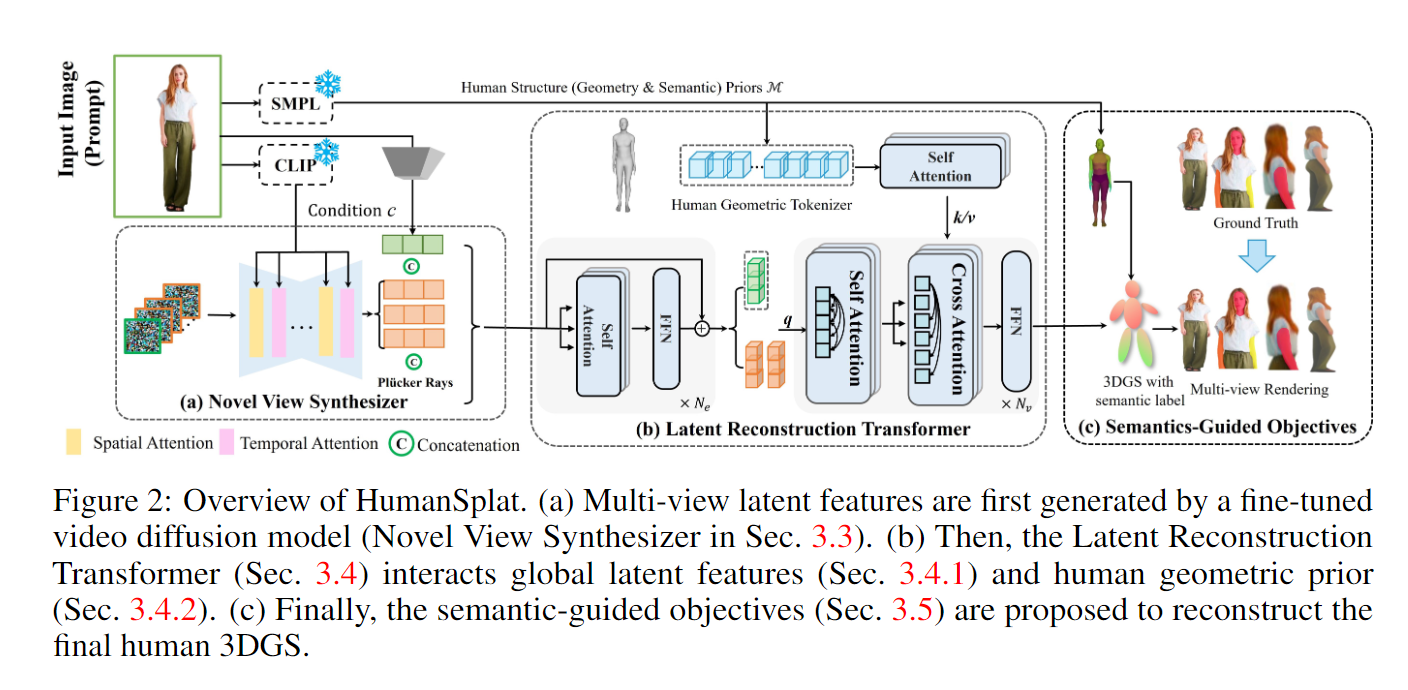
【CVPR 2024】GART: Gaussian Articulated Template Models
Authors: Jiahui Lei, Yufu Wang, Georgios Pavlakos, Lingjie Liu, Kostas Daniilidis
Abstract We introduce Gaussian Articulated Template Model GART, an explicit, efficient, and expressive representation for non-rigid articulated subject capturing and rendering from monocular videos. GART utilizes a mixture of moving 3D Gaussians to explicitly approximate a deformable subject's geometry and appearance. It takes advantage of a categorical template model prior (SMPL, SMAL, etc.) with learnable forward skinning while further generalizing to more complex non-rigid deformations with novel latent bones. GART can be reconstructed via differentiable rendering from monocular videos in seconds or minutes and rendered in novel poses faster than 150fps.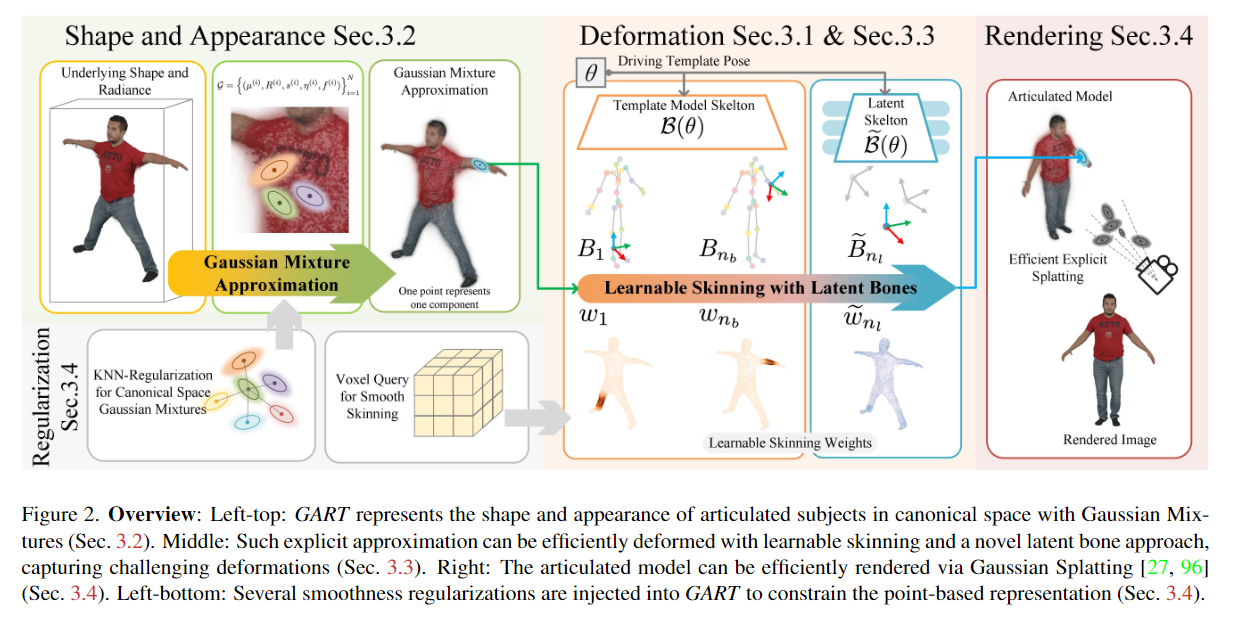
xxx 【arxiv 2024.02】
Authors:
Abstract【CVPR 2024】MeshPose: Unifying DensePose and 3D Body Mesh reconstruction
Authors: Eric-Tuan Lê, Antonis Kakolyris, Petros Koutras, Himmy Tam, Efstratios Skordos, George Papandreou, Rıza Alp Güler, Iasonas Kokkinos
Abstract DensePose provides a pixel-accurate association of images with 3D mesh coordinates, but does not provide a 3D mesh, while Human Mesh Reconstruction (HMR) systems have high 2D reprojection error, as measured by DensePose localization metrics. In this work we introduce MeshPose to jointly tackle DensePose and HMR. For this we first introduce new losses that allow us to use weak DensePose supervision to accurately localize in 2D a subset of the mesh vertices ('VertexPose'). We then lift these vertices to 3D, yielding a low-poly body mesh ('MeshPose'). Our system is trained in an end-to-end manner and is the first HMR method to attain competitive DensePose accuracy, while also being lightweight and amenable to efficient inference, making it suitable for real-time AR applications.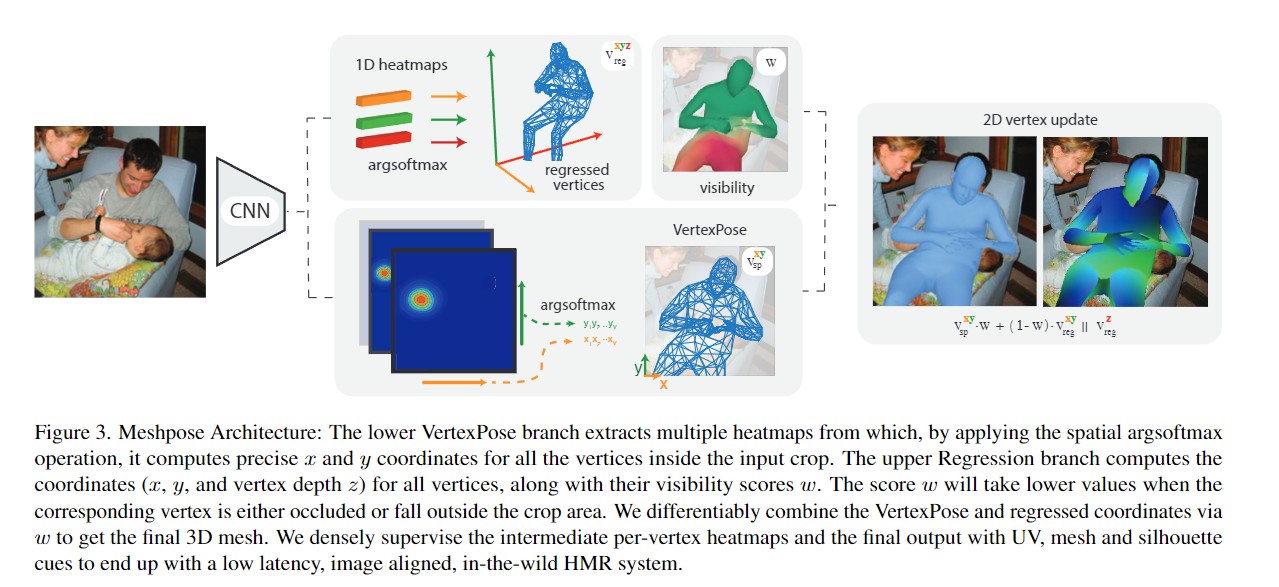
【arxiv 2024.06】MeshAnything: Artist-Created Mesh Generation with Autoregressive Transformers
Authors: Yiwen Chen, Tong He, Di Huang, Weicai Ye, Sijin Chen, Jiaxiang Tang, Xin Chen, Zhongang Cai, Lei Yang, Gang Yu, Guosheng Lin, Chi Zhang
Abstract Recently, 3D assets created via reconstruction and generation have matched the quality of manually crafted assets, highlighting their potential for replacement. However, this potential is largely unrealized because these assets always need to be converted to meshes for 3D industry applications, and the meshes produced by current mesh extraction methods are significantly inferior to Artist-Created Meshes (AMs), i.e., meshes created by human artists. Specifically, current mesh extraction methods rely on dense faces and ignore geometric features, leading to inefficiencies, complicated post-processing, and lower representation quality. To address these issues, we introduce MeshAnything, a model that treats mesh extraction as a generation problem, producing AMs aligned with specified shapes. By converting 3D assets in any 3D representation into AMs, MeshAnything can be integrated with various 3D asset production methods, thereby enhancing their application across the 3D industry. The architecture of MeshAnything comprises a VQ-VAE and a shape-conditioned decoder-only transformer. We first learn a mesh vocabulary using the VQ-VAE, then train the shape-conditioned decoder-only transformer on this vocabulary for shape-conditioned autoregressive mesh generation. Our extensive experiments show that our method generates AMs with hundreds of times fewer faces, significantly improving storage, rendering, and simulation efficiencies, while achieving precision comparable to previous methods.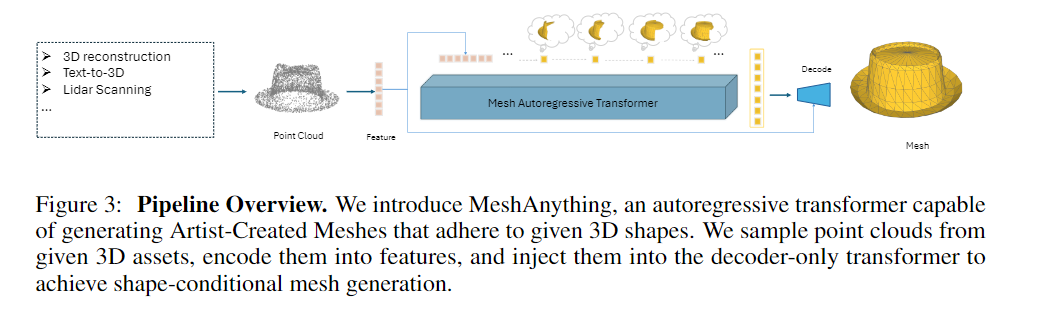
【arxiv 2024.06】Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion Models
Authors: Yuxuan Xue, Xianghui Xie, Riccardo Marin, Gerard Pons-Moll
Abstract Creating realistic avatars from a single RGB image is an attractive yet challenging problem. Due to its ill-posed nature, recent works leverage powerful prior from 2D diffusion models pretrained on large datasets. Although 2D diffusion models demonstrate strong generalization capability, they cannot provide multi-view shape priors with guaranteed 3D consistency. We propose Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion. Our key insight is that 2D multi-view diffusion and 3D reconstruction models provide complementary information for each other, and by coupling them in a tight manner, we can fully leverage the potential of both models. We introduce a novel image-conditioned generative 3D Gaussian Splats reconstruction model that leverages the priors from 2D multi-view diffusion models, and provides an explicit 3D representation, which further guides the 2D reverse sampling process to have better 3D consistency. Experiments show that our proposed framework outperforms state-of-the-art methods and enables the creation of realistic avatars from a single RGB image, achieving high-fidelity in both geometry and appearance. Extensive ablations also validate the efficacy of our design, (1) multi-view 2D priors conditioning in generative 3D reconstruction and (2) consistency refinement of sampling trajectory via the explicit 3D representation.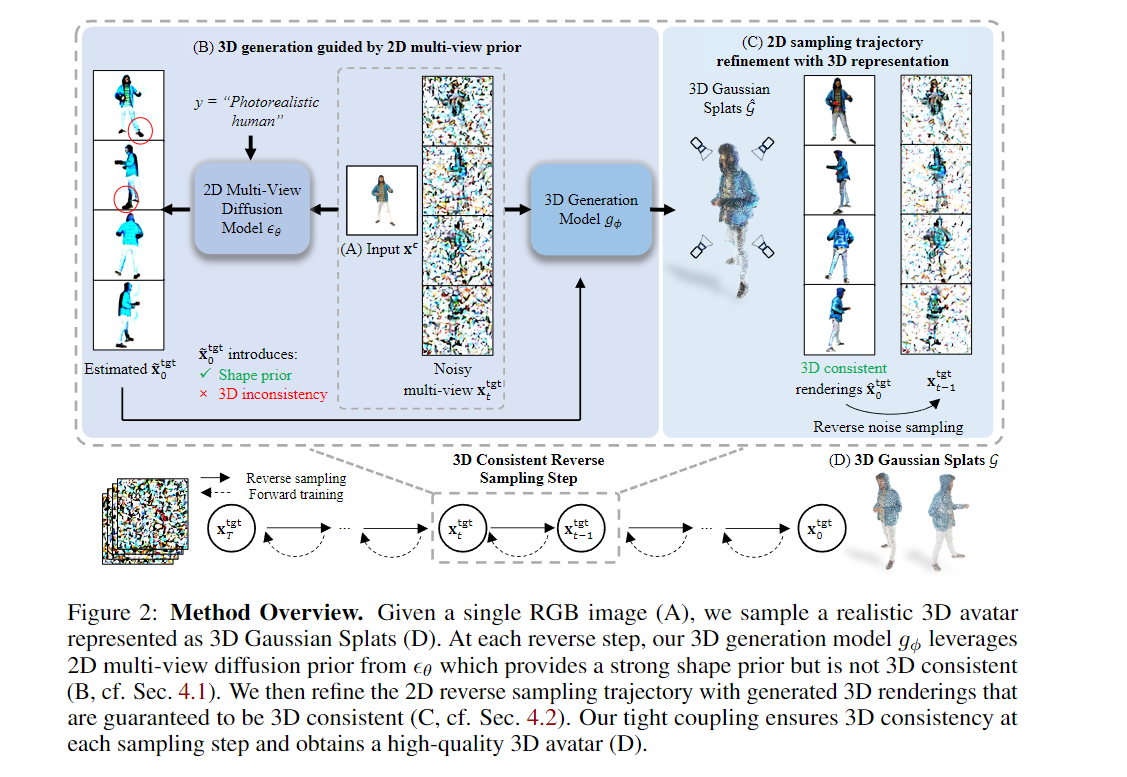
【arxiv 2024.06】A Survey on 3D Human Avatar Modeling – From Reconstruction to Generation
Authors: Ruihe Wang, Yukang Cao, Kai Han, Kwan-Yee K. Wong
Abstract 3D modeling has long been an important area in computer vision and computer graphics. Recently, thanks to the breakthroughs in neural representations and generative models, we witnessed a rapid development of 3D modeling. 3D human modeling, lying at the core of many real-world applications, such as gaming and animation, has attracted significant attention. Over the past few years, a large body of work on creating 3D human avatars has been introduced, forming a new and abundant knowledge base for 3D human modeling. The scale of the literature makes it difficult for individuals to keep track of all the works. This survey aims to provide a comprehensive overview of these emerging techniques for 3D human avatar modeling, from both reconstruction and generation perspectives. Firstly, we review representative methods for 3D human reconstruction, including methods based on pixel-aligned implicit function, neural radiance field, and 3D Gaussian Splatting, etc. We then summarize representative methods for 3D human generation, especially those using large language models like CLIP, diffusion models, and various 3D representations, which demonstrate state-of-the-art performance. Finally, we discuss our reflection on existing methods and open challenges for 3D human avatar modeling, shedding light on future research.xxx 【arxiv 2024.02】
Authors:
Abstractxxx 【arxiv 2024.02】
Authors:
Abstractxxx 【arxiv 2024.02】
Authors:
Abstractxxx 【arxiv 2024.02】
Authors:
Abstractxxx 【arxiv 2024.02】
Authors:
Abstractxxx 【arxiv 2024.02】
Authors:
Abstractxxx 【arxiv 2024.02】
Authors:
Abstractxxx 【arxiv 2024.02】
Authors:
Abstractxxx 【arxiv 2024.02】
Authors:
Abstract原文地址:https://blog.csdn.net/qq_45934285/article/details/140096607
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!