Python基于Django、大数据的北极星招聘数据可视化系统
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w+、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌
🍅文末获取源码联系🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
2022-2024年最全的计算机软件毕业设计选题大全:1000个热门选题推荐✅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
文章目录
前言:
嗨喽,大家好,今天为大家带来的是Python基于Django、大数据的北极星招聘数据可视化系统,该项目使用 Django 框架,Mysql 数据库,request,selenium 框架进行爬虫,实现招聘数据的采集,清洗等,该项目总体来说还是挺不错的,界面美观,下面针对这个项目做具体介绍。
1:项目涉及技术:
项目后端语言:python django
项目页面布局展现:前端bootstrap
项目数据可视化呈现:html, css,echars
项目数据操作:mysql数据库
项目数据获取方式:爬虫(selenium)
2 Django 介绍
Django 是一个高级的 Python Web 框架,它鼓励快速开发和干净、实用的设计。以下是 Django 的一些优缺点以及如何使用它来搭建网站的基本步骤:
Django 的优点
- 完备的功能:Django 提供了包括 ORM、模板引擎、表单验证、管理后台等在内的全套工具,适合快速开发企业级网站。
- 可扩展性:Django 的设计允许它随着项目的成长而扩展,可以轻松地将新的模块集成到现有的 Web 应用程序中。
- 巨大的生态系统:Django 拥有一个庞大的社区和丰富的第三方库,可以大大加快开发进程。
- 社区支持:Django 拥有一个活跃的社区,提供详细的文档和教程,对开发者非常有帮助。
- 安全性:Django 内置了许多安全特性,如防止 SQL 注入、跨站脚本(XSS)、跨站请求伪造(CSRF)等。
Django 的缺点
- 学习曲线较陡峭:Django 的强大功能也意味着它有一定的学习曲线,初学者可能需要时间来掌握。
- 速度相对较慢:Django 是一个重量级框架,在处理大量请求时,性能可能受到影响。
- 模板系统:Django 的模板系统虽然功能强大,但可能不如某些其他模板引擎灵活。
如何使用 Django 搭建网站
- 安装 Django:首先需要安装 Python,然后使用 pip 安装 Django。
- 创建项目:使用
django-admin startproject myproject命令创建一个新的 Django 项目。 - 创建应用:在项目中创建一个或多个应用,使用
python manage.py startapp myapp。 - 定义模型:在应用的
models.py文件中定义数据模型,这些模型将映射到数据库表。 - 配置 URL:在项目的
urls.py文件中配置 URL 路由,将 URL 路径映射到视图函数。 - 编写视图:在应用的
views.py文件中编写视图逻辑,处理用户请求并返回响应。 - 创建模板:制作 HTML 模板来展示数据和用户界面。
- 运行开发服务器:使用
python manage.py runserver启动 Django 开发服务器,测试网站。 - 数据库迁移:使用
python manage.py migrate命令应用数据库迁移,创建数据模型的数据库表。 - 管理后台:Django 自带一个强大的管理后台,可以通过少量配置来管理网站内容。
- 部署:最后,将网站部署到生产服务器上,这可能涉及到配置 Web 服务器、数据库和静态文件服务。
通过这些步骤,你可以使用 Django 搭建一个功能完备的网站。Django 的强大功能和社区支持使得它成为许多开发者构建 Web 应用程序的首选框架。
总的来说,Django 是一个功能强大、适合快速开发的 Web 框架,尤其适合那些需要快速构建复杂 Web 应用的项目。然而,对于需要高度定制化或轻量级解决方案的项目,可能需要考虑其他框架。
Python 爬虫功能实现
Python Selenium 是一个自动化测试工具集合,主要用于Web应用程序的测试。Selenium 可以模拟用户在浏览器中的行为,如点击、滚动、键入等,因此它也常被用于Web爬虫的开发,尤其是对于那些需要与JavaScript交互的动态网页。
Selenium 简介
Selenium 支持多种编程语言,包括 Python、Java、C# 等。在 Python 中,Selenium 提供了一个简单的 API 来编写测试脚本。Selenium 通过 WebDriver 与浏览器进行交互,WebDriver 是一个浏览器自动化的驱动程序,Selenium 支持所有主流浏览器,如 Chrome、Firefox、Safari、Edge 等。
Selenium 的主要组件
- WebDriver:直接与浏览器进行交互的接口。
- Remote WebDriver:允许你通过 Selenium Server 在不同的机器上运行测试。
- Selenium API:提供了一组简单的命令来控制 WebDriver。
如何使用 Selenium 爬虫
使用 Selenium 进行爬虫的基本步骤如下:
-
安装 Selenium:在 Python 环境中安装 Selenium 库。
pip install selenium -
下载 WebDriver:根据你使用的浏览器,下载对应的 WebDriver。例如,如果你使用 Chrome 浏览器,你需要下载 ChromeDriver。
-
编写爬虫脚本:使用 Selenium 的 API 编写爬虫脚本,模拟用户行为获取动态内容。
-
运行爬虫:执行脚本,Selenium 将自动打开浏览器,模拟用户操作,获取网页数据。
下面是一个简单的 Selenium 爬虫示例:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
# 初始化 WebDriver
driver = webdriver.Chrome('/path/to/chromedriver')
# 打开网页
driver.get('http://example.com')
# 等待页面加载
time.sleep(3) # 简单睡眠等待,实际应用中应使用更智能的等待条件
# 找到元素并进行操作,例如输入文本
element = driver.find_element_by_name('q')
element.send_keys('Python')
element.send_keys(Keys.RETURN)
# 等待搜索结果
time.sleep(3)
# 获取搜索结果页面的标题
print(driver.title)
# 关闭浏览器
driver.quit()
注意事项
- 遵守 robots.txt:在进行爬虫之前,应该检查目标网站的
robots.txt文件,以确保你的爬虫行为是被允许的。 - 设置合理的请求频率:避免对目标网站服务器造成过大压力。
- 异常处理:在爬虫中添加异常处理逻辑,确保在遇到错误时能够正确处理。
- 数据解析:获取到的网页内容通常需要进一步解析,可以使用 BeautifulSoup、lxml 等库来提取所需数据。
Selenium 爬虫适用于那些需要模拟用户交互才能获取数据的网站,但它通常比纯粹的 HTTP 请求库(如 requests)慢,因为它需要启动浏览器实例。因此,对于静态内容的抓取,通常推荐使用更轻量级的方法。
3:项目功能:
1 登录注册
爬取数据后启动项目会把数据都存放在数据库里,(数据库有3个表,一个工作岗位信息表,一个用用户信息表,一个工作收藏表),然后进入项目的登陆注册页面,以及会对用户的账号密码经行校验和存储,校验成功后进入首页:
首页招聘数据
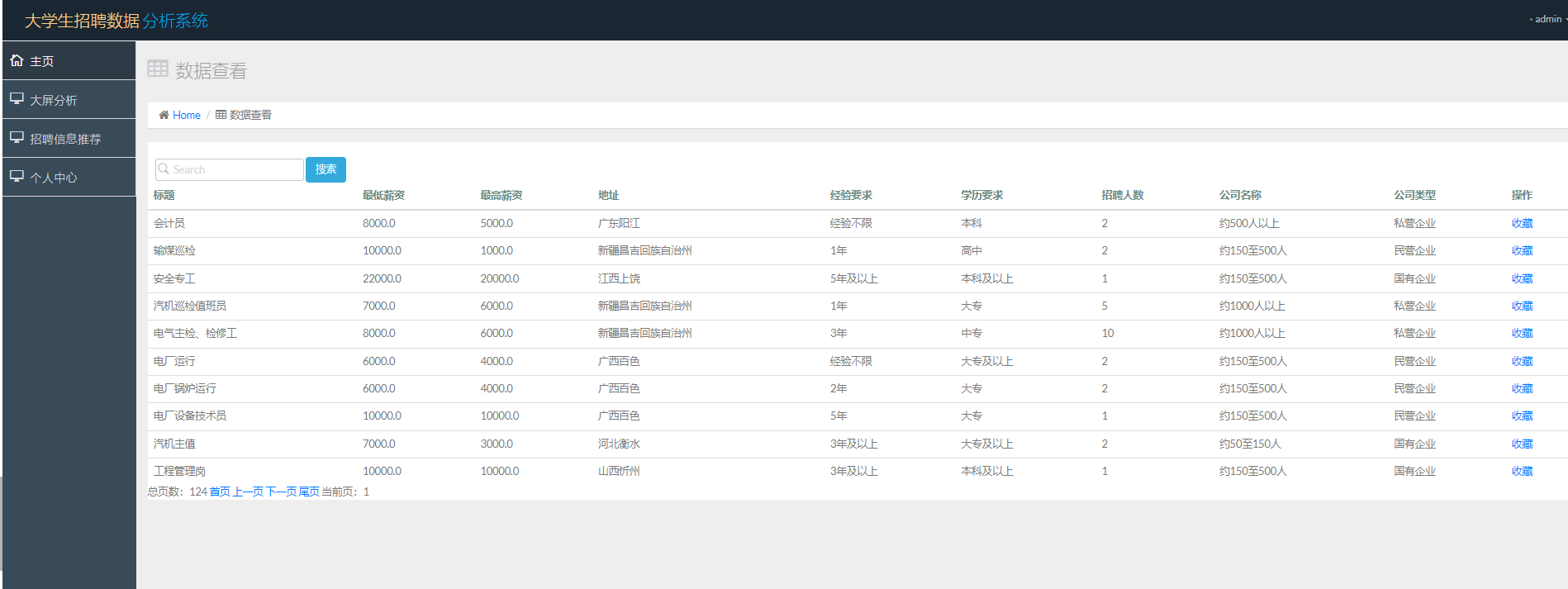
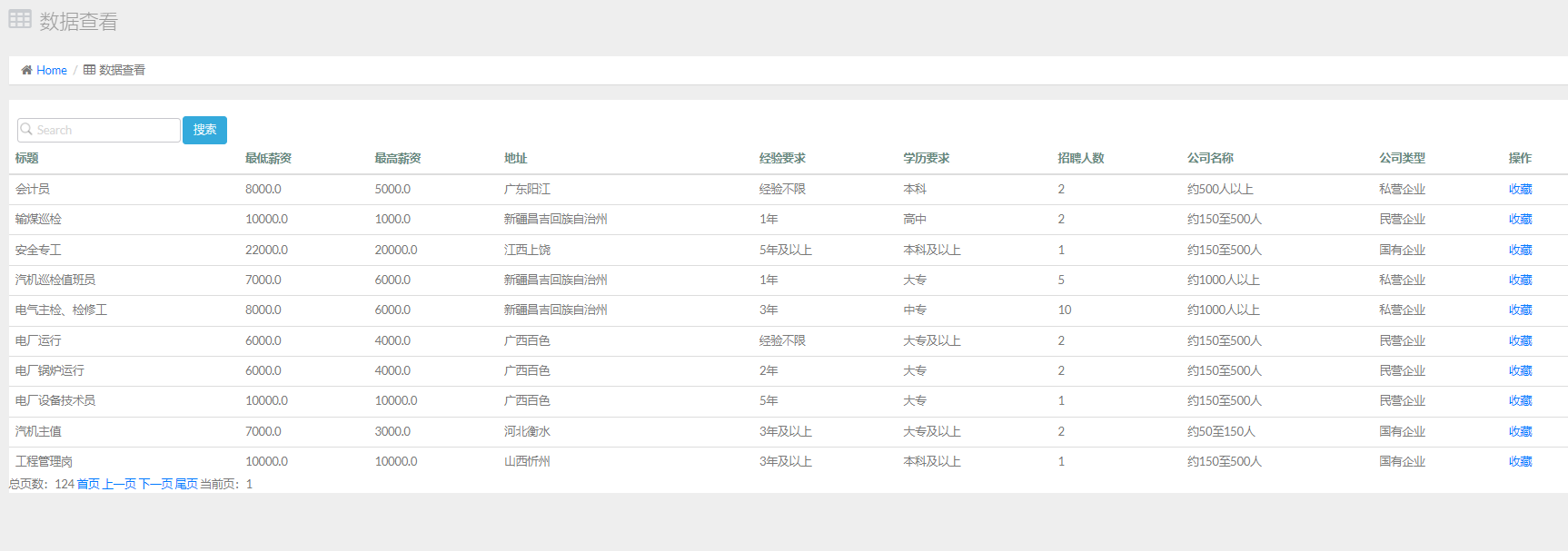
招聘数据
这里的招聘数据,是我们爬虫的数据,存储在 mysql 数据库当中,如果我们想要展示,可以通过读取数据库进行展示,同时进行分页
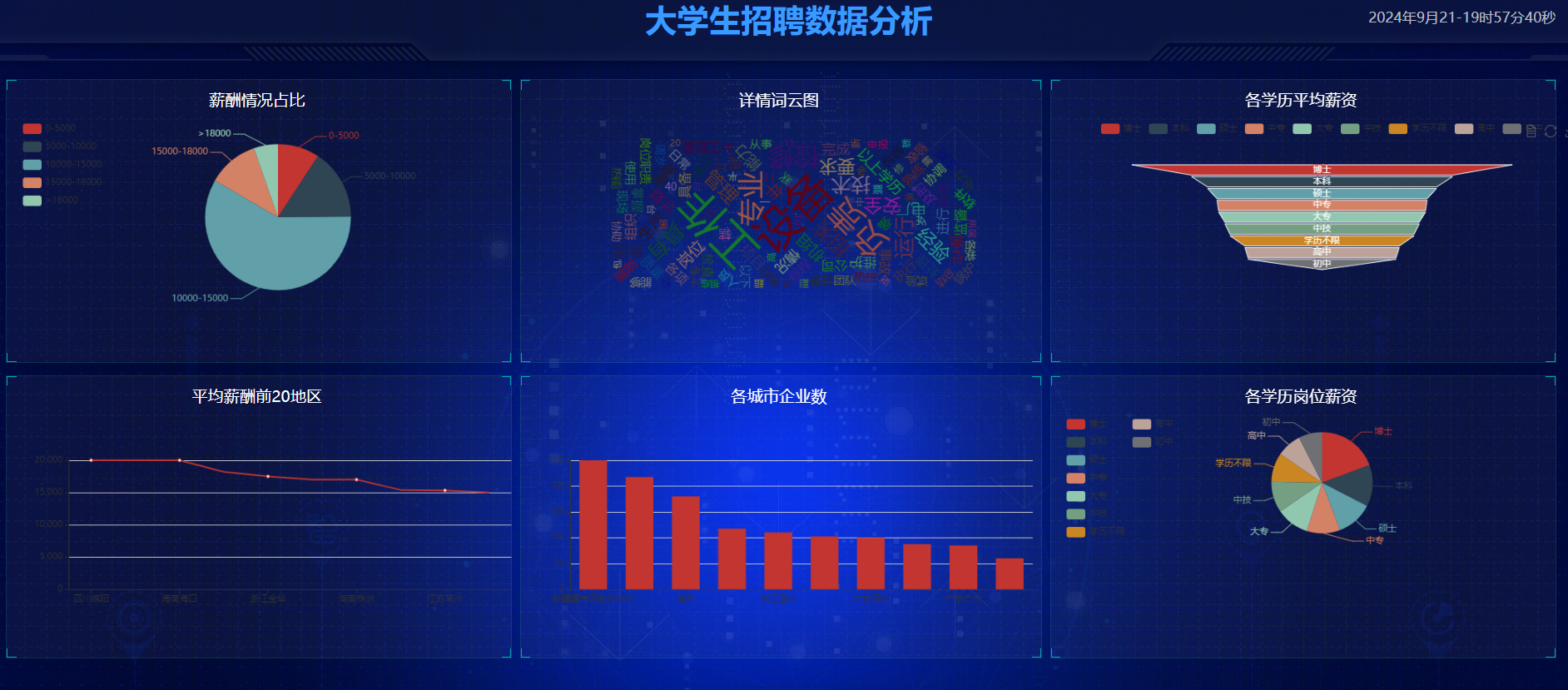
招聘数据可视化
4 推荐阅读
5 源码获取:
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
2022-2024年最全的计算机软件毕业设计选题大全:1000个热门选题推荐✅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
原文地址:https://blog.csdn.net/JasonXu94/article/details/142423023
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!