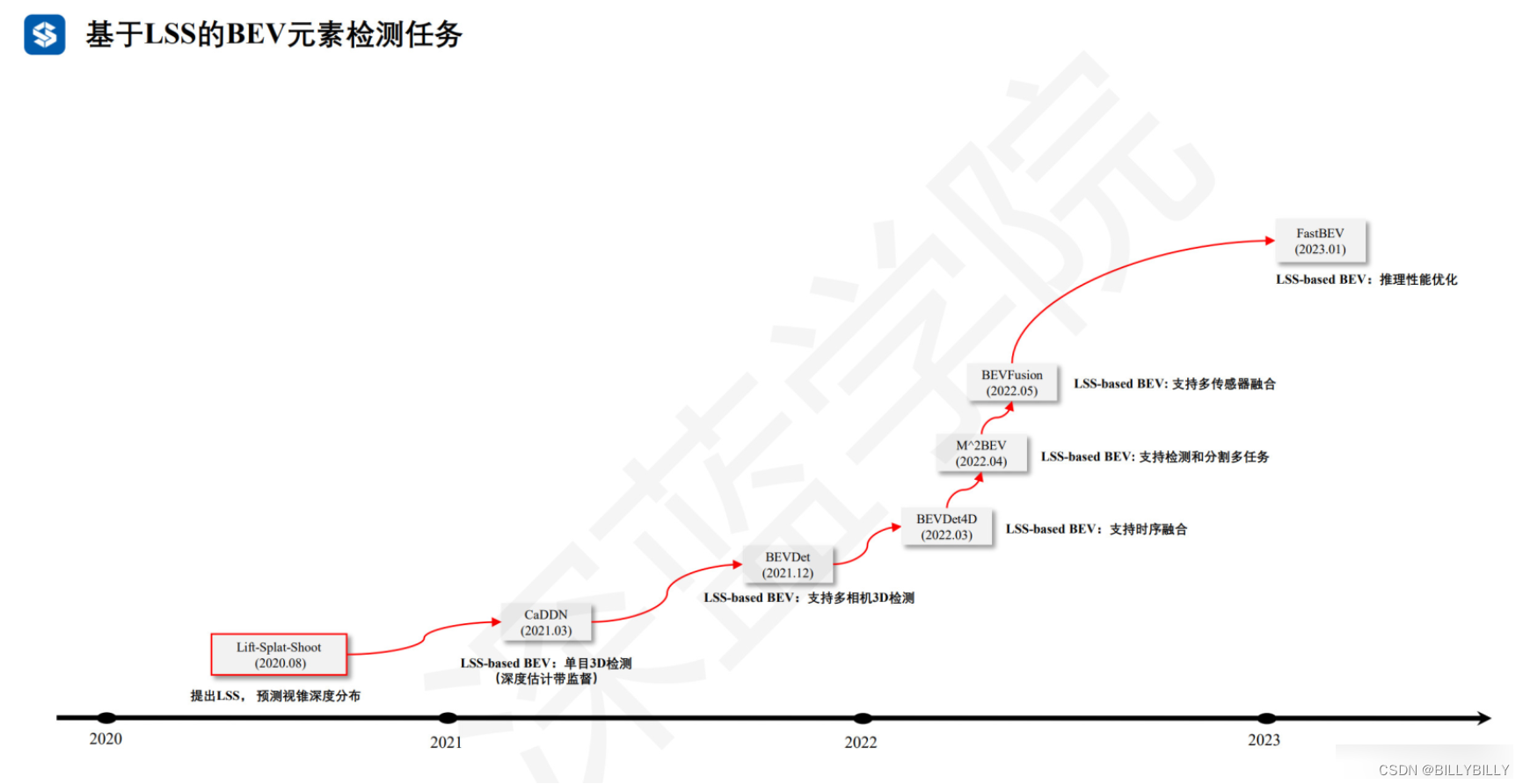
【3D->2D转换(1)】LSS(提升,投放,捕捉)
Lift, Splat, Shoot
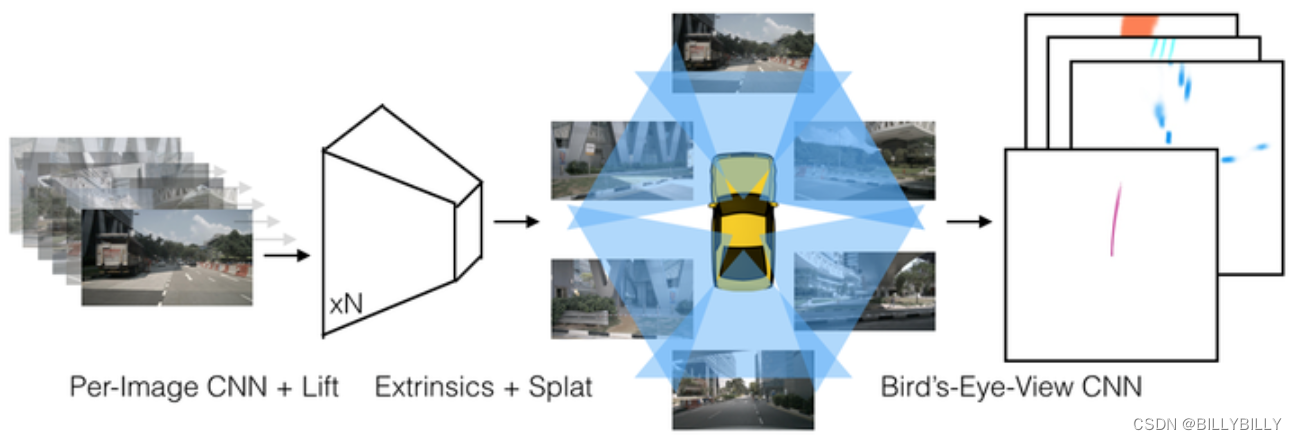
这是一个端到端架构,直接从任意数量的摄像头数据提取给定图像场景的鸟瞰图表示。将每个图像分别“提升(lift)”到每个摄像头的视锥(frustum),然后将所有视锥“投放(splat)”到光栅化的鸟瞰图网格中。这里要学习的是,如何表示图像以及如何将所有摄像机的预测融合到场景的单个拼接表示,同时又能抵抗标定误差。为学习运动规划的密集表示,这里模型推断的表示,“捕捉(shoot)”模板轨迹到网络输出的鸟瞰损失图,从而实现可解释的端到端运动规划。
本文采用像素级深度分布,将图像特征映射到BEV上。输入图像HW3 ,D代表离散深度维度,对于每个像素都有 (h,w,d) ,这样我们模型预测结果 HWD 。同时对每个像素都会提取出长度为c的向量,和一个深度分布 的向量( 为归一化的),c维度的特征,在D维度上进行重复,并乘上对应的 值,得到下图。
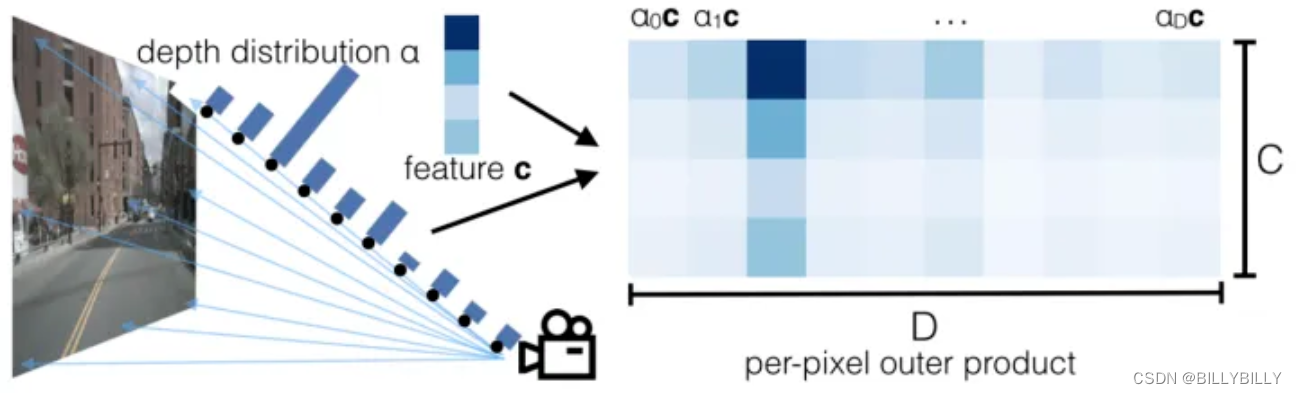
每个像素+深度值,得到一个 (x,y,z) 点,再像pointpillar一样处理,每个点落在最近的pillar上,在高程上求sum pooling。整个过程,可以通过像OFT中的积分表来进行加速。不同相机之间,通过外参+depth来对齐。
lift是提升,即像pointpillar中特征通过pointnet来提升维度;splat为投放,即将特征放在BEV上。
原文地址:https://blog.csdn.net/m0_51579041/article/details/140149586
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!