使用自己的数据基于SWIFT微调Qwen-Audio-Chat模型
目录
使用自己的数据
官方参考文档:这里
训练参数设置
训练时去掉参数:
--dataset aishell1-mini-zh
使用如下参数:
--custom_train_dataset_path aishell_train.jsonl
--custom_val_dataset_path aishell_val.jsonl
--dataset_test_ratio 0.01
自己的数据准备
jsonl格式
语音转写任务
{'query': 'Audio 1:<audio>***.wav</audio>\n语音转文本', 'response': '转录文本'}
每一行是一个json字典串,有两个key,分别是query和response,query对应部分按照格式填写,将自己的wav路径添加进去;response是对应的标注。
本例子是语音转写任务,这里的Prompt是"语音转文本",response对应的内容即为语音转文本的内容。
语音分类任务
{'query': 'Audio 1:<audio>***.wav</audio>\n语音分类:男声、女声', 'response': '男声'}
Prompt: “语音分类:男声、女声”; response的内容为‘男声’或者‘女声’。
其他的任务可以参考这两个任务自己设计,将自己的数据处理为这种格式。
例如:
{'query': 'Audio 1:<audio>/root/.cache/modelscope/hub/datasets/speech_asr/speech_asr_aishell1_trainsets/master/data_files/extracted/037bf9a958c0e200c49ae900894ba0af40f592bb98f2dab81415c11e8ceac132/speech_asr_aishell_testsets/wav/test/S0764/BAC009S0764W0217.wav</audio>\n语音转文本', 'response': '营造良好的消费环境'}
开始训练
训练脚本:scripts/qwen_audio_chat/lora_ddp_ds/sft.sh
不同训练方法
mp
mp(Model Parallel Training):
CUDA_VISIBLE_DEVICES=0,1
ddp
ddp(Data Parallel Training):
CUDA_VISIBLE_DEVICES=0,1
NPROC_PER_NODE=2 \
mp + ddp
mp+ddp(Combining Model Parallelism and Data Parallelism):
NPROC_PER_NODE=2
CUDA_VISIBLE_DEVICES=0,1,2,3 \
deepspeed
ZeRO2:
–deepspeed default-zero2 \
ZeRO3:
–deepspeed default-zero3 \
–ddp_backend nccl
训练实例
如下为mp + ddp + zero3训练(这种训练比较快,选择这种即可)
nproc_per_node=8
PYTHONPATH=../../.. \
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
torchrun \
--nproc_per_node=$nproc_per_node \
--master_port 29500 \
llm_sft.py \
--model_type qwen-audio-chat \
--sft_type lora \
--tuner_backend swift \
--template_type AUTO \
--dtype AUTO \
--output_dir output \
--ddp_backend nccl \
--custom_train_dataset_path data/multiclass_train.jsonl \
--dataset_test_ratio 0.001 \
--train_dataset_sample -1 \
--num_train_epochs 3 \
--max_length 2048 \
--check_dataset_strategy warning \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout_p 0.05 \
--lora_target_modules DEFAULT \
--gradient_checkpointing true \
--batch_size 8 \
--weight_decay 0.01 \
--learning_rate 1e-4 \
--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \
--max_grad_norm 0.5 \
--warmup_ratio 0.03 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 10 \
--use_flash_attn false \
--deepspeed default-zero3 \
--save_only_model true \
--lazy_tokenize true \
训练详情
Qwen-Audio-Chat模型
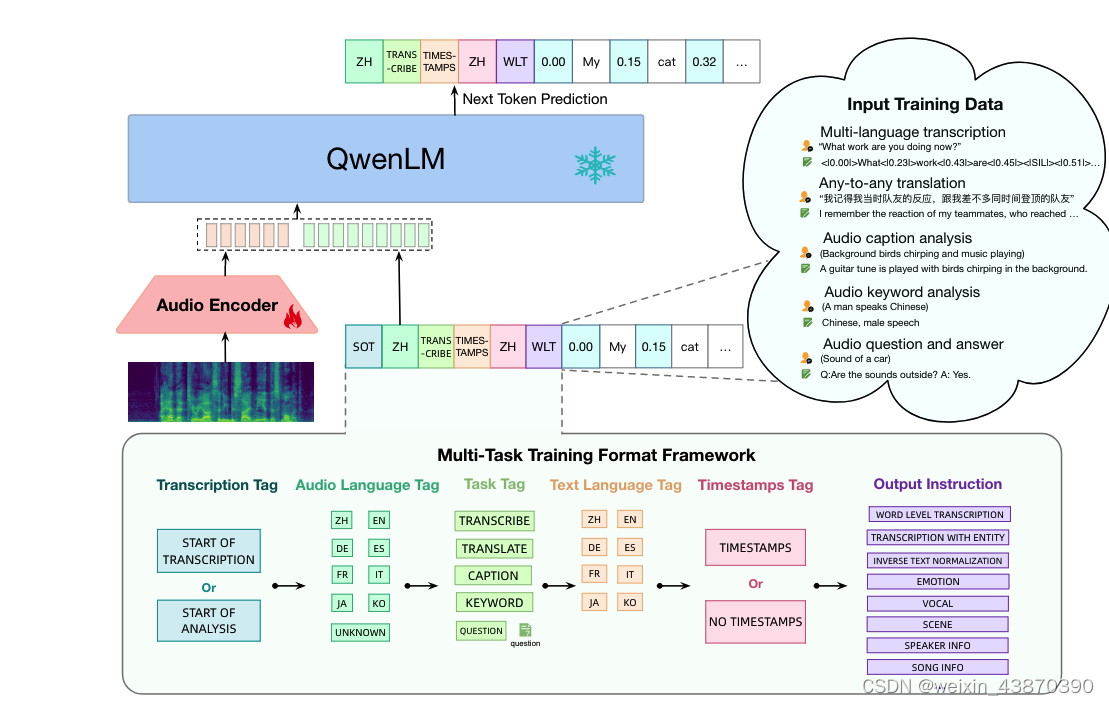
其中AudioEncoder部分使用Whisper-large-v2的音频编码初始化。QwenLM部分用 Qwen-7B 的预训练模型作为语言模型初始化。上述训练基于Qwen-Audio-Chat进行基于LORA的SFT微调训练。微调时冻结Encoder参数,冻结QwenLM参数,只在QwenLM的attn中增加lora参数。Qwen-Audio-Chat的总体参数为8398.4968M,其中QwenLM为7B参数,Encoder部分640M参数,lora参数为4.1943M Trainable [0.0499%]。
训练之后的模型存放位置:output/qwen-audio-chat/v6-20240402-032912/checkpoint-27500/
训练使用8卡RTX 6000,使用900h数据,共计训练1.38迭代,耗时118h,约5.9天。
模型数据实例
template_type: qwen-audio
回车 198
<|im_start|> 151644
<|im_end|> 151645
<audio> 155163
</audio>155164
audio填充 151851
[INFO:swift] system: You are a helpful assistant.
[INFO:swift] args.lazy_tokenize: True
[INFO:swift] [INPUT_IDS] [151644, 8948, 198, 2610, 525, 264, 10950, 17847, 13, 151645, 198, 151644, 872, 198, 14755, 220, 16, 25, 155163, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 155164, 198, 105761, 46670, 108704, 151645, 198, 151644, 77091, 198, 106805, 104021, 102842, 100715, 101042, 151645]
[INFO:swift] [INPUT] <|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
Audio 1:<audio>/root/.cache/modelscope/hub/datasets/speech_asr/speech_asr_aishell1_trainsets/master/data_files/extracted/bcd95ebccbcf812b344ba13b6ca59a26cb8c41370f482f27da9aeedc5360e907/speech_asr_aishell_devsets/wav/dev/S0724/BAC009S0724W0121.wav</audio>
语音转文本<|im_end|>
<|im_start|>assistant
广州市房地产中介协会分析<|im_end|>
[INFO:swift] [LABLES_IDS] [-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, 106805, 104021, 102842, 100715, 101042, 151645]
[INFO:swift] [LABLES] [-100 * 136]广州市房地产中介协会分析<|im_end|>
打印数据: td0, tkwargs0 = template.encode(train_dataset[0])
print_example(td0, tokenizer, tkwargs0)
官方可用的数据由内部函数处理为指定格式
MsDataset.load处理完了是如下格式:
[INFO:swift] {'Audio:FILE': '/root/.cache/modelscope/hub/datasets/speech_asr/speech_asr_aishell1_trainsets/master/data_files/extracted/bcd95ebccbcf812b344ba13b6ca59a26cb8c41370f482f27da9aeedc5360e907/speech_asr_aishell_devsets/wav/dev/S0724/BAC009S0724W0121.wav', 'Text:LABEL': '广 州 市 房 地 产 中 介 协 会 分 析 '}
get_dataset_from_repo函数处理完了就是query/response对数据,主要是这个函数_preprocess_aishell1_dataset做的工作。
训练好的模型测试
import os
from swift.tuners import Swift
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import (
get_model_tokenizer, get_template, inference, ModelType, get_default_template_type,
)
from swift.utils import seed_everything
model_type = ModelType.qwen_audio_chat
template_type = get_default_template_type(model_type)
print(f'template_type: {template_type}') # template_type: qwen
model, tokenizer = get_model_tokenizer(model_type, model_kwargs={'device_map': 'auto'})
print(model)
lora_ckpt_dir="output/qwen-audio-chat/v6-20240402-032912/checkpoint-27500"
model = Swift.from_pretrained(model, lora_ckpt_dir, inference_mode=True)
template = get_template(template_type, tokenizer)
seed_everything(42)
# 读取wav.scp文件
wav_scp_file = 'data/wav.scp.test.10'
output_dict = {}
with open(wav_scp_file, 'r') as f:
for line in f:
utt, wav_path = line.strip().split()
query = tokenizer.from_list_format([
{'audio': wav_path},
{'text': '语音转文本'},
])
response, history = inference(model, template, query)
print(f'query: {query}')
print(f'response: {response}')
output_dict[utt] = response
# 将结果写入到文件中
output_file = 'output.txt'
with open(output_file, 'w') as f:
for utt, response in output_dict.items():
f.write(f'{utt} {response}\n')
原文地址:https://blog.csdn.net/weixin_43870390/article/details/137586929
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!