爬虫学习笔记-get请求获取豆瓣电影排名多页数据★★★★★
1. 导入爬虫需要使用的包
import urllib.request
import urllib.parse
2.创建请求函数
def create_request(page):
# 定义不变的url部分
base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
# 根据规律定义data拼接url
data = { 'start':(page-1)*20, 'limit':20, }
#将字典数据编码为字符串
data = urllib.parse.urlencode(data)
url = base_url + data
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36" }
# 请求对象定制
request = urllib.request.Request(url=url,headers=headers)
return request
3.创建获取内容函数
def get_content(request):
# 向服务器发送请求,接收获取响应
response = urllib.request.urlopen(request)
# 将字节形式的内容转码
content = response.read().decode('utf-8') return content
4.创建下载函数
def download(page,content):
fp = open('movie_'+ str(page) + '.json','w',encoding='utf-8')
fp.write(content)
5. 程序入口
if __name__ == '__main__':
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page,end_page+1):
request = create_request(page)
content = get_content(request)
download(page,content)
6.展示
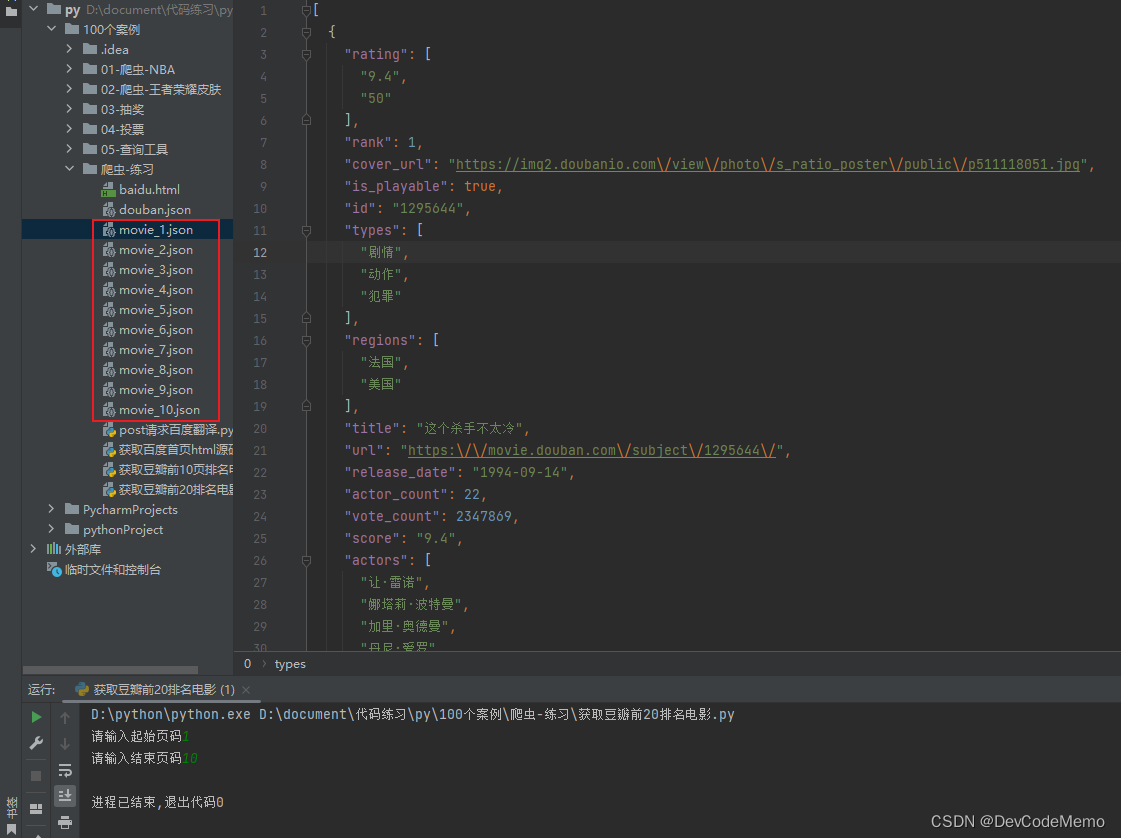
7.源码
import urllib.request
import urllib.parse
# 创建请求函数
def create_request(page):
# 源网址
# 第一页https: // movie.douban.com / j / chart / top_list?type = 5 & interval_id = 100 % 3A90 & action = & start = 0 & limit = 20
# 第二页https: // movie.douban.com / j / chart / top_list?type = 5 & interval_id = 100 % 3A90 & action = & start = 20 & limit = 20
# 第三页https: // movie.douban.com / j / chart / top_list?type = 5 & interval_id = 100 % 3A90 & action = & start = 40 & limit = 20
# 定义不变的url部分
base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
# 根据规律定义data拼接url
data = {
'start':(page-1)*20,
'limit':20,
}
#将字典数据编码为字符串
data = urllib.parse.urlencode(data)
url = base_url + data
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
# 请求对象定制
request = urllib.request.Request(url=url,headers=headers)
return request
# 创建获取内容函数
def get_content(request):
# 向服务器发送请求,接收获取响应
response = urllib.request.urlopen(request)
# 将字节形式的内容转码
content = response.read().decode('utf-8')
return content
# 创建下载函数
def download(page,content):
fp = open('movie_'+ str(page) + '.json','w',encoding='utf-8')
fp.write(content)
# 主程序入口
if __name__ == '__main__':
# 手动输入要爬取的起始页码
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
# 循环遍历每一页数据
for page in range(start_page,end_page+1):
# 调用接收函数
request = create_request(page)
content = get_content(request)
download(page,content)原文地址:https://blog.csdn.net/2301_77321248/article/details/135817030
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!