pandas之重复数据的查看、删除和提取(后附数据网盘链接)
数据预览:
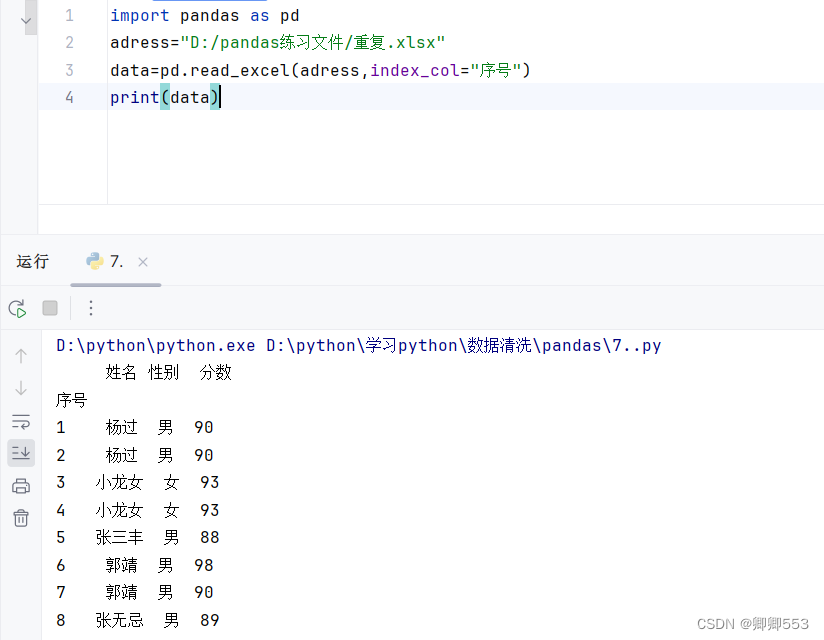
一、 查看value_counts()
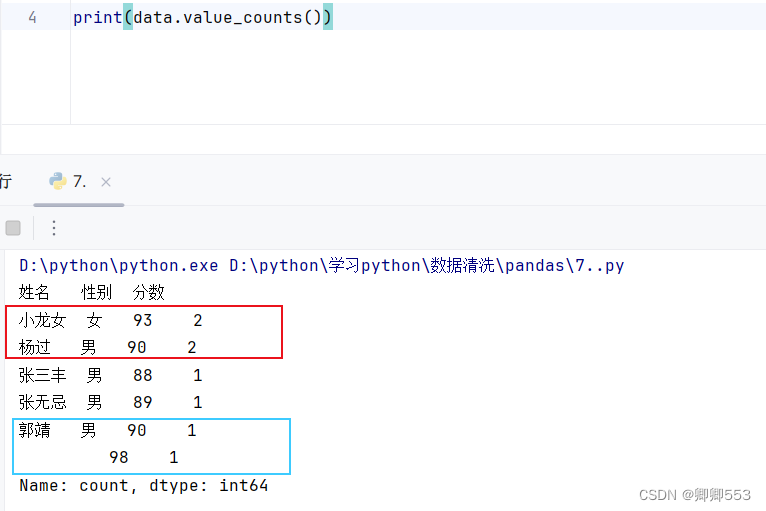
这一函数能够查看每一数据出现了几次,但是用data.value_counts()这一方法时,只有一行数据全都一样才算做重复行,如下图中的郭靖分数不一样的话它没有计入是重复行,要想以名字作为重复判断依据的话,可以用data['姓名'].value_counts()
data.value_counts()
二、删除重复 drop_duplicates()
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
1.参数介绍
(1)subset
用来指定特定的列,默认是所有列
(2)keep
指定处理重复值的方法:
A.first:保留第一次出现的值
B.last:保留最后一次出现的值
C.False:删除所有重复值,留下没有出现过重复的
(3)inplace
是直接在原来数据上修改还是保留一个副本
2.使用方法
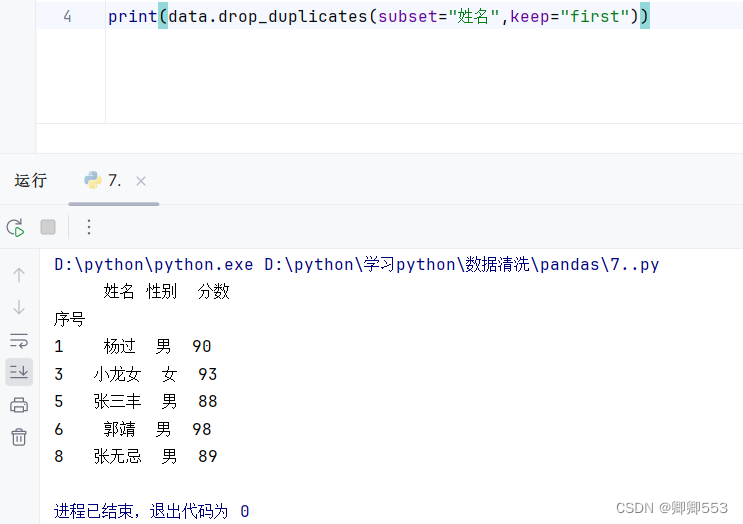
比如我想删除名字重复的整行数据,保留第一次出现的数据
data.drop_duplicates(subset="姓名",keep="first")
三、提取重复
1.参数介绍
DataFrame.duplicated(subset=None, keep='first')
本函数的参数同drop_duplicates()是一样的,这里不再赘述
2.使用方法
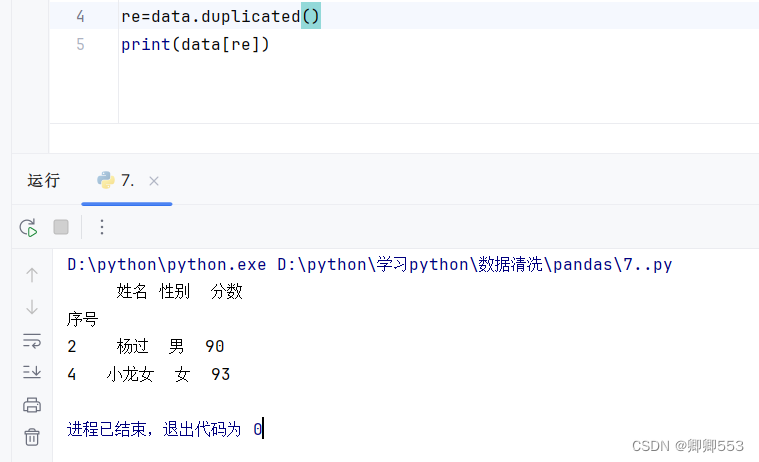
比如我想提取各列数据都一样的重复数据,由一中我们可知这样的数据有杨过和小龙女两人
re=data.duplicated() print(data[re])
四、源数据网盘链接
链接:https://pan.baidu.com/s/1FhJqeJM51ufSfcoPQJzwtg
提取码:1234
原文地址:https://blog.csdn.net/2302_80061155/article/details/135587133
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!