MySQL事务与事务原理
目录
事务
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。
start transaction; -- 开启事务 或者 begin 开启
...
rollback/commit; -- 回滚(全部失败)/提交(全部成功)事务的四大特性ACID
- 原子性:事务中的操作要么全部成功,要么全部失败
- 一致性:事务必须使数据库从一个一致性状态变换到另外一个一致性状态
- 隔离性:多个并发事务之间要相互隔离
- 持久性:持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的
事务日志用于保存对数据的更新操作
事务隔离级别
事务隔离级别分为读未提交、读已提交、可重复读、串行化四个级别。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 读未提交 | 可能出现 | 可能出现 | 可能出现 |
| 读已提交 | 不会出现 | 可能出现 | 可能出现 |
| 可重复读 | 不会出现 | 不会出现 | 可能出现 |
| 串行化 | 不会出现 | 不会出现 | 不会出现 |
- 脏读:指的是读到了其他事务未提交的数据,未提交意味着这些数据可能会回滚,也就是可能最终不会存到数据库中,也就是不存在的数据。读到了不一定最终存在的数据,这就是脏读。
- 可重复读:指的是在一个事务内,最开始读到的数据和事务结束前的任意时刻读到的同一批数据都是一致的。通常针对数据更新(修改或删除)操作。
- 不可重复读:对比可重复读,不可重复读指的是在同一事务内,不同的时刻读到的同一批数据可能是不一样的,可能会受到其他事务的影响,比如其他事务改了这批数据并提交了。通常针对数据更新(修改或删除)操作。
- 幻读:幻读是针对数据插入操作来说的。幻读官方定义,在一个事务中,前后两次使用了相同的查询语句,但是第二次查询发现了第一次查询时不存在的数据(中间没有插入操作),这种查询到了此前未存在的数据就是幻读。
个人看法:按照可重复读隔离级别的定义,在一个事务中,相同的DQL语句查询出来的结果应该保持一致,而可重复读的隔离级别解决不了幻读问题。
然而按照官方的定义,在可重复读的隔离级别下是不应该出现所谓幻读的。
另一种流传较为广泛的定义是:假设事务A开启后,还未提交,此时事务B插入了新的数据,并且提交,而这时,事务A也想插入事务B刚刚插入的数据,但是却插不进去(主键唯一),然而查询却查不到这条数据(这是因为可重复读的隔离级别),让用户感觉很魔幻,感觉出现了幻觉,这就叫幻读。
至于怎么理解,只能见仁见智。
事务原理
在解释原理之前,有必要先了解一下存储引擎。
存储引擎
存储引擎是数据库的核心组件,决定了数据的存储方式、索引构建、并发控制、事务处理、恢复机制及性能优化等关键特性。事实上,不是所有的存储引擎都支持事务,而支持事务的存储引擎,其事务原理也不相同。
常用的存储引擎主要有InnoDB、MyISAM、Memory,各自特点如下:
| 存储引擎 | 事务 | 锁类型 | 外键 | 索引 | 持久化 | 使用场景 |
| InnoDB | 支持 | 行锁 | 支持 | B+树索引 | 可持久化 | 大多数场景 |
| MyISAM | 不支持 | 表锁 | 不支持 | B+树索引 | 可持久化 | 性能优先级 > 数据安全的场景 (例如查询评论) |
| Memory | 不支持 | 表锁 | 不支持 | B+树索引和Hash索引 | 不可持久化 | 适用于临时存储,性能高的场景 (作为缓存) |
自从MySQL5.5版本开始,默认存储引擎使用InnoDB。因此这里的事务原理是针对InnoDB引擎而言。
四大特性的保证
- 原子性
- 通过回滚日志(undolog)保证原子性(undolog日志不止用于回滚操作,在MVCC中也发挥重要作用)。
- 在事务开始时, InnoDB 会将事务涉及的所有修改操作记录到 undolog 中(逻辑记录,比如要删除一条数据,可能日志中记录的就是新增一条数据)。如果事务执行出错,就可以通过 undolog 实现回滚机制,从而保证了事务的原子性。
- 一致性
- 预提交校验(Pre-commit Checks):在事务提交前,MySQL会对事务执行的结果进行校验,确保其符合数据库定义的完整性约束条件。如果违反了约束,则事务会被回滚。
- 另外需要开发人员通过设置触发器和约束、设定合适的隔离级别以及在业务中处理。
- 隔离性
- 通过锁机制和MVCC共同实现。MVCC机制实现读已提交和可重复读,间隙锁和临键锁用来解决幻读问题。
- 在可重复读隔离级别下,InnoDB不仅锁定查询行,同时会锁定上一行到查询行以及查询行到下一行的间隙,以防止其他事务在此间隙插入新行导致幻读(这里的幻读应该按照官方定义理解)。
举个例子:
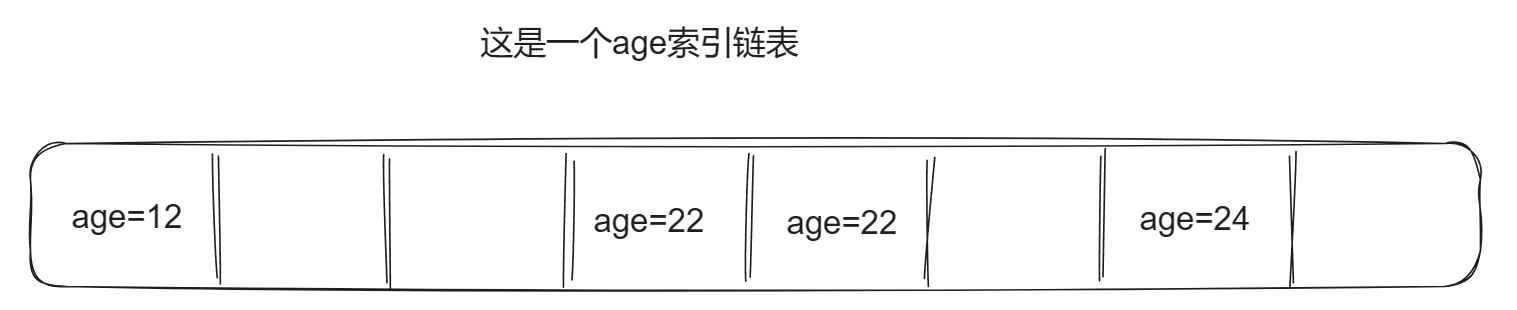
假如有这样一组数据:
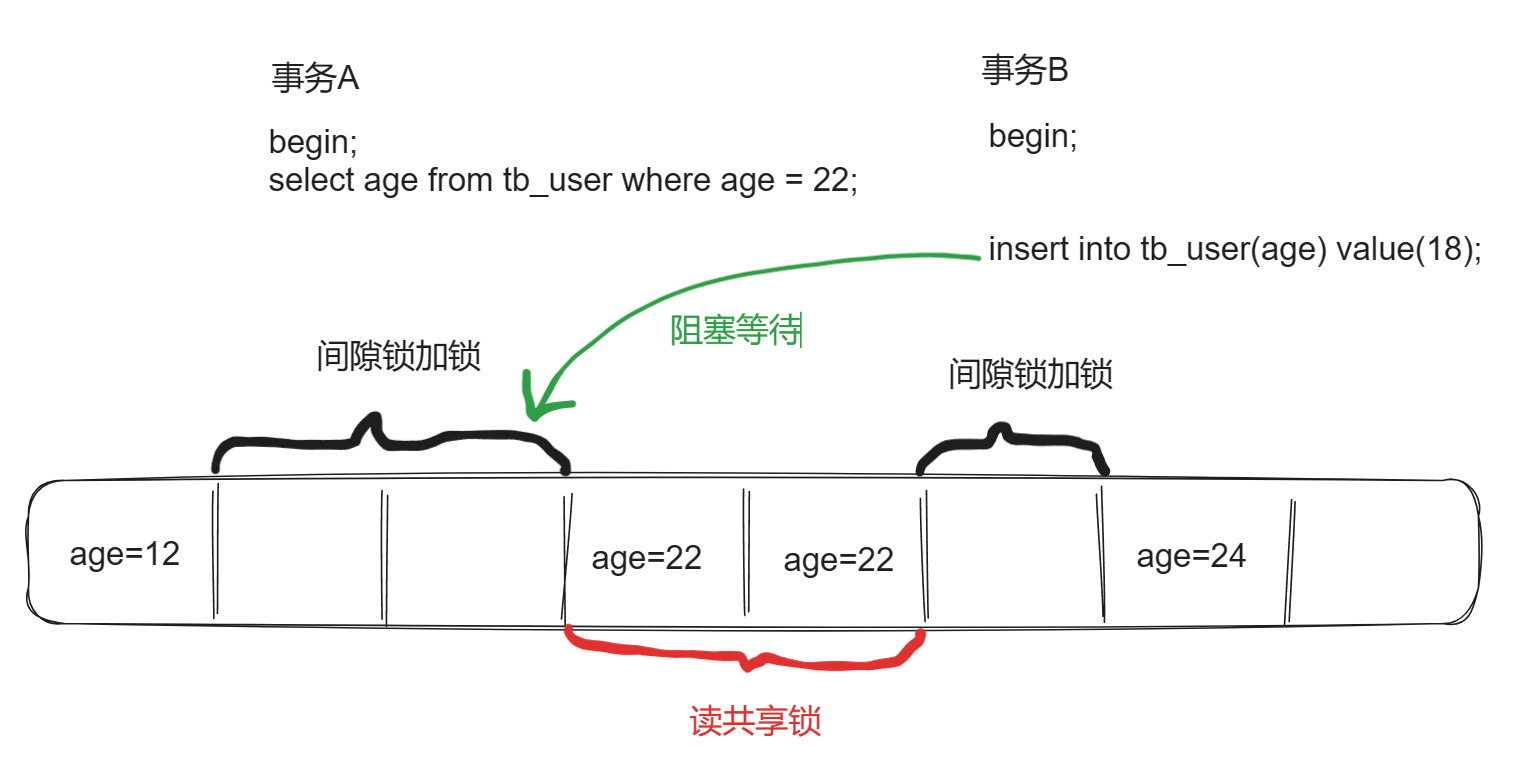
我要查询age=22的数据,此时age=12的数据到age=24的数据之间都会锁定,共享锁锁定age=22的数据,间隙锁锁定12-22和22-24的数据(不包括12和24)。
此时其他事务想要插入age=18,由于间隙锁的存在,插入操作被阻塞,直到事务提交或回滚会才会执行。
- 持久性
- 通过重做日志 (redolog) 保证持久性。
- 缓冲池往磁盘中的刷新是间歇性的(减少磁盘IO以提升性能),如果刷新失败持久性就会失效。而为了保证性能,又不好每次都往磁盘中写(写操作是相对随机的,性能较低),于是把操作写入 redolog 日志,从 redolog 中往磁盘中同步( redolog 的写入是顺序写入的,效率很高)。
MVCC
MVCC全称是多版本并发控制 (Multi-Version Concurrency Control),只有在InnoDB引擎下存在。MVCC机制的作用其实就是避免同一个数据在不同事务之间的竞争,提高系统的并发性能。
特点:
- 允许多个版本同时存在,并发执行。
- 读操作不依赖锁机制,性能高。
- 只在读已提交和可重复读的事务隔离级别下工作。
使用MVCC可以避免读写并发执行时的阻塞,优化了MySQL的并发性能。
MVCC中,读操作是基于"快照"(ReadView) 实现的,可以理解为创建了一个该时刻数据库中数据的副本,读操作是读取的这个副本而非数据库。
事务链
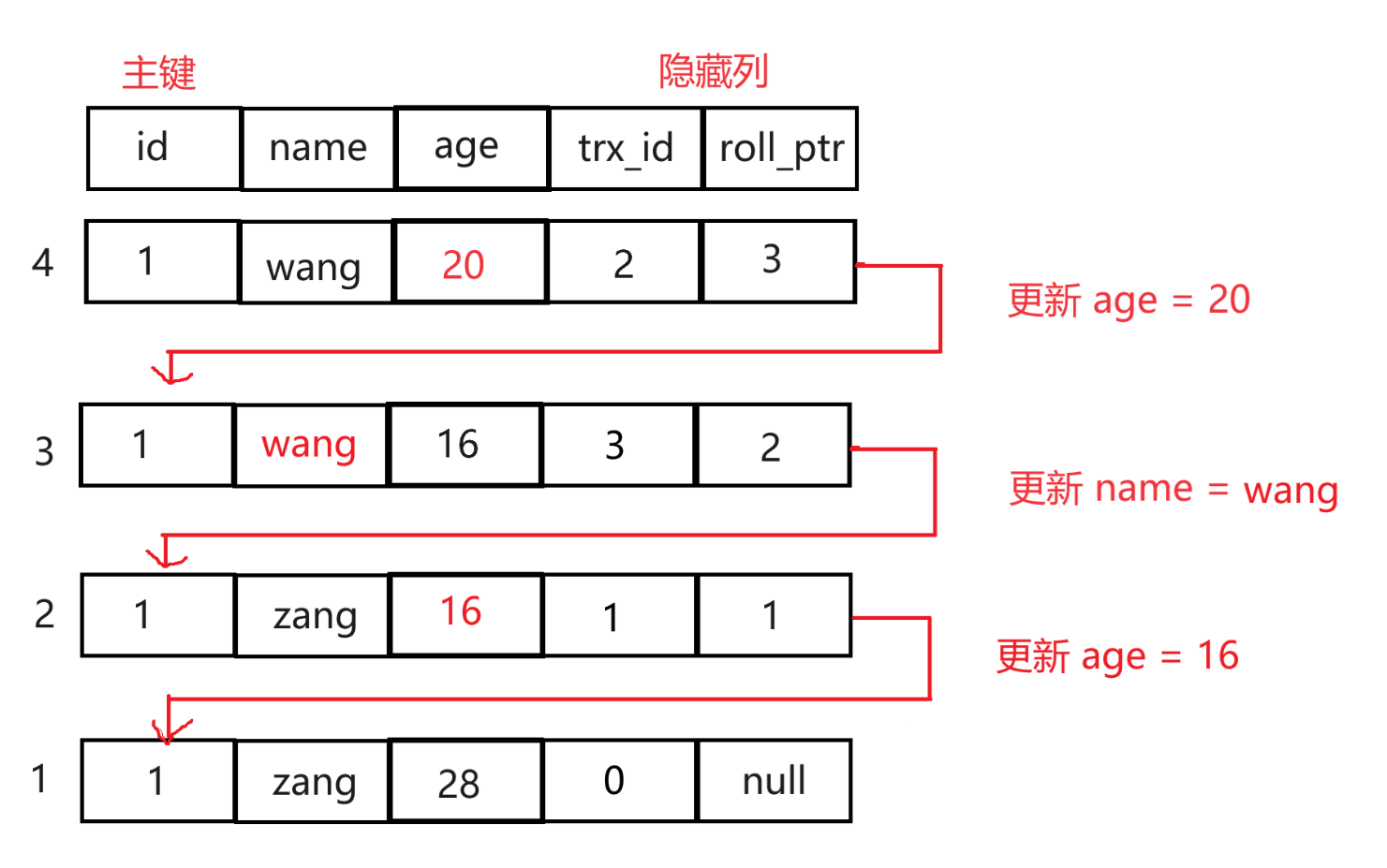
InnoDB引擎中,每张表中包含一些隐藏列:
- trx_id: 事务Id,每当事务对某行数据进行修改时,都会把该事务id赋值给 trx_id,用于记录当前修改操作;
- roll_pointer: 回滚指针,指向undolog中的某个位置,用于记录上一个版本的数据状态,方便查询历史版本或回滚。
- db_row_id: 对于没有显式主键的表,InnoDB会自动为其生成一个隐藏的行ID列,作为内部的唯一标识符。
每次对事物中某条数据进行修改时,都会产生一条undolog日志(如果是 insert 操作则不产生),同时roll_pointer会指向这块空间,以便于回滚。
而指针会把多条undolog日志串联起来,形成事务链:

ReadView
InnoDB的 ReadView 就是通过这种版本控制的手段实现读已提交(RC)和可重复读(RR)的,在RC隔离级别下,每次查询都会生成一个ReadView,然后根据一定的规则判断哪些事务可见,那些不可见。
ReadView包含四个核心字段:
- 创建ReadView的事务的id:creator_trx_id;
- 最早的活跃事务(最早开启的还未提交的事务)id:min_trx_id;
- 下一次开启事务预生成的事务id:max_trx_id;
- 所有的活跃事务id列表:m_ids。
假设当前所处事务的id为cur_trx_id,则规则如下:
- cur_trx_id == creator_trx_id (说明修改操作位于当前事务)可以被访问;
- cur_trx_id < min_trx_id (说明当前事务已提交)可以被访问;
- cur_trx_id >= max_trx_id(当前事务在查询之后开启)不可以被访问;
- min_trx_id <= cur_trx_id < max_trx_id 且 cur_trx_id 不在 trx_ids 中(说明当前事务已提交)可以被访问;
举例,对于这样一组事务:

此时事务链为:
- 第一次生成ReadView的属性为:create_trx_id = 4, min_trx_id = 2, max_trx_id = 5, trx_ids = [2, 3, 4]
- 首先是cur_trx_id = 2,显然四个条件都不满足,沿着事务链往下走,cur_trx_id = 3,仍然不满足;
- 继续,cur_trx_id = 1,满足第二个条件 cur_trx_id < min_trx_id,可以读取到该版本,即返回的数据为:id = 1, name = 'zang', age = 16
对比前面的图会发现,读取到的数据就是已提交的数据,因此就实现了读已提交;
在RC隔离级别下,每次查询都会生成一个新的ReadView,第二次查询生成的ReadView属性为:create_trx_id = 4, min_trx_id = 2, max_trx_id = 5, trx_ids = [2, 4]
沿着事务链最后读取到的数据为:id = 1, name = 'wang', age = 16。
而在RR隔离级别下,只有在第一次查询才生成ReadView,后续在同一事务中的相同查询语句直接引用已有的ReadView,从而实现可重复读机制。
注意:如果开启事务A后,事务B修改了数据并且提交,此时在事务A中查询,是可以查询到事务B提交的数据的,但只有第一次查询是读已提交(此后即使有其他的事务修改数据并且提交,在事务A中都是查不到的)。
原文地址:https://blog.csdn.net/weixin_71020872/article/details/137735238
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!