大语言模型赋能病理AI,自动从报告文本中分类TNM分期|顶刊精析·24-10-17
小罗碎碎念
这篇文章介绍了一种名为BB-TEN(Big Bird – TNM staging Extracted from Notes)的方法,它能够自动从病理报告文本中分类TNM(肿瘤大小、区域淋巴结受累和远处转移)分期。
今天分享的这篇文章于2024-10-16发表于Nature Communications,目前IF=14.7。

| 姓名 | 单位 | 单位中文译文 |
|---|---|---|
| Jenna Kefeli | Department of Systems Biology, Columbia University | 哥伦比亚大学系统生物学系 |
| Nicholas P. Tatonetti | Department of Biomedical Informatics, Columbia University | 哥伦比亚大学生物医学信息学系 |
这种方法基于BERT模型,使用大约7000名患者的公开病理报告进行训练,涵盖了23种癌症类型。
研究者们探索了不同模型类型、输入大小、参数和模型架构,最终发现他们的模型能够超越单纯的术语提取,通过上下文推断TNM分期,即使报告文本中没有明确包含这些信息。
BB-TEN模型在外部验证中表现良好,研究者们在哥伦比亚大学医学中心的近8000份病理报告上测试了他们的模型,发现AU-ROC(Area Under the Receiver Operating Characteristic curve)值在0.815到0.942之间,表明该模型可以广泛应用于其他机构,无需额外的机构特定微调。
文章还讨论了之前的研究工作,这些工作通常集中在单一癌症类型上,使用较小的训练和测试数据集,并且依赖于单一机构的数据,没有外部验证和可证明的泛化能力。与之相比,本研究在大约7000份报告的泛癌症数据集上进行,并在近8000份外部泛癌症报告上展示了泛化能力。
此外,文章还提到了使用最新的大型语言模型(LLMs)如OpenAI的GPT4进行病理报告中的分期信息提取的尝试。这些大型模型在训练样本数量上可能要求较少,但在API访问费用或运行本地硬件要求上成本较高,可能不适合敏感的健康信息,并且可能容易产生幻觉。相比之下,研究者们展示了像BERT这样的小型变换模型,能够在资源需求更少的情况下取得更好的性能,并且不需要使用第三方API。
研究者们还强调了他们的模型在临床相关性方面的优越性,例如预测N分期的完整范围(0-3)而不是二元N分期(0-1),因为对于不同的癌症类型,不同的N值在预后、建议治疗和研究队列选择上有重大区别。此外,他们还预测了临床上可操作的M分期范围(0-1),而不是预测M作为(0-1, X)。
最后,文章讨论了BB-TEN方法的潜在应用,包括缩短临床试验患者选择和研究队列构建的周转时间,允许更多患者被常规调查以纳入临床试验和研究。自动化的分期注释可能有助于促进病理报告的自动化审查,用于临床使用和预后,以及在医学中心越来越多地数字化病理幻灯片的情况下,开发结合图像和文本的多模态模型。
一、绪论
癌症分期是重要的诊断和预后临床属性,常用于识别临床试验招募和研究队列构建的患者。
尽管在电子健康记录中并不常规捕获分期信息,但可以在患者病理报告中找到。肿瘤登记处负责从临床笔记和病理报告中手动识别分期,从诊断到提取可能需要长达6个月的时间,此时可能已经错过了临床试验或其他治疗的机会[1,2]。
癌症登记专家的短缺表明,这一时间可能会变得更长[3]。在本研究中,作者提出了BB-TEN:Big Bird—TNM分期Extracted from Notes,这是一种基于Transformer的方法,用于从23种癌症类型的病理报告文本中自动分类TNM分期。
Transformer方法已应用于其他临床文本[4],但尚未广泛应用于病理报告。作者证明了BB-TEN可推广至独立机构,表明其他机构可以使用作者的方法进行现成使用。
癌症分期的提取一直是一个持续关注的研究方向。
先前的研究集中于单一癌症类型[5-8],使用了较小规模的训练[5,6,9]或测试[5,6,9,10]数据集(<1000份报告),并且依赖于单机构数据,没有外部验证,也没有证明其普适性[6,10]。
相比之下,作者的工作最初是在一个大约7000份报告的泛癌症数据集上进行的,然后以可泛化的方式扩展到一个近8000份报告的外部泛癌症数据集。一些研究需要除了病理报告文本之外的额外数据作为模型输入[5,6,10,11]。
为了便于使用,BB-TEN只需要病理报告文本作为输入,不需要包含任何其他患者数据类型。
在方法上,两项研究采用了较旧的NLP方法(正则表达式和定制规则方法)[6,10],一项利用了传统机器学习方法[5],另一项使用了混合Transformer嵌入和深度学习模型[11]。
相比之下,作者的方法使用了一种最近开发的可处理长输入的Transformer,直接处理临床长度的病理报告,并在模型训练中完全融入标记之间的长距离依赖关系。此外,这些研究尚未将其模型公开,而作者正在发布训练好的TNM模型,供其他机构直接使用。
最后,已经探讨了使用像OpenAI的GPT4这样的最新生成式大型语言模型(LLMs)进行基于提示的病理报告分期信息提取[7-9,12]。这些大型模型的优势在于,它们可能需要更少的训练样本。然而,成本很高,无论是API访问费用还是运行本地的硬件要求,它们的使用可能不适合敏感的健康信息,并且可能容易出现幻觉[13]。
相比之下,作者表明,像BERT这样的小型Transformer模型,在资源更少且无需使用第三方API的情况下,实现了更优越的性能。
大多数先前的工作将患者分类到不包括所有临床价值的广泛TNM类别[5,6,11],而在这项研究中,作者将报告具体分类到具有临床相关性的TNM类别。
每个可能的类别值都是根据当前的 clinical 使用定制的,并为下游效用优化。例如,作者预测完整的N(0–3)范围,而不是二进制的N(0–1),因为对于不同癌症类型的不同N值,在预后、建议治疗和研究队列选择上有重大区别。
此外,细化N是一个更具挑战性的分类任务。其他研究[5,6,10,11]在预测二进制的N(0–1)时实现了高AU-ROC,作者在初步工作中也是如此;作者最终选择(0–3),因为(0–1)是对分期的粗略近似,对于临床有用的最终模型来说不够充分。
同样,为了优先考虑临床相关性,作者预测了完整的具有临床行动意义的M范围,即(0–1),而不是资源[11]预测的M(0–1,X)。在初步工作中,作者为M(0–1,X)实现了高AU-ROC;然而,作者移除了X作为可能的预测值,以遵循AJCC指南,该指南要求从病理分期词汇中移除X,因为X是一个不具有临床行动意义的类别。

总体而言,作者的预测类别和模型输出在当前的医学词汇背景下更具临床相关性,并且比Preston, S. et al.[11]更符合AJCC指南。
在这项研究中,作者利用自然语言处理的最新进展,直接从病理报告文本中分类癌症分期[14]。
作者特别使用了一种新的BERT[15,16]变体,该变体的输入容量比先前版本更大,并显示作者的模型性能优于标准BERT模型。
作者还与一种最先进的LLM,Llama 3进行了比较,并显示BERT模型在三项任务中的两项性能优于基础Llama 3模型,并且优于微调后的Llama 3模型,训练时间更快,计算资源更少。
据作者所知,这是首次将高输入容量的LLMs应用于病理报告文本,用于任何预测目标的分类,而无需进一步修改。这一创新不仅提高了模型的实用性,而且为从病理报告中提取关键临床信息提供了新的可能性。
本研究的方法论和结果具有几个显著特点。
首先,BB-TEN模型的设计考虑了实际临床应用的需求,通过仅使用病理报告文本作为输入,简化了数据准备过程,提高了模型的易用性。其次,模型在处理长文本输入方面的能力,使其能够直接处理完整的病理报告,这在以往的研究中是难以实现的。此外,本研究通过在多个癌症类型和大量数据集上的验证,证明了模型的泛化能力,这对于推广到不同医疗机构的实际应用至关重要。
在性能方面,BB-TEN模型在预测TNM分期具体类别上展现了优越的性能,特别是在细化N和M分类上,相较于以往的研究,作者的模型提供了更精细、更具临床指导意义的分期预测。这种细粒度的预测有助于更准确地评估患者预后、制定治疗计划,并提高临床试验和研究队列构建的准确性。
此外,本研究还关注了成本和资源问题。与大型语言模型相比,BB-TEN模型在训练时间和计算资源需求上更为高效,这使得其在临床环境中的部署更加可行。同时,作者公开了训练好的TNM模型,这不仅促进了研究成果的共享,也为其他研究者和医疗机构提供了直接应用的可能性。
二、结果
本研究采取两阶段方法进行:(1)利用公开可获得的病理报告训练模型,随后(2)将训练好的模型应用于一组独立的报告上,以验证模型的泛化能力(图1A)。
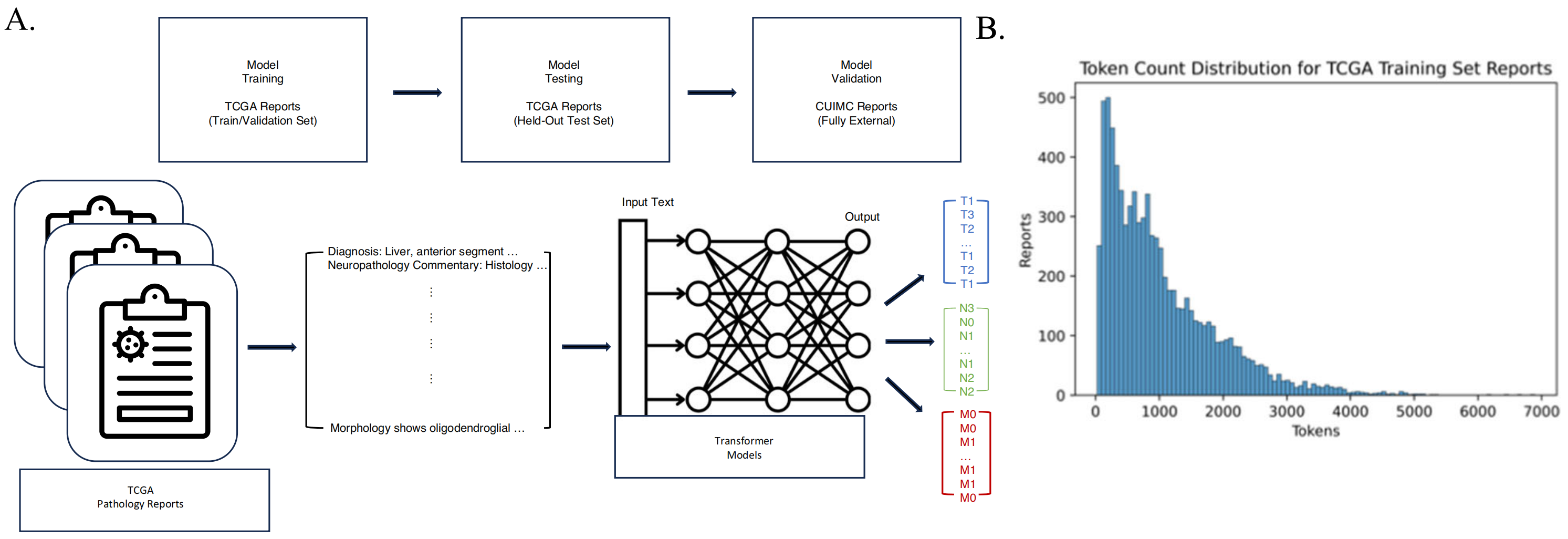
癌症分期包括三个要素:肿瘤大小(T)、区域淋巴结受累(N)和远处转移(M)。作者的预测任务是将报告分类到TNM分期类别中,每个变量分别训练一个模型。
首先,作者从癌症基因组图谱(TCGA)中选取了9523份病理报告[14,17]。
TCGA元数据中TNM注释的可用性各异:6887份报告记录了已知的肿瘤大小(T),5678份报告记录了已知的区域淋巴结受累(N),4608份报告记录了已知的转移(M)。所有TNM值均基于病理学家对相关组织学切片的审查。
已知T和N值的病人涵盖了23种不同的癌症类型,而已知M状态的病人对应21种癌症类型。由于TCGA数据集中包含了大量贡献的病理学家和机构(图S1),作者观察到即使是在单一癌症类型子集中,报告的结构、组成和术语也存在很大差异。
数据集的复杂性和规模表明,使用大型语言模型(LLM)是合适的,并且一旦训练完成,这样的模型应当具有泛化能力。
为此,作者针对提出的分类任务测试了三种预训练的LLM[16,18,19](方法部分)。
其中两种模型是在大量公开可获得的临床笔记上预训练的。第一种,ClinicalBERT(CB)[18],在临床自然语言处理领域被广泛使用,但其训练和应用受到最大输入容量(每个文档512个令牌)的限制。
实际上,作者发现超过66%的TCGA报告长度超过512个令牌(图1B,表S1)。
第二种模型,Clinical-BigBird(CBB)[16],最近发布,其文档输入能力大幅提高(每个文档4096个令牌),模型参数相应减少。第三种模型是作者评估的Meta最新发布的LLM,Llama 3,其在常见基准测试上具有最先进的性能[21]。作者探索了基础模型(零样本)和微调后的版本。
由于基于TNM状态的患者训练集大小不同,分类被划分为单独的任务。
每个分类目标根据标准临床用途分配不同的整数值范围:T值范围为[1, 2, 3, 4],N值范围为[0, 1, 2, 3],M值为二进制,[0, 1]。
作者将这些范围表示为T14,N03和M01(图1C)。

作者将TCGA患者分为训练集、验证集和保留的测试集。
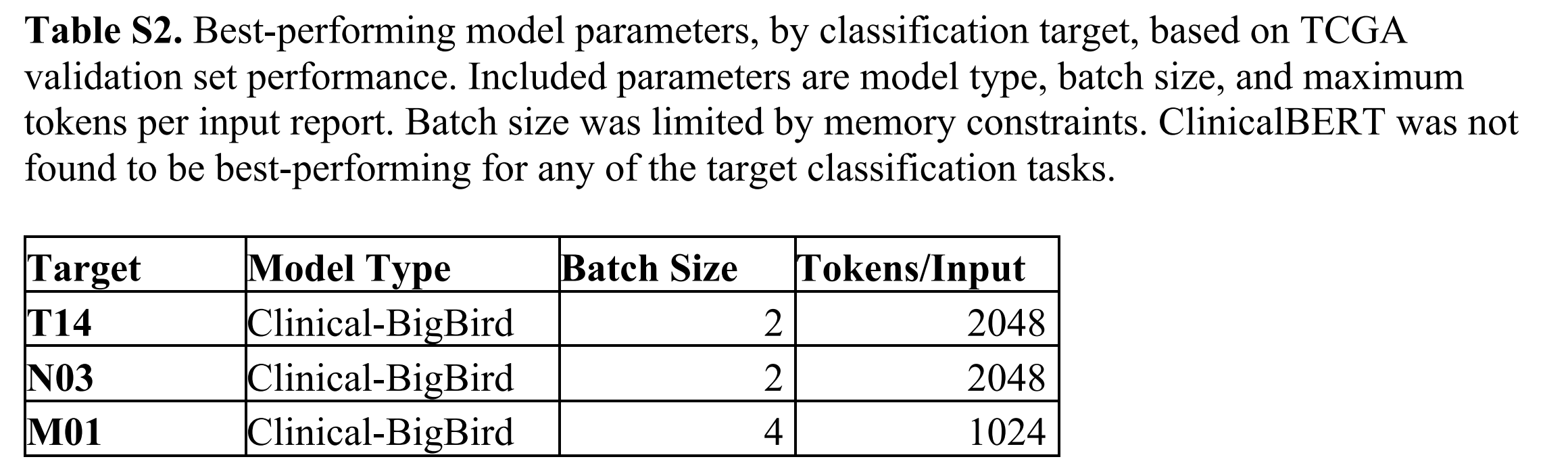
作者根据验证集优化为每个目标选择了表现最佳的BERT-based模型。在所有三个目标上表现最佳的模型类型是CBB。作者调整了输入大小,发现参数化较大的CBB模型通常表现更好——对于T14和N03目标,2048输入令牌的CBB表现最佳,而对于M01目标,则是1024输入令牌的CBB(表S2)。
验证集性能范围为0.82–0.96 AU-ROC。然后作者在TCGA保留的测试集上评估了最佳模型的性能,AU-ROC范围为0.75–0.95(图S2和3)。TCGA测试集与每个目标的训练数据集完全独立。
为了比较,作者重复了此分析以评估Llama 3的性能。
作者发现基础模型在T14、N03和M01上的F1得分分别为0.70、0.84和0.81。然后作者使用与BERT-based模型相同的实验设置对Llama 3进行了微调,模型在T14、N03和M01上的F1得分分别为0.78、0.88和0.92。
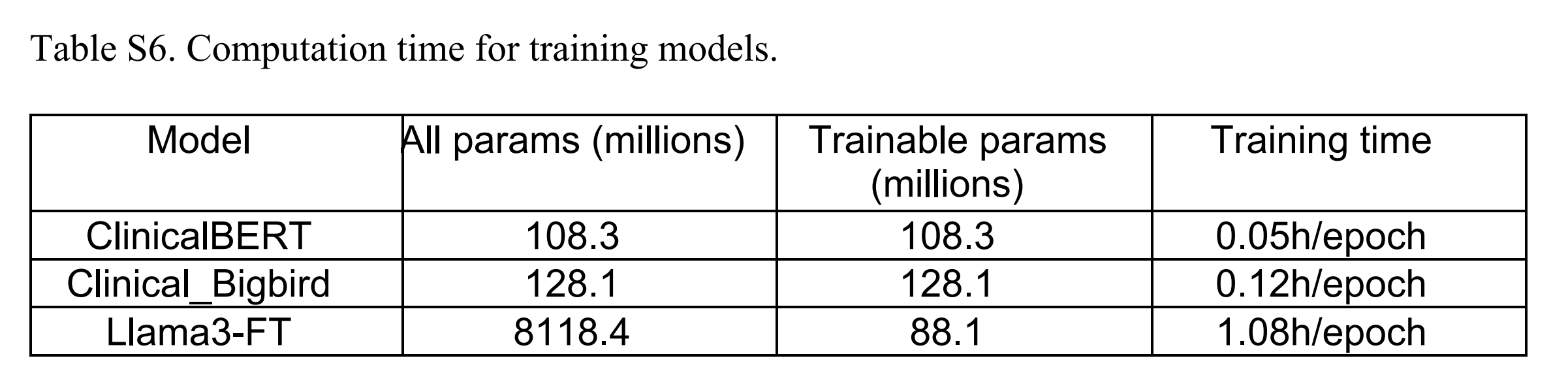
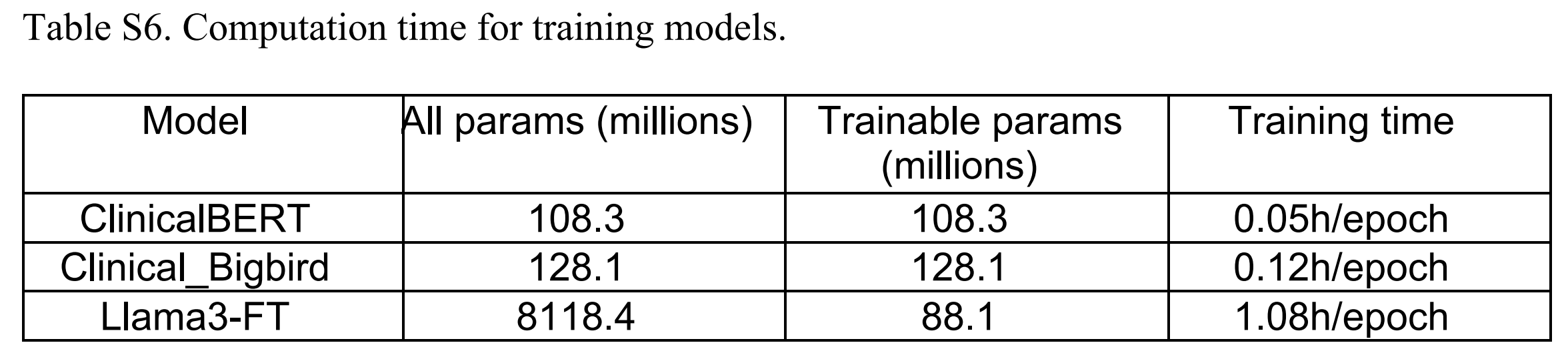
BB-TEN在所有三个分类任务上都优于基础Llama 3模型,并且在T14和M01上优于微调后的Llama 3(Llama3-FT)模型。作者还进行了运行时间分析,发现CB、BB-TEN(CBB)和Llama3-FT训练一个周期的时间分别为3分钟、7.2分钟和64.8分钟(表S6)。
作者进一步在独立的一组病理报告上评估了作者表现最佳的模型。
作者从哥伦比亚大学欧文医学中心(CUIMC)选取了2010–2019年所有的病理报告,并根据报告日期和诊断与肿瘤登记处的TNM注释进行匹配(见“方法”部分)。
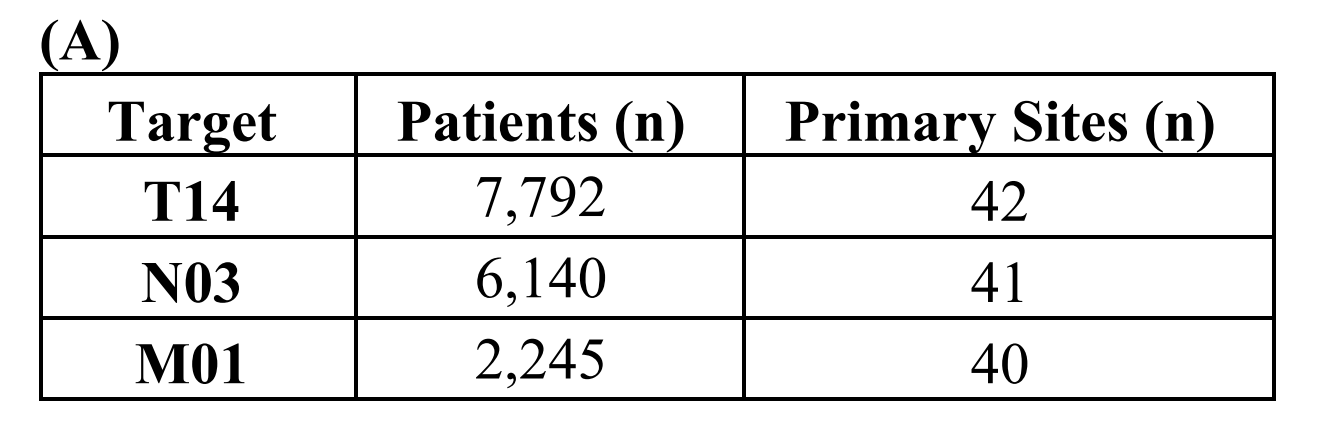
与TCGA数据集一样,患者TNM注释的覆盖率不均:7792名患者对应已知的T状态,6140名患者对应已知的N状态,2245名患者对应已知的M状态(表S3)。
T状态的患者涵盖了42个主要癌症部位;N状态的患者涵盖了41个主要癌症部位,
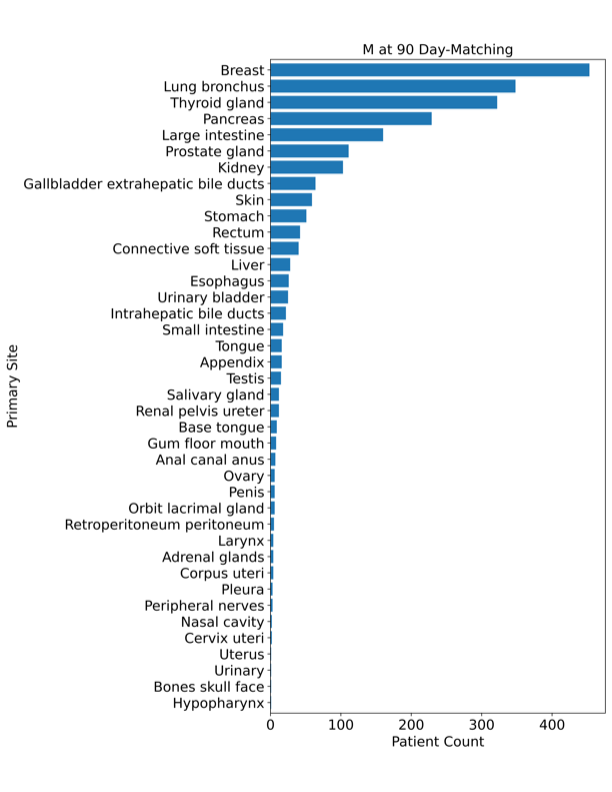
M状态的患者涵盖了40个主要癌症部位(图S4)。
最终的模型没有在CUIMC报告上进行微调,而是直接以现成的方式应用。作者发现BB-TEN表现良好,AU-ROC范围从0.815–0.942(图2A–D)。
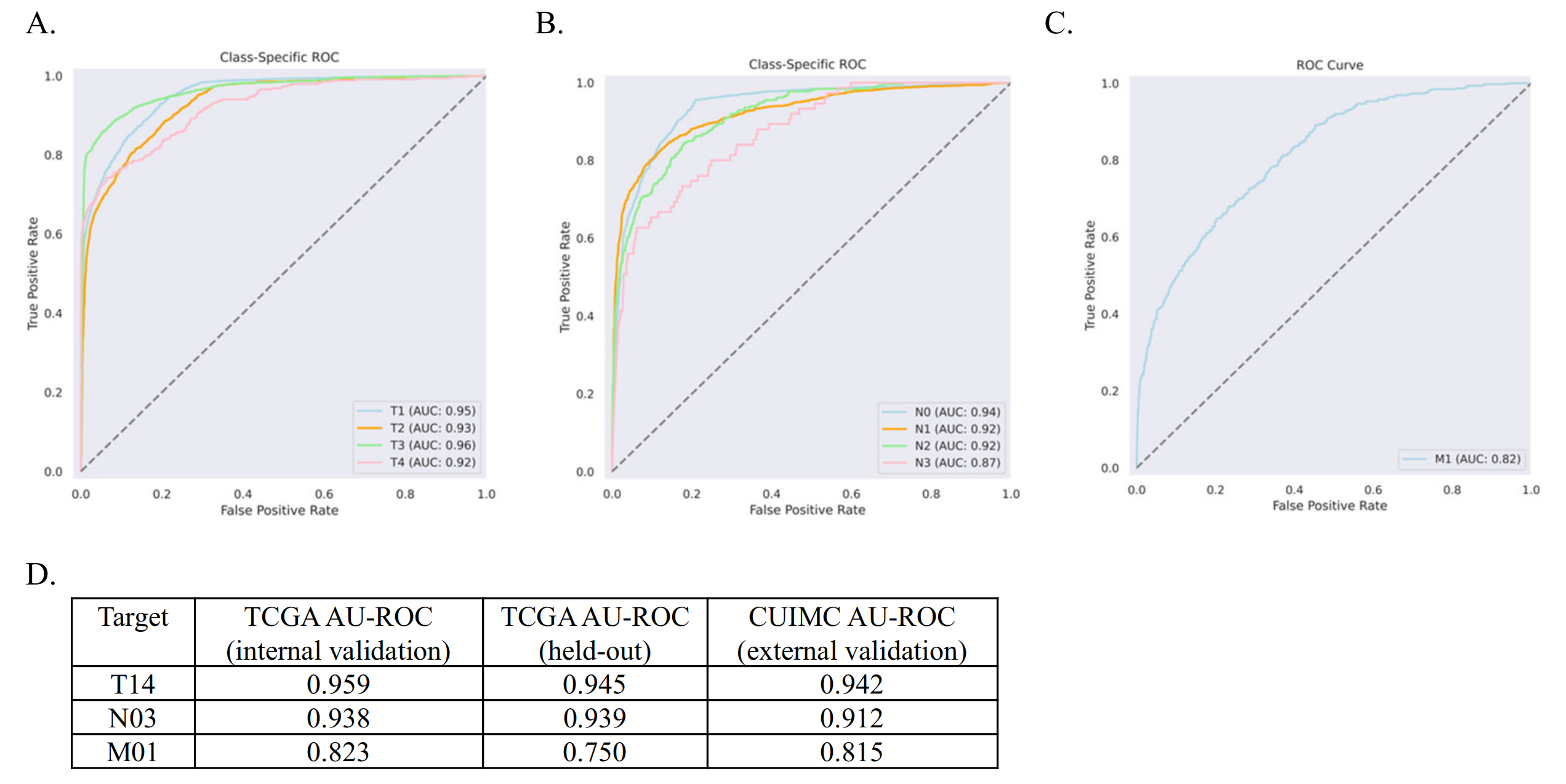
对于多类别目标T14和N03,作者发现每个类别的性能始终很高(图2A,B)。为了确定使用CBB模型类型(其复杂性和输入大小都有所增加)在应用于CUIMC数据时是否有所区别,作者比较了在TCGA验证集上确定的最佳CB模型与最佳CBB模型在N03任务上的表现。作者发现最佳CB模型的AU-ROC为0.779,而最佳CBB模型在CUIMC数据上的AU-ROC为0.912(表S4)。
最后,作者测试了包括受保护的健康信息(PHI),如姓名、出生日期、病历号和性别,对T14模型性能的影响。作者发现最佳表现模型在去除PHI后性能略有提高(AU-ROC差异为0.0001)(表S5)。鉴于性能上的微小差异,作者不认为排除PHI是使用或应用作者模型的必要要求。
三、讨论
自动化地从病理报告中分类癌症分期将缩短临床试验患者筛选和研究队列构建的周转时间。
这将使得更多的患者能够常规性地被纳入临床试验和研究研究中。自动化的分期标注可以用于促进临床使用和预后分析中的病理报告自动审查,以及开发结合图像和文本的多模态模型,特别是随着医疗中心越来越多地数字化病理切片[22]。
在本研究中,作者应用了一种最近发布的Transformer模型,其输入容量高于传统的BERT模型,以在多个独立数据集上实现一致的高预测性能。重要的是,作者已经将作者的模型公开可用。
与其他临床NLP研究不同,作者的模型是在完全去识别的病理报告上训练的,因此不需要特殊的方法,如差分隐私或联邦学习,来进行传播。此外,作者的模型是在一个高度多样化的数据集上训练的,该数据集涵盖了超过500个组织来源站点(图S1),而以往的研究通常只使用了来源种类较少的数据——例如,一项研究仅从28个站点获取数据[11]。
正如作者所展示的,TNM模型在不同机构中表现一致。
作者发现,在CUIMC报告集上的表现与在TCGA保留测试集上的表现一样好(图2D),这表明它们确实具有泛化能力。许多CUIMC报告并未包含明确的分期术语(15.3%的T14,20.3%的N03,以及94.7%的M01报告),这表明模型通过超越直接提取,从上下文中推断分期分类,展现了提高的性能。
最后,作者将作者的BERT-based模型与更先进的生成式LLMs进行了比较。具体来说,作者评估了Meta最新发布的Llama 3的性能,并发现作者的BERT-based模型表现更好且速度更快。
尽管生成式模型在广泛的NLP基准测试中提供了普遍强大的性能,但作者的结果表明,BERT-based模型可以快速且有效地针对特定分类任务进行调整。这使得这些模型特别适用于敏感的医疗保健数据,以及跨各种计算基础设施的使用。
未来的工作应该专注于在外部机构进行额外的测试,以进一步验证作者的TNM模型的泛化能力。
尽管前景看好,但作者的方法有几个显著的局限性。
首先,作者抽象了T、N和M的值,例如将T1a转换为T1。在更大的病理报告集上重新训练作者的模型将允许更详细的预测目标。其次,作者受到计算内存分配的限制,将每份报告的令牌数限制为2048。如果计算能力增加,可能会扩展到4096个令牌,以完整长度捕获更长的报告。第三,作者根据当前的AJCC[23]分期定义开发了作者的模型;如果AJCC定义有重大更新,作者的模型将需要重新训练。
此外,M01模型的整体表现不如T14和N03模型。这可能是由于TCGA训练数据中固有的几个因素:
(1)M01是一个特别不平衡的数据集,只有6.7%的报告具有M1注释(图1C),这是由于TCGA设计偏好非转移性病例
(2)许多报告并未明确包含M0或M1,与其他目标相比(95.1%的报告未包含明确的M01,而N03为66.5%,T14为35.8%)
(3)TCGA对M01的注释有时与报告文本不一致(见“方法”部分)。
M01模型受限于其训练的输入数据质量。在未来的工作中,通过在含有大量M1注释的病理报告数据集上进行训练,并且具有更一致的 ground truth 注释,可能会改善M01模型。
四、方法
4-1:TCGA病理报告数据集构建与TNM注释
从TCGA基因组数据共享(GDC)数据门户(https://portal.gdc.cancer.gov)下载了病理报告及相关TNM临床元数据。
报告最初以PDF格式存储;在之前的工作中,作者使用OCR将TCGA病理报告语料库转换为机器可读的纯文本,并进行了广泛的审查和最终的TCGA报告集全特征描述。最终数据集涵盖了9,523份报告,患者与报告的比例为1:1[14]。
TNM分期注释包含在TCGA提供的临床元数据中。本研究使用的TNM分期属性是病理分期,即基于病理学家对患者肿瘤切片(们)的评估并结合之前的临床结果确定的分期。这个值与TCGA提供的临床分期不同;作者选择病理分期而非临床分期作为真实标签,因为
(1)它被认为是患者护理过程中诊断的金标准
(2)关于病理分期的信息包含在报告文本中
TCGA对所有患者的分期是以系统化的方式确定的[17]。用于真实标签标注的所有数据均来自TCGA数据门户提供的TCGA元数据。
TNM值被抽象为不带额外字母后缀的数值——例如,N1B被转换为N1。数据可用性或TNM覆盖率各不相同。给定的报告可能没有关联的TNM数据,可能有完整的关联TNM数据,或者有部分关联的TNM值。
由于覆盖率的差异,作者根据TNM数据的可用性将数据分开进行个别分类任务。每个目标数据集都包含了非均匀的目标值分布,如图1C所示,程度各不相同。
最后,发现TCGA对M01的注释不一致。作者检查了10份随机抽取的病理报告,其中5份报告在TCGA元数据中被标注为M0,5份报告被标注为M1。
作者发现,5/5被标注为M0的报告与AJCC定义的M0一致。然而,作者发现2/5被标注为M1的报告并不符合AJCC定义的M1(远处转移),而是包含了类似于被标注为M0的报告的特征。
由此,作者观察到M01目标的真实标签可能并非普遍准确,因为它们有时与AJCC关于远处转移的定义不一致,并且在报告中的应用也不一致。
4-2:临床预训练BERT-based模型的比较
对于每个目标,作者使用两种模型类型,CB18和CBB16,进行了微调实验。
两种模型都在一组临床笔记(MIMIC III[20])上进行了预训练。CB在多种临床自然语言处理任务中始终表现出高水平[24–26]。模型CB包含108.3M参数,基于经典的BERT架构[15]。然而,CB的最大输入文档长度限制为512个令牌,这是一个严重的限制。当报告超过512个令牌时,在训练期间会被截断,且超过512个令牌的文本不会用于模型学习。
此外,当将模型应用于外部数据集时,报告必须再次截断为512个令牌,因此任何包含在超过512个令牌文本中的信息都不会用于模型预测。由于许多现实世界的报告长度超过512个令牌,这成为一个严重的问题。
一个较新的模型,CBB,拥有128.1M参数,并采用了计算优化的BigBird架构[27]。BigBird基于BERT架构,但在注意力机制的规范上有所不同。简而言之,稀疏注意力机制使得更长的输入在计算上可行,提供了与输入令牌数量线性运行时间(与BERT的二次运行时间相比)并在基准任务上表现更好[27]。
因此,模型CBB具有大幅增加的文档长度容量(4096个令牌),这使得在训练和应用中可以使用整个长度的报告。例如,在TCGA病理报告数据集中,超过66%的报告包含超过512个令牌(表S1),而12.9%的报告长度超过2048个令牌,只有0.7%的报告超过4096个令牌。
4-3:多类分类任务利用TCGA病理报告数据集
作者将报告分为带有M01注释的报告、带有N03注释的报告和带有T14注释的报告。
在整体TCGA数据集中,M01注释的覆盖率最低。每个报告集被分为训练集(70%)、验证集(15%)和保留测试集(15%)。由于每位患者对应一份报告,没有患者跨越超过一个训练/验证/测试(TVT)子集。
此外,在将报告分为TVT子集时,作者根据TNM值组成进行了平衡,使得相同的值平衡在TVT子集中保持一致。这允许在TVT子集之间进行公平的性能比较,没有任何TVT子集的失衡程度超过整个数据集。
分别为M01、N03和T14分类目标独立训练模型并进行超参数优化,如下所述。作者根据宏观AU-ROC和每个类别的AU-ROC(采用一对所有的方式)评估模型性能。每个目标都是单独评估的。
4-4:超参数优化、模型微调和模型选择
对于超参数优化,作者进行了迭代网格搜索,跨越两个学习率、三个批大小和三个随机种子(用于训练/验证分割)。由于内存限制,作者能够实施的最大输入令牌数为每文档2048个输入令牌。
作者为CB使用了512个输入令牌(CB模型允许的最大值),但对于CBB,作者尝试了512、1024和2048(作者硬件允许的最大值)。作者为每个模型微调了30个周期。CBB实验的运行时间明显长于CB实验,使用2048个输入令牌的CBB(CBB-2048)实例的训练运行时间几乎为每个参数组合24小时。
作者根据TCGA验证集的AU-ROC评估模型性能,根据这个指标选择每个目标的最佳最终模型。作者发现CBB-2048是T14和N03目标的最佳模型类型,而CBB-1024是M01目标的最佳模型类型(表S2)。最终的TNM模型通过Huggingface(https://huggingface.co)公开提供,这是一个广泛用于发布和下载LLMs的Python库。
Llama 3由Meta AI开发,是一个拥有80亿参数的大规模语言模型,旨在捕捉广泛的一般知识,并在各种自然语言理解基准上展示最先进的性能。
为了将Llama 3适应作者的特定临床分类任务,作者采用了低秩适配器(LoRa)方法,该方法允许高效地微调大型预训练模型。LoRa在模型的注意力和前馈层引入低秩矩阵,使作者能够只更新模型参数的一小部分,同时保持其余部分不变。
这种方法显著减少了微调所需的计算资源,并允许快速适应新任务。对于微调过程,作者用Llama 3的预训练权重初始化模型,并引入了秩为r=16、缩放因子alpha=16的LoRa适配器。作者在TCGA病理报告数据集上微调模型,针对M01、N03和T14分期注释的分类层。微调进行了3个周期,批大小为16,学习率为3e-4。作者测试了微调后的模型以及基础模型。
4-5:训练时间的评估
为了比较不同模型的训练时间,作者设置了一个实验,三个模型的条件相同。作者使用了一个NVIDIA A100 GPU实例。
该模型的规格包括80 GB内存和2 TB/s的内存带宽。结果可见表S6,显示了参数与训练时间之间的直接相关性。
4-6:CUIMC病理报告数据集的特征描述
作者从CUIMC病理报告数据库中检索了2010至2019年间的所有报告,并去除了空白报告和外部咨询报告。
作者选择了带有外科病理标签的报告,因为这种标签表明进行了组织病理学切片分析,与其他由病理科生成的报告类型相比。报告文本保持原样,未进行预处理。TNM分期注释数据位于一个单独的元数据表中,来源于肿瘤登记处。作者选择了TNM值非空的患者。
作者使用了三个属性来匹配报告文本与患者的TNM注释:患者ID、报告日期(与TNM诊断日期匹配)和TNM原发部位(图S4)。患者ID在两个数据库中精确匹配。对于日期匹配,作者允许报告日期与诊断日期之间最多有90天的差距,因为病理学家记录与肿瘤登记处正式提取分期之间存在时间差。作者观察到,随着时间窗口从0天扩展到90天,报告的总数以及每位患者的报告数都增加了。
此外,作者观察到单个患者可能有多份病理报告可能与给定的TNM注释相关,处于相同的时间窗口内。因此,作者施加了额外的匹配要求,以确保报告与注释的相关性,选择最相关的报告为与TNM相关原发部位值匹配的字符串数量最多的报告。
在这个阶段,绝大多数患者与单个TNM报告匹配。然而,在多个报告同等相关的情况下,作者连接报告以确保捕获所有相关的TNM信息。
在最终的CUIMC数据集中,大多数报告具有相关的T14注释,而具有M注释的报告数量最少,这与TCGA数据集相似(表S3A)。
作者为每个目标记录了类别不平衡(表S3D)。作者发现,T4和N3是每个目标中最不常见的类别,这与TCGA报告集的情况相同(图1C)。

作者还发现,CUIMC数据集中M1的比例(20.1%)高于TCGA数据集(6.7%)。与TCGA报告相比,CUIMC报告的疾病范围更广:TCGA数据集涵盖了21-23种癌症类型,而CUIMC数据集涵盖了40-42个原发部位(尽管这些术语并不直接可比)。作者绘制了每个目标报告集的原发部位分布(图S4),发现三个目标之间的分布相似。与TCGA数据集一样,乳腺癌和肺癌是所有三个目标中最常见的癌症部位。
最后,使用CBB分词器,作者计算了每个目标数据集的令牌统计(表S3C)。总体而言,作者发现CUIMC病理报告的长度超过了TCGA病理报告,无论是平均长度还是最大报告长度。
此外,作者还探索了数据集的人口统计学特征,并包括在表S3B中。

4-7:将TCGA训练的模型应用于CUIMC数据集
TNM模型直接应用于整个CUIMC报告集(无需任何额外的微调)。
与之前一样,作者计算AU-ROC以评估模型性能。作者发现,与TCGA验证和保留测试集一样,M01是表现最差的模型(与T14和N03模型相比)。
作者将TNM模型在CUIMC数据集上的表现与Abedian等人的研究进行了比较5,10,这是在病理报告文本作为唯一输入、预测的TNM目标值范围(T14、N03和M01)以及训练和测试集中包含多种癌症类型方面与作者最相似的研究。Abedian等人报告了F1,而不是AU-ROC。
作者计算了F1,并将结果与参考文献5中的泛癌症测试集结果进行了比较(表S3E)。
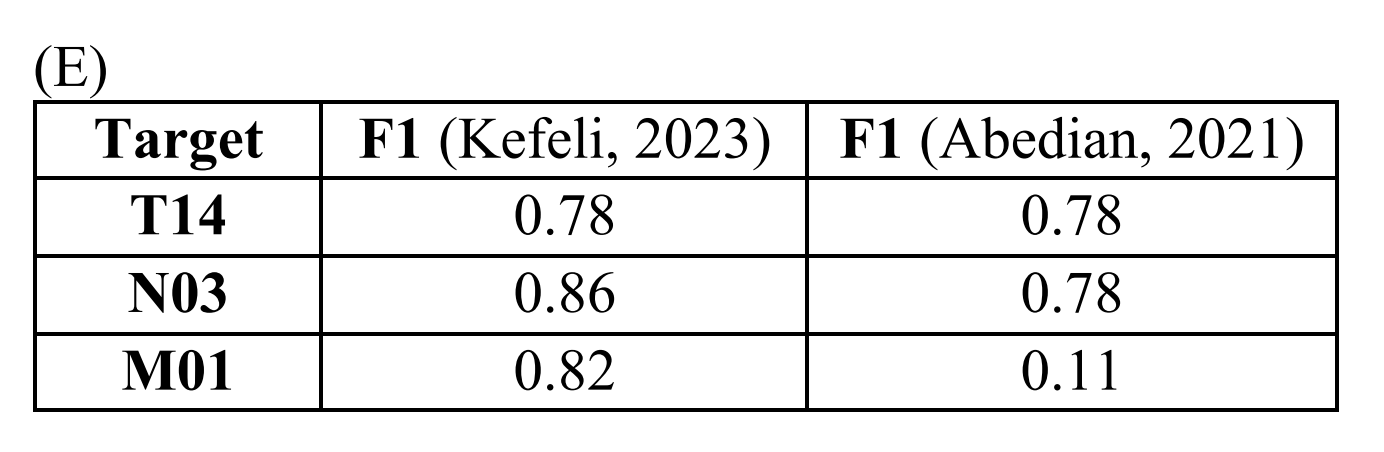
作者发现,作者的T14模型表现与参考文献5相当,作者的N03模型表现略好,而作者的M01模型表现显著优于参考文献5中的相应模型。
为了进一步探测作者的外部验证结果,作者进行了三项额外的实验。
首先,尽管作者发现CBB模型类型在TCGA报告集上实现了最佳性能,但作者感兴趣的是这一结果是否也适用于CUIMC报告。
为了测试这一点,作者将最佳表现的TCGA训练的CB模型应用于CUIMC报告集,以预测N03目标。CB和CBB在所有评估指标上的性能差异很大,包括整体宏观和每个类别的AU-ROC(表S4)。CBB可能由于其增加的复杂性和增加的输入令牌大小而表现优于CB(表S3C)。
其次,作者测试了作者的报告诊断匹配的主要参数,即诊断与报告日期之间的天数,对CUIMC表现是否有影响。作者将TCGA训练的模型分别应用于0、10和30天的CUIMC数据,并将结果与90天报告匹配的性能进行了比较(图S5)。
在这个敏感性分析中,作者发现随着天数的增加,AU-ROC保持稳定。对于多类别目标T14和N03,作者绘制了随时间变化的每个类别的变化,发现随着天数的增加,每个类别的AU-ROC略有提高。AU-ROC随天数增加的变化幅度因类别而异。最不常见的类别(例如T4和N3)在天数增加时AU-ROC的提高幅度最大;这可能是由于随着天数增加,报告相关性的可能性增加。
最后,作者测试了去除每份报告前言中的PHI,如病历号、出生日期等,对T14目标的影响。在CUIMC数据集中,大多数患者识别文本位于每份报告的前几行(而诊断信息通常不包含在这个前言部分)。作者的假设是,在没有这些额外患者细节的情况下,模型可能会表现更好,尤其是这些细节在模型训练时并未出现在去识别的TCGA报告集中。
然而,作者发现当去除PHI时,AU-ROC仅提高了0.0001(表S5)。作者确定,对于外部验证来说,PHI去除不是必要的,因为增加的预处理努力可能会导致性能只有非常小的提升。
4-8:软件需求
在训练和测试作者的模型过程中,作者使用了以下Python(版本3.12)软件包。
numpy(版本1.26.4)进行数值计算,pandas(版本2.2.2)进行数据操作和分析,scikit-learn(版本1.4.2)提供机器学习算法,scipy(版本1.13.0)用于科学计算,seaborn(版本0.11.2)进行数据可视化,transformers(版本4.40.2)用于自然语言处理,以及torch(版本2.3.0)进行深度学习。
特别是对于llama3模型,作者使用了accelerate(版本0.30.0)以优化训练速度,bitsandbytes(版本0.43.1)进行高效计算,evaluate(版本0.4.2)进行性能评估,huggingface-hub(版本0.23.0)用于模型分享,以及peft(版本0.10.0)进行参数高效的微调。
五、数据可用性
本研究使用了来自TCGA和CUIMC电子健康记录(EHR)的数据。
TCGA病理报告文本可在https://github.com/tatonetti-lab/tcga-path-reports 以MIT许可证的形式找到。
来自CUIMC EHR的去识别化数据(即病理报告)将以受控访问的方式提供。由于本研究使用的病理报告中的数据敏感性,需要受控访问。
希望访问数据的研究人员必须接受HIPAA政策培训并遵守该政策,并可联系相应作者发起数据访问请求,作者将在30天内回复每个请求。
六、代码可用性
本研究使用的Python脚本可在Github上找到:https://github.com/tatonetti-lab/tnm-stage-classifier。
本研究生成的模型可在Huggingface上找到:https://huggingface.co/jkefeli/CancerStage_Classifier_T、https://huggingface.co/jkefeli/CancerStage_Classifier_N 和 https://huggingface.co/jkefeli/CancerStage_Classifier_M。
原文地址:https://blog.csdn.net/qq_45404805/article/details/143008084
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!