Java8新语法
一、Java8新特性
JDK 8 正式版在 2013 年 9 月份发布。
Java8主要内容
Lambda表达式
函数式接口
方法引用与构造器引用
Stream API
接口中的默认方法与静态方法
新时间日期API
其他新特性
Java8新特性简介:
速度更快
代码更少(增加了新的Lambda表达式)
强大的Stream API
便于并行
最大化减少空指针异常Optional
二、编程范式
+++ 编程范式
编程范式是一种编程风格或方法论,它规定了解决问题和构建软件系统的基本方式。
编程范式就是写代码的不同风格或方法,就像不同的做饭方式(炒、煮、烤)一样。
不同的编程范式有不同的规则和特点,指导你如何组织代码和解决问题。
2.1 编程范式
+++ 常见的编程范式包括:
*命令式编程(Imperative Programming):通过一系列命令来描述程序执行的步骤,侧重于描述“如何做”。
特点:通过一系列明确的命令来改变程序的状态。
*函数式编程(Functional Programming):将计算视为数学函数的求值,强调函数的纯粹性和不可变性。
特点:使用纯函数、不可变数据结构和高阶函数,强调函数的组合和数据的不可变性。
它将计算过程视为函数求值,强调函数的纯粹性、不可变性和高阶函数。
函数式编程强调的是尽量避免修改变量的值和程序状态。
这意味着在函数式编程中,函数不会改变传入的参数,也不会修改外部的状态或变量。
相反,它会创建新的数据结构来表示变化,而不是直接修改原有的数据。
*流式编程(Stream Programming):它强调数据流的处理和变换,尤其适合处理大规模数据或连续数据流。
*面向对象编程(Object-Oriented Programming):将数据和对数据的操作封装为对象,强调数据封装、继承和多态。
特点:通过定义类和对象来封装数据和行为,强调代码的重用性和模块化。
*面向切面编程(Aspect-Oriented Programming, AOP):
特点:通过将横切关注点(如日志记录、安全性等)分离出来,使核心业务逻辑更加清晰。
过程式编程(Procedural Programming):按照过程或函数的顺序执行代码,将代码模块化为过程或函数。
逻辑式编程(Logic Programming):基于逻辑规则进行推理和问题求解,如Prolog。
声明式编程(Declarative Programming):描述问题的性质而非解决问题的步骤,如SQL。
特点:通过描述“是什么”而不是“怎么做”来实现计算,常用于数据库查询和配置文件。
面向事件编程(Event-Driven Programming):基于事件和事件处理来组织程序结构。
并发编程(Concurrent Programming):处理多个任务同时执行的编程范式,如使用线程或协程。
+++ 编程范式在代码中实际应用
每种编程范式都有自己的优势和适用场景,选择合适的编程范式可以帮助开发人员更有效地解决问题并构建可维护的软件系统。
在实际开发中,通常会结合多种编程范式来编写代码,以充分利用各种范式的特点。
`
1)命令式编程:就像跟着食谱一步一步做饭。
// 命令式:一步步指示计算机做什么
int sum = 0;
for (int i = 1; i <= 10; i++) {
sum += i;
}
System.out.println(sum);
2)函数式编程:就像告诉别人你想要什么结果,他们来帮你做。
import java.util.stream.IntStream;
int sum = IntStream.rangeClosed(1, 10)
.sum();
System.out.println(sum);
3)面向对象编程:就像组织厨房里的工具和食材,把相关的东西放在一起。
class Calculator {
private int sum = 0;
public void add(int value) {
sum += value;
}
public int getSum() {
return sum;
}
}
Calculator calc = new Calculator();
for (int i = 1; i <= 10; i++) {
calc.add(i);
}
System.out.println(calc.getSum());
2.2 编程范式:函数式编程
函数式编程(Functional Programming)是一种编程范式,
它使用纯函数、不变数据和高阶函数,避免状态变化和副作用,通过函数组合和递归来实现逻辑,从而使代码更加简洁、可读、易于调试和并发安全。
1)使用纯函数、不变数据和高阶函数
纯函数:函数的输出仅依赖于其输入,不依赖于外部状态或副作用。
不可变性:数据在函数式编程中通常是不可变的。不可变性意味着一旦创建数据结构,它就不能被修改。
高阶函数:函数式编程中,函数可以作为参数传递给另一个函数,也可以作为返回值。
2)避免状态变化和副作用
函数式编程尽量减少或消除全局状态和可变状态,侧重于通过函数参数传递数据。这种方法有助于编写更易于理解和调试的代码。
3)通过函数组合和递归来实现逻辑
函数组合:通过组合简单的函数可以构建复杂的功能。这种方式通常使代码更简洁、更易读。
递归:由于数据不可变,函数式编程中广泛使用递归来替代传统的迭代操作。许多函数式编程语言优化了递归以防止栈溢出。
public static void main(String[] args) {
// 不可变数据
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// 纯函数:square函数不改变输入数据,也不依赖外部状态
Function<Integer, Integer> square = x -> x * x;
// 高阶函数:map方法接受一个函数作为参数,并返回一个新的列表
List<Integer> squares = numbers.stream()
.map(square)
.collect(Collectors.toList());
// 输出结果
System.out.println("Original numbers: " + numbers);
System.out.println("Squared numbers: " + squares);
}
2.3 编程范式:流式编程
流式编程:流式编程通常涉及使用方法链(method chaining)来串联多个操作,
使代码看起来像一条连续的流水线(pipeline)一样
1)声明式编程风格:
流式编程采用了一种声明式的编程风格,
你只需描述你想要对数据执行的操作,而不需要显式地编写迭代和控制流语句。这使得代码更加直观和易于理解,
因为你可以更专注地表达你的意图,而无需关注如何实现。
2)链式调用:
流式编程使用方法链式调用的方式,将多个操作链接在一起。
每个方法都返回一个新的流对象,这样你可以像“流水线”一样在代码中顺序地写下各种操作,使代码逻辑清晰明了。
这种链式调用的方式使得代码看起来更加流畅,减少了中间变量和临时集合的使用。
3)操作的组合:
流式编程提供了一系列的操作方法,如过滤、映射、排序、聚合等,这些方法可以按照需要进行组合使用。
你可以根据具体的业务需求将这些操作串联起来,形成一个复杂的处理流程,而不需要编写大量的循环和条件语句。
这种组合操作的方式使得代码更加模块化和可维护。
4)减少中间状态:
传统的迭代方式通常需要引入中间变量来保存中间结果,这样会增加代码的复杂度和维护成本。
而流式编程将多个操作链接在一起,通过流对象本身来传递数据,避免了中间状态的引入。这种方式使得代码更加简洁,减少了临时变量的使用。
5)减少循环和条件:
流式编程可以替代传统的循环和条件语句的使用。例如,可以使用 filter() 方法进行元素的筛选,使用 map() 方法进行元素的转换,使用 reduce() 方法进行聚合操作等。
这些方法可以用一行代码完成相应的操作,避免了繁琐的循环和条件逻辑,使得代码更加简洁明了。
>>>> 自定义类实现流式编程
import java.util.ArrayList;
import java.util.List;
import java.util.function.Predicate;
import java.util.function.Function;
public class CustomDataProcessor {
private List<String> data;
public CustomDataProcessor(List<String> data) {
this.data = data;
}
public CustomDataProcessor filter(Predicate<String> predicate) {
List<String> filteredData = new ArrayList<>();
for (String item : data) {
if (predicate.test(item)) {
filteredData.add(item);
}
}
this.data = filteredData;
return this;
}
public CustomDataProcessor map(Function<String, String> mapper) {
List<String> mappedData = new ArrayList<>();
for (String item : data) {
mappedData.add(mapper.apply(item));
}
this.data = mappedData;
return this;
}
public List<String> collectToList() {
return new ArrayList<>(data);
}
public static void main(String[] args) {
List<String> data = List.of("Apple", "Banana", "Cherry", "Date", "Elderberry");
List<String> result = new CustomDataProcessor(data)
.filter(s -> s.startsWith("A"))
.map(String::toUpperCase)
.collectToList();
System.out.println(result); // 输出结果为 [APPLE]
}
}
三、Java8中函数式编程的实现
3.1 Java8实现函数式编程的基础
+++ Java8实现函数式编程的前提
Java 8 通过引入多种新特性,使得函数式编程成为可能。
以下是一些关键点:
1)Lambda表达式:
Lambda 表达式提供了一种简洁的方式来定义匿名函数,允许将函数作为参数传递。
高阶函数:是指能够接受其他函数作为参数或者返回一个函数作为结果的函数。
换句话说,高阶函数将函数视为一等公民,可以像普通变量一样进行操作,这是函数式编程中的一个重要概念。
Lambda 表达式的作用:
在 Java 8 之前,Java 并不支持将函数作为一等公民,也就是说,函数不能作为参数传递给另一个函数,也不能作为返回值。
然而,Lambda 表达式使得这一点成为可能。
2)函数式接口:
函数式接口是只包含一个抽象方法的接口,可以用 Lambda 表达式或方法引用来实现。Java 8 提供了很多内置的函数式接口,例
如 Function、Predicate、Consumer 和 Supplier。
// 使用 Function 接口
Function<Integer, Integer> square = x -> x * x;
int result = square.apply(5);
3)方法引用:
方法引用是一种更简洁的 Lambda 表达式语法,可以直接引用现有的方法。
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
names.forEach(System.out::println); // 使用方法引用
4)Stream API:
Stream API 提供了一种声明式的数据处理方式,可以对集合执行过滤、映射、规约等操作。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> squares = numbers.stream()
.map(x -> x * x) // 映射操作
.collect(Collectors.toList()); // 收集结果
5)默认方法和静态方法:
Java 8 允许在接口中定义默认方法和静态方法,使得接口更灵活。
interface MyInterface {
default void defaultMethod() {
System.out.println("Default method");
}
static void staticMethod() {
System.out.println("Static method");
}
}
+++ Java8实现函数式编程
Java 8 实现函数式编程主要通过引入 Lambda 表达式和 Stream API。
Lambda 表达式允许开发者以更简洁的方式定义匿名函数,
而Stream API则提供了一种声明式的方式来处理集合数据,支持并行处理和链式操作,从而使得代码更具表现力、可读性和并发性,符合函数式编程的核心理念。
通过以上Java8提供的新特性,Java 8 实现了函数式编程的以下核心概念:
高阶函数:可以将函数作为参数传递和返回。
纯函数:函数不依赖于外部状态,也不改变外部状态。
不可变性:鼓励使用不可变的数据结构。
函数组合:可以通过组合多个小函数来构建复杂的操作。
声明式编程:通过 Stream API,使用声明式方式处理集合。
3.2 代码演示
java
import java.util.Arrays;
import java.util.List;
import java.util.function.Function;
import java.util.stream.Collectors;
public class FunctionalProgrammingExample {
public static void main(String[] args) {
// 不可变数据
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// 纯函数:square函数不改变输入数据,也不依赖外部状态
Function<Integer, Integer> square = x -> x * x;
// 高阶函数:map方法接受一个函数作为参数,并返回一个新的列表
List<Integer> squares = numbers.stream()
.map(square)
.collect(Collectors.toList());
// 输出结果
System.out.println("Original numbers: " + numbers);
System.out.println("Squared numbers: " + squares);
}
}
四、函数式编程 – Lambda表达式
Lambda 表达式:
1、本质上就是一种匿名函数的简写。
2、它将方法参数、表达式和代码块封装在一个可传递的函数体中,
从而实现更加紧凑的代码结构和函数式编程。
3、作用:将代码像数据一样进行传递
4.1 Lambda的作用(优点)
1)代码简洁性
使用 Lambda 表达式可以显著减少样板代码的量,使程序变得更加简洁和易于阅读。与内部类相比,Lambda 表达式更加紧凑,可以减少您需要编写和维护的代码量。
// 传统的 Java 方法
Runnable r1 = new Runnable() {
@Override
public void run() {
System.out.println("Hello, World!");
}
};
// 使用 Lambda 表达式
Runnable r2 = () -> System.out.println("Hello, World!");
2)函数式编程特性
Lambda 表达式允许 Java 实现函数式编程的核心特性,例如高阶函数和闭包。通过 Lambda 表达式,可以将函数作为参数传递给其他函数或从其他函数中返回函数。
public static void forEach(List<Integer> list, Consumer<Integer> consumer) {
for (Integer i : list) {
consumer.accept(i);
}
}
3)提高代码可读性和可维护性
Lambda 表达式可以使代码更易于阅读和维护。由于 Lambda 表达式可以消除冗长的样板代码,因此它们使代码更具可读性和可维护性。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.stream()
.filter(n -> n % 2 == 0)
.map(n -> n * 2)
.forEach(System.out::println);
4.2 Lambda表达式的基本语法
+++ Lambda表达式
Lambda表达式的结构由三个部分组成:参数列表、箭头符号和函数体。
1)“->”
Java8中引入了一个新的操作符
该操作符称为箭头操作符或者Lambda操作符
2)箭头操作符将Lambda表达式拆分为两个部分
a、左侧: Lambda表达式的参数列表 (接口中抽象方法的形参列表)
b、右侧: Lambda表达式中所需执行的功能, 即Lambda体(重写的抽象方法的方法体)
c、左边右边均可以简写
//无参数无返回值
Runnable runnable = () -> System.out.println("runable");
//有参数无返回值
Consumer<Integer> consumer = (Integer a) -> System.out.println(a);
//有参数有返回值
Comparator<String> comparator = (a,b) -> a.compareTo(b);
+++ Lambda表达式基础语法:
1)语法格式一: 无参数, 无返回值
() -> System.out.printIn(“Hello Lambda!”);
2)语法格式二:有一个参数,并且无返回值 此时参数的小括号可以不写
x -> System.out.printIn(x);
(x) -> System.out.printIn(x);
3)语法格式三:有两个参数,有返回值,并且Lambda体中有多条语句
(x, y) -> {多条语句}
4)语法格式四:若Lambda体中只有一条语句,return和大括号都可以省略不写
Comparator com = (x,y) -> Integer.compare(x,y);
5)语法格式五:Lambda表达式的参数列表的数据类型可以省略不写,因为JVM编译器通过上下文推断出数据类型,即”类型推断“
+++ Lambda表达式前提条件:
1)Lambda表达式需要一个函数式接口作为目标。
2)函数式接口: 接口中有且只有一个抽象方法的接口, 称为函数式接口.
可以使用注解@FunctionalInterface修饰, 可以检查是否是函数式接口.
常见的函数式接口包括java.util.function包中的Function、Predicate、Consumer、Supplier等。
4.3 Lambda表达式在集合操作中的应用
1)遍历
public static void main(String[] args) {
//lambda表达式遍历List
List<String> list=Arrays.asList("1212","434","2323");
list.forEach(e->{
System.out.println(e);
});
//lambda表达式遍历Set
Set<String> set = new HashSet<>(Arrays.asList("apple", "orange", "banana", "pear"));
set.forEach(e->{
System.out.println(e);
});
//lambda表达式遍历map
Map<Integer, String> map = new HashMap<>();
map.put(1, "apple");
map.put(2, "orange");
map.entrySet().stream().forEach(e->{
System.out.println(e.getKey());
System.out.println(e.getValue());
});
}
2)排序????
public static void main(String[] args) {
//=========================== lambda表达式遍历List
List<String> list=Arrays.asList("1212","434","2323");
//1、使用Comparator匿名内部类实现比较器
list.sort(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.length()-o2.length();
}
});
//2、使用lambda表达式实现比较器
list.sort((a1,a2)->a1.compareTo(a2));
System.out.println(list);
//=========================== lambda表达式遍历Set
Set<String> set = new HashSet<>(Arrays.asList("apple", "orange", "banana", "pear"));
//1、使用Comparator匿名内部类实现比较器
set.stream().sorted(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.length()-o2.length();
}
});
//2、使用lambda表达式实现比较器
set.stream().sorted((o1,o2)->{
return o1.length()-o2.length();
});
System.out.println(set);
//=========================== lambda表达式遍历map
Map<Integer, String> map = new HashMap<>();
map.put(1, "apple");
map.put(2, "orange");
//1、使用Comparator匿名内部类实现比较器
Map<Integer, String> newMap = map.entrySet().stream().sorted(new Comparator<Map.Entry<Integer, String>>() {
@Override
public int compare(Map.Entry<Integer, String> o1, Map.Entry<Integer, String> o2) {
return o1.getKey() - o2.getKey();
}
}).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
System.out.println(newMap);
//2、使用lambda表达式实现比较器
Map<Integer, String> map2 = map.entrySet().stream().sorted((o1, o2) -> {
return o1.getKey() - o2.getKey();
}).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
System.out.println(map2);
}
五、函数式编程 – 函数式接口
【Java中函数编程来源】
Java从诞生起就一直倡导“万物皆可对象”,在Java里面向对象(OOP)编程是一切,
但是随着python、Scala等语言的兴起和挑战,Java不得不作出调整以便支持更加广泛的技术要求,
也即Java不但可以支持OOP还可以支持OOF(面向函数编程)
【Java中Lambda表达式对象,它是函数式接口的实例对象】
在函数式编程语言中,函数被当作一等公民对待,在将函数作为一等公民的编程语言中,Lambda表达式的类型是函数。
但是在Java8中,有所不同。在Java8注解,Lambda表达式是对象,而不是函数,它们必须依附于一类特别的对象类型—函数式接口
+++ 函数式接口(Functional Interface)
1)一个接口如果只声明了一个抽象方法,则这个接口就被称为函数式接口。
2)Java 8内置了许多常用的函数式接口,这些接口都位于java.util.function包中。
+++ Lambda表达式在函数式接口中的使用
1)只有函数式接口才能缩写成 Lambda 表示式。函数式接口与Lambda 表示式共同实现Java编程式风格。
2)Lambda表达式是函数式接口的实例对象(匿名内部类)。它实现了函数式接口的抽象方法。
a、Lambda表达式实现了函数式接口的抽象方法:
函数式接口只有一个抽象方法,Lambda表达式可以实现该抽象方法,从而创建函数式接口的实例。
b、Lambda表达式作为函数式接口的实例:
Lambda表达式可以看作是函数式接口的实例,因为它们都符合函数式接口的定义。
c、函数式接口作为Lambda表达式的目标类型:
Lambda表达式必须有一个目标类型,通常是函数式接口。
5.1 什么是函数式接口
+++ 什么是函数式接口
1、一个接口如果只声明了一个抽象方法,则这个接口就被称为函数式接口。
2、接口中只包含一个抽象方法,且不包含静态方法、默认方法或重写 Object 类方法时,即可被视为函数式接口。
接口中静态方法除外(static方法)
接口有默认方法除外(default方法)
接口中重写的Object对象的方法除外(例如接口中有equals方法)
【以Comparator比较器为例】
+++ 函数式接口的检验
1、函数式接口可通过@FunctionalInterface注解进行检验。
2、@FunctionalInterface 注解的作用
1)明确意图:@FunctionalInterface 注解明确表示一个接口是一个函数式接口。
这有助于代码的可读性和理解,表明该接口的设计目的就是用作 lambda 表达式或方法引用的目标类型。
2)编译时检查:当一个接口被标记为 @FunctionalInterface 时,编译器会强制检查该接口是否符合函数式接口的定义(即只有一个抽象方法)。
如果该接口包含多个抽象方法,编译器会报错。这可以帮助开发者避免错误地定义函数式接口。
1)什么是函数式接口【以Comparator比较器为例】

为什么 Comparator 是函数式接口
1、只有一个抽象方法:
尽管 Comparator 接口中定义了许多方法,
但根据 Java 8 的定义,
1)只有 compare(T o1, T o2) 是抽象方法。
2)equals(Object obj) 是继承自 Object 类的方法,不算作抽象方法。
3)其他的都是默认方法或静态方法,
这些方法不影响接口作为函数式接口的资格。
2、注解 @FunctionalInterface:
虽然 @FunctionalInterface 注解是可选的,但它明确表示这个接口是一个函数式接口。
如果接口不符合函数式接口的定义(即包含多个抽象方法),编译器会报错。
Comparator 接口使用了这个注解,确保它是一个函数式接口。
5.2 Java中内置函数式接口
+++ Java8内置的函数式接口
1)Consumer接口:口。接收一个入参,不返回结果。【有1个入参,无结果】
void accept(T t);
//案例
Consumer<String> printer = (s) -> System.out.println(s);
printer.accept("Hello, World!");
2)Supplier接口: 供给型接口。不接收参数,返回一个结果。【无入参,有结果】
T get();
//案例
Supplier<Double> randomNumber = () -> Math.random();
System.out.println(randomNumber.get());
3)Function接口:函数型接口。接收一个入参,返回一个结果。【有1个入参,有结果】
R apply(T t);
//案例
Function<Integer, String> converter = (num) -> Integer.toString(num);
System.out.println(converter.apply(42));
4)Predicate接口:断言型接口。接口一个入参,返回一个布尔值。【有1个入参,有结果,结果为布尔类型】
boolean test(T, t);
//案例
Predicate<String> isLongEnough = (s) -> s.length() > 5;
System.out.println(isLongEnough.test("Hello"));
BiPredicate接口:断言型接口。接口两个入参,返回一个布尔值。【有1个入参,有结果,结果为布尔类型】
boolean test(T, t);
//案例
BiPredicate<String,String> biPredicate=(s1,s2)->{
return s1.length()==s2.length();
};
System.out.println(biPredicate.test("Hello","xxxxx"));
1)基础案例 – 使用lamba表达式创建匿名内部类,直接使用
public class Demo2 {
public static void main(String[] args) {
//测试生产型接口:无入参,有结果
System.out.println("=============测试生产型接口");
Supplier<String> supplier=()->"随机生成:"+Math.random();
String result = supplier.get();
System.out.println(result);
//测试消费性接口:有入参,无结果
System.out.println("=============测试消费型接口");
Consumer<String> consumer=msg->{
String result2="收到消息:"+msg;
System.out.println(result2);
};
consumer.accept("123");
//测试函数型接口:有入参,有结果
System.out.println("=============测试函数型接口");
Function<String,Integer> function=x->{
return x.length();
};
Integer result3 = function.apply("12323");
System.out.println(result3);
//测试断言型接口:有入参,有结果,结果为布尔型
System.out.println("=============测试断言型接口");
Predicate<String> predicate=x->x.length()>3;
boolean xxxx = predicate.test("xxxx");
System.out.println(xxxx);
}
}
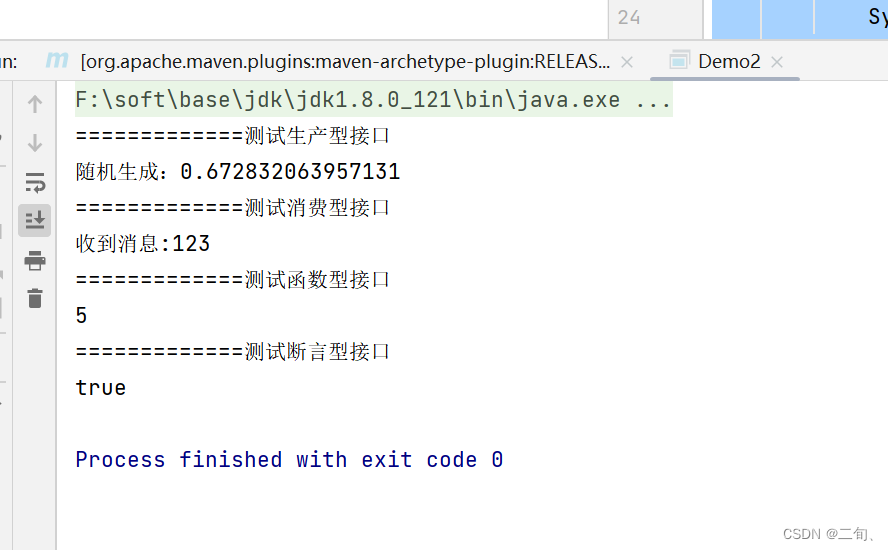
2)基础案例2 – 使用lamba表达式创建匿名内部类,作为参数传递
public class Demo {
/**
* 测试消费型接口
* @param msg
* @param consumer
*/
public static void testCousumer(String msg, Consumer<String> consumer){
consumer.accept(msg);
}
/**
* 测试供给型接口
* @param supplier
*/
public static void testSupplier(Supplier<Double> supplier){
Double result = supplier.get();
System.out.println(result);
}
/**
* 测试函数型接口
* @param msg
* @param fun
*/
public static void testFunction(String msg,Function<String,String> fun){
String result = fun.apply(msg);
System.out.println(result);
}
/**
* 测试断言型接口
* @param msg
* @param predicate
*/
public static void testPredicate(String msg, Predicate<String> predicate){
boolean test = predicate.test(msg);
System.out.println(test);
}
public static void main(String[] args) {
//测试消费型接口
testCousumer("hello",(m)->{
System.out.println("接收到消息:"+m);
});
//测试消费型接口
testSupplier(()->{return Math.random();});
//测试函数型接口
testFunction("123",msg->{
return "接收到消息:"+msg;
});
//测试断言型接口
testPredicate("1234",x->{
return x.length()>0;
});
}
}
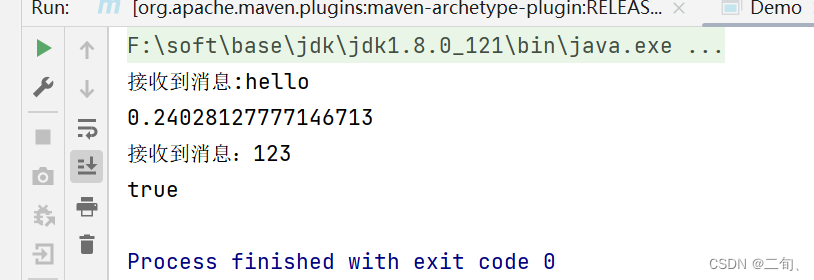
3)基础案例2 – lamba表达式高级应用
>>>>> 消费
public class Demo2 {
private static Map<String,Consumer<CrudVO>> consumerMap=new HashMap();
static {
Consumer<CrudVO> addConsumer=t->{
Integer number = t.getNumber();
System.out.println("+1操作:"+(number+1));
};
Consumer<CrudVO> reduceConsumer=t->{
Integer number = t.getNumber();
System.out.println("-1操作:"+(number-1));
};
Consumer<CrudVO> quartConsumer=t->{
Integer number = t.getNumber();
System.out.println("平方操作:"+(number*number));
};
consumerMap.put("add",addConsumer); //加1
consumerMap.put("reduce",reduceConsumer); //减1
consumerMap.put("quart",quartConsumer); //平方
}
static class CrudVO{
private Integer number;
public Integer getNumber() {
return number;
}
public void setNumber(Integer number) {
this.number = number;
}
}
public static void main(String[] args) {
CrudVO vo=new CrudVO();
vo.setNumber(12);
consumerMap.get("add").accept(vo);
consumerMap.get("reduce").accept(vo);
consumerMap.get("quart").accept(vo);
}
}
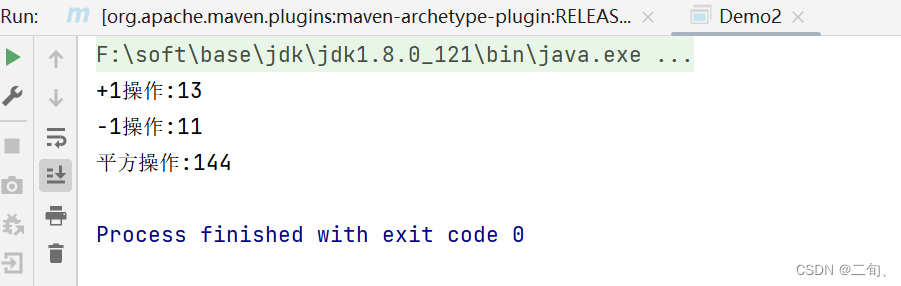
>>>>> 供给
public class Demo2 {
private static Map<String,Supplier<LocalDate>> supplierMap=new HashMap();
static {
//当前日期-当月第一天
Supplier<LocalDate> dayFun=()->{
LocalDate now = LocalDate.now();
LocalDate localDate = now.withDayOfMonth(1);
return localDate;
};
//当前日期+1个月
Supplier<LocalDate> dayFun2=()->{
LocalDate now = LocalDate.now();
LocalDate localDate = now.plusDays(15);
return localDate;
};
supplierMap.put("way1",dayFun);
supplierMap.put("way2",dayFun2);
}
public static void main(String[] args) {
LocalDate localDate = supplierMap.get("way1").get();
System.out.println(localDate);
LocalDate localDate1 = supplierMap.get("way2").get();
System.out.println(localDate1);
}
}

>>>>> 函数
public class Demo2 {
private static Map<String,Function<LocalDate,LocalDate>> funMap=new HashMap();
static {
//根据传入日期,获取月初
Function<LocalDate,LocalDate> way1=t->{
LocalDate localDate = t.withDayOfMonth(1);
return localDate;
};
//根据传入日期,获取月中
Function<LocalDate,LocalDate> way2=t->{
LocalDate localDate = t.withDayOfMonth(15);
return localDate;
};
funMap.put("way1",way1);
funMap.put("way2",way2);
}
public static void main(String[] args) {
LocalDate way1 = funMap.get("way1").apply(LocalDate.now());
System.out.println(way1);
LocalDate way2 = funMap.get("way2").apply(LocalDate.now());
System.out.println(way2);
}
}
5.3 自定义函数式接口
步骤一:创建自定义函数式接口
自定义函数式接口可以使用@FunctionalInterface注解来标记,
该注解可以让编译器检查当前接口是否符合函数式接口的规范,即只包含一个抽象方法。
@FunctionalInterface
public interface MyFunction<T, R> {
R apply(T t);
}
步骤二:使用自定义函数式接口
自定义函数式接口可以与Lambda表达式结合使用,例如:
// 在这个例子中,
// 使用了自定义的函数式接口MyFunction,
// 并通过Lambda表达式实现了该接口的抽象方法apply()。
MyFunction<Integer, String> converter = (num) -> Integer.toString(num);
System.out.println(converter.apply(42));
1)案例
自定义函数式接口
@FunctionalInterface
public interface MyFun<T1,T2,R> {
public R compute(T1 t1,T2 t2);
}
函数式接口与lamba接口结合使用
public class Demo2 {
public static void main(String[] args) {
//测试自定义函数型
MyFun<String,String,Integer> myFun=(str1,str2)->{
return str1.length()+str2.length();
};
Integer compute = myFun.compute("xxx", "wwww");
System.out.println(compute);
}
}
六、函数式编程 – 方法引用
+++ 方法引用
1)方法引用是Java 8中的一种语法糖。使用方法引用替换Lambda表达式。
它允许你直接引用已有的方法,而不需要像 Lambda 表达式那样提供一个方法体。
2)方法引用可以使代码更加简洁、易读,并且提高了代码的可维护性。
+++ 使用
1)方法引用仅能替换只有一行语句的Lambda表达式。
2)方法引用的入参、出参要与被替换的Lambda表达式一致。
3)在方法引用中,使用:: 操作符来表示引用一个方法。
4)方法引用可以分为以下几种类型:
a、静态方法引用:引用类的静态方法。
b、实例方法引用:引用特定对象的实例方法。
c、构造方法引用:引用构造函数。
d、数组构造方法引用:引用数组的构造函数。
1. 静态方法引用
// Lambda表达式
Function<Integer, String> converter = (num) -> Integer.toString(num);
// 方法引用
Function<Integer, String> converter = Integer::toString;
2. 实例方法引用
// Lambda表达式
BiPredicate<String, String> startsWith = (str, prefix) -> str.startsWith(prefix);
// 方法引用
BiPredicate<String, String> startsWith = String::startsWith;
3. 构造方法引用
// Lambda表达式
Supplier<List<String>> listSupplier = () -> new ArrayList<>();
// 方法引用
Supplier<List<String>> listSupplier = ArrayList::new;
4. 数组构造方法引用
// Lambda表达式
Function<Integer, int[]> arrayCreator = (length) -> new int[length];
// 方法引用
Function<Integer, int[]> arrayCreator = int[]::new;
3.1 基础
1)静态方法引用
public class Demo2 {
public static void say(Integer num){
System.out.println(num);
}
public static void main(String[] args) {
//1、静态方法引用
Consumer<Character> consumer1=t-> String.valueOf(t);
consumer1.accept('1');
Consumer<Character> consumer11=String::valueOf;
consumer11.accept('x');
//2、自定义静态方法引用
Consumer<Integer> consumer2=t-> say(t);
consumer2.accept(12);
Consumer<Integer> consumer22=Demo2::say;
consumer22.accept(13);
}
}
2)实例方法引用
public class Demo2 {
public boolean testxxx(String str1,String str2){
return str1.length()==str2.length();
}
public static void main(String[] args) {
//1、示例方法引用
BiPredicate<String,String> biPredicate=(str1,str2)->str1.contains(str2);
System.out.println(biPredicate.test("1234","123"));
BiPredicate<String,String> biPredicate2=String::contains;
System.out.println(biPredicate2.test("1234","123"));
//2、自定义示例方法引用
Demo2 demo2=new Demo2();
BiPredicate<String,String> biPredicate3=(str1,str2)->demo2.testxxx(str1,str2);
System.out.println(biPredicate3.test("1234","123"));
BiPredicate<String,String> biPredicate4=demo2::testxxx;
System.out.println(biPredicate4.test("1234","123"));
}
}
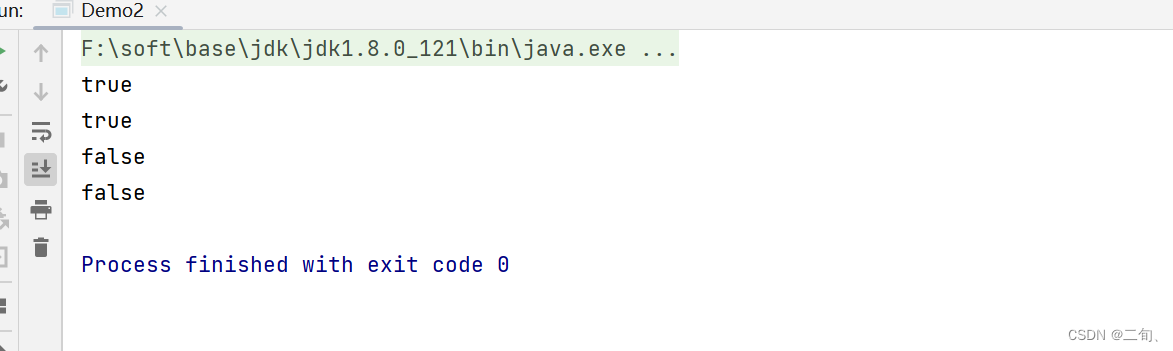
3)构造方法引用
public static void main(String[] args) {
//1、普通对象
Function<String,String> function=t->new String(t);
System.out.println(function.apply("xxx"));
Function<String,String> function1=String::new;
System.out.println(function1.apply("xxx2"));
//2、集合
Supplier<List> supplier=()->new ArrayList();
System.out.println(supplier.get());
Supplier<List> supplier2=ArrayList::new;
System.out.println(supplier2.get());
//3、数组
Function<Integer,String[]> function2=(length)->new String[length];
System.out.println(function2.apply(12));
Function<Integer,String[]> function3=String[]::new;
System.out.println(function3.apply(12));
}
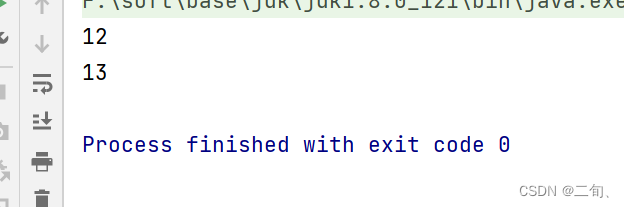
3.2 【System.out 】方法引用
public static void main(String[] args) {
Consumer<Integer> consumer=t-> System.out.println(t);
consumer.accept(12);
Consumer<Integer> consumer1=System.out::println;
consumer1.accept(13);
}
七、函数式编程 – stream
Java中有两个重要的改变. 一个是Lambda表达式, 另外一个则是Stream API(java.util.stream.*).
Stream是Java8中处理集合的关键抽象概念, 它可以指定你希望对集合进行的操作, 可以执行非常复杂的查找, 过滤和映射数据等操作.
使用Stream API对集合数据进行操作, 就类似于使用SQL执行的数据库查询. 也可以使用Stream API来并行执行操作.
简而言之,Stream API提供了一种高效且易于使用的处理数据的方式.
1 基础
1)什么是 Stream
+++ 什么是 Stream
1)Stream(流)是 Java 8 引入的一个新的抽象概念。它是对集合(Collection)对象功能的增强。
2)Stream表示数据元素的序列。它不是数据结构,而是从源中按需计算生成的。
3)Stream具有以下特点:
元素是不可变的,即操作不会修改源数据。
支持延迟操作,即只有在终端操作时,才会执行所有的中间操作。
可以并行处理,利用多核处理器的优势。
相比传统的循环和条件语句,Stream使代码更具可读性、简洁性和可维护性。
++ Stream 具有以下几个关键特点:
1)声明式编程:
使用Stream API,你可以以更为声明式的方式来处理数据,而不需要显式地控制迭代和条件语句,
这可以让代码更加清晰和易于理解。
2)集成函数式接口:
Stream API与Java中的函数式接口(如Predicate、Function等)紧密集成,
可以轻松结合Lambda表达式,使得代码更为简洁和灵活。
Java 8 的 Stream API 并不是完全的函数式编程范式,但它确实借鉴了函数式编程中的许多概念,
使得 Java 可以在一定程度上以函数式编程的风格编写代码。
3)惰性求值:
Stream 的操作是惰性求值的。也就是说在定义操作流程时,不会立即执行实际计算。
只有当终止操作(如收集结果或遍历元素)被调用时,才会触发实际的计算过程。
Stream API使用惰性求值的方式来处理数据。
中间操作(如filter、map等)只会描述要对数据执行的操作,而不会立即执行。
只有在终止操作(如collect、forEach等)调用时,才会触发实际的计算。
4)支持并行处理:
Stream API内建了并行处理能力,可以通过调用parallel方法将顺序流转换为并行流,
从而充分利用多核处理器的优势,提高处理效率。
+++ Stream中采用了哪些编程范式的代码风格
Stream采用了声明式编程、流式编程、函数式编程等代码风格。
1)声明式编程
// 声明式编程
// 开发者只需要声明数据处理的意图,具体的实现由底层框架负责。
List<String> words = Arrays.asList("apple", "banana", "cherry", "date", "elderberry");
List<String> filteredWords = words.stream()
.filter(word -> word.length() > 5) // 声明过滤条件
.map(String::toUpperCase) // 声明转换操作
.collect(Collectors.toList()); // 声明收集结果
2)流式编程
链式调用
3)函数式编程
惰性求值。
2)Stream的工作原理
+++ Stream的核心工作机制包括延迟求值和内部迭代
1)延迟求值
Stream操作(特别是中间操作)是延迟求值的。
即使你链式调用了多个中间操作,这些操作不会立即执行,只有在调用终端操作时,才会触发整个操作链。
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
Stream<String> stream = names.stream()
.filter(name -> name.startsWith("A"))
.map(String::toUpperCase);
// 此时并没有执行过滤和映射操作
System.out.println(stream); //此时并没有执行过滤和映射操作
//只有当你调用终端操作(如forEach)时,操作链才会执行:
stream.forEach(System.out::println); // 现在过滤和映射操作才会被执行
2)内部迭代
传统的集合迭代是外部迭代(由开发者控制),
而Stream使用内部迭代,由Stream API控制迭代过程,从而可以更好地优化和并行处理。
3)Stream操作执行

+++ Stream的执行流程
Stream的执行过程可以分为三个步骤:
1)构建Stream:从数据源创建Stream。
2)定义流水线:使用中间操作构建一个操作链(流水线)。
3)执行流水线:使用终端操作触发Stream的执行。
Stream上的所有操作分为两类:
1、中间操作和结束操作:
中间操作只是一种标记,只有结束操作才会触发实际计算。
2、中间操作又可以分为无状态的(Stateless)和有状态的(Stateful),
1)无状态中间操作是指元素的处理不受前面元素的影响,
2)有状态的中间操作必须等到所有元素处理之后才知道最终结果,
比如排序是有状态操作,在读取所有元素之前并不能确定排序结果;
3、结束操作又可以分为短路操作和非短路操作
短路操作是指不用处理全部元素就可以返回结果,比如找到第一个满足条件的元素。
非短路操作是指处理全部元素才可以返回结果。
【核心解析】
1、中间操作只是一种标记,只有结束操作才会触发实际计算。
2、Stream 操作是基于迭代器(Iterator)的,而不是直接使用传统的 for 循环。
3、Stream在执行多个连续操作时,会对操作进行优化。
【注意:为了便于解释stream的优化逻辑,我们用for循环来标识迭代】
1)连续操作时,会将连续的无状态的中间操作、结束操作合并到一个for循环中执行
2)有状态的中间操作会单独开启一个for循环执行。
如果前面有其他操作,则对于之前的连续操作会合并到一个for循环中执行。
如果后面有其他操作,则对于之后的连续操作也会合并到一个for循环中执行。
>>> 中间操作只是一种标记,只有结束操作才会触发实际计算。
以下代码为例,
在执行打印stream时,map方法并不会执行,因为它是中间操作,还未被触发。
在执行stream的foreach方法时,此时map才会执行。
Stream<Integer> stream = Arrays.asList(1, 2, 4, 11, 3).stream().map(e -> {
System.out.println("执行map");
return e;
});
//1、此时stream的map不会执行,因为map是中间操作
System.out.println(stream);
System.out.println("====================");
//2、此时stream的map才会执行。因为foreach是结束操作。
//结束操作触发实时计算
stream.forEach(e->{
System.out.println("执行stream:"+e);
});
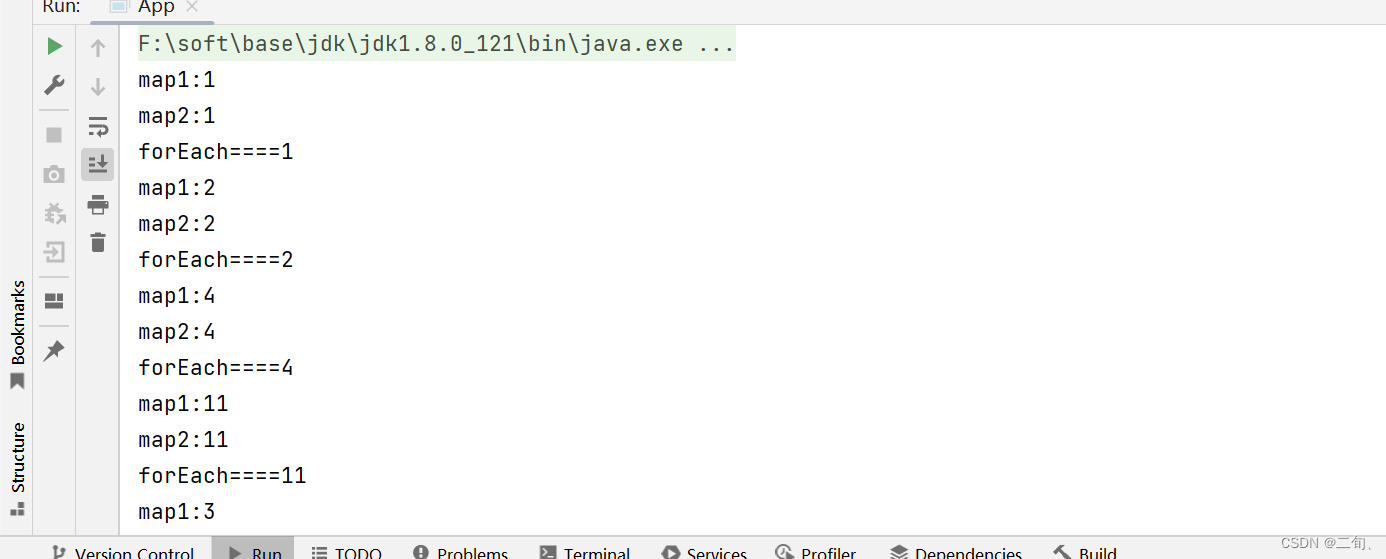
>>> 连续操作时,会将连续的无状态的中间操作、结束操作合并到一个for循环中执行
以下代码为例,map为无状态的中间操作,stream为结束操作。
stream操作有:map、map、stream。且三个操作连续执行。所以在执行代码时,会将这三段的代码放在一个for循环中执行,对元素进行遍历。
Stream<Integer> stream = Stream.of(1, 2, 4, 11, 3).map(e -> {
System.out.println("map1:" + e);
return e;
}).map(e -> {
System.out.println("map2:" + e);
return e;
});
stream.forEach(e->{
System.out.println("forEach===="+e);
});
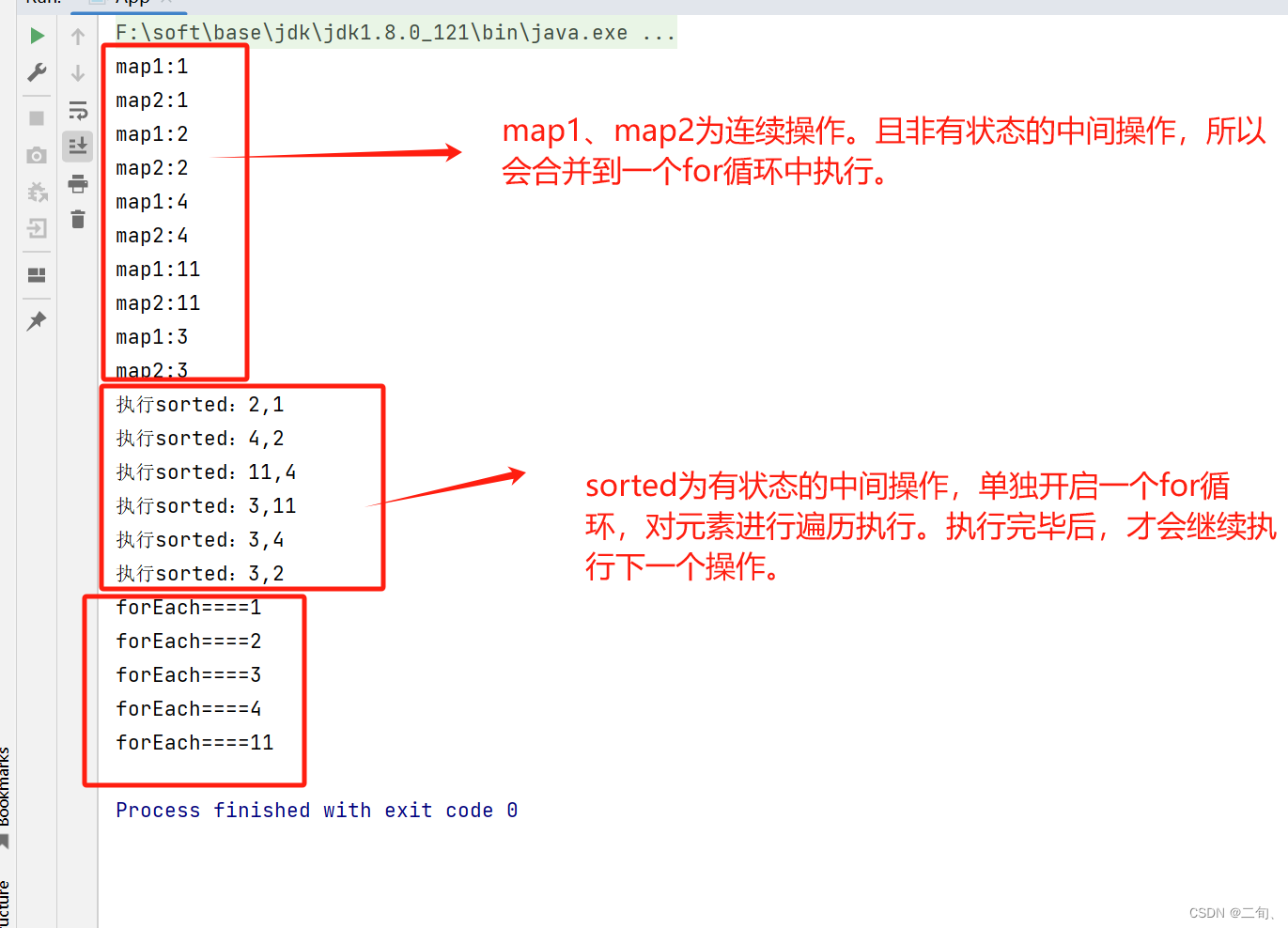
>>> 有状态的中间操作会单独开启一个for循环执行。
stream操作:map、sorted、foreach。
由于sorted为有状态的中间操作,所以会单独开启一个for循环执行。
执行完毕后,才会执行下面的操作
Stream<Integer> stream = Stream.of(1, 2, 4, 11, 3).map(e -> {
System.out.println("map1:" + e);
return e;
}).sorted((x1, x2) -> {
System.out.println("执行sorted:" + x1 + "," + x2);
return x1-x2;
});
stream.forEach(e->{
System.out.println("forEach===="+e);
});

>>> 有状态的中间操作会单独开启一个for循环执行。该操作前的连续操作、该操作后的连续操作会单独合并for循环执行。
Stream<Integer> stream = Stream.of(1, 2, 4, 11, 3).map(e -> {
System.out.println("map1:" + e);
return e;
}).map(e -> {
System.out.println("map2:" + e);
return e;
}).sorted((x1, x2) -> {
System.out.println("执行sorted:" + x1 + "," + x2);
return x1-x2;
});
stream.forEach(e->{
System.out.println("forEach===="+e);
});
2 Stream的创建
创建Stream流的四种方式:
1)将集合转为流:
我们可以通过调用集合的 stream() 方法来创建一个 Stream 对象
通过Collection系列集合提供的stream()或者parallelStream() 并行的流
2)将数组转为流:
Java 8 引入了 Arrays 类的 stream() 方法,我们可以使用它来创建一个 Stream 对象。
3)通过 Stream.of() 创建:
我们可以使用 Stream.of() 方法直接将一组元素转换为 Stream 对象
Stream<String> sd = Stream.of("!2", "#4", "sd");
4)通过 Stream.builder() 创建:
Stream.Builder<Object> builder = Stream.builder();
builder.add("123");
builder.add("xxx");
Stream<Object> build = builder.build();
5)从 I/O 资源创建:
Stream<String> lines = Files.lines(Paths.get("c://1.txt"));
6)通过生成器创建:
Java 8 中提供了 Stream.generate() 方法和 Stream.iterate() 方法来创建无限 Stream。
对于无限流,一定要结合 limit、findFirst、findAny 等终端操作,以避免无限循环。
Stream.iterate(T seed, UnaryOperator<T> f)
指定种子值,生成一个无限的流,每个新元素是通过将函数 f 应用于前一个元素来生成的。
示例
Stream<Integer> infiniteStream = Stream.iterate(0, n -> n + 2);
infiniteStream.limit(10).forEach(System.out::println);
解释:
Stream.iterate(0, n -> n + 2) 创建了一个无限流,从 0 开始,每次递增 2。
limit(10) 限制流的大小为前 10 个元素。
forEach(System.out::println) 打印流中的每个元素。
Stream<T> generate(Supplier<T> s)
生成无限流
1)示例:基础使用
public static void main(String[] args) throws IOException {
//1、将集合转化流
List<Integer> list=Arrays.asList(1,3,4);
Stream<Integer> stream = list.stream();
//2、将数组转化流
Integer[]arr=new Integer[]{12,45};
Stream<Integer> stream1 = Arrays.stream(arr);
//3、Stream.of创建流
Stream<String> sd = Stream.of("!2", "#4", "sd");
//4、Stream.builder创建流
Stream.Builder<Object> builder = Stream.builder();
builder.add("123");
builder.add("xxx");
Stream<Object> build = builder.build();
//5、通过Files读取文件创建流
Stream<String> lines = Files.lines(Paths.get("c://1.txt"));
}
2)示例:将集合转为流
public static void main(String[] args) {
//集合流
List<String> list = Arrays.asList("!2", "xxx", "eee");
Stream<String> stream = list.stream();
}
3)示例:将数组转为流
public static void main(String[] args) {
//数组流
Integer[] arr=new Integer[]{12,34};
Stream<String> stream = Arrays.stream(args);
}
4)示例:Stream.of创建流
public static void main(String[] args) {
//序列流
Stream<String> stringStream = Stream.of("1221", "xxx", "2323");
}
5)示例:Stream.builder创建流
public static void main(String[] args) throws IOException {
Stream.Builder<Object> builder = Stream.builder();
builder.add(12);
builder.add(34);
Stream<Object> build = builder.build();
}
6)示例:通过Files创建流
public static void main(String[] args) throws IOException {
Stream<String> lines = Files.lines(Paths.get("C:\\Users\\lenovo\\Desktop\\新建文件夹\\NEW FOLDER\\NEW FOLDER2\\x.txt"));
lines.forEach(e->{
System.out.println(e);
});
}

6)示例:通过Stream.generate创建无限流
>>>> 示例:打印1
循环打印1,不会停止
public static void main(String[] args) throws IOException {
Stream<Integer> stream = Stream.generate(() -> {
return 1;
});
stream.forEach(e->{
System.out.println(e);
});
}
>>>> 示例:打印1【简写】
public static void main(String[] args) throws IOException {
Stream.generate(() -> {
return 1;
}).forEach(e->{
System.out.println(e);
});
}
>>>> 示例:创建随机数
循环打印随机数,不会停止
public static void main(String[] args) throws IOException {
Stream.generate(()->{
return Math.random();
}).forEach(e->{
System.out.println(e);
});
}
>>>> 示例:创建随机数【简写】
public static void main(String[] args) throws IOException {
Stream.generate(Math::random).forEach(System.out::println);
}
>>>> 示例:生成十个随机数
public class StreamGenerateExample {
public static void main(String[] args) {
Random random = new Random();
Stream.generate(random::nextInt)
.limit(10) // 限制生成10个元素
.forEach(System.out::println);
}
}
8)示例:通过Stream.iterate创建无限流
>>>> 示例:一直执行,不会停止
public static void main(String[] args) {
//会一直执行,不会暂停
Stream<Integer> stream = Stream.iterate(20, n -> n + 2);
stream.forEach(System.out::println);
}
>>>> 示例:执行5次,就会停止
public static void main(String[] args) {
//会一直执行,不会暂停
Stream<Integer> stream = Stream.iterate(20, n -> n + 2).limit(5);
stream.forEach(System.out::println);
}
3 Stream 操作方法
3.1 Stream 操作方法原理
+++ Stream上的所有操作分为两类:
1、中间操作和结束操作:
中间操作只是一种标记,只有结束操作才会触发实际计算。
2、中间操作又可以分为无状态的(Stateless)和有状态的(Stateful),
1)无状态中间操作是指元素的处理不受前面元素的影响,
2)有状态的中间操作必须等到所有元素处理之后才知道最终结果,
比如排序是有状态操作,在读取所有元素之前并不能确定排序结果;
3、结束操作又可以分为短路操作和非短路操作
短路操作是指不用处理全部元素就可以返回结果,比如找到第一个满足条件的元素。
非短路操作是指处理全部元素才可以返回结果。
【核心解析】
1、中间操作只是一种标记,只有结束操作才会触发实际计算。
2、Stream 操作是基于迭代器(Iterator)的,而不是直接使用传统的 for 循环。
3、Stream在执行多个连续操作时,会对操作进行优化。
【注意:为了便于解释stream的优化逻辑,我们用for循环来标识迭代】
1)连续操作时,会将连续的无状态的中间操作、结束操作合并到一个for循环中执行
2)有状态的中间操作会单独开启一个for循环执行。
如果前面有其他操作,则对于之前的连续操作会合并到一个for循环中执行。
如果后面有其他操作,则对于之后的连续操作也会合并到一个for循环中执行。
3.2 Stream 操作方法 – 中间操作
Stream操作分为中间操作和结束操作:
+++ 中间操作:中间操作会返回一个新的Stream,它们是惰性求值的。
1)无状态中间操作:
filter(Predicate<T>):过滤元素。
接受一个 Predicate 函数作为参数,用于过滤 Stream 中的元素。
只有满足 Predicate 条件的元素会被保留下来。
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);
Stream<Integer> filteredStream = stream.filter(n -> n % 2 == 0); // 过滤出偶数
map(Function<T, R>):元素转换。
接受一个 Function 函数作为参数,用于对 Stream 中的元素进行映射转换。
对每个元素应用函数后的结果会构成一个新的 Stream。
Stream<String> stream = Stream.of("apple", "banana", "cherry");
Stream<Integer> mappedStream = stream.map(s -> s.length()); // 映射为单词长度
flatMap(Function<T, Stream<R>>):扁平化映射。
flatMap() 方法类似于 map() 方法,不同之处在于它可以将每个元素映射为一个流,并将所有流连接成一个流。
这主要用于解决嵌套集合的情况。
List<List<Integer>> nestedList = Arrays.asList(
Arrays.asList(1, 2),
Arrays.asList(3, 4),
Arrays.asList(5, 6)
);
Stream<Integer> flattenedStream = nestedList.stream().flatMap(List::stream); // 扁平化为一个流
2)有状态中间操作:
distinct():去重。
distinct() 方法用于去除 Stream 中的重复元素,
基本数据类型、String:根据值去重。
引用数据类型:根据元素的 equals() 和 hashCode() 方法来判断是否重复。例如:
自定义类去重时,需重写equals方法、hashcode方法。
sorted(Comparator<T>):排序。
sorted() 方法用于对 Stream 中的元素进行排序,默认是自然顺序排序。
还可以提供自定义的 Comparator 参数来指定排序规则。例如:
Stream<Integer> stream = Stream.of(5, 2, 4, 1, 3);
Stream<Integer> sortedStream = stream.sorted(); // 自然顺序排序
limit(long n):截取前n个元素。
limit() 方法可以限制 Stream 的大小,只保留前 n 个元素。例如:
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);
Stream<Integer> limitedStream = stream.limit(3); // 只保留前 3 个元素
skip(long n):跳过前n个元素。
skip() 方法可以跳过 Stream 中的前 n 个元素,返回剩下的元素组成的新 Stream。例如:
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);
Stream<Integer> skippedStream = stream.skip(2); // 跳过前 2 个元素
3)其他
Stream<String> concatStream = Stream.concat(stream1, stream2);
合并两个流
3.2.1 filter过滤
public static void main( String[] args ) throws IOException {
List<Student> stus = Arrays.asList(
new Student("张三", 12),
new Student("李四", 15),
new Student("小闳", 10)
);
System.out.println(stus);
List<Student> newStus = stus.stream().filter(e -> e.getAge() > 12).collect(Collectors.toList());
System.out.println(newStus);
}

3.2.2 map(Function<T, R>):元素转换。
public static void main( String[] args ) throws IOException {
List<Student> stus = Arrays.asList(
new Student("张三", 12),
new Student("李四", 15),
new Student("小闳", 10)
);
System.out.println(stus);
//方式一:映射
List<String> names = stus.stream().map(e -> e.getName()).collect(Collectors.toList());
System.out.println(names);
//方式二:映射:方法引用
List<String> names2 = stus.stream().map(Student::getName).collect(Collectors.toList());
System.out.println(names2);
//方式三:映射
List<String> names3 = stus.stream().map(e -> {
return "pre" + e.getName();
}).collect(Collectors.toList());
System.out.println(names3);
}
3.2.3 flatMap(Function<T, Stream>):扁平化映射。
public static void main( String[] args ) throws IOException {
List<Student> stus = Arrays.asList(
new Student("张三", 12),
new Student("李四", 15)
);
List<Student> stus2 = Arrays.asList(
new Student("小闳", 10)
);
List<List<Student>> listList = Arrays.asList(stus, stus2);
System.out.println(listList);
//扁平映射:合并流
List<Student> collect = listList.stream().flatMap(e -> e.stream()).collect(Collectors.toList());
System.out.println(collect);
}
3.2.4 distinct():去重。
>>>>>> 基本数据类型、String类型
public static void main(String[] args) {
Stream<String> stream = Stream.of("!2", "2121", "2121");
List<String> collect = stream.distinct().collect(Collectors.toList());
System.out.println(collect);
}
>>>>>> 自定义数据类型去重
public class App3 {
static class Student{
private String name;
private int age;
@Override
public boolean equals(Object obj) {
Student target=(Student)obj;
if(this.getName().equals(target.getName())){
return true;
}
return false;
}
@Override
public int hashCode() {
return Objects.hash(name);
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
public static void main(String[] args) {
Stream<Student> studentStream = Stream.of(
new Student("小白", 12),
new Student("小白12", 18),
new Student("小白12", 20),
new Student("小白12", 20)
);
List<Student> collect = studentStream.distinct().collect(Collectors.toList());
System.out.println(collect);
}
}

3.2.5 sorted(Comparator):排序。
sorted() 方法用于对 Stream 中的元素进行排序。默认是自然顺序排序。
还可以提供自定义的 Comparator 参数来指定排序规则。
>>>> 默认是自然顺序排序。
public static void main(String[] args) {
//1、默认根据自然顺序排序
//2、基本数据类型,根据数值进行排序
//3、string数据类型,从左到右比较ascii值。
Stream<String> stringStream = Stream.of("523", "32323", "sasa");
List<String> collect1 = stringStream.sorted().collect(Collectors.toList());
System.out.println(collect1);
}
>>>> 指定字段排序
List<User> newList = users.stream()
.sorted(Comparator.comparing(User::getAge))
.collect(Collectors.toList());
>>>> 指定字段排序,并反转
List<User> newList2 = users.stream()
.sorted(Comparator.comparing(User::getAge).reversed())
.collect(Collectors.toList());
>>>> 先按年龄排,再按工资排,升序(thenComparing)
List<User> newList3 = users.stream()
.sorted(Comparator.comparing(User::getAge).thenComparing(User::getSalary))
.collect(Collectors.toList());
>>>> 自定义的 Comparator 参数来指定排序规则。
public class App3 {
static class Student{
private String name;
private int age;
@Override
public boolean equals(Object obj) {
Student target=(Student)obj;
if(this.getName().equals(target.getName())){
return true;
}
return false;
}
@Override
public int hashCode() {
return Objects.hash(name);
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
public static void main(String[] args) {
Stream<Student> studentStream = Stream.of(
new Student("小白", 12),
new Student("小白12", 18),
new Student("小白12", 20),
new Student("小白12", 20)
);
List<Student> collect = studentStream.sorted((a1,a2)->{
return a1.getAge()-a2.getAge();
}).collect(Collectors.toList());
System.out.println(collect);
}
}

3.2.6 limit(long n):截取前n个元素。
public static void main(String[] args) {
Stream<Student> studentStream = Stream.of(
new Student("小白", 12),
new Student("小白12", 18),
new Student("小白12", 20),
new Student("小白12", 20)
);
//取前两个元素
List<Student> collect = studentStream.limit(2).collect(Collectors.toList());
System.out.println(collect);
}
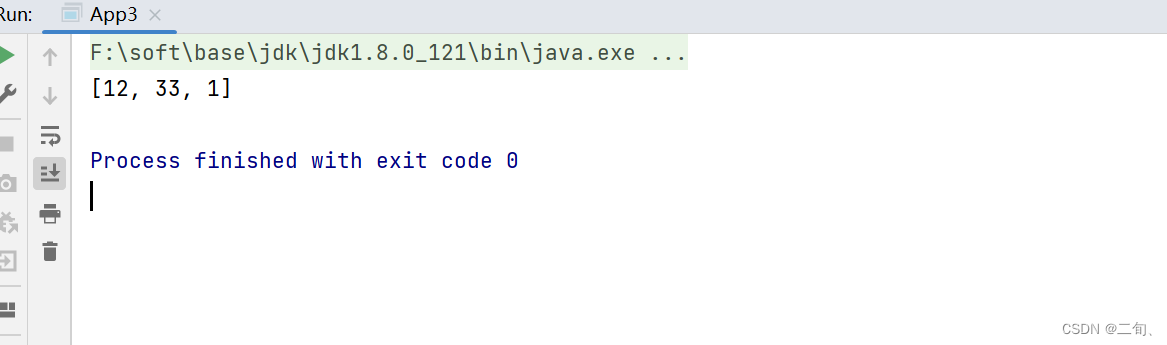
3.2.7 skip(long n):跳过前n个元素。
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 3, 12, 33, 1);
//跳过前两个元素
List<Integer> collect = list.stream().skip(2).collect(Collectors.toList());
System.out.println(collect);
}
3.3 Stream 操作方法 – 结束操作
Stream操作分为中间操作和结束操作:
+++ 结束操作:结束操作会触发Stream的实际计算,并返回结果。
1)遍历
forEach(Consumer<T>):遍历每个元素。
List<String> list = Arrays.asList("a", "b", "c");
list.stream().forEach(element -> System.out.println(element));
2)匹配
allMatch(Predicate<T>):匹配操作,所有都匹配,返回true
anyMatch(Predicate<T>):匹配操作,有一个匹配,返回true
noneMatch(Predicate<T>):匹配操作,没有匹配,返回true。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
boolean allMatch = list.stream().allMatch(n -> n > 0);
System.out.println(allMatch); // 输出: true
findFirst():返回第一个元素的Optional。
findAny():返回任意一个元素的Optional。
3)收集
collect(Collector<T, A, R>):收集元素到集合或其他容器。
collect() 方法用于将 Stream 中的元素收集到结果容器中,如 List、Set、Map 等。可以使用预定义的 Collectors 类提供的工厂方法来创建收集器,也可以自定义收集器。例如:
Stream<String> stream = Stream.of("apple", "banana", "cherry");
List<String> collectedList = stream.collect(Collectors.toList()); // 收集为 List
toArray():将 Stream 中的元素收集到一个数组中
List<String> list = Arrays.asList("a", "b", "c");
String[] array = list.stream().toArray(String[]::new);
3)聚合
reduce(BinaryOperator<T>):聚合操作。
reduce() 方法用于将 Stream 中的元素依次进行二元操作,得到一个最终的结果。
它接受一个初始值和一个 BinaryOperator 函数作为参数。例如:
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);
Optional<Integer> sum = stream.reduce((a, b) -> a + b); // 对所有元素求和
4)统计
max()用于寻找 Stream 中的最大元素。它同样接受一个 Comparator 作为参数,用于比较元素。
min()用于寻找 Stream 中的最小元素。它接受一个 Comparator 作为参数,用于比较元素。
List<Integer> list = Arrays.asList(3, 5, 1, 2, 4);
Optional<Integer> max = list.stream().max(Integer::compareTo);
max.ifPresent(System.out::println); // 输出: 5
count():计算元素数量。
List<String> list = Arrays.asList("a", "b", "c", "d");
long count = list.stream().count();
System.out.println(count); // 输出: 4
3.2.1 遍历
public static void main(String[] args) {
List<Integer> list = Arrays.asList(12, 34, 45);
list.stream().forEach(e->{
System.out.println(e);
});
}
3.2.2 匹配
public static void main(String[] args) {
List<Integer> list = Arrays.asList(12, 34, 45);
//所有元素都匹配,则返回true
boolean flag = list.stream().allMatch(e -> e > 10); //false
//任一元素匹配,则返回true
boolean flag2 = list.stream().anyMatch(e -> e > 10);//true
//所有元素都不匹配,则返回true
boolean flag3 = list.stream().noneMatch(e -> e > 10);//false
}
3.2.3 收集
public static void main(String[] args) {
List<Integer> list = Arrays.asList(12, 34, 45);
List<Integer> newList = list.stream().collect(Collectors.toList());
System.out.println(newList);
Integer[] newArr = list.stream().toArray(Integer[]::new);
System.out.println(newArr);
}
3.2.4 聚合
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3);
//初始值:2
//2+1+2+3
Integer reduce = list.stream().reduce(2, (a, b) -> a + b);
System.out.println(reduce);
//初始值:3
//3*1*2*3
Integer reduce2 = list.stream().reduce(3, (a, b) -> a*b);
System.out.println(reduce2);
}
3.2.4 统计
public class App5 {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3);
//最大值
Integer integer = list.stream().max(Integer::compare).get();
System.out.println(integer);
//最小值
Integer integer1 = list.stream().min(Integer::compare).get();
System.out.println(integer1);
long count = list.stream().count();
System.out.println(count);
}
3.4 Stream 操作方法 – 结束操作【Collectors收集器 】
Collectors 类提供了一组静态工厂方法,用于生成收集器(Collector)。
收集器主要用于将流中的元素累积到一个汇总结果中,例如集合(List)、映射(Map)、整数汇总等。
1、转换
toList()将流中的元素收集到一个 List 中。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> collected = numbers.stream().collect(Collectors.toList());
toSet()将流中的元素收集到一个 Set 中,去除重复元素。
Set<Integer> collected = numbers.stream().collect(Collectors.toSet());
toMap()将流中的元素收集到一个 Map 中,需要提供键映射函数和值映射函数。
Map<Integer, String> map = numbers.stream()
.collect(Collectors.toMap(
Object::hashCode,
Object::toString));
joining()将流中的元素连接成一个字符串。可以选择分隔符、前缀和后缀。
List<String> strings = Arrays.asList("Hello", "World", "!");
String result = strings.stream().collect(Collectors.joining(" ", "[", "]"));
// Result: "[Hello World !]"
reducing()
使用累加器对流中的元素进行规约操作,类似于 reduce 方法,但可以用于更复杂的聚合操作。
Optional<Integer> sum = numbers.stream()
.collect(Collectors.reducing((a, b) -> a + b));
// 结果:Optional[41]
2、分组
partitioningBy()将流中的元素按布尔条件分区为两个 Map。
Map<Boolean, List<Integer>> partitioned = numbers.stream()
.collect(Collectors.partitioningBy(n -> n % 2 == 0));
// 结果:{false=[1, 3, 5], true=[2, 4]}
groupingBy()
将流中的元素按某个分类函数分组为 Map。可以进一步使用收集器对每个组的元素进行收集。
Map<Integer, List<Integer>> groupedByMod = numbers.stream()
.collect(Collectors.groupingBy(n -> n % 3));
// 结果:{0=[3], 1=[1, 4], 2=[2, 5]}
groupingBy() + counting()
将流中的元素分组,并计算每个组的元素数量。
Map<Integer, Long> groupCount = numbers.stream()
.collect(Collectors.groupingBy(n -> n % 3, Collectors.counting()));
// 结果:{0=1, 1=2, 2=2}
3、统计
summarizingInt(), summarizingDouble(), summarizingLong()
收集流中元素的汇总统计信息,如计数、总和、平均值、最大值和最小值。
IntSummaryStatistics stats = numbers.stream().collect(Collectors.summarizingInt(Integer::intValue));
counting()计算流中元素的数量。
long count = numbers.stream().collect(Collectors.counting());
3.2.1 转换
public static void main(String[] args) {
List<Integer> list = Arrays.asList(4,1, 2, 3);
//转为list
List<Integer> collect = list.stream().collect(Collectors.toList());
System.out.println(collect);
//转为set
Set<Integer> collect1 = list.stream().collect(Collectors.toSet());
System.out.println(collect1);
//转为map
Map<String, Integer> maps = list.stream().collect(Collectors.toMap(e -> {
return "key:"+e;
}, e -> e));
System.out.println(maps);
}

public static void main(String[] args) {
List<Integer> list = Arrays.asList(4,1, 2, 3);
//拼接
String collect = list.stream().map(String::valueOf).collect(Collectors.joining(",", "开始", "结束"));
System.out.println(collect);
}

public static void main(String[] args) {
List<Integer> list = Arrays.asList(4,1, 2, 3);
Integer collect = list.stream().collect(Collectors.reducing(2, (a, b) -> {
return a + b;
}));
System.out.println(collect);
}

3.2.1 分组
public class App5 {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3);
//分组
Map<Boolean, List<Integer>> collect1 = list.stream().collect(Collectors.partitioningBy(x -> x > 1));
System.out.println(collect1);//{false=[1], true=[2, 3]}
//分组2
Map<String, List<Integer>> collect = list.stream().collect(Collectors.groupingBy(x -> {
if (x > 1) {
return "大于1";
} else {
return "小于1";
}
}));
System.out.println(collect);//{小于1=[1], 大于1=[2, 3]}
Map<Boolean, Long> collect2 = list.stream().collect(Collectors.groupingBy(x -> x > 1, Collectors.counting()));
System.out.println(collect2);//{false=1, true=2}
}
3.2.1 统计
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3);
Long collect = list.stream().collect(Collectors.counting());
System.out.println(collect);
//统计信息-double类型
DoubleSummaryStatistics collect1 = list.stream().collect(Collectors.summarizingDouble(e -> e));
System.out.println(collect1); //返回DoubleSummaryStatistics 对象
//统计信息-int类型
IntSummaryStatistics collect2 = list.stream().collect(Collectors.summarizingInt(e -> e));
System.out.println(collect2); // //返回IntSummaryStatistics 对象
//统计信息-long类型
LongSummaryStatistics collect3 = list.stream().collect(Collectors.summarizingLong(e->e));
System.out.println(collect3); //返回LongSummaryStatistics 对象
//求和
Integer collect4 = list.stream().collect(Collectors.summingInt(e -> e));
System.out.println(collect4);
}

3.5 Stream 操作方法 – 结束操作【Optional类】
Java8 新增了非常多的特性,而Optional 类就是其中一个新增的类。
+++ 什么Optional
Optional是一个容器类,它可以包含一个非空的对象,或者为空(空的Optional)。
它提供了一些有用的方法来避免显式的空检查。
+++ 创建Optional
Optional.of(value): 创建一个包含非空值的Optional。
Optional.ofNullable(value): 创建一个可能为空的Optional。
Optional.empty(): 创建一个空的Optional。
stream.findFirst():返回第一个元素的Optional。
stream.findAny():返回任意一个元素的Optional。
+++Optional常用方法
flatMap(Function<? super T,Optional<U>> mapper)
如果值存在,返回基于Optional包含的映射方法的值,
否则返回一个空的Optional
map(Function<? super T,? extends U> mapper)
如果有值,则对其执行调用映射函数得到返回值。如果返回值不为 null,则创建包含映射返回值的Optional作为map方法返回值。
否则返回空Optional。
filter(Predicate<? super <T> predicate)
如果值存在,并且这个值匹配给定的 predicate,
返回一个Optional用以描述这个值,否则返回一个空的Optional。
get()
如果在这个Optional中包含这个值,返回值。
否则抛出异常:NoSuchElementException
ifPresent(Consumer<? super T> consumer)
如果值存在则使用该值调用 consumer , 否则不做任何事情。
isPresent()
如果值存在则方法会返回true,
否则返回 false。
orElse(T other)如果存在该值,返回值, 否则返回 other。
orElseGet(Supplier<? extends T> other)如果存在该值,返回值, 否则返回 other。
3.2.1 flatMap、map、filter
public class App5 {
static class Person{
String name;
int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
public static void main(String[] args) {
List<Person> list = Arrays.asList(new Person("小红", 12), new Person("小侯", 122));
Optional<Person> first = list.stream().findFirst();
//flatMap映射
Optional<Integer> integer = first.flatMap(e -> Optional.of(e.getAge()));
System.out.println(integer.get());
//map映射
Integer integer1 = first.map(e -> e.getAge()).get();
System.out.println(integer1);
//filter
Optional<Person> person = first.filter(e -> e.getAge() > 12);
System.out.println(person);
}
}

3.2.2 ifPresent、isPresent
public class App5 {
static class Person{
String name;
int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
public static void main(String[] args) {
List<Person> list = Arrays.asList(new Person("小红", 12), new Person("小侯", 122));
Optional<Person> first = list.stream().findFirst();
//ifPresent
//如果元素存在,则执行
first.filter(e -> e.getAge() > 11).ifPresent(e->{
System.out.println("存在大于11的人");
System.out.println(e);
});
//判断元素是否存在,如果存在返回true
boolean present = first.isPresent();
System.out.println(present);
}
}
3.2.3 orElse、orElseGet
orElse:如果调用对象存在,则直接返回调用对象。如果调用对象不存在,则返回orElse中的对象。
public static void main(String[] args) {
List<Person> list = Arrays.asList(new Person("小红", 12), new Person("小侯", 122));
Optional<Person> first = list.stream().findFirst();
//如果存在则直接返回。
//如果不存在则返回orElse中的对象。
Person person = first.filter(e -> e.getAge() > 11).orElse(new Person("小黑", 13));
Person person2 = first.filter(e -> e.getAge() > 122).orElse(new Person("小黑", 13));
System.out.println(person);
System.out.println(person2);
}
orElseGet:如果调用对象存在,则直接返回调用对象。如果调用对象不存在,则返回orElse中的对象。
和orElse方法作用相同
public static void main(String[] args) {
List<Person> list = Arrays.asList(new Person("小红", 12), new Person("小侯", 122));
Optional<Person> first = list.stream().findFirst();
//如果存在则直接返回。
//如果不存在则返回orElse中的对象。
Person person = first.filter(e -> e.getAge() > 11).orElseGet(() -> {
return new Person("小黑", 32);
});
Person person2 = first.filter(e -> e.getAge() > 112).orElseGet(() -> {
return new Person("小黑", 32);
});
System.out.println(person);
System.out.println(person2);
}
3.2.4 完整的使用Optional处理Stream元素
假设我们有一个包含订单的列表,并且每个订单可能包含一个用户信息,我们想要找到某个订单并获取其用户的邮箱地址:
List<Order> orders = ...;
Optional<String> email = orders.stream()
.filter(order -> order.getId().equals(someOrderId))
.findFirst() // 找到第一个匹配的订单
.flatMap(Order::getUser) // 获取订单中的用户(如果有)
.map(User::getEmail); // 获取用户的邮箱(如果有)
email.ifPresent(System.out::println); // 如果邮箱存在,打印出来
在这个例子中,Order::getUser返回一个Optional<User>,而flatMap会处理这个嵌套的Optional,然后再通过map提取邮箱地址。
九、 Java 8 引入的日期和时间 API
四、Arrays工具类、Collections工具类
原文地址:https://blog.csdn.net/weixin_45602227/article/details/139484332
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!