Vitis AI - 量化流程详解
目录
1. 简介
想象一下,你有一个非常聪明的机器人朋友,它可以帮你做很多事情,比如预测天气。但是,这个机器人的大脑(我们可以把它想象成一个神经网络模型)需要很多能量和空间来思考(也就是进行计算和存储数据)。现在,如果我们想让这个机器人更小巧,更省电,还能快速做出预测,我们就需要采用一些特殂的技巧。
这时,Vitis AI 量化器就像一个魔法工具,它可以帮助机器人的大脑变得更高效。原来,机器人的大脑用一种非常详细(32位浮点)的方式来记住信息,这种方式虽然精确,但是需要很多空间和能量。Vitis AI 量化器通过一种叫做“量化”的魔法,把这些详细的信息转换成更简单(8位整数)的形式。这样做虽然会让信息变得不那么精确,但是我们可以通过一些技巧,让机器人的预测能力几乎不受影响。
这个魔法包括几个步骤:
- 自定义操作检查:先检查一下机器人的大脑里是否有些特殊的思考方式是我们需要特别注意的。
- 量化:用魔法把复杂的信息变成简单的形式。
- 校准:调整一下这个简化后的大脑,确保它还能准确地做出预测。
- 微调:进一步调整和优化,让机器人的大脑运行得更顺畅。
- 模型转换:最后,把这个优化后的大脑转换成一种特殊的格式,这样它就可以更容易地被部署到不同的地方,比如小巧的设备上。
通过这个过程,机器人的大脑变得更小,更省电,而且还能快速做出准确的预测。这样,我们就可以把这个聪明的机器人带到更多的地方去,让它帮助更多的人。
2. 具体流程
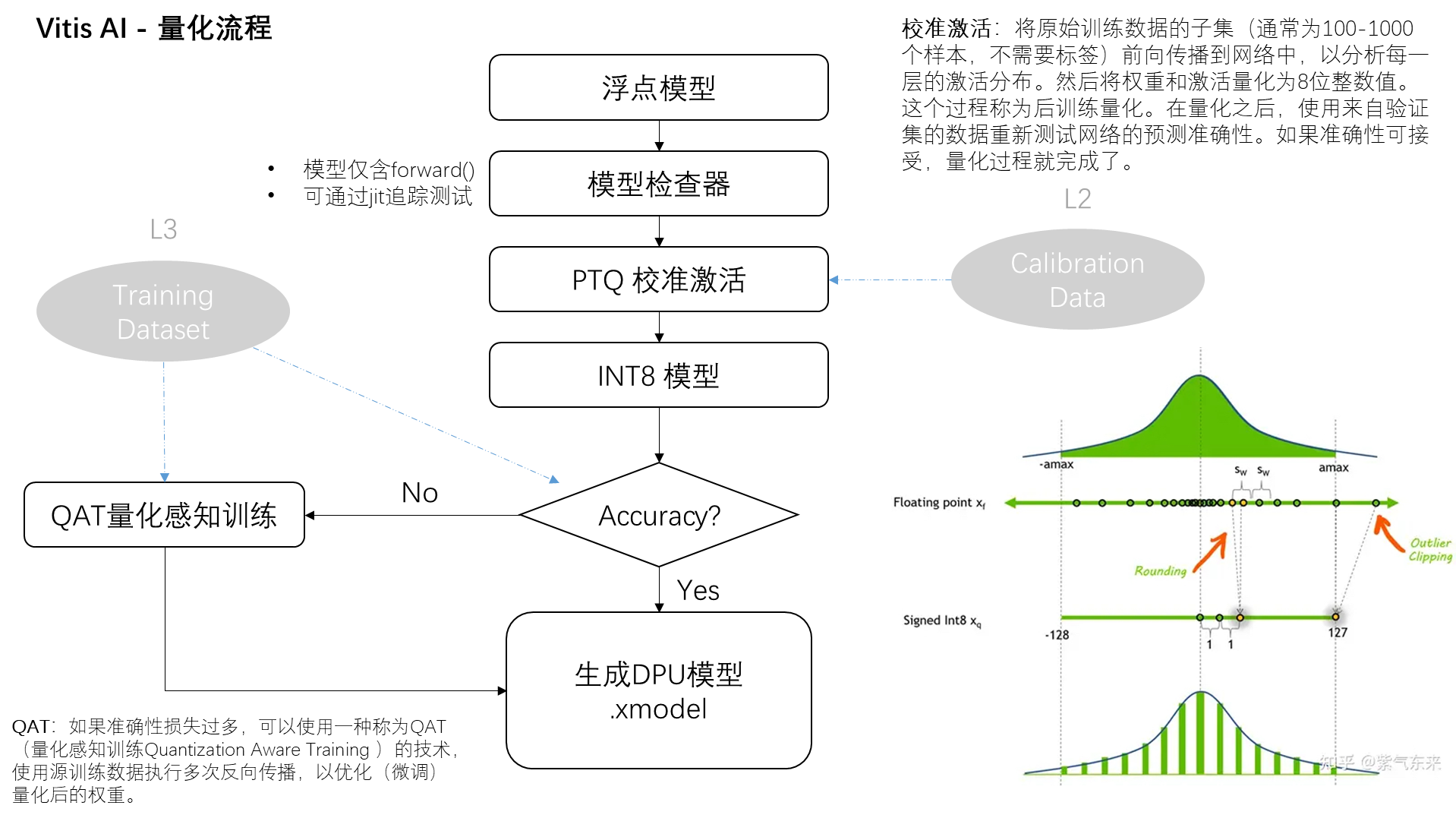
2.1 校准激活
当我们谈论“校准激活”这个过程时,我们实际上在讨论的是一个将神经网络模型调整为更高效版本的关键步骤,这一步骤是在所谓的后训练量化过程中进行的。让我们一步一步地详细解释这个过程:
- 选择数据样本
首先,我们需要从原始的训练数据中挑选出一个子集。这个子集不需要很大,通常包含100到1000个样本,而且不需要样本的标签(即我们不需要知道这些数据的正确答案是什么)。这个子集的目的是帮助我们理解模型在处理不同数据时的行为模式。
- 前向传播
接下来,我们将这个数据子集通过神经网络进行前向传播。前向传播简单来说,就是让数据通过网络的每一层,从输入层开始,一直到输出层。在这个过程中,网络的每一层都会对数据进行一些计算和转换,这些转换是由该层的权重(即该层学习到的参数)和激活函数(一种特定的数学函数,用于决定神经元是否应该被激活)控制的。
- 分析激活分布
当数据通过网络前向传播时,我们会分析网络中每一层的“激活分布”。激活分布基本上是指,在数据通过网络层时,神经元输出值的分布情况。这是非常重要的信息,因为它可以帮助我们了解数据是如何在网络中流动的,以及每一层是如何对数据进行处理的。
- 量化权重和激活
一旦我们有了关于激活分布的信息,我们就可以开始将权重和激活值从32位浮点数转换为8位整数值。这个过程称为量化。通过量化,我们可以显著减小模型的大小和计算需求,同时尽量保持模型的预测准确性不变。
2.2 量化感知训练
QAT(Quantization-Aware Training,量化感知训练)是一种特殊的神经网络训练方法,它在训练过程中就考虑到了模型最终会被量化(即权重和激活值会被转换成较低精度格式,如8位整数)的事实。通过这种方式,QAT旨在训练出一个在量化后仍能保持高性能的模型。
QAT的工作原理
- 在传统的训练过程中,模型通常在浮点数(如32位浮点数)环境下进行训练和优化。然而,当模型被量化(为了部署在资源受限的设备上)时,模型的性能可能会因为精度损失而下降。为了缓解这个问题,QAT采用了一种在训练过程中就模拟量化效果的方法。
- 模拟量化:在训练过程中,QAT通过在前向传播和反向传播时模拟权重和激活值的量化效果,使模型“意识到”其将在低精度环境中运行。这意味着模型的训练不仅要考虑如何最小化误差,还要学会在量化带来的限制条件下保持性能。
- 微调和优化:通过这种训练方式,模型可以在量化的约束下学习到更鲁棒的特征表示。此外,训练过程中还可以对量化操作进行微调和优化,比如调整量化参数(比如量化的比例因子),以进一步减小量化带来的误差。
- 减少性能损失:最终,通过QAT训练的模型在被量化到低精度格式后,其性能损失会比传统训练后直接量化的模型小很多。这意味着可以在保持较高预测精度的同时,享受量化带来的好处(如模型尺寸更小,推理速度更快,功耗更低)。
QAT的优势
- 高效的模型部署:通过QAT,可以更有效地将深度学习模型部署到资源受限的硬件上,如移动设备、嵌入式系统等。
- 性能和精度的平衡:QAT提供了一种有效的方法来平衡模型的性能和精度,使得在量化后的模型仍能保持接近其原始浮点数模型的预测精度。
- 加速推理过程:由于量化后的模型有更小的模型尺寸和更快的推理速度,QAT有助于加速模型的推理过程,使其更适合实时应用场景。
2.3 量化校准配置
量化校准配置文件的目录在 config_file = "./configs/mix_precision_config.json"
| 配置名 | 解释 | 选项 |
| convert_relu6_to_relu | 是否将ReLU6转换为ReLU | true、false |
| include_cle | 是否使用跨层均衡(cross layer equalization) | true、false |
| include_bias_corr | 是否使用偏差校正 | true、false |
| keep_first_last_layer_accuracy | 是否跳过对第一层和最后一层进行量化(未启用) | FALSE |
| keep_add_layer_accuracy | 是否跳过对"add"层进行量化(未启用) | FALSE |
| target_device | 部署量化模型的设备 | DPU、CPU、GPU |
| quantizable_data_type | 模型中要进行量化的张量类型 | |
| datatype | 用于量化的数据类型 | int、bfloat16、float16、float32 |
| bit_width | 用于量化的比特宽度 | |
| method | 用于校准量化的方法 | maxmin、percentile、entropy、mse、diffs |
| round_mode | 量化过程中的舍入方法 | half_even、half_up、half_down、std_round |
| symmetry | 是否使用对称量化 | true、false |
| per_channel | 是否使用通道级别的量化 | true、false |
| signed | 是否使用有符号量化 | true、false |
| narrow_range | 是否对有符号量化使用对称整数范围 | true、false |
| scale_type | 量化过程中使用的尺度类型 | float、poweroftwo |
| calib_statistic_method | 如果使用多批次数据获得不同的尺度,用于选择一个最优尺度的方法 | modal、max、mean、median |
2.4 quantization 函数
使用PyTorch框架和Xilinx Vitis AI量化工具(通过pytorch_nndct模块)的一个示例:
# 创建量化器对象,并获取量化模型
from pytorch_nndct.apis import torch_quantizer
quantizer = torch_quantizer(
quant_mode, model, (dummy_input), device=device, quant_config_file=config_file, target=target)
quant_model = quantizer.quant_model
loss_fn = torch.nn.CrossEntropyLoss().to(device)
val_loader, _ = load_data(…)
if finetune == True:
ft_loader, _ = load_data(…)
if quant_mode == 'calib':
quantizer.fast_finetune(evaluate, (quant_model, ft_loader, loss_fn))
elif quant_mode == 'test':
quantizer.load_ft_param()
acc1_gen, acc5_gen, loss_gen = evaluate(quant_model, val_loader, loss_fn)
if quant_mode == 'calib':
quantizer.export_quant_config()
if deploy:
quantizer.export_torch_script()
quantizer.export_onnx_model()
quantizer.export_xmodel()
代码的主要功能和步骤包括:
- 创建量化器对象:使用torch_quantizer函数创建一个量化器对象,这个对象用于管理模型的量化过程。这里需要指定量化模式(quant_mode),可以是calib(校函量化模式)或test(测试量化模型性能模式),模型本身,一个虚拟输入(dummy_input)用于模型推理,以及其他配置如设备(device),量化配置文件(quant_config_file)和目标平台(target)。
- 获取量化模型:通过量化器对象的quant_model属性获取量化后的模型。这个模型将用于后续的校准、微调和评估。
- 加载数据:加载验证数据集(val_loader),如果需要微调(finetune为True),也会加载微调数据集(ft_loader)。
- 微调和校准:如果设置了微调,根据量化模式执行相应的操作。在calib模式下,使用fast_finetune方法进行快速微调,以优化模型的量化参数;在test模式下,使用load_ft_param方法加载已经微调过的参数。
- 评估量化模型性能:使用evaluate函数评估量化模型在验证数据集上的性能,包括准确率(acc1_gen和acc5_gen)和损失(loss_gen)。
- 导出量化配置和模型:如果是calib模式,使用export_quant_config方法导出量化配置。此外,如果设置了部署(deploy为True),则会导出用于部署的模型,包括Torch Script(export_torch_script)、ONNX模型(export_onnx_model)和Xilinx特定的xmodel(export_xmodel)。
3. 总结
在当今技术快速发展的时代,我们追求的不仅是智能设备的高性能,同时也强调其能效和便携性。Vitis AI量化器便是在这样的背景下应运而生的一个工具,它通过将神经网络模型的数据精度从32位浮点数降低到8位整数,极大地缩减了模型的体积和计算需求,而通过精心设计的校准和微调过程,又能确保模型的预测准确性基本不受影响。这一过程不仅包括了校准激活、量化感知训练等关键步骤,还提供了详细的量化校准配置和实用的量化函数,以适应不同的部署需求。通过这种方式,Vitis AI量化器使得深度学习模型能够更加轻松地被部署到资源受限的设备上,无论是在移动设备、嵌入式系统还是其他平台,都能够实现快速、高效的智能计算,为用户带来更加丰富和流畅的体验。

原文地址:https://blog.csdn.net/DongDong314/article/details/140138394
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!