Web爬虫
📑前言
本文主要是【Web爬虫】——简单使用的文章,如果有什么需要改进的地方还请大佬指出⛺️
🎬作者简介:大家好,我是听风与他🥇
☁️博客首页:CSDN主页听风与他
🌄每日一句:狠狠沉淀,顶峰相见
Web爬虫
什么是 Web 爬虫?
- Web 爬虫是从网站中提取数据的过程。数据可以是 HTML、XML 或 JSON 等各种格式。Web 爬虫的应用包括研究、数据分析和自动化等方面。在 Python 中,使用第三方库如 BeautifulSoup 和 Requests 进行 Web 爬虫。
Web 爬虫是否合法?
- Web 爬虫的合法性取决于其目的和方法的使用。一般来说,只要不违反网站的服务条款或版权法,Web 爬虫就是合法的。但是,如果 Web 爬虫涉及访问私人数据或侵犯某人的知识产权,那么它就是非法的。
- Web 爬虫需要遵守道德规范。一些网站可能不希望其数据被爬取,重视尊重他们的意愿是非常重要的。此外,Web 爬虫可能会对网站的资源造成压力,因此使用 Web 爬虫时要注意责任。
可以被爬取的网页类型
一般来说,可以被爬取的网站类型可以分为两类:
-
静态网站,即网站的内容不会随时间变化而变化,如博客、新闻等网站。
-
动态网站,即网站的内容会随时间变化而变化,如在线商城、社交网站等网站。
在爬取不同类型的网站时,需要使用不同的爬虫工具和技术,比如对于静态网站,可以使用 requests 、urllib 等工具进行爬取;对于动态网站,一般需要使用 Selenium 等工具模拟浏览器行为进行爬取。
Python爬虫入门
基础用法
-
了解 HTML,CSS 和 JavaScript
-
安装第三方库(Requests 和 BeautifulSoup )
在进行网页内容解析时,需要了解 HTML、CSS 和 JavaScript 等前端技术的基础知识。HTML 是网页内容的结构化表示,CSS 用于控制网页的外观和样式,JavaScript 用于控制网页的交互行为。了解这些知识可以帮助我们更好地理解网页的结构和内容,从而更好地进行网页内容解析。
在开始网络抓取之前,我们需要安装一些必需的库。我们将在本章中使用 Requests 和 BeautifulSoup 库。
Requests 是一个常用于 HTTP 请求的 Python 库,在使用 Requests 库进行爬虫时,通常需要进行如下几个步骤:
-
发送请求,获取网页内容;
-
解析网页内容,提取需要的数据;
-
存储数据或进行后续处理。
Beautiful Soup 是另外一个 Python 库,用于从 HTML 和 XML 文件中提取数据。 它通常用于网页抓取。 它创建了一个解析树,便于在不同的节点之间轻松遍历。
# 下面语句在Jupyter Notebook环境中运行
!pip install requests beautifulsoup4
-
三种常见的 HTML 解析器
-
-
解析器名称 特点 html.parser Python 自带的标准库,可以进行基本的 HTML 解析。速度比较快,但是容错能力稍差。 lxml 速度较快,容错能力较好,支持 XPath 等高级解析技术,但需要安装 C 语言库和依赖库。 html5lib 支持最好的容错能力,可以处理非标准的 HTML 代码,但是解析速度相对较慢。
-
因此,在选择解析器时,需要根据实际需要进行选择。如果需要解析的是基本的 HTML 代码,可以选择 html.parser 解析器;如果需要解析的是复杂的 HTML 代码,可以选择 lxml 解析器;如果需要容错能力最好的解析器,可以选择 html5lib 解析器。
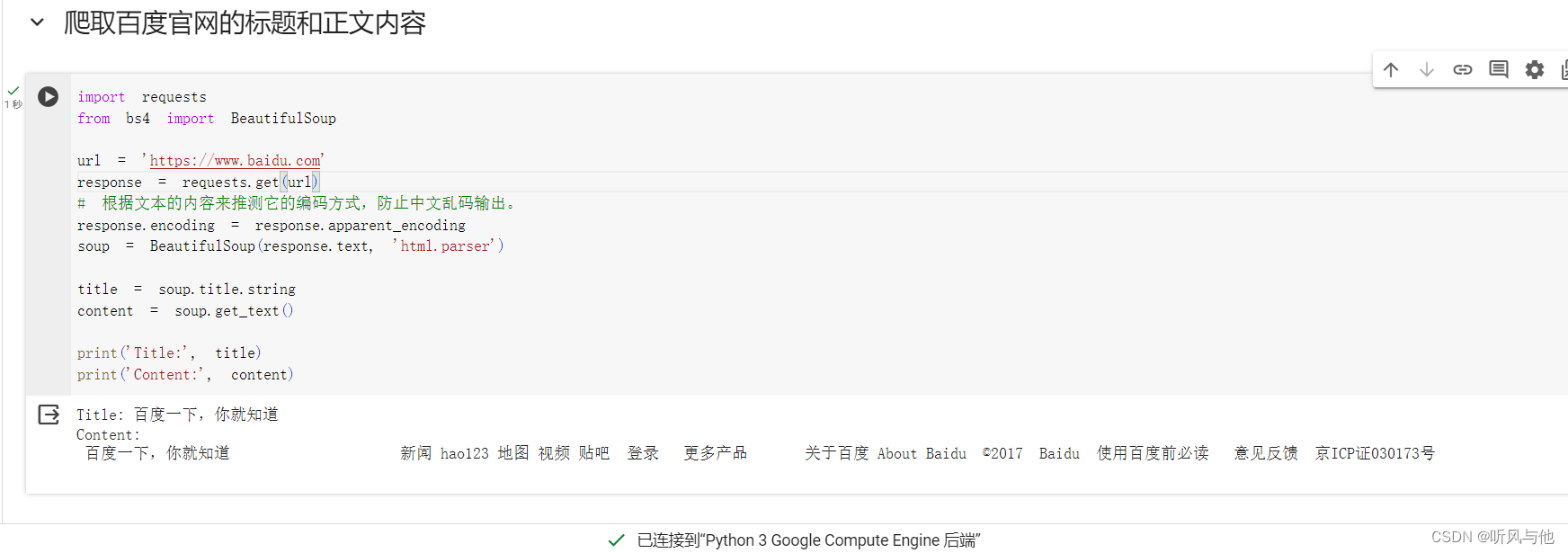
我们用 Requests 和 Beautiful Soup 爬取百度首页的标题和正文内容。
import requests
from bs4 import BeautifulSoup
url = 'https://www.baidu.com'
response = requests.get(url)
# 根据文本的内容来推测它的编码方式,防止中文乱码输出。
response.encoding = response.apparent_encoding
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.string
content = soup.get_text()
print('Title:', title)
print('Content:', content)
-
首先,我们导入了 Requests 和 BeautifulSoup 库。我们定义了一个 URL,并使用 requests.get() 方法获取页面内容。我们将获取到的内容传递给 BeautifulSoup 对象,并使用 ‘html.parser’ 进行解析。
-
然后,我们使用 soup.title.string 获取页面标题。同样地,我们使用 soup.get_text() 获取页面正文内容。
上机操作
-
博主操作网站地址:https://colab.research.google.com/
-
安装requests beautifulsoup4等依赖
-
爬取百度官网的标题和正文内容
友情推荐
- 这里推荐一个数据采集需要的代理池

📑文章末尾

原文地址:https://blog.csdn.net/weixin_61494821/article/details/137448593
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!