Go第三方框架--ants协程池框架
1. 背景介绍
1.1 goroutine
ants是站在巨人的肩膀上开发出来的,这个巨人是goroutine,这是连小学生都知道的事儿,那么为什么不继续使用goroutine(以下简称go协程)呢。这是个思考题,希望讲完本文大家可以有个答案。
go协程只涉及用户态的使用,不涉及内核态和两态的切换,所以非常轻便,通常一个协程大概只占用2k的内存,比线程更轻量级,而且其还有特别高效的GMP协程调度算法,使得go语言编写并发程序简单和高效。但是官方没有提供协程池包,虽然go协程有如此多的优点,go语言也支持垃圾自动回收,但是不断地对资源进行创建和回收是一种犯罪行为;为了更好的支持协程资源空间重复使用、并发控制、提升性能,并为开发者提供更简便和使用的功能,有大量的第三方协程池框架应运而生,ants是其中的佼佼者。
2. ants简介
ants是github托管的一个高效的协程池库,其star已经有12k了,足见其受欢迎的程度。本ants版本使用的是v2.8.2 目前最新版是2.9.1。其主要committer是潘建锋,根据公开资料(应该没侵犯隐私)曾任职腾讯,现在在亚马逊上班,未婚,个人博客。八卦完了,现在看看ants的发展史吧。ps:为了还原历史,下文引用ants的readme 相信很多博客都介绍过了,纯属凑字数。
2.1 简介
ants是一个高性能的 goroutine 池,实现了对大规模 goroutine 的调度管理、goroutine 复用,允许使用者在开发并发程序的时候限制 goroutine 数量,复用资源,达到更高效执行任务的效果。
2.2 功能
- 自动调度海量的 goroutines,复用 goroutines
- 定期清理过期的 goroutines,进一步节省资源
- 提供了大量有用的接口:任务提交、获取运行中的 goroutine 数量、动态调整 Pool 大小、释放 Pool、重启 Pool
- 优雅处理 panic,防止程序崩溃
- 资源复用,极大节省内存使用量;在大规模批量并发任务场景下比原生 goroutine 并发具有更高的性能
- 非阻塞机制
2.3 ants是如何运行的
流程图
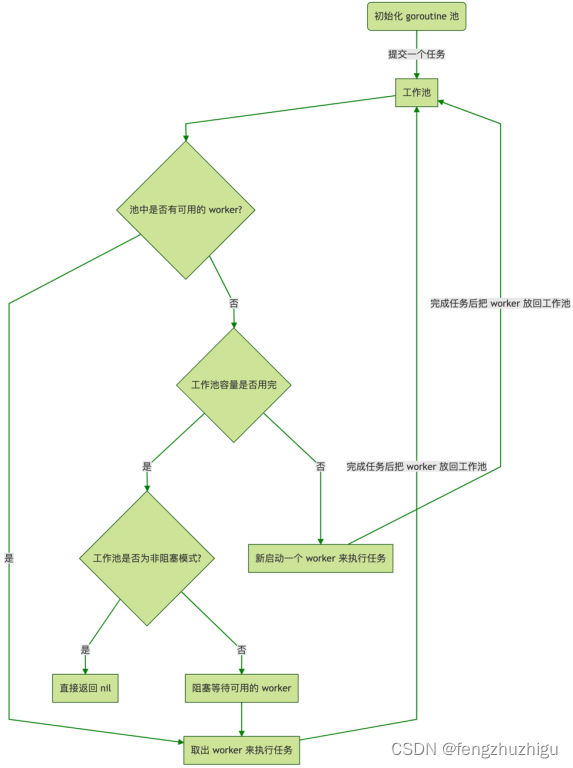
2.4 使用
// demoPoolFunc1 执行任务
func demoPoolFunc1() {
time.Sleep(2 * time.Millisecond)
}
// TestAntsPoolWaitToGetWorker ants运行简单例子.
func TestAntsPoolWaitToGetWorker(t *testing.T) {
var wg sync.WaitGroup
p, _ := NewPool(1000) // 初始化一个协程池 容量是 1000
defer p.Release() // 执行成功手动释放协程池
for i := 0; i < 10000; i++ { // 启动10000个任务 让协程池来运行
wg.Add(1) // wg++
_ = p.Submit(func() { // 提交任务
demoPoolFunc1()
wg.Done() // 完成后 wg--
})
}
wg.Wait() // 阻塞等待任务完成
}
可以看到 暴露给外面的 就是 图2.3的 pool池初始化、任务提交和pool池回收 剩下的 都在水面之下 . ps:submit 也可以使用协程启动 这样 下方代码中出现的锁 就可以解释的通了。
以下 源码讲解就拿上述代码为例子
ps: 还有一些内容 请看客移步代码的readme
3. 几种重要的结构体
3.1 pool
pool核心结构体,其结构体 如下
// Pool 接受来自客户端的任务,通过循环利用 goroutines 限制了总数量为给定值。
type Pool struct {
// pool 的容量,负值表示 pool 容量无限,使用无限 pool 是为了避免由于 pool 的嵌套使用(向同一个 pool 提交任务,该任务又向同一个 pool 提交新任务)可能引起的无限阻塞问题。
capacity int32
// 当前运行的 goroutines(goworker的items长度) 数量。
running int32
// 保护 worker 队列的锁。
lock sync.Locker
// 存储可用 worker 的切片,是任务执行器的队列,是一个接口
workers workerQueue
// 状态用于通知 pool 关闭自身。
state int32
// 等待获取空闲 worker 的条件。
cond *sync.Cond
// workerCache 池化技术 不断生成 新worker , 但是他不是 2.3工作池。它在woker数量没达到容量阈值时,
// 会不断生成。一旦达到了,就不会再工作,因为这时 workerStack 中的 items 满了后会自己维持(因为一般不会有过期,又有容量限制),后续会讲解。
// 直到将过期的worker放入队列时,woker数量减少,才又继续工作生成新的worker。但是 一般情况下 过期时间都特别长,当过期时间短时,
// 工作池就是 workers + workerCache 这两个属性 在不断向items补充 gowoker。workers回收可用的goworker,workerCache 补齐不足容量的部分。
// 但是一般不会让goworker过期,所以为了方便 我们一般吧 items叫做工作池
workerCache sync.Pool
// waiting 是已经在 pool.Submit() 上被阻塞的 goroutines 数量(因为本2.3例子没有使用协程提交submit,所以最大为1),受 pool.lock 保护。
waiting int32
purgeDone int32
stopPurge context.CancelFunc // cancel 用来停止 goPurge 函数
ticktockDone int32
stopTicktock context.CancelFunc // cancel 用来停止 goTicktock 函数
now atomic.Value // 存储现在时间
// 存放一些参数 过期时间 最大阻塞任务等
options *Options
}
3.2 workerStack
任务的执行队列
type workerStack struct {
items []worker // 工作池, 对应 2.3 图中的 工作池 每个工作池 运行一个 协程
expiry []worker // 已经过期的任务执行器队列(工作池)
}
这个结构体实现了 workerQueue 结构体的接口 也就是 3.1pool里的 workerQueue 。
type workerQueue interface {
len() int
isEmpty() bool
insert(worker) error // 向工作池中 加入一个 任务执行器
detach() worker // 从工作池中 拿到一个 任务执行器
refresh(duration time.Duration) []worker // 清理掉过期的goworker
reset() // 重置 将所有goworker 任务执行完毕后 结束
}
接口中都是操作工作执行器(goworker)队列的一些函数
3.3 goWorker
goWorker 是实际任务执行器
// goWorker 是实际执行任务的执行器,
// 它启动一个 goroutine 来接受任务并执行函数调用。
type goWorker struct {
// 拥有该 worker 的池 也就是 3.1中的 pool, 将pool传给 worker 以便调用pool的函数和属性。
pool *Pool
// task 存放 执行任务的chan。 将任务输送到chan来执行。
task chan func()
// lastUsed 在将 worker 放回队列时将更新,有多个任务则时间是最后一个任务执行时间。
lastUsed time.Time
}
其实现了下面的 worker 结构体
type worker interface {
run() // 运行 goworker
finish() // 让任务执行完毕后 结束goworker
lastUsedTime() time.Time
inputFunc(func()) // 向 goworker 中的 chan 传递任务
inputParam(interface{})
}
接口中都是操作工作执行器的一些函数
ps: 之所以需要执行器和其队列的接口 是因为有不同的执行器和执行器队列,例如goWorkerWithFunc执行器和 loopQueue执行器队列,因为不是本文重点不做介绍,但其大体执行逻辑是一致的,感兴趣的看官可以自行研究。
如上我们就可以猜到执行的一个大体的脉络,控制逻辑是 pool–>workerStack(2.3中的工作池,主要是属性items)–>goworker(worker 任务执行器),接下来我们来看下源码 验证下
4. ants 协程池初始化
见 2.4 代码部分 p, _ := NewPool(1000) ,这样可以初始化一个pool池。我们看下其源码,
// NewPool generates an instance of ants pool.
func NewPool(size int, options ...Option) (*Pool, error) {
if size <= 0 {
size = -1
}
opts := loadOptions(options...) // opts 没有传 跳过
if !opts.DisablePurge { // 值是 true 走这里
if expiry := opts.ExpiryDuration; expiry < 0 {
return nil, ErrInvalidPoolExpiry
} else if expiry == 0 {
opts.ExpiryDuration = DefaultCleanIntervalTime // 过期时间
}
}
if opts.Logger == nil { // logger 选择默认的
opts.Logger = defaultLogger
}
p := &Pool{ // 初始化 pool 将size赋值给capacity
capacity: int32(size),
lock: syncx.NewSpinLock(), // 这里是自己实现的指数退避的自旋锁,为啥要自己实现我想可能是官方的性能作者不满意吧 有空细研究下
options: opts,
}
p.workerCache.New = func() interface{} { // 从缓存池中可以获取新的 goworker
return &goWorker{
pool: p,
task: make(chan func(), workerChanCap), // 创建一个 大小是1的任务chan,注意大小是0和1不一样,感兴趣的自行gpt3.5
}
}
if p.options.PreAlloc { // false 不走这里
if size == -1 {
return nil, ErrInvalidPreAllocSize
}
p.workers = newWorkerQueue(queueTypeLoopQueue, size)
} else {
p.workers = newWorkerQueue(queueTypeStack, 0) // 初始化 workerStack(工作池) 结构体 大小是0
}
p.cond = sync.NewCond(p.lock)
p.goPurge() // 启动一个协程 不断检查执行器队列,将过期的执行器(goworker)的任务释放,任务对应的任务执行器放入 pool中,工作执行器协程退出;
p.goTicktock() // 启动协程更新pool的时间,用来更新 goworker的最后使用时间
return p, nil
}
到这里 一个新的 pool就建立起来了 ,这其中需要进一步剖析的是 p.goPurge() 其 值得关注的调用链 如下
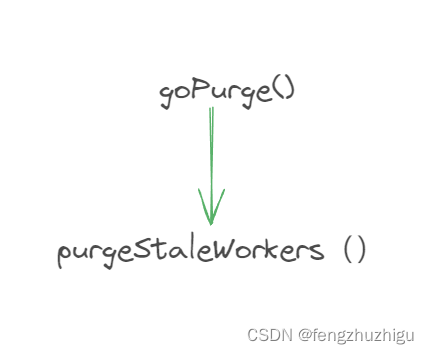
purgeStaleWorkers(ctx context.Context) 函数代码如下
// 启动一个协程 不断检查执行器队列,将过期的执行器的任务释放,任务对应的任务执行器放入 workercache 中,工作执行器协程退出;
func (p *Pool) purgeStaleWorkers(ctx context.Context) {
ticker := time.NewTicker(p.options.ExpiryDuration) // 使用过期时间 建一个 ticker
defer func() {
ticker.Stop()
atomic.StoreInt32(&p.purgeDone, 1)
}()
for {
select {
case <-ctx.Done():
return
case <-ticker.C: // 到了过期时间 就开始执行 查找过期woker的逻辑
}
if p.IsClosed() {
break
}
var isDormant bool
p.lock.Lock() // 为什么加锁 (因为submit可以使用 协程启动)
staleWorkers := p.workers.refresh(p.options.ExpiryDuration) // 将 items里面 过期的任务队列 复制到 expires队列里 并 返回
n := p.Running()
isDormant = n == 0 || n == len(staleWorkers)
p.lock.Unlock()
// Notify obsolete workers to stop.
// This notification must be outside the p.lock, since w.task
// may be blocking and may consume a lot of time if many workers
// are located on non-local CPUs.
for i := range staleWorkers { // 将过期队列 依次调用 finish() 使得本 woker停止(因为本worker的任务执行完毕后 会 阻塞,当调用finish()时,会给chan传递一个 nil 使得任务停止 详细 请看 worker.run()) 并加入workercache 中
staleWorkers[i].finish()
staleWorkers[i] = nil
}
// There might be a situation where all workers have been cleaned up (no worker is running),
// while some invokers still are stuck in p.cond.Wait(), then we need to awake those invokers.
if isDormant && p.Waiting() > 0 { // 如果 不存在运行的协程(调用 run()会启动一个协程 数量 跟执行器相等 可以看做一个协程就是一个运行着的执行器 也就是 len(items)),或者 等待的协程>1 就广播 通知等待的协程来运行(主要是来提交任务)
p.cond.Broadcast()
}
}
}
到这里 goPurge()就讲解 完毕了 。
5. 任务提交
任务 提交 到 任务 处理的 调用链 如下
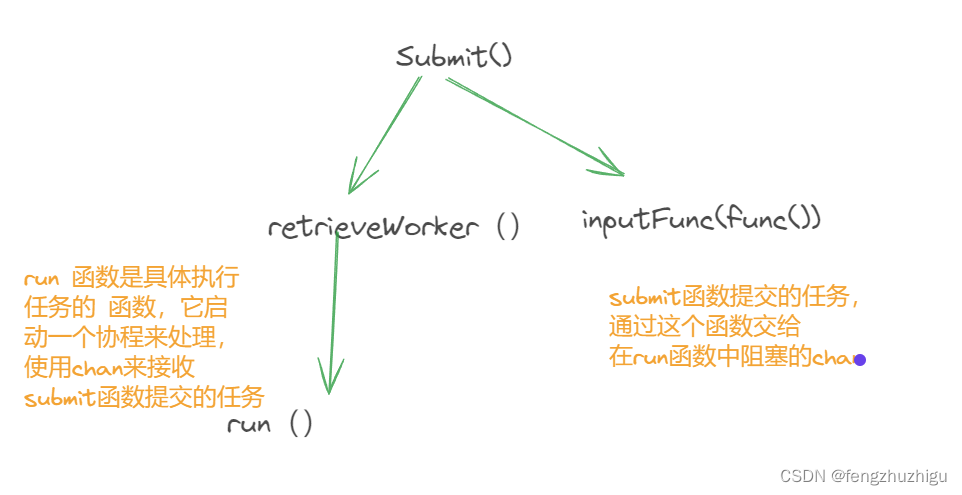
run 函数是具体执行 任务 的函数,它启动一个协程来处理submit函数提交的任务
池化完毕后 就是 任务提交 p.Submit(…),这是核心执行逻辑 见 2.3 中 提交后 后续的执行逻辑都在这个函数里。 老规矩,我们继续追踪源码
5.1 任务提交
func (p *Pool) Submit(task func()) error { // 其接受一个 任意类型的 任务
if p.IsClosed() { // 如果协程池关闭了 则报错
return ErrPoolClosed
}
w, err := p.retrieveWorker() // 获取一个工作执行器(用 goworker 简称),规则:大体逻辑 如果工作池有,就拿来用,如果没有就新建(还有阻塞等)见 2.3流程图
if w != nil {
w.inputFunc(task) // 将 任务 加入到 获取的 goworker 的任务chan 中(这时 goworker的run()函数可能正在 chan处阻塞),开始执行任务。大家思考下这边会不会阻塞??
}
return err
}
其中 retrieveWorker() (w worker, err error) 函数如下
5.2 任务获取
// 这个应该是核心执行逻辑,返回一个可以使用的w或者阻塞
// retrieveWorker returns an available worker to run the tasks.
func (p *Pool) retrieveWorker() (w worker, err error) {
p.lock.Lock()
retry:
// First try to fetch the worker from the queue.
if w = p.workers.detach(); w != nil { // items(工作池) 头部goworker出栈 赋值给 w,如果有空闲的w(w!=nil) 则返回
p.lock.Unlock()
// 为什么得到 w 后不run() 而是直接返回 ps: 因为只要可以获取到 工作执行器 则 必定 有一个 协程正在运行,否则这个执行器就是过期的退出了 不在 items中。
return
}
// If the worker queue is empty and we don't run out of the pool capacity,
// then just spawn a new worker goroutine.
// 如果工作队列是空的或者 正在跑的 协程数(items大小)没达到 容量,任务刚启动时,会走这边,一旦items满了后,基本不走这边 要么从 items直接获取任务(上面代码),要么阻塞(下方代码 p.addWaiting)
if capacity := p.Cap(); capacity == -1 || capacity > p.Running() {
p.lock.Unlock()
w = p.workerCache.Get().(*goWorker) // 从pool缓冲池中获取一个 工作队列,注意 workerCache 不是工作池,而是 对应2.3 “新启动一个 woker 来执行任务 ”的前半句话。
w.run() // 这边 开始 启动协程 处理 任务。思考题:items数量和协程数量是否是一致的(一致)
return
}
// Bail out early if it's in nonblocking mode or the number of pending callers reaches the maximum limit value.
if p.options.Nonblocking || (p.options.MaxBlockingTasks != 0 && p.Waiting() >= p.options.MaxBlockingTasks) {
p.lock.Unlock()
return nil, ErrPoolOverload
}
// Otherwise, we'll have to keep them blocked and wait for at least one worker to be put back into pool.
p.addWaiting(1) //能走到这里,证明items 达到最大容量了。
p.cond.Wait() // block and wait for an available worker// 程序阻塞等待唤醒,任务执行完毕或者goworker过期都会唤醒。
p.addWaiting(-1)
if p.IsClosed() {
p.lock.Unlock()
return nil, ErrPoolClosed
}
goto retry // 被唤醒后 走到 retry 重新开始 为任务选 gowoker
}
在上述代码 w = p.workerCache.Get().(*goWorker) 处,我们可以发现 ,每次从缓存池获取一个 goworker 都要调用 run()函数,来启动goworker,这个函数才是执行任务的核心代码。它会启动一个协程 并采用chan阻塞等待任务得到来。下面介绍run()函数
5.3 任务执行
这里开始执行任务
func (w *goWorker) run() {
w.pool.addRunning(1) // 运行的 goworker 数量+1
go func() {
defer func() { // 当 goworker过期 或者 批量任务执行完毕 调用 p.Release(), 下方 for 循环 退出,然后则调用 本defer
w.pool.addRunning(-1) // 正在运行的 goworker 数量-1
w.pool.workerCache.Put(w) // 将不用的 goworker 放入 缓存池中
if p := recover(); p != nil {
if ph := w.pool.options.PanicHandler; ph != nil {
ph(p)
} else {
w.pool.options.Logger.Printf("worker exits from panic: %v\n%s\n", p, debug.Stack())
}
}
// Call Signal() here in case there are goroutines waiting for available workers.
w.pool.cond.Signal() // 唤醒一个 在 retrieveWorker()函数 中 代码p.cond.Wait() 处阻塞的程序,开始提交任务
}()
for f := range w.task { // 从 5.1submit()函数的 inputFunc(func())调用 处获取任务
if f == nil { // 如果 chan 传递的是 nil (调用 finish()),则这个goworker退出
return
}
f() // 开始执行任务 执行2.4中例子中的 demoPoolFunc1()
if ok := w.pool.revertWorker(w); !ok { // 任务执行完毕,将本goworker 入栈 items ,这时 协程不退出 继续for循环,这边就实现了 重复利用。
return
}
}
}()
}
任务执行完成后,对应的goworker需要入栈 在代码 w.pool.revertWorker(w) 处执行,下面介绍下这个函数
5.4 工作执行器(goworker)入栈
本小结主要是将闲下来的goworker入栈 涉及到 revertWorker(worker *goWorker) 函数,其代码如下:
// revertWorker puts a worker back into free pool, recycling the goroutines.
// 直接翻译: 将goworker放入 items中,循环使用这个协程
func (p *Pool) revertWorker(worker *goWorker) bool {
if capacity := p.Cap(); (capacity > 0 && p.Running() > capacity) || p.IsClosed() {
p.cond.Broadcast()
return false
}
worker.lastUsed = p.nowTime() // 更新goWorker协程的最后使用时间
p.lock.Lock()
// To avoid memory leaks, add a double check in the lock scope.
// Issue: https://github.com/panjf2000/ants/issues/113
if p.IsClosed() {
p.lock.Unlock()
return false
}
if err := p.workers.insert(worker); err != nil { // 将 goWorker 入栈
p.lock.Unlock()
return false
}
// Notify the invoker stuck in 'retrieveWorker()' of there is an available worker in the worker queue.
p.cond.Signal() /// 唤醒一个 在 retrieveWorker()函数 中 代码p.cond.Wait() 处阻塞的程序(如果是协程启动的submit,则将此协程唤醒)
p.lock.Unlock()
return true
}
到此 我们2.3的流程图涉及到的所有模块都梳理完毕,接下来就等着任务执行完毕后,将协程池释放。
6. 协程池释放
释放所有跟pool相关的资源,我们来梳理下 有几处在运行或阻塞的程序
a. 提交任务时,当多于items容量时,阻塞在 5.2 函数的 p.cond.Wait() 处(要是submit是协程提交的话这里阻塞更多,,现在最多阻塞1个)
b. 新建 池时 启动的两个协程 见 标题4
c. submit提交任务时,启动的 items里的协程
所以有四处需要关闭,我们看下源码
func (p *Pool) Release() {
if !atomic.CompareAndSwapInt32(&p.state, OPENED, CLOSED) { // 使用 cas算法 将 pool状态 修改为关闭,为续资源关闭做准备。
// 则所有协程任务执行完毕后,入 items 队列时会退出见 revertWorker() 函数 第一行)
// 所有阻塞的协程 会退出(见 5.2 retrieveWorker()函数 最后部分 p.IsClosed()),其他见 对 p.IsClosed() 的调用
return
}
if p.stopPurge != nil { // 停止 goPurge()函数 对应 --> b
p.stopPurge()
p.stopPurge = nil
}
p.stopTicktock() // 对应 --> b
p.stopTicktock = nil
p.lock.Lock()
p.workers.reset() // 将所有goworker停止 对应 --> c
p.lock.Unlock()
// There might be some callers waiting in retrieveWorker(), so we need to wake them up to prevent
// those callers blocking infinitely.
p.cond.Broadcast() // 广播给 在 p.cond.wait()处阻塞的协程 继续运行,后续调用 p.IsClosed()退出。 这里对应 --> a
到这里ants的真个生命流程就梳理完毕了。
7.总结
感觉还是得梳理源码,才能有长进。这次只是梳理了最常用的核心部分,还有其他一些功能或结构体没有梳理到,希望有时间再添加吧。由于本人水平有限,本次梳理难免有疏漏,还请各位大佬指正,互相学习,谢谢。
原文地址:https://blog.csdn.net/u013915286/article/details/137376751
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!