【OpenCV】基础操作学习--实现原理理解
读取和显示图像
基本操作
- cv2.imread(filename , flags):文件中读取图像,从指定路径中读取图像,返回一个图像数组(NumPy数组)
- filename:图像文件的路径
- flags:指定读取图像的方式
- cv2.IMREAD_COLOR(默认为1):以彩色图像读取,忽略透明度通道
- cv2.IMREAD_GRAYSCALE(0):以灰度图像读取
- cv2.IMREAD_UNCHANGED(-1):包含图像中alpha通道
- cv2.imshow():窗口中显示图像,从新窗口中显示图像
- cv2.waitkey():控制图像显示事件,参数值是毫秒,0表示无限等待
- 因为运行环境在云服务器上,所以无法实时显示图像,后期补充测试
代码实现1
#读取与显示图像
import cv2
#读取
img = cv2.imread('your_image.jpg')
#检测是否加载成功
if img is None:
print("图像读取失败,检查图像路径是否存在")
else:
#显示图像
cv2.imshow('显示窗口',img)
#等待任意按键
cv2.waitKey(0)
cv2.destroyAllWindows()
代码实现2: 根据三种读取方式,分别读取图片


import cv2
# 读取彩色图像
# color_img = cv2.imread('your_image.jpg', cv2.IMREAD_COLOR)
# cv2.imwrite('color.jpg',color_img)
# 读取灰度图像
# gray_img = cv2.imread('your_image.jpg', cv2.IMREAD_GRAYSCALE)
# cv2.imwrite('gray.jpg',gray_img)
# # 读取包含 alpha 通道的图像
unchanged_img = cv2.imread('your_image.png', cv2.IMREAD_UNCHANGED)
cv2.imwrite('unchange.jpg',unchanged_img)实现理解
- 图像读取逻辑:底层调用图像解码库来读取图像文件,然后将其转换为NumPy数组
- 图像显示逻辑:创建一个窗口,然后调用GUI库(例如Qt)将图像数据渲染到屏幕上
计算机图像学相关知识
像素与颜色空间
- 像素:图像中的基本元素,通常表示为数值的集合,代表图像在某个位置上的颜色和亮度
- 图像的最小单位,类似于拼图中的一小块,拼在一起就是一个整体的图像
- 颜色空间:描述颜色的模型,使用坐标系或者子空间来表示颜色,例如RGB、BGR、HSV等
- 不同描述颜色的方法,相似与不同语言但是最终表示的都是相同含义
颜色通道
- RGB颜色:Red , Green , Blue三个颜色通道组成
- 每个通道的数值是0-255的整数,相对应着表示颜色强弱
- BGR颜色:OpenCV默认的颜色模型
- OpenCV中使用BGR颜色主要是因为需要与早期设计的图形格式兼容
- 可以通过函数对图片的格式进行变换
像素与图像的理解

import cv2
# 读取彩色图像
img = cv2.imread('your_image.jpg')
# 查看图像的尺寸和像素值
print("图像尺寸:", img.shape)
print("像素值示例:", img[0, 0]) # 输出第一个像素的 BGR 值
# 转换为灰度图像
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
print("灰度图像尺寸:", gray_img.shape)
print("灰度像素值示例:", gray_img[0, 0]) # 输出第一个像素的灰度值
# 保存灰度图像
cv2.imwrite('gray_image.jpg', gray_img)
保存图像
基本操作
- cv2.imwrite(filename , img , params = None):将图像保存为文件,也就是将图像保存为指定格式,最终格式取决于设定拓展名
- filename:保存的文件名,其格式是由拓展名决定的
- img:需要保存的图像对象
- params:可选参数,用于设置特定格式的编码参数
代码实现


参数设置
import cv2
# 读取图像
img = cv2.imread('your_image.jpg')
# 保存为不同格式
cv2.imwrite('output_image.jpg', img, [int(cv2.IMWRITE_JPEG_QUALITY), 90]) # JPEG,质量90
cv2.imwrite('output_image.png', img, [int(cv2.IMWRITE_PNG_COMPRESSION), 5]) # PNG,压缩级别5
print("图像已保存。")
import cv2
img = cv2.imread('your_image.jpg')
# JPEG 质量90
cv2.imwrite('output_image.jpg',img,[int(cv2.IMWRITE_JPEG_QUALITY),90])
cv2.imwrite('output_image.png',img,[int(cv2.IMWRITE_PNG_COMPRESSION),5])参数调整总结
- JPEG质量参数:数值越高,图像质量越好,相应的文件体积越大
- PNG压缩级别:数值越高,压缩率越高,文件体积也就越小
计算机图形学知识补充
图像编码与压缩
- 无损压缩:例如PNG,图像的质量不受损失,但是文件的体积较大
- 有损压缩:例如JPEG,会舍弃部分的像素来达到压缩的目的,文件体积会更小
保存图像函数实现分析
图像保存会调用编码库,会将NumPy数组编码为指定格式的图像文件,其中编码参数params传递给编码器,从而控制压缩质量和压缩级别
调整图像大小
基本操作
- cv2.resize(src , dsize , fx=0 , fy=0 , interolation = cv2.INTER_LINEAR):按照指定的尺寸或者缩放比例去调整图像大小
- 参数
- src:输出图像
- desize:输出图像的尺寸(宽、高)
- fx,fy:水平和垂直方向的缩放因子
- interpolation:插值方法
- 插值方法
cv2.INTER_NEAREST: 最近邻插值,速度快,质量低cv2.INTER_LINEAR: 双线性插值,默认值,适用于放大cv2.INTER_AREA: 区域插值,适用于缩小cv2.INTER_CUBIC: 三次插值,质量较高,速度较慢
- 参数
代码实现

#调整尺寸
import cv2
img = cv2.imread('your_image.jpg')
#按比例将其缩放成原来的一半
resized_img = cv2.resize(img,None,fx=0.5,fy=0.5,interpolation=cv2.INTER_AREA)
#保存查看
cv2.imwrite('resized_image.jpg',resized_img)参数调整测试

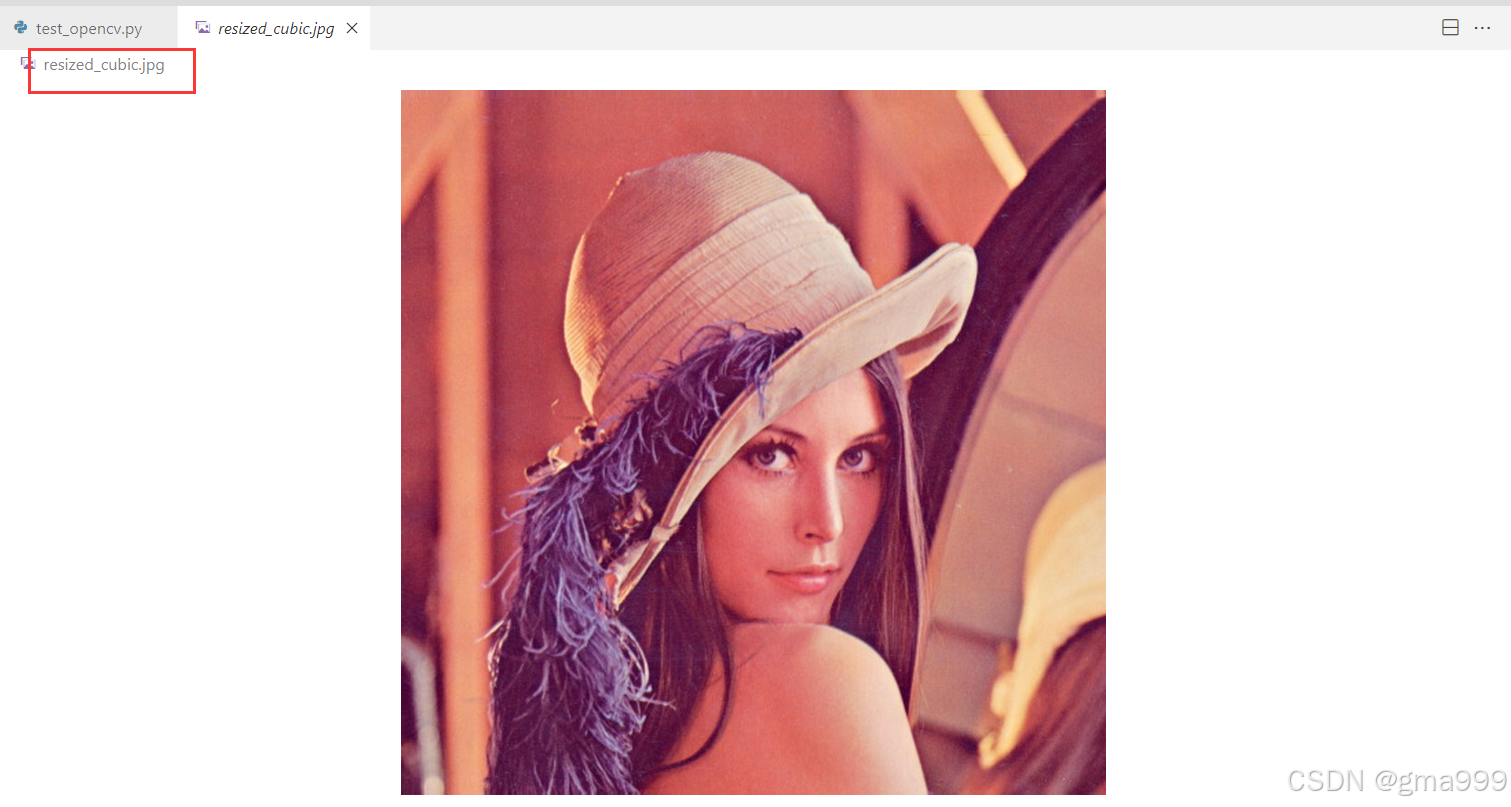
import cv2
# 读取图像
img = cv2.imread('your_image.jpg')
# 指定输出尺寸
resized_img_fixed = cv2.resize(img, (800, 600), interpolation=cv2.INTER_LINEAR)
# 使用缩放因子
resized_img_scale = cv2.resize(img, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_LINEAR)
# 使用不同的插值方法
resized_img_nearest = cv2.resize(img, None, fx=2, fy=2, interpolation=cv2.INTER_NEAREST)
resized_img_cubic = cv2.resize(img, None, fx=2, fy=2, interpolation=cv2.INTER_CUBIC)
# 保存结果
cv2.imwrite('resized_fixed.jpg', resized_img_fixed)
cv2.imwrite('resized_scale.jpg', resized_img_scale)
cv2.imwrite('resized_nearest.jpg', resized_img_nearest)
cv2.imwrite('resized_cubic.jpg', resized_img_cubic)- 通过改变输出尺寸与缩放因子,可以调整图像的大小
- 不同的插值方法会影响图像的质量,最近邻插值可能会出现像素化,三次插值则会更加的平滑
计算机图像学相应知识
图像缩放与插值
- 图像缩放,主要就是改变图像分辨率,需要重新计算其像素值
- 插值算法:用于估计新的像素值,常见的右最近邻、双线性、双三次插值等
- 处理图像的时候,插值算法主要用于在图像缩放和旋转的时候生成新像素
- 也就是说当要放大或者缩小图像的时候,原图中的像素不够使用了,插值算法就是用来填补这些空白区域的,目的就是为了让变换后的新图像看起来更加的平滑自然
插值方法原理理解
- 最近邻插法:选择最接近的像素值,简单但是可能会出现锯齿或者马赛克的效果
- 观察哪个已有像素距离新位置最近,然后直接将这个最近的像素颜色搬运过来
- 也就类似于在放大图片的时候,直接把原来的像素点扩大复制出来,这样省时省力,但是结果可能会出现锯齿现象,图像看起来也就不平滑
- 具体理解,类似于网格纸上的像素画,该算法就是暴力将每个格子放大几倍,但是格子的颜色不变,这样放大后的图像在视觉上一定是存在锯齿形状
- 双线性插值:根据周围四个像素的加权平均计算,效果比较好
- 考虑周围4个像素,并根据这些像素做一个加权平均生成一个新的像素,也就是根据周围的颜色混合出一个中间值,所以图像会比最近邻插值平滑的多
- 根据周围的四个颜色计算出一个过度色,从而更加自然
- 双三次插值:考虑周围16个像素,计算更加复杂一些,效果更加平滑
- 考虑16个相邻的像素,然后利用数学公式生成新的像素,这样就会让边缘和细节更加清晰
- 超分辨率插值
- 该种方法不是简单的利用周围元素生成新的像素,而是利用机器学习来理解图像的内容,甚至预测出新的细节,所以该种方法可以恢复一些模糊的部分
调整图像背后实现理解
- 重采样:计算机通过对目标图像每个像素在源图像的对应位置,使用插值方法计算新的像素值
- 插值计算:根据插值算法,对源图像的像素值进行加权平均,最终得到目标像素值
转换色彩空间
基本操作
- cv2.cvtColor(src , code):转换图像颜色空间,主要用于不同颜色空间之间的转换(BGR转换到灰度)
- src :输入的图像
- code:颜色空间转换代码
cv2.COLOR_BGR2GRAY: BGR 转 灰度cv2.COLOR_BGR2HSV: BGR 转 HSVcv2.COLOR_BGR2RGB: BGR 转 RGB
- OpenCV默认的颜色空间是BGR
代码实践

#颜色空间转换
import cv2
img = cv2.imread('your_image.jpg')
#转换为灰度图像
gray_img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#保存灰度图像
cv2.imwrite('gray_image.jpg',gray_img)实现原理理解
- 该函数会使用预定义的转换公式,将像素值从一种颜色空间映射到另一种颜色空间
- 颜色空间的转换会涉及到对图像的每一个像素和通道进行计算
计算机图形学相应知识补充
颜色空间
- BGR/RGB:基于三原色的颜色模型,一般用于显示设备
- HSV(色调、饱和度、明度):接近于人类感知,主要用于处理颜色分析和处理
颜色空间转换
- 线性转换:部分颜色空间是可以直接通过线性变换转换
- 非线性转换:RGB转换为HSV,就需要使用到非线性公式
图像裁剪
基本说明
- 图像在OpenCV中是以NumPy数组形式表示,所以图像裁剪可以使用数组切片的方式实现
- 数组切片:img[y1:y2 , x1:x2] ,先行后列
- y1:y2:行索引范围(高度)
- x1:x2:列索引范围(宽度)
代码实践
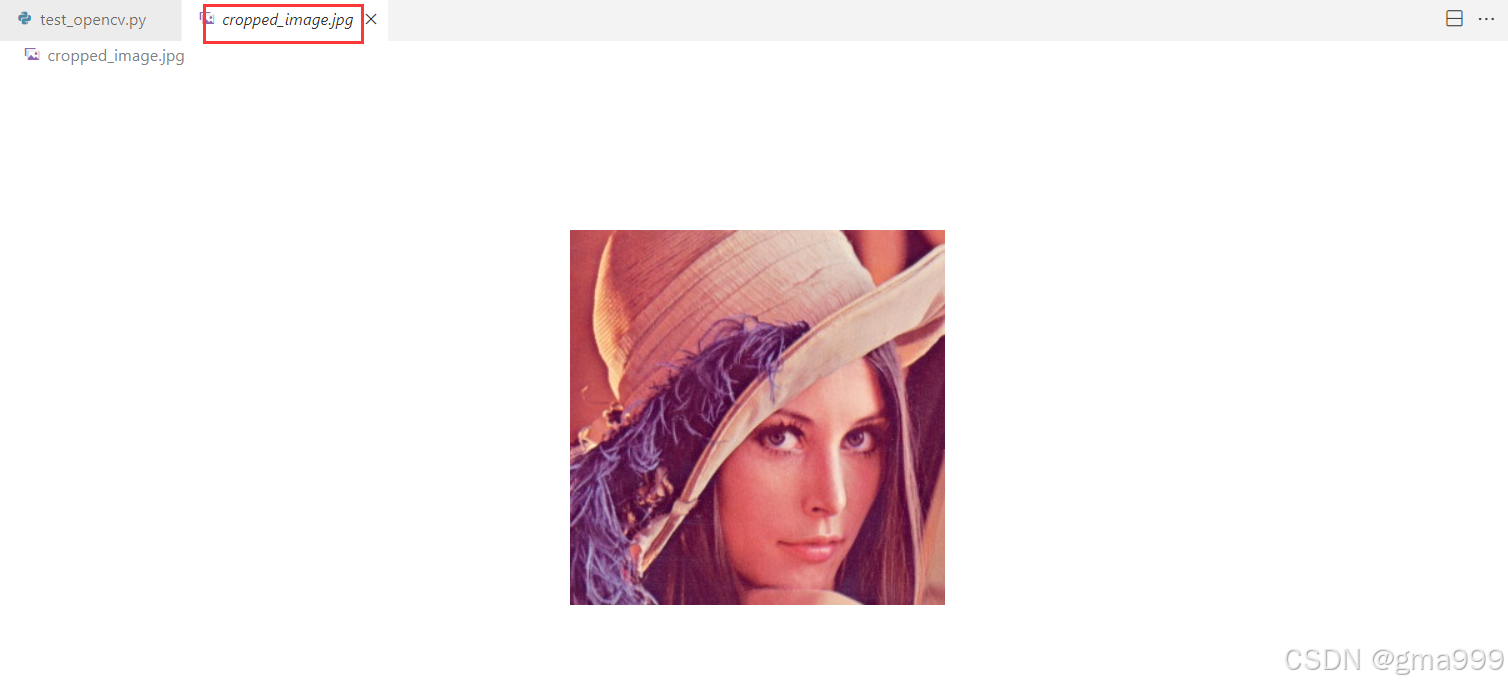
import cv2
img = cv2.imread('your_image.jpg')
#裁剪图像,获取[100,100]到[400,400]
cropped_img = img[100:400,100:400]
#保存图像
cv2.imwrite('cropped_image.jpg',cropped_img)函数实现
- 图像在内存中是以二维或者三维数值表示的,裁剪操作实际上就是对数组进行切片
- 裁剪得到的图像与原图像共享内存,修改裁剪后的图像会影响原图像
计算机原理知识补充
ROI(感兴趣区域)
- 图像中需要处理或者分析的特定区域,主要用于降低计算量,聚焦于关键部分
- ROI是图像中的一块区域,当对这个区域的内容感兴趣的时候,并且需要在这个部分进行处理、分析或者提取信息
- 例如在对一张风景照进行处理,只是对该图片上的一朵花感兴趣,那么只需要提取这朵花的ROI区域,那么接下来的操作就可以对这朵花进行操作,例如放大、修改其形状等
- 实现流程
- 确定ROI的位置,即通过矩形划出感兴趣的部分,然后提取ROI,作为一个独立的小图像
- 处理ROI,针对于该块区域进行处理,最后将ROI还原到原图即可
- 裁剪,即是选取图像中感兴趣的部分,类似于用剪刀将照片上剪下一块
ROI实验
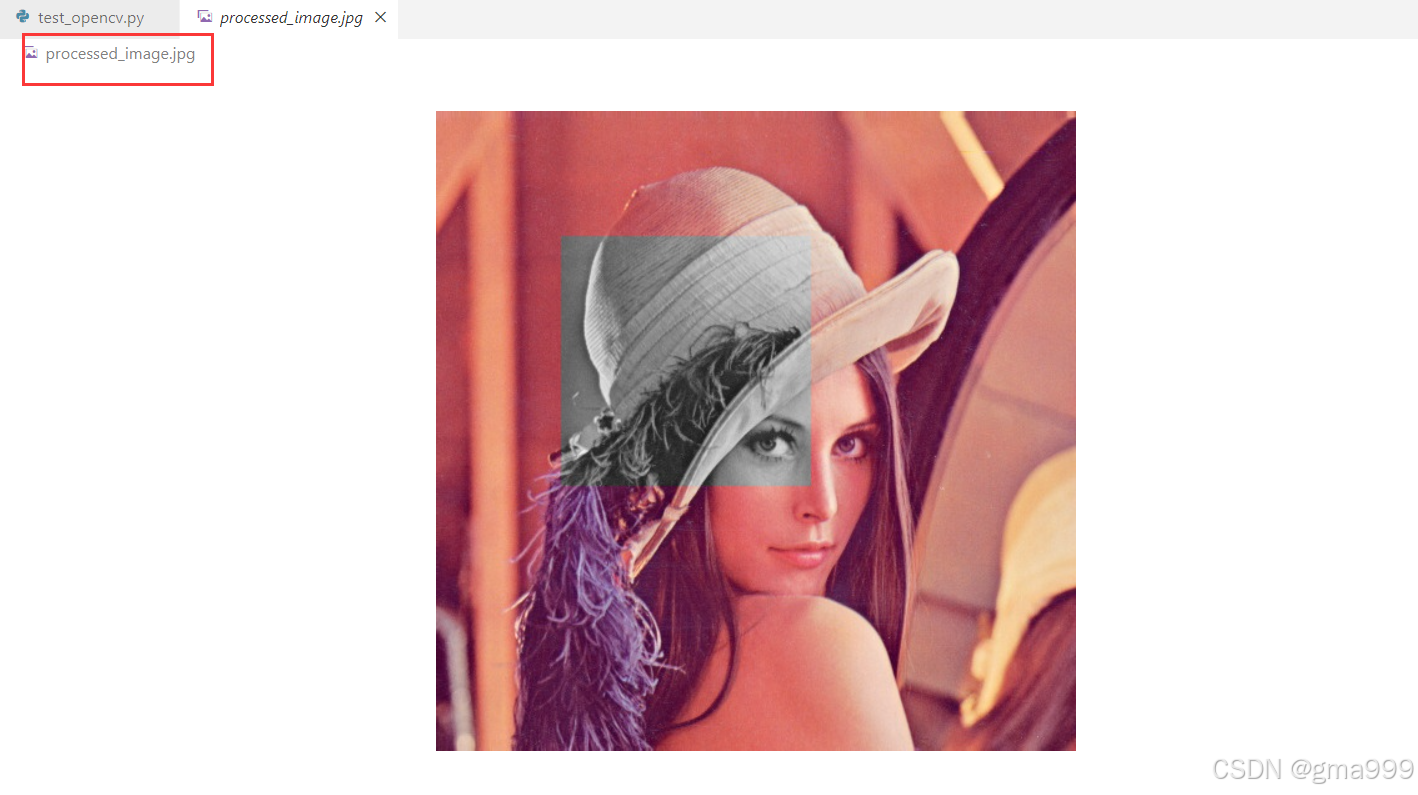
import cv2
# 读取图像
img = cv2.imread('your_image.jpg')
# 定义 ROI 区域(假设已知需要裁剪的坐标)
x, y, w, h = 100, 100, 200, 200 # 左上角坐标 (x, y),宽度 w,高度 h
# 裁剪 ROI
roi = img[y:y+h, x:x+w]
# 对 ROI 进行处理,例如转换为灰度
roi_gray = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
# 将处理后的 ROI 放回原图(需要匹配通道数)
roi_color = cv2.cvtColor(roi_gray, cv2.COLOR_GRAY2BGR)
img[y:y+h, x:x+w] = roi_color
# 保存结果
cv2.imwrite('processed_image.jpg', img)绘制形状和添加文字
基本方法
- cv2.line(img , pt1 , pt2 , color , thickness , lineType):绘制直线
- pt1 , pt2 :起点和终点坐标
- color:线条颜色(B G R)
- thickness:线条厚度
- lineType
cv2.LINE_8: 8-connected line(默认)cv2.LINE_AA: 抗锯齿线条,效果更平滑cv2.LINE_4: 4-connected line
- cv2.rectangle(img , pt1 , pt2 , color-BGR , thickness,lineType,shift ):绘制矩形
- img:目标图像
- pt1:矩形左上角顶点(x,y)
- pt2:矩形的右下顶点
- color:矩形边框颜色
- thickness(可选):边框的厚度,如果将其设置为负数或者cv2.FILLED矩形将被填充
- lineType(可选):边框线条类型
- shift(可选):坐标的小数位表示
- cv2.circle(img , center , radius , color , thickness=None , lineType=None , shift=None):绘制圆形
- img:目标图像
- center:圆心位置
- radius:圆的半径
- color:圆的颜色
- thickness(可选):元边框的厚度
- cv2.putText(img , text , org , fontFace , fontScale , color , thickness=None,lineType=None,bottomLeftOrigin=None):在图形上添加文字
img:目标图像text:要绘制的文本字符串org:文本左下角的起始位置,格式为(x, y)fontFace:字体类型。常用的字体类型:cv2.FONT_HERSHEY_SIMPLEX: 常用字体,正常大小cv2.FONT_HERSHEY_PLAIN: 非常小的字体cv2.FONT_HERSHEY_DUPLEX: 比较粗的字体cv2.FONT_HERSHEY_COMPLEX: 比较复杂的字体cv2.FONT_HERSHEY_TRIPLEX: 更复杂的字体cv2.FONT_HERSHEY_COMPLEX_SMALL: 小字体cv2.FONT_HERSHEY_SCRIPT_SIMPLEX: 类似手写字体cv2.FONT_HERSHEY_SCRIPT_COMPLEX: 更复杂的手写字体
fontScale:字体的缩放比例(大小)color:文本颜色,格式为(B, G, R)thickness(可选):文本线条的粗细,默认为1lineType(可选):线条类型,通常是cv2.LINE_AA抗锯齿bottomLeftOrigin(可选):如果为True,则文本原点为左下角,默认是False,即左上角为原点
代码实践
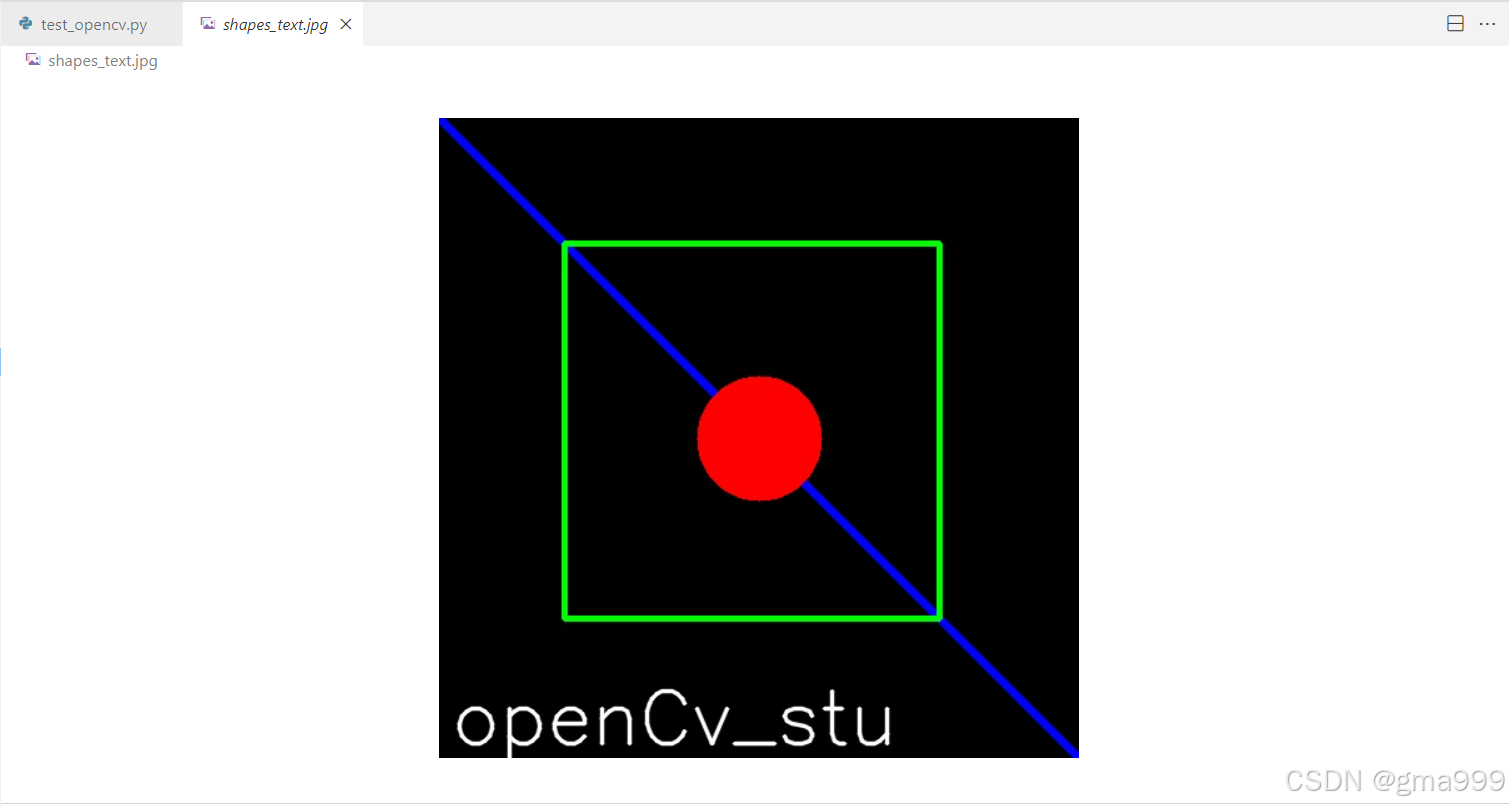
#绘制文字与添加形状
import cv2
import numpy as np
#创建纯黑色背景
img = np.zeros((512,512,3),np.uint8)
#蓝色直线,左上角到右下角
cv2.line(img,(0,0),(511,511),(255,0,0),5)
#绿色矩形,左上角到右下角
cv2.rectangle(img,(100,100),(400,400),(0,255,0),3)
#红色圆形,中心坐标和半径
cv2.circle(img,(256,256),50,(0,0,255),-1) #-1是填充的意思
#添加文字
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img,'openCv_stu',(10,500),font,2,(255,255,255),2,cv2.LINE_AA)
#保存结果
cv2.imwrite('shapes_text.jpg',img)参数调整分析

import cv2
import numpy as np
# 创建黑色图像
img = np.zeros((512, 512, 3), np.uint8)
# 绘制不同厚度和颜色的线条
cv2.line(img, (50, 50), (462, 50), (255, 0, 0), 1)
cv2.line(img, (50, 100), (462, 100), (0, 255, 0), 3)
cv2.line(img, (50, 150), (462, 150), (0, 0, 255), 5)
# 绘制填充和非填充的矩形
cv2.rectangle(img, (50, 200), (200, 350), (255, 255, 0), 3)
cv2.rectangle(img, (250, 200), (450, 350), (255, 0, 255), -1)
# 绘制不同半径的圆形
cv2.circle(img, (256, 400), 50, (0, 255, 255), 2)
cv2.circle(img, (256, 400), 30, (255, 255, 255), -1)
# 添加不同字体和大小的文字
fonts = [cv2.FONT_HERSHEY_SIMPLEX, cv2.FONT_HERSHEY_COMPLEX]
cv2.putText(img, 'OpenCV', (10, 450), fonts[0], 1, (255, 255, 255), 2)
cv2.putText(img, 'Graphics', (10, 500), fonts[1], 2, (255, 255, 255), 3)
# 保存结果
cv2.imwrite('drawings.jpg', img)
计算机图形学补充
光栅化与绘制
- 光栅化就是将几何图形转换为像素阵列
- 光栅图形
- 由像素组成的图像,类似于一个由多个小方格组成的画,每个方格都有颜色
- 抗锯齿即是通过灰度处理平滑边缘,减少锯齿效果
矢量图形
- 使用数学描述图形,放大不会模糊
- 矢量图形是可以实现无损缩放、光栅图形由像素组成,缩放会失真
图像算术运算
基本操作
- cv2.add():图像相加
- cv2.addWeighted(src1 , alpha , scr2 , beta , gamma):图像融合
- src1 , src2 :输入图像
- alpha , beta:图像的权重
- gamma:加到结果上的标量值
代码实践




#图像运算
import cv2
#读取两个相同尺寸的图片
img1 = cv2.imread('image1.jpg')
img2 = cv2.imread('image2.jpg')
#简单相加
added_img = cv2.add(img1,img2)
#两张图像融合
blended_img = cv2.addWeighted(img1,0.7,img2,0.3,0)
#保存结果
cv2.imwrite('added_imge.jpg',added_img)
cv2.imwrite('boended_image.jpg',blended_img)参数调整测试
import cv2
# 读取图像
img1 = cv2.imread('image1.jpg')
img2 = cv2.imread('image2.jpg')
# 确保图像尺寸相同
img2 = cv2.resize(img2, img1.shape[1::-1])
# 不同权重的加权融合
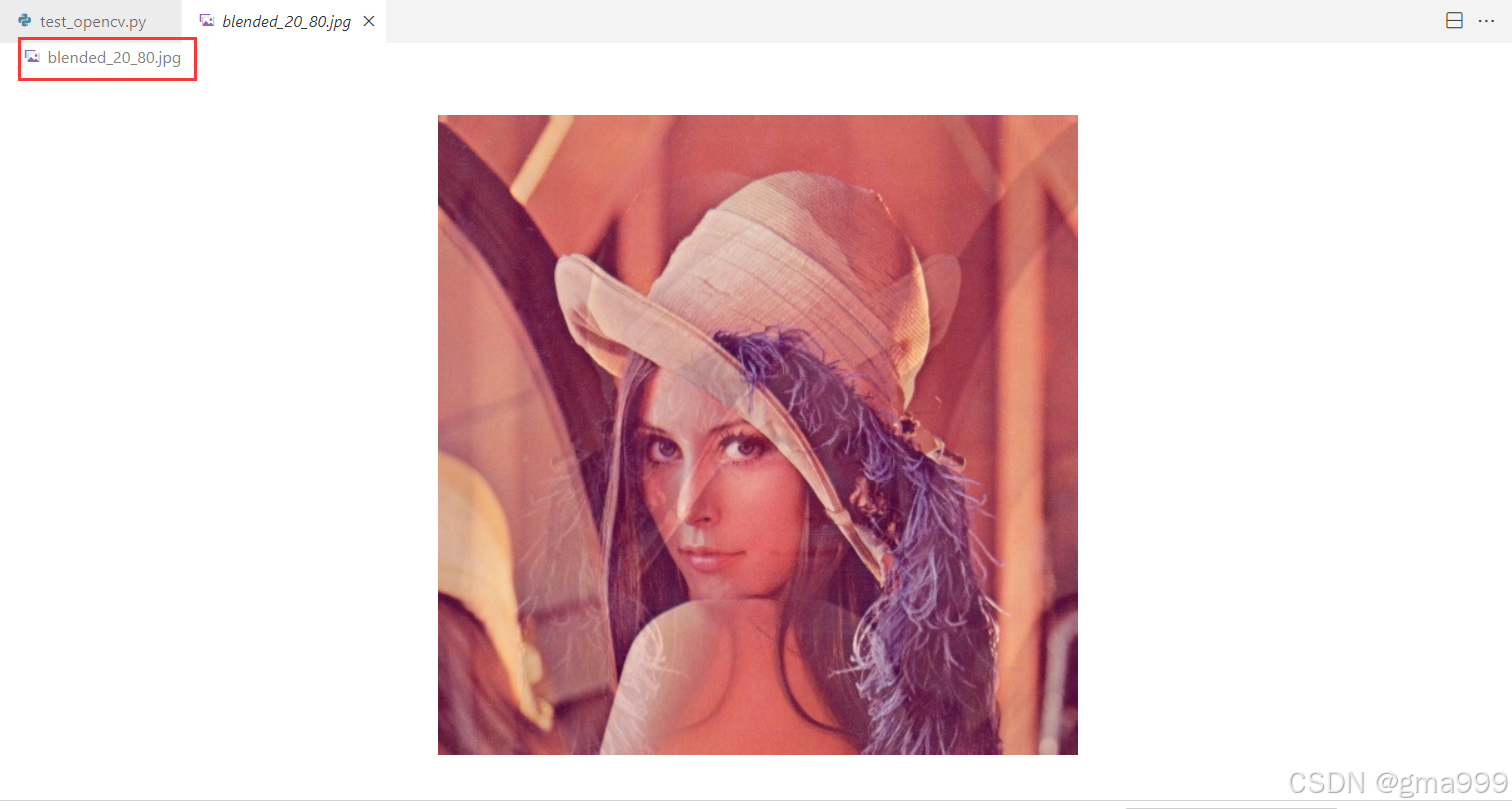
blended_img1 = cv2.addWeighted(img1, 0.2, img2, 0.8, 0)
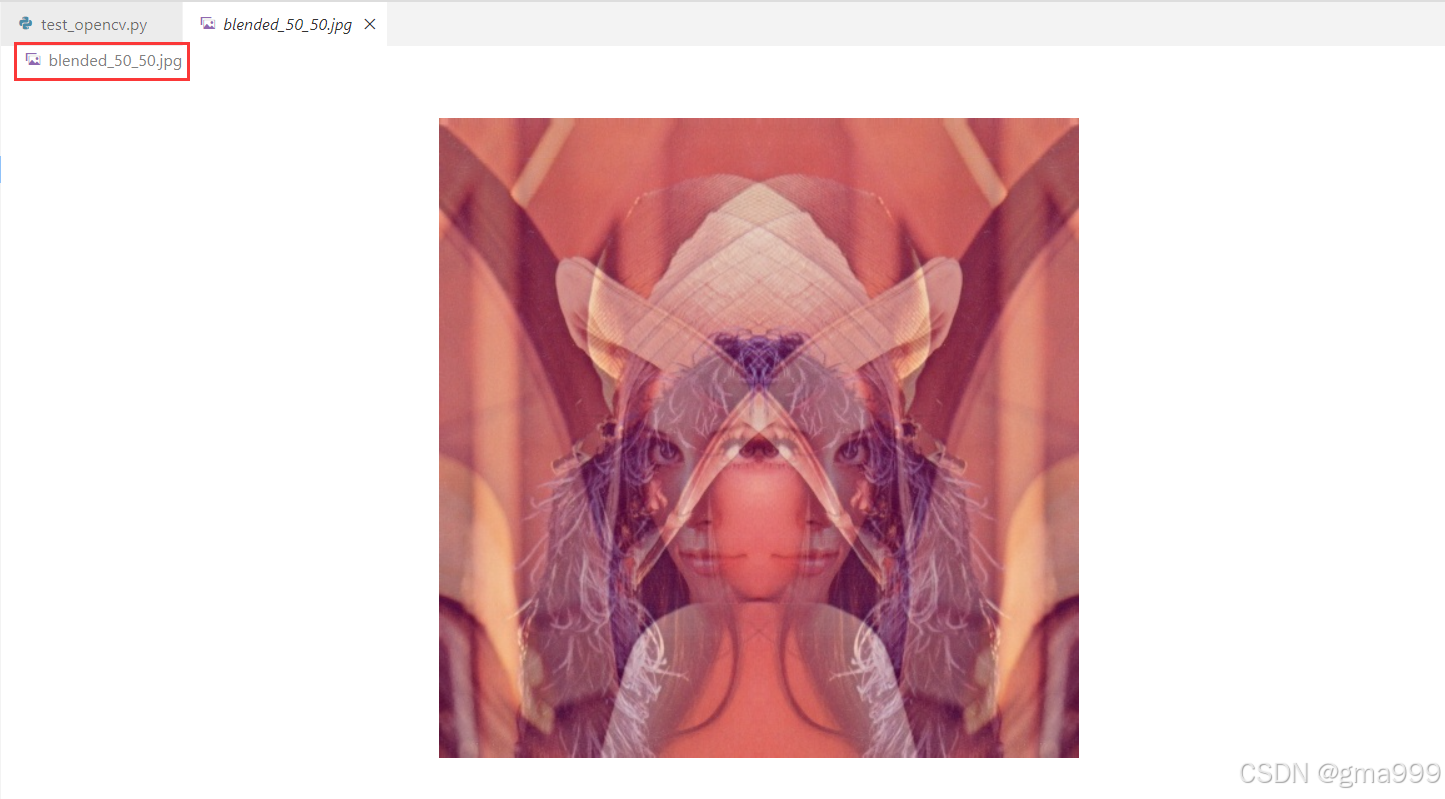
blended_img2 = cv2.addWeighted(img1, 0.5, img2, 0.5, 0)
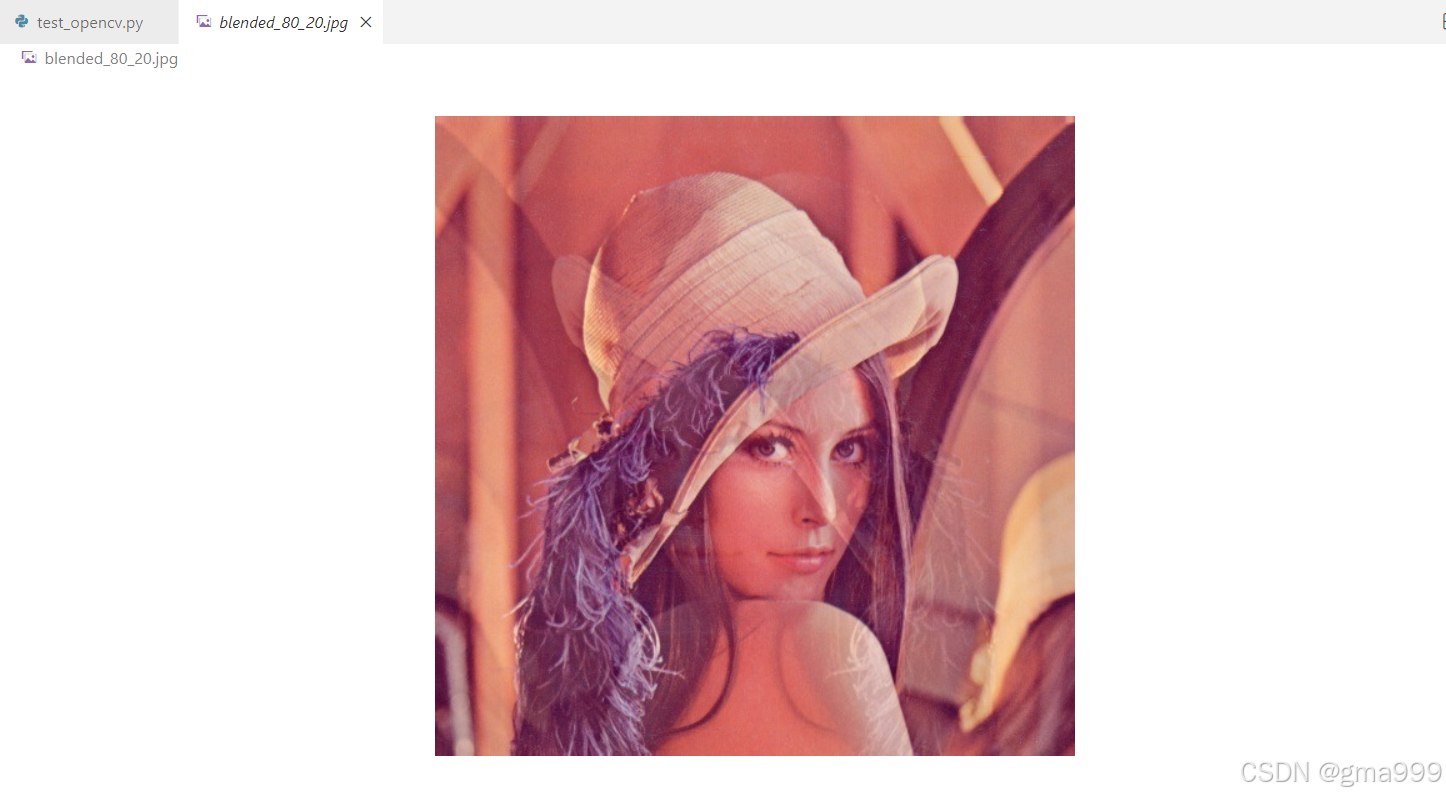
blended_img3 = cv2.addWeighted(img1, 0.8, img2, 0.2, 0)
# 保存结果
cv2.imwrite('blended_20_80.jpg', blended_img1)
cv2.imwrite('blended_50_50.jpg', blended_img2)
cv2.imwrite('blended_80_20.jpg', blended_img3)计算机图形学知识补充
图像融合
- 加权平均:对两张图像的像素值按照权重求和,实现融合效果
- Alpha通道:用于表示图像的透明度,在图像叠加的时候起作用
像素级运算
- 逐像素计算:对图像的每个像素进行算术运算,生成新的图像
- 对图像中的每个元素进行计算,就像个每个像素加上一样的亮度
- 图像融合
- 将两个图像按照一定比例进行叠加,从而产生融合效果,类似于PS中的正片叠底等效果
图像阈值处理
基本操作
- cv2.threshold(src , thresh , maxval , type):主要负责对图像的阈值进行处理,阈值就是用来将灰度图像二值化,根据阈值将像素进行分类
- src:输出灰度图像
- thresh:阈值
- maxval:当满足条件的时候,赋予的像素值
- type:阈值类型
cv2.THRESH_BINARY: 大于阈值的像素赋值为maxval,否则为 0cv2.THRESH_BINARY_INV: 反转的二值化cv2.THRESH_TRUNC: 大于阈值的像素赋值为阈值cv2.THRESH_TOZERO: 大于阈值的保留,其他设为 0
- 注意其返回值有两个,以代码事例来说,ret是阈值,thresh_img是处理后的图像
代码实践

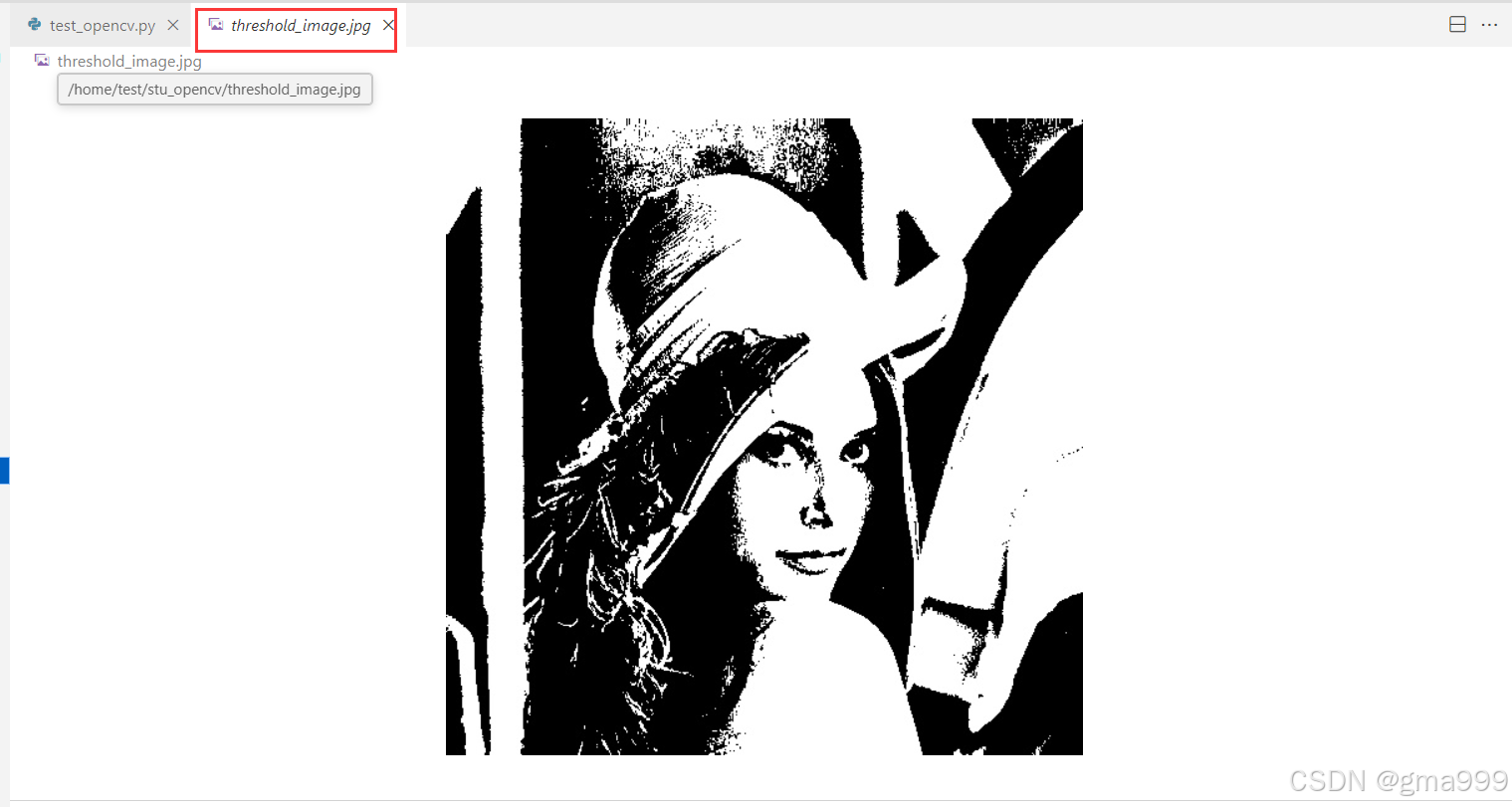
import cv2
#读取灰度图像
gray_img = cv2.imread('gray_image.jpg',0)
#应用全局阈值
ret,thresh_img = cv2.threshold(gray_img,127,255,cv2.THRESH_BINARY)
#保存处理结果
cv2.imwrite('threshold_image.jpg',thresh_img)参数调整测试



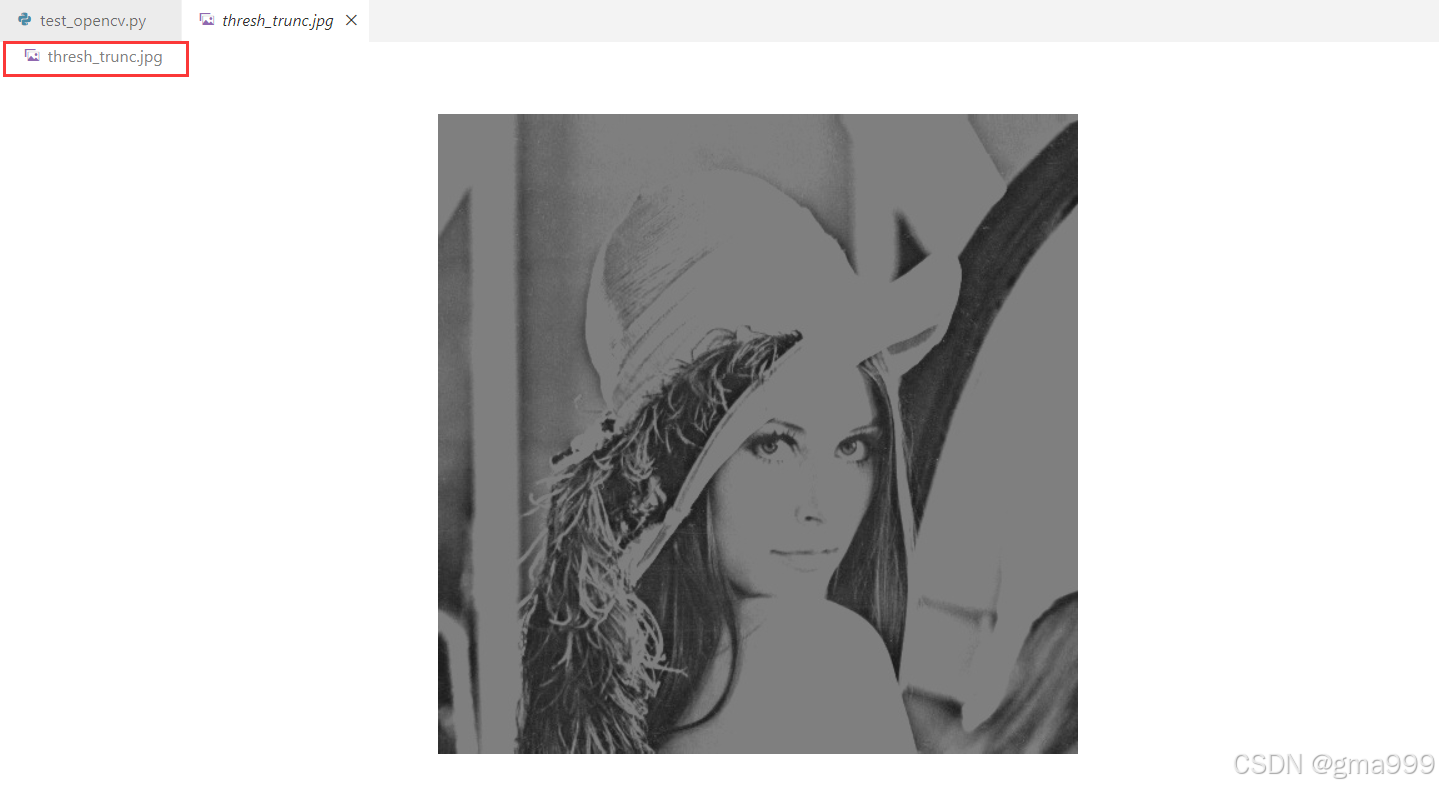
import cv2
# 读取灰度图像
gray_img = cv2.imread('gray_image.jpg', 0)
# 应用不同阈值和类型
ret, thresh_binary = cv2.threshold(gray_img, 127, 255, cv2.THRESH_BINARY)
ret, thresh_binary_inv = cv2.threshold(gray_img, 127, 255, cv2.THRESH_BINARY_INV)
ret, thresh_trunc = cv2.threshold(gray_img, 127, 255, cv2.THRESH_TRUNC)
ret, thresh_tozero = cv2.threshold(gray_img, 127, 255, cv2.THRESH_TOZERO)
# 保存结果
cv2.imwrite('thresh_binary.jpg', thresh_binary)
cv2.imwrite('thresh_binary_inv.jpg', thresh_binary_inv)
cv2.imwrite('thresh_trunc.jpg', thresh_trunc)
cv2.imwrite('thresh_tozero.jpg', thresh_tozero)计算机图形学概念理解
阈值处理
- 阈值处理理解
- 类似于一张黑白照片,然后手动管设定一个亮度数值,照片上比这个亮度更亮的部分都变成的了白色,低于这个亮度的部分都变成了黑色,该操作就是阈值处理
- 阈值处理就是设定了一个门槛值,将图像的像素分成的两类,一类就是高于这个门槛的像素,另一个就是低于这个门槛的像素,一般用于区分图像前景和后景
- 图像分割:根据像素值,将图像分为前景和背景
- 将自己想要的图像分割出来,但是这个区分标准是基于像素的亮度
- 直方图分析:通过图像的灰度直方图,选择合适的阈值
- 首先直方图就是一个统计表,该直方图中显式的告诉照片中有多少亮的像素和多少暗的像素,这样就可以合理的找出自己想要设定的阈值
- 例如一张黑白图片,上面主要有亮的和暗的物体,直方图中就统计了这张照片亮和暗的像素有多少,然后设计了一个统计表,然后就可以利用直方图将明暗区域分开
自动阈值算法
- 大津算法:自动计算最佳阈值,最大化类间方差
- 大津算法就是在照片中找到一个最佳的分界线,让前景物体和背景区分最明显
- 也就是自动帮忙找到最佳阈值,从而找到最佳分割亮度值
图像平滑(模糊)
基本操作
- 主要功能:图像平滑主要就是用来降低噪声,改善图像质量
- 滤波核大小:核越大,模糊的程度就越高
- 高斯滤波:比均值更加平滑,保留边缘能力更强
- cv2.blur(src , ksize):均值滤波
- ksize:滤波核大小
- cv2.GaussianBlur(src , kszie , sigmaX):高斯滤波
- sigmaX:高斯核在X方向的标准差
- cv2.medianBlur(src , ksize)
- ksize:滤波核大小,必须是奇数
代码实践
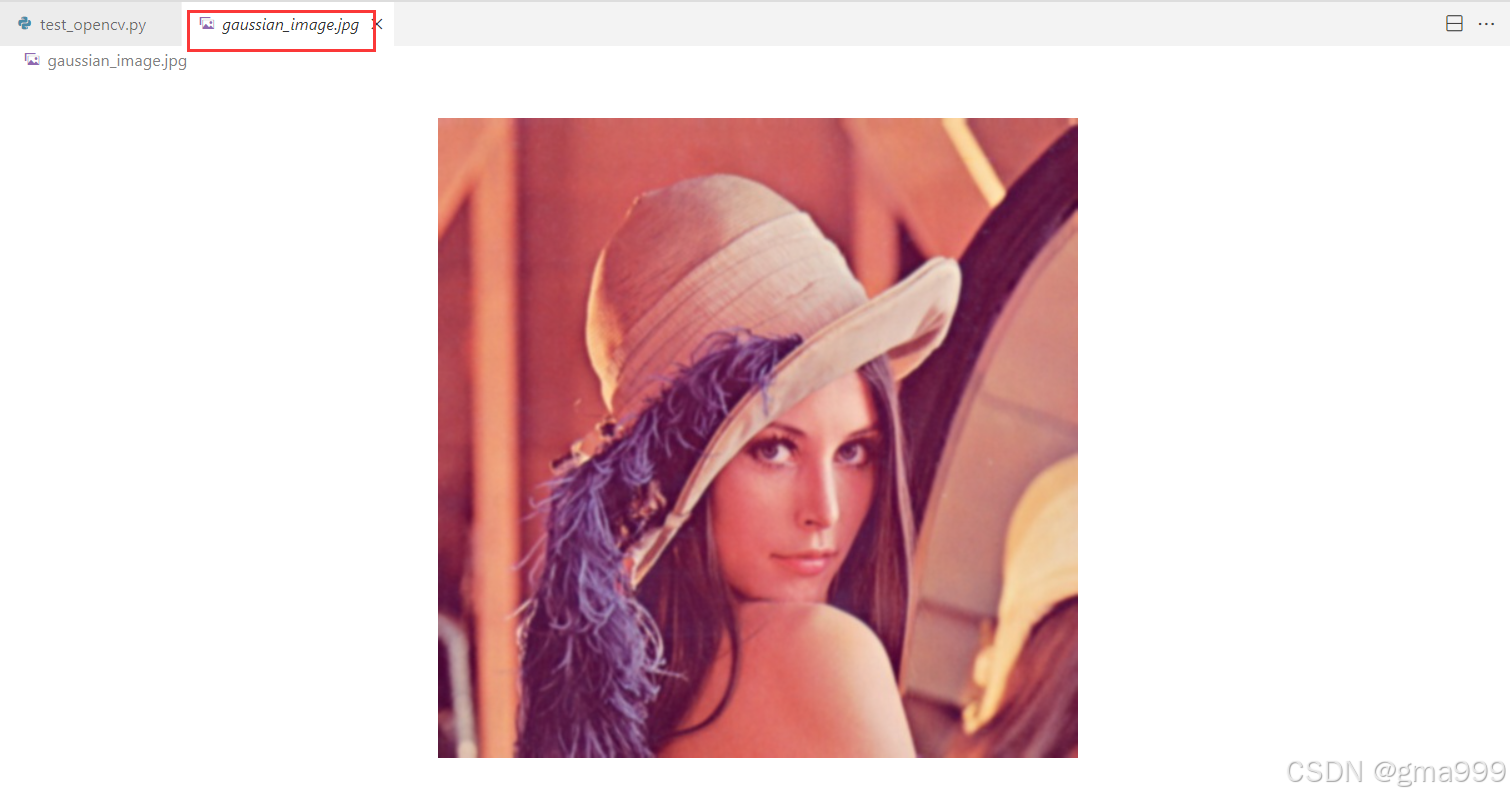

#图像平滑
import cv2
img = cv2.imread('your_image.jpg')
#均值滤波
blur_img = cv2.blur(img,(10,10))
#高斯滤波
gaussian_img = cv2.GaussianBlur(img,(5,5),0)
cv2.imwrite('blur_image.jpg',blur_img)
cv2.imwrite('gaussian_image.jpg',gaussian_img)参数调整变化分析


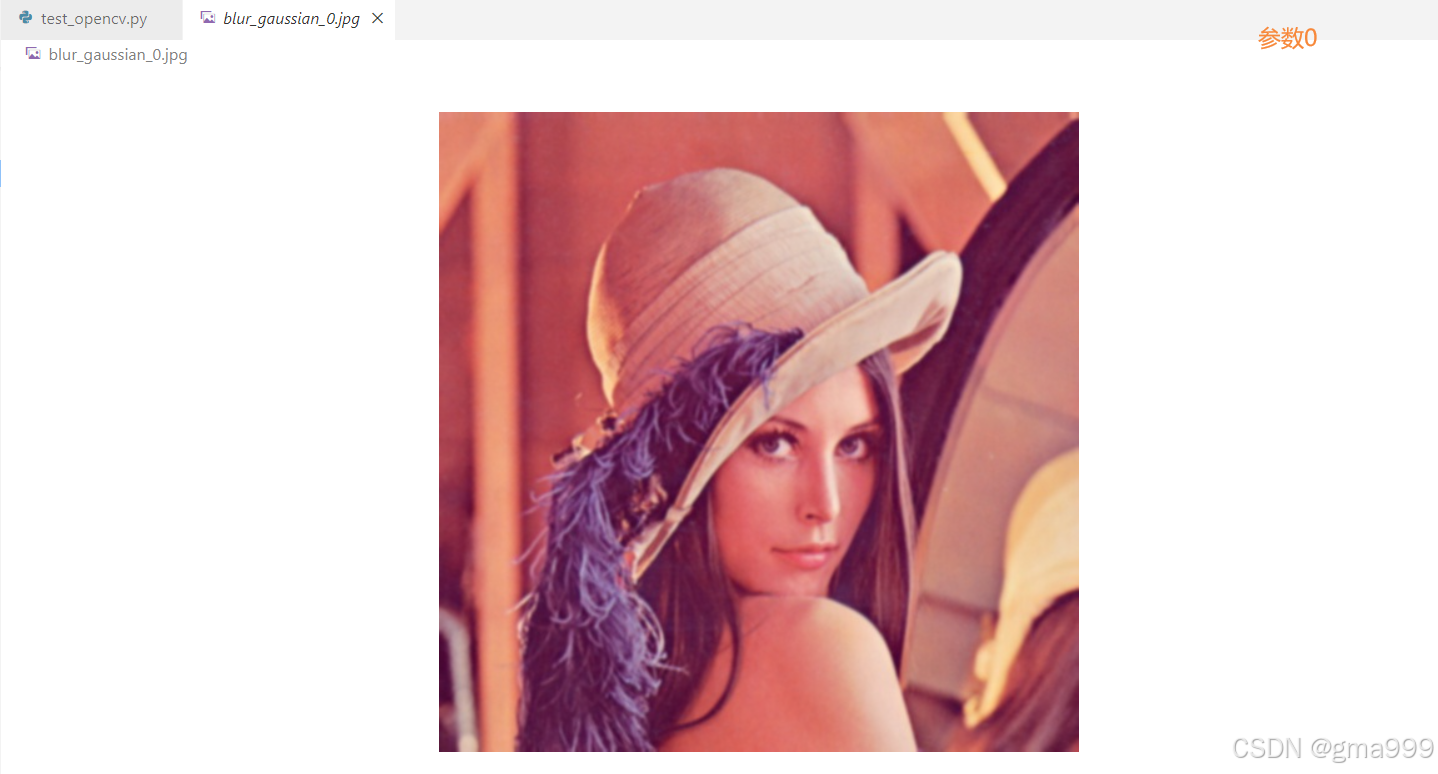
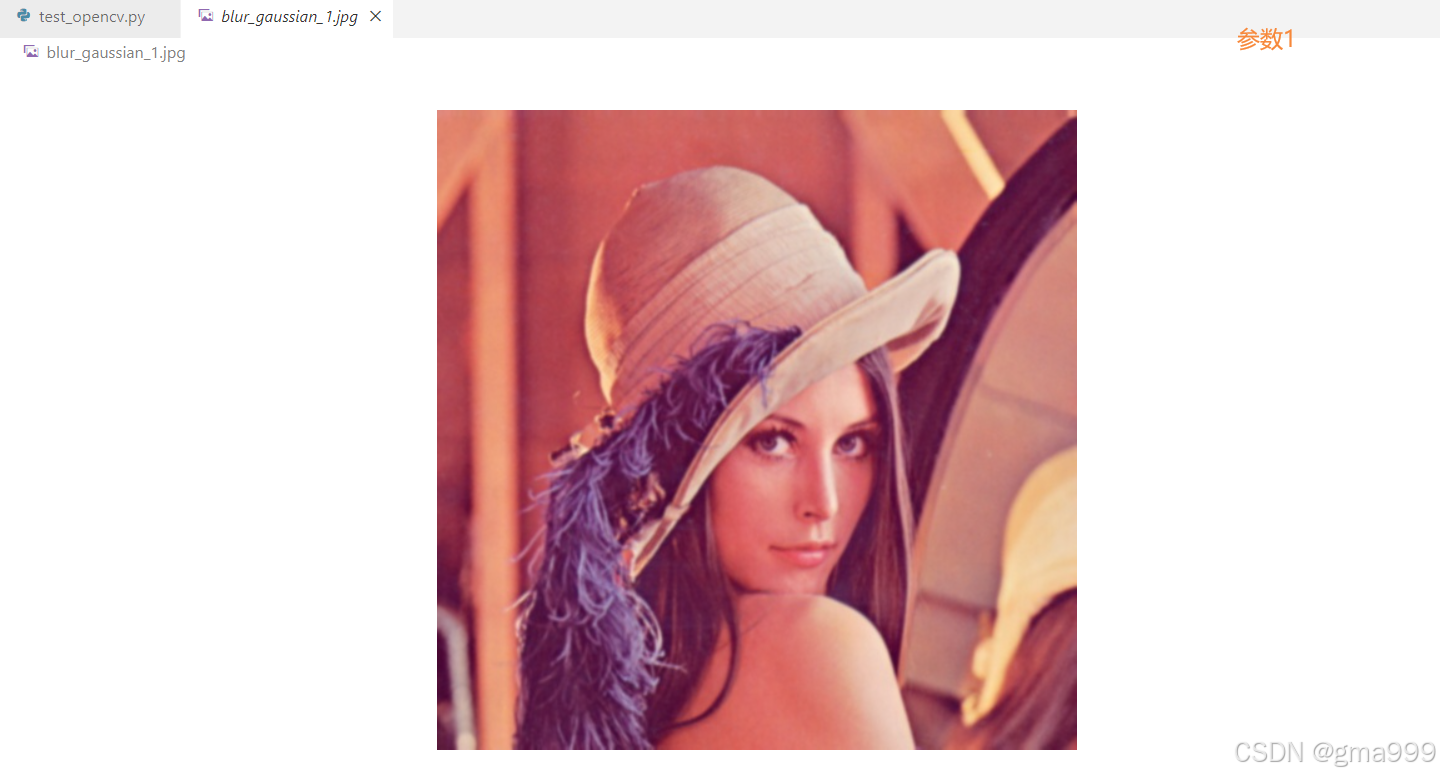
计算机图形学知识补充
滤波器
- 滤波器,类似于PS中的模版或者工具,可以达到模糊、锐化等效果,就像在照片上盖了一层透明的薄膜一样
- 不同滤波器的理解:卷积就像手中拿到的放大镜,观察图像中的每一个部分,然后使用滤波器,类似的滤波器不同的类型可以让图像达到不同的效果
- 空间域滤波:直接在图像像素空间上进行操作
- 卷积操作:滤波器与图像进行卷积,从而得到平滑效果
- 将滤波器在图像上滑动,对对应的像素进行运算,这就像用滚筒在墙上刷漆一样
- 本身是一种数学运算,通过将滤波器核与图像进行点积,得到滤波后的结果
高斯滤波器
- 其权重按照高斯分布,中心权重大,边缘权重小
- 主要用于平滑噪声以及保留边缘信息
不同滤波器实践验证
- 均值滤波对随机噪声有一定抑制作用,但会模糊边缘
- 高斯滤波保留边缘的能力较好,适合去除高斯噪声
- 中值滤波对椒盐噪声有很好的去除效果
import cv2
# 读取图像
img = cv2.imread('your_image.jpg')
# 均值滤波
mean_blur = cv2.blur(img, (5, 5))
# 高斯滤波
gaussian_blur = cv2.GaussianBlur(img, (5, 5), 1)
# 中值滤波
median_blur = cv2.medianBlur(img, 5)
# 保存结果
cv2.imwrite('mean_blur.jpg', mean_blur)
cv2.imwrite('gaussian_blur.jpg', gaussian_blur)
cv2.imwrite('median_blur.jpg', median_blur)
边缘处理
基本用法
- 边缘检测主要用于提取图像中的边缘信息
- cv2.Canny( image , threshold1 , threshold2 , aertureSize=3 , L2gradient=False):边缘检测算法
- image(输入图像)
- 必须是单通道的灰度图像,如果输入的是彩色图像,需要先将其转为灰度图像,然后进行边缘检测
- threshold1 , threshold2 :低阈值与高阈值
- 低阈值,表示任何小于该值的像素梯度将会被认为不是边缘,低阈值直接影响检测出边缘的数量和强度
- 高阈值,任何大于该值的像素梯度都会被认为是边缘,高阈值会直接的影响边缘的强度和检测的灵敏度
- aertureSize:Sobel算子的大小,默认是3
- Sobel算子就是用于计算图像梯度的卷积核尺寸,该算子是一种用于检测边缘的算子
- apertureSize的数值必须是奇数,卷积和越大,计算出来梯度就越精细,但是可能也会导致边缘模糊
- L2gradient:是否使用更加精确的L2范数进行梯度的运算
- image(输入图像)
代码实践

参数调整
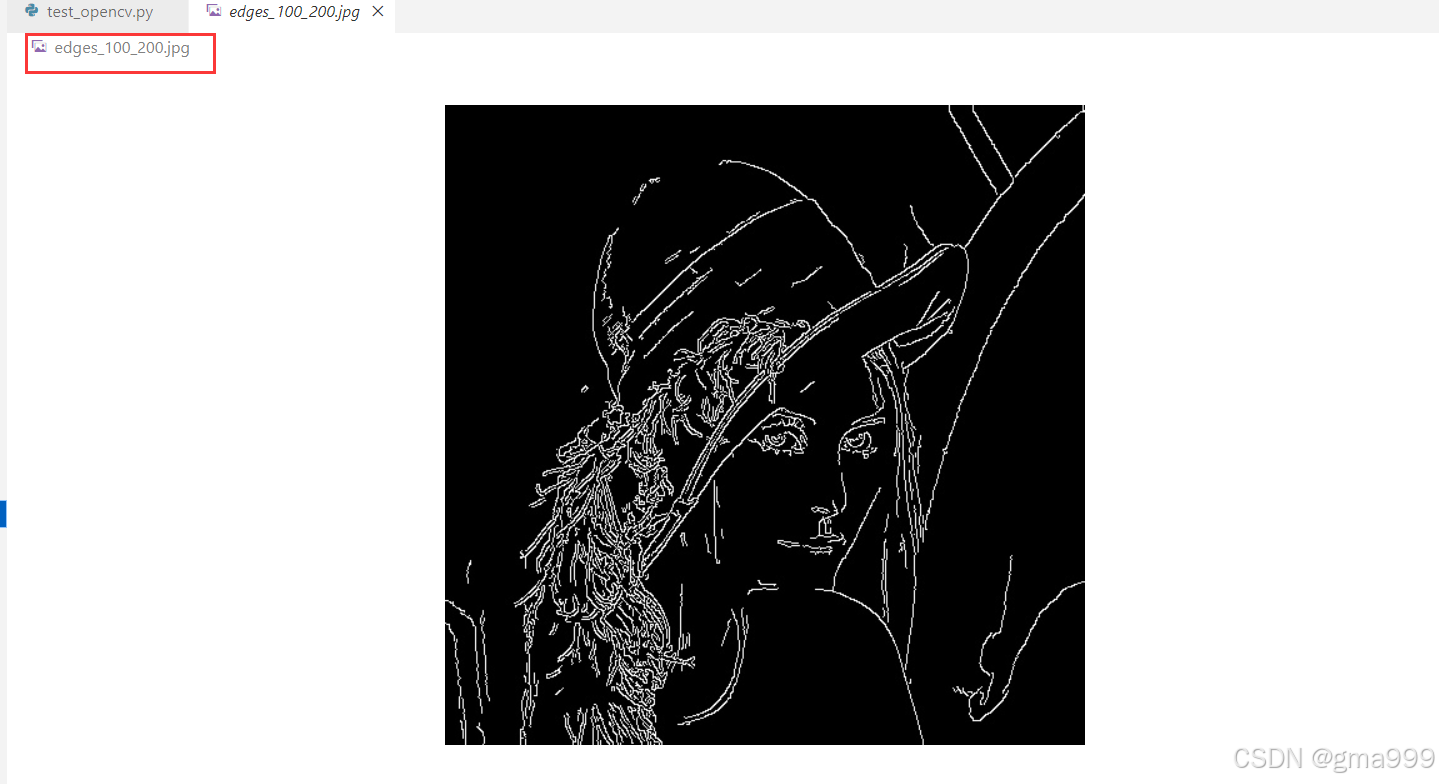
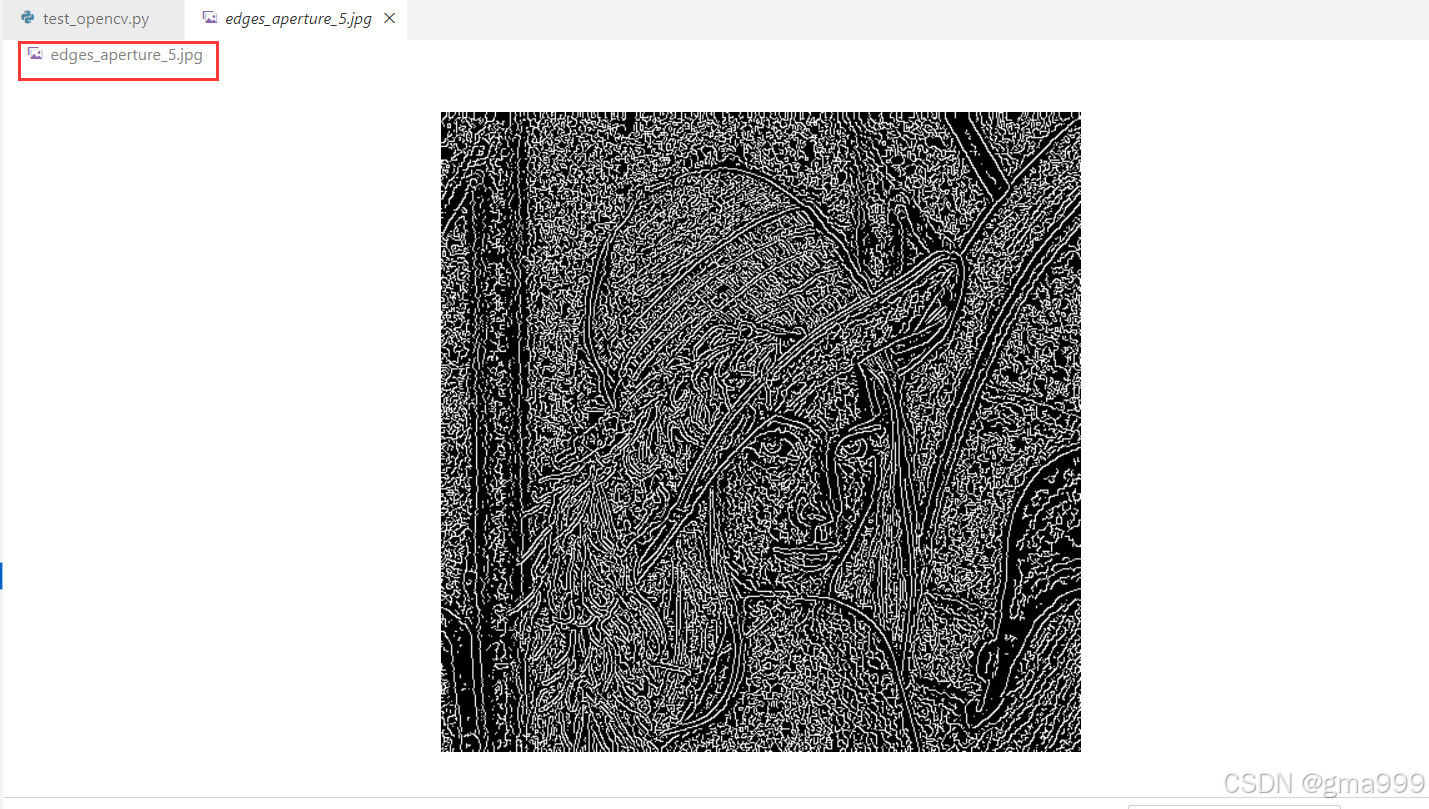
结论: 改变阈值可以控制检测到的边缘数量;增大aertureSize,可以检测到更粗的边缘
import cv2
gray_img = cv2.imread('gray_image.jpg',0)
#不同阈值边缘检测
edges_50_150 = cv2.Canny(gray_img, 50, 150)
edges_100_200 = cv2.Canny(gray_img, 100, 200)
edges_150_250 = cv2.Canny(gray_img, 150, 250)
# 使用不同的 apertureSize
edges_aperture_5 = cv2.Canny(gray_img, 100, 200, apertureSize=5)
# 保存结果
cv2.imwrite('edges_50_150.jpg', edges_50_150)
cv2.imwrite('edges_100_200.jpg', edges_100_200)
cv2.imwrite('edges_150_250.jpg', edges_150_250)
cv2.imwrite('edges_aperture_5.jpg', edges_aperture_5)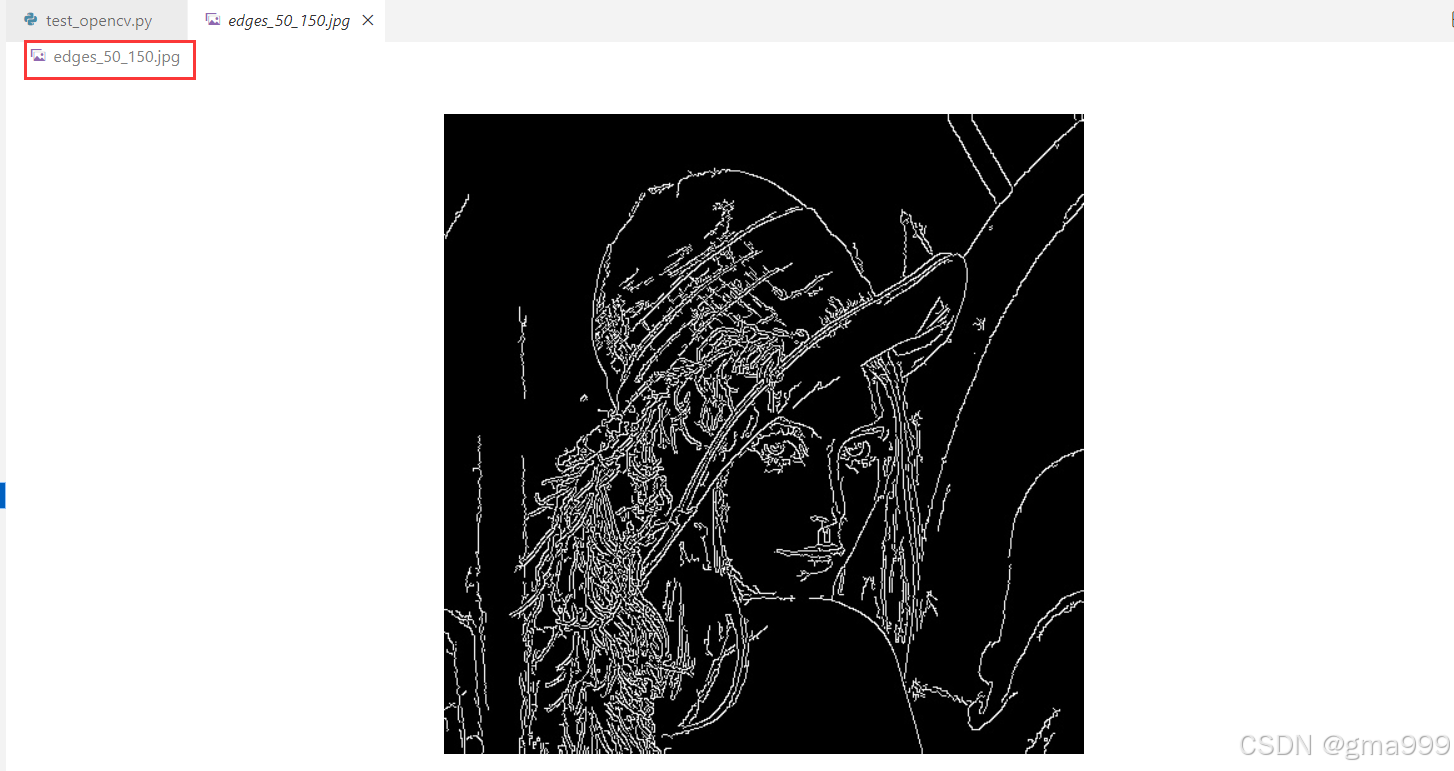

计算机图形学知识补充
边缘检测算法
- Canny边缘检测:多级边缘检测算法,
- Sobel算子:用于计算图形的梯度
梯度
- 梯度就是图像中像素值变化的程度,就像山坡的坡度,坡度越大变化也就越明显
- 图像处理中的梯度,表示的是在空间位置上的变化率,是向量,包含幅值和方向
- 课本概念理解
- 梯度是图像中亮度(灰度值)变化的方向和强度,对于每个像素,梯度是一个向量,其指的是像素值变化最快的方向
- Gx:图像在水平方向的变化
- Gy:图像上垂直方向上变化
原文地址:https://blog.csdn.net/gma999/article/details/142780822
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!