Kafka模拟器产生数据仿真-集成StructuredStreaming做到”毫秒“级实时响应StreamData落地到mysql
这是仿真过程某图:
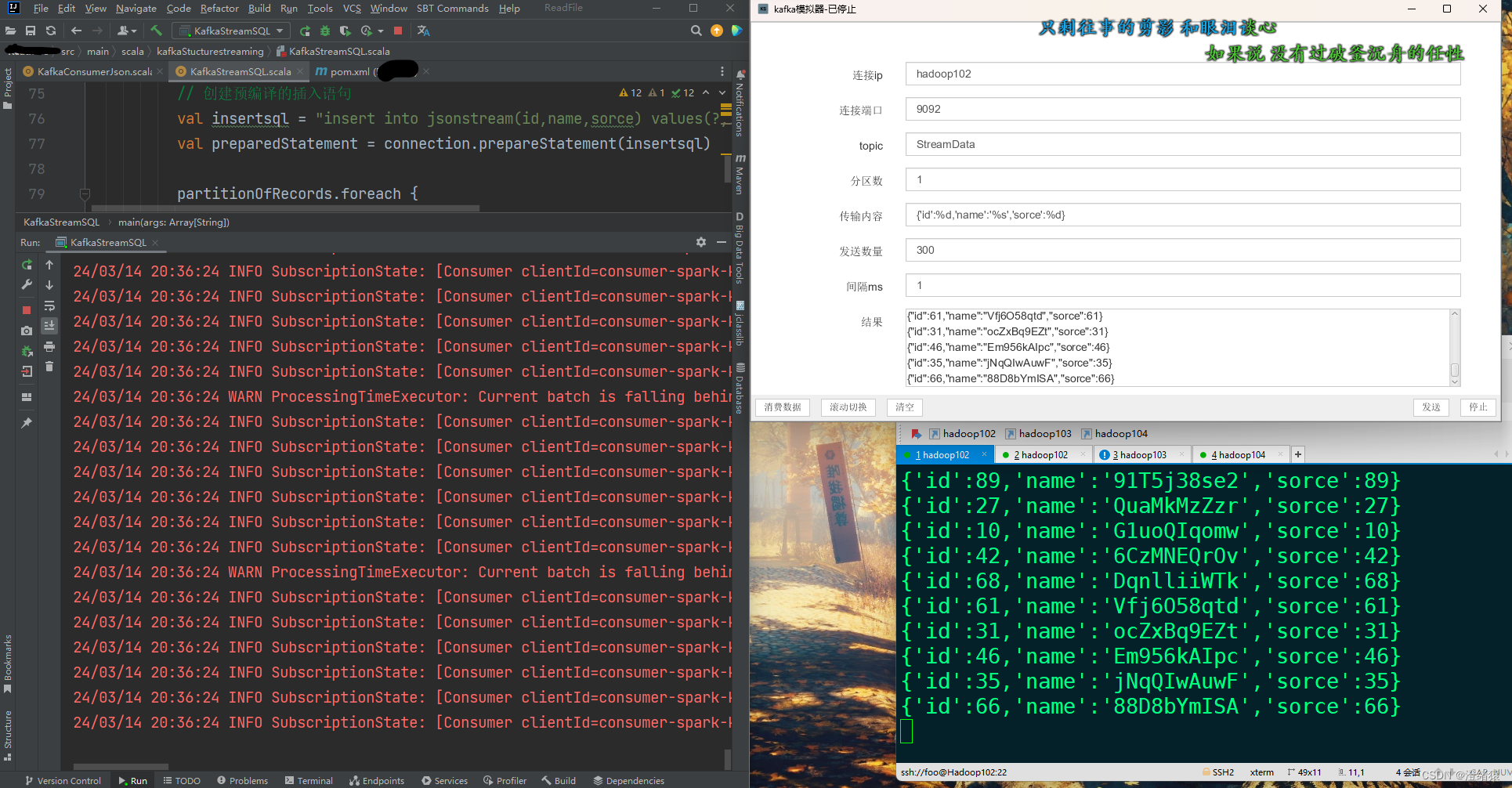
kafka消费sink端和StructuredStreaming集成通信成功 , 数据接收全部接收
数据落地情况:
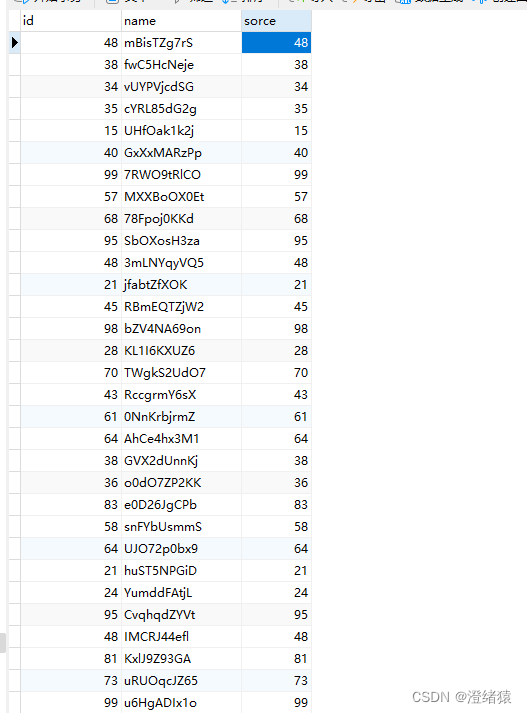
全部接收到并all存入mysql
下面就简单分享一下StructuredStreaming代码吧
import org.apache.spark.sql.functions.{col, from_json}
import org.apache.spark.sql.streaming.{ OutputMode, Trigger}
import org.apache.spark.sql.types.{IntegerType, StringType, StructType}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
val spark: SparkSession = SparkSession.builder()
.appName("kafkaConsumer")
.master("local[3]")
.getOrCreate()
import spark.implicits._
// 定义json字段类型格式
val Jsonschmea: StructType = new StructType()
.add("id", dataType = IntegerType)
.add("name", dataType = StringType)
.add("sorce", dataType = IntegerType)
val message: DataFrame = spark.readStream // message为从kafka读到的原数据
.format("kafka")
.option("kafka.bootstrap.servers", "xxxxx:9092,xxxx:9092,xxxx:9092")
.option("subscribe", "xxxx")
.option("startingOffsets", "latest")
.load()
// 将json字符串转化为结构化数据
val streamData: DataFrame = message.selectExpr("cast(value as String) as message")
.select(from_json($"message", Jsonschmea).alias("data"))
// 将json结构化为新的df
// 预加载mysql驱动
// 实时写入 第二个参数预占位,want给每一批次加入唯一表示, but本次仅占位没有传参数
def writeToMysql(batchDF: DataFrame, epochId: Long): Unit = {
val sqlurl = "jdbc:mysql://localhost:xxxx/xxxx"
val sqluser = "xxxx"
val sqlpass = "xxxxx"
Class.forName("com.mysql.cj.jdbc.Driver") // mysql 8.0后得驱动,旧版本去掉cj
batchDF.foreachPartition {
partitionOfRecords =>
val connection = DriverManager.getConnection(sqlurl, sqluser, sqlpass)
// 关闭自动提交以支持增量写入
connection.setAutoCommit(false)
// 创建预编译的插入语句
val insertsql = "insert into jsonstream(id,name,sorce) values(?,?,?)"
val preparedStatement = connection.prepareStatement(insertsql)
partitionOfRecords.foreach {
row =>
// val id = row.getAs[Int]("data.id")
// val name = row.getAs[String]("data.name")
// val score = row.getAs[Int]("data.sorce")
val id = row.getAs[Row]("data").getAs[Int]("id")
val name = row.getAs[Row]("data").getAs[String]("name")
val sorce = row.getAs[Row]("data").getAs[Int]("sorce")
// 设置参数到预处理sql函数中
preparedStatement.setInt(1, id)
preparedStatement.setString(2, name)
preparedStatement.setInt(3, sorce)
// 执行添加到批次操作
preparedStatement.addBatch()
}
preparedStatement.executeBatch()
connection.commit() // 执行批处理后手动提交事务
preparedStatement.close() // 手动GC
connection.close()
}
}
// 数据落地到数据库
streamData.writeStream
.outputMode(OutputMode.Append())
.foreachBatch(writeToMysql _)
.trigger(Trigger.ProcessingTime("1 millisecond")) // 1 毫秒每个batch
.start()
.awaitTermination()存储按照一定批次量做存储
友情提示 : 上述程序是经过脱敏处理的哦
----彩蛋----
如果你看到者你会知道scala在11更新之后也就是12版本如下:
batchDF.foreachPartition {
partitionOfRecords => ... 这个位置
Dataset的foreachPartition 里面不能处理 Row的Iterator, 所以需要转为rdd在做处理
所以更改后为
batchDF.rdd.foreachPartition { partitionOfRecords => ...
而且这里不能用foreach , 否则无法序列化就能存储到mysql, 不能被序列化的数据是不能在网络中进行传输的,通过二进制流的形式传出,在被反序列化回来转化为对象的形式存储
ok -----
原文地址:https://blog.csdn.net/python8181/article/details/136721419
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!