bayesplot|分享一个可视化贝叶斯模型的R包
1.bayesplot介绍
该包主要用于贝叶斯模型的可视化分析,提供了一系列工具来帮助评估、理解和诊断贝叶斯模型。这个包特别适用于与 Stan 以及其他提供 MCMC 样本的软件如 JAGS 和 BUGS 的模型输出。
- 后验分布图:包括密度图、直方图和区间图,用于展示模型参数的后验分布。
- MCMC 诊断图:
追踪图(trace plots)、秩序图(rank plots)、自相关图(autocorrelation plots)和转移图(transition plots),这些都是用来诊断 MCMC 算法收敛性的工具。 - 后验预测检查:
包括残差图、PPC(后验预测检查)条形图等,这些图形用来评估模型预测数据的能力与实际观测数据的符合程度。 - 比较和模型评估:
提供 LOO-CV(留一交叉验证)和 WAIC(Widely Applicable Information Criterion)等模型比较指标的可视化。
2.bayesplot-DEMO
library("bayesplot")
library("rstanarm")
library("ggplot2")
fit <- stan_glm(mpg ~ ., data = mtcars)
posterior <- as.matrix(fit)
plot_title <- ggtitle("Posterior distributions",
"with medians and 80% intervals")
mcmc_areas(posterior,
pars = c("cyl", "drat", "am", "wt"),
prob = 0.8) + plot_title

- 密度曲线:这条曲线展示了在参数的可能值上概率密度的估计。曲线越高,表示该值的概率密度越大。
- 中位数:每个分布中的垂直灰色线表示该分布的中位数,也就是所有后验样本中值的中位数。
- 80%区间:蓝色填充区域展示了每个变量的后验分布的 80% 最高密度区间(Highest Posterior Density, HPD)。HPD 区间包含了后验分布中最有可能的 80% 值,通常用来作为参数的不确定性的度量。
color_scheme_set("red")
ppc_dens_overlay(y = fit$y,
yrep = posterior_predict(fit, draws = 50))
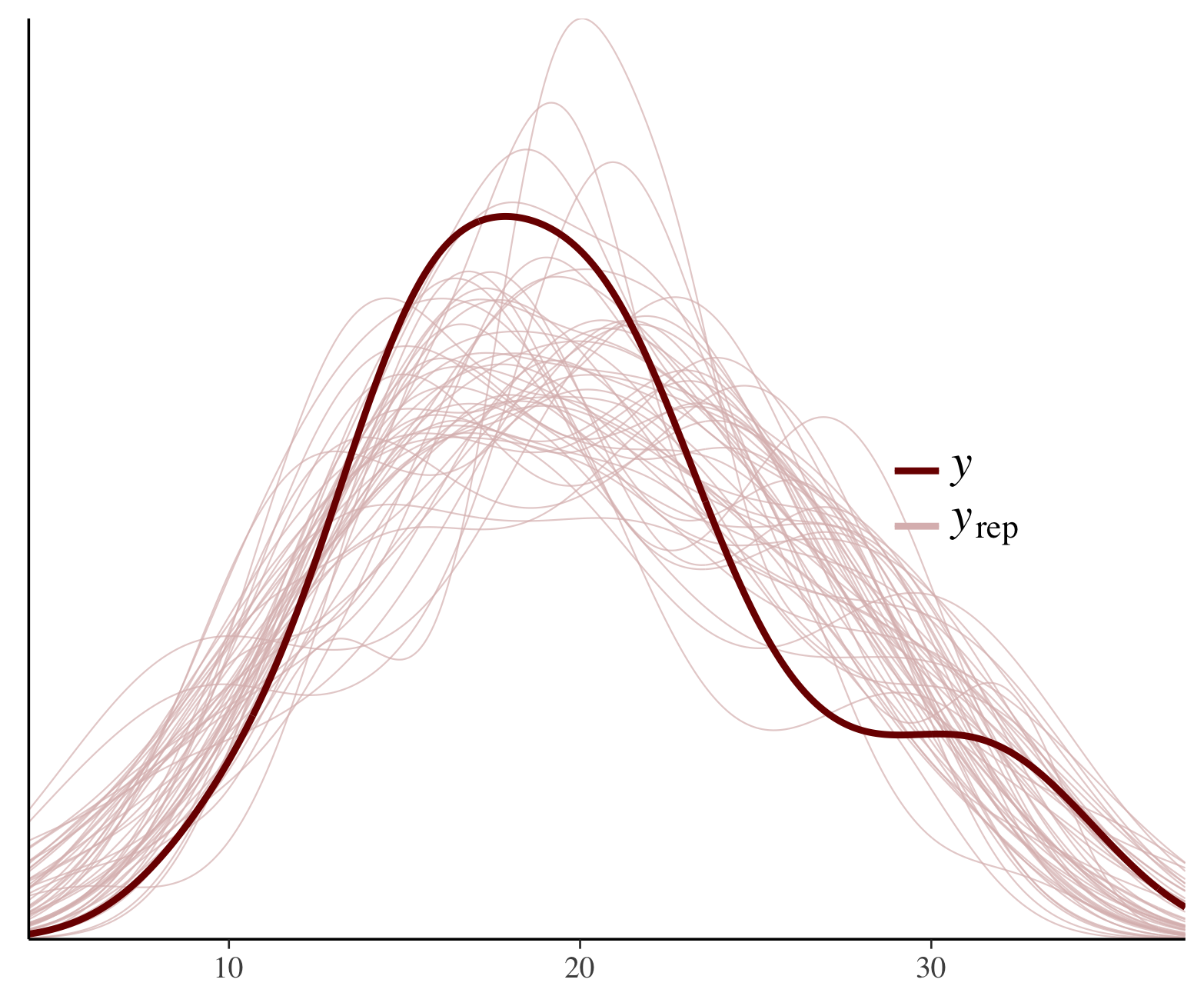
- Y:粗黑线表示观察到的数据或数据的预测平均值。这是比较复制数据集的参考点。
- Y_rep:许多细线代表基于模型参数的后向分布的预测数据(复制数据集)的单独模拟。每条线都是给定模型及其不确定性的数据的可能实现。
# also works nicely with piping
library("dplyr")
color_scheme_set("brightblue")
fit %>%
posterior_predict(draws = 500) %>%
ppc_stat_grouped(y = mtcars$mpg,
group = mtcars$carb,
stat = "median")
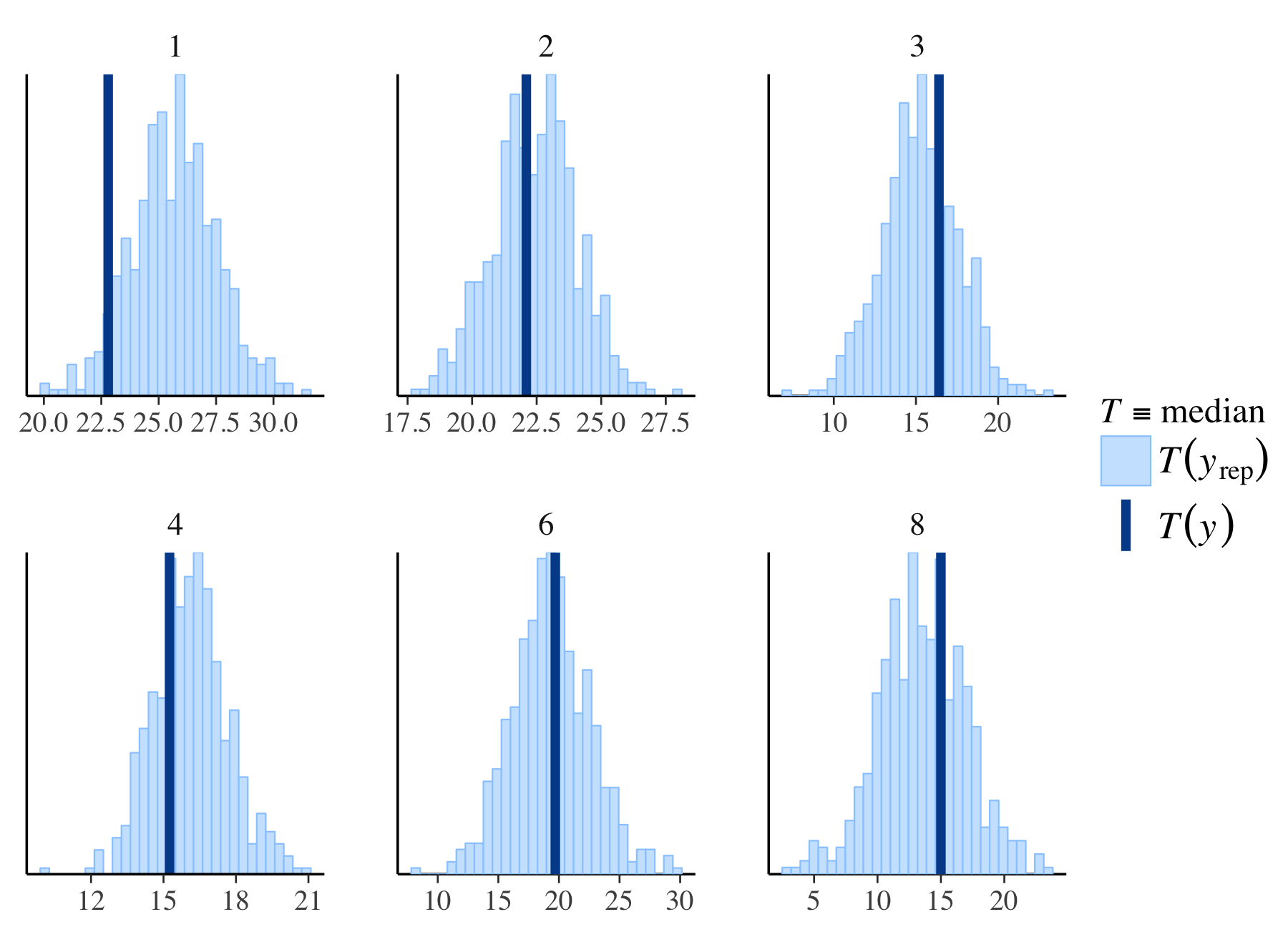
每个直方图中的深蓝色垂直线表示观察到的数据集的统计量T(y) 的值。理想情况下,如果模型拟合良好,观测到的数据的统计量值应该位于模拟的数据分布的中心区域。
图中的T=median 表示这些模拟的数据分布中位数的位置。在后验预测检查中,通常希望观察到的数据的统计量值接近于模拟数据分布的中位数或落在高密度区间内,这表明模型对数据的预测与实际观测相符。
# with rstan demo model
library("rstan")
fit2 <- stan_demo("eight_schools", warmup = 300, iter = 700)
posterior2 <- extract(fit2, inc_warmup = TRUE, permuted = FALSE)
color_scheme_set("mix-blue-pink")
p <- mcmc_trace(posterior2, pars = c("mu", "tau"), n_warmup = 300,
facet_args = list(nrow = 2, labeller = label_parsed))
p + facet_text(size = 15)
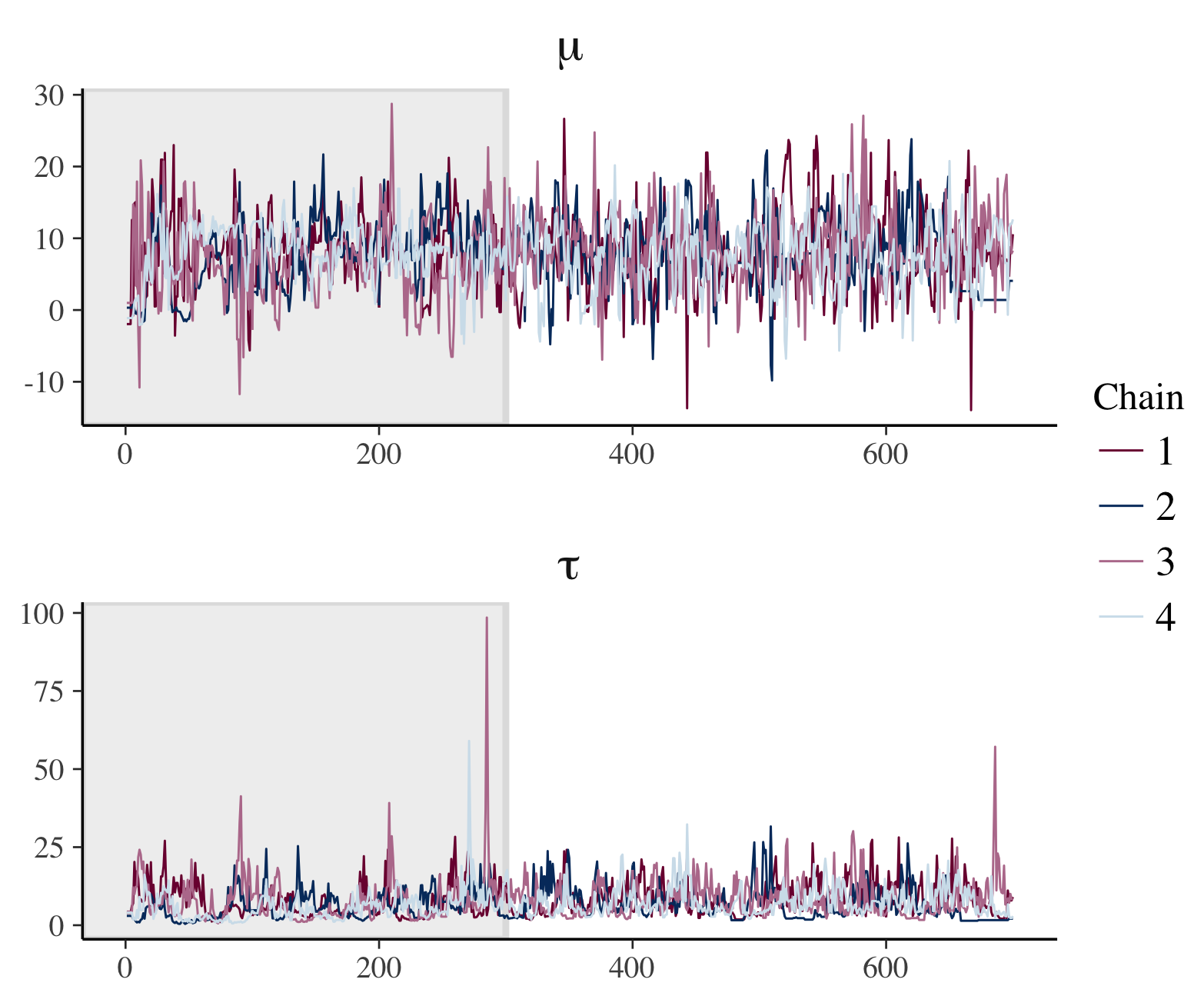
- 上面的图 μ: 展示了四条不同的 MCMC 链(用不同的颜色表示),它们对参数 μ 的取值进行采样。理想状态下,所有链都应围绕同一平均值随机摆动,且具有相似的变异度,这样可以认为收敛到了相同的后验分布。
- 下面的图 τ: 同样展示了四条 MCMC 链,但是针对另一个参数 τ。这里的链条看起来比上图更加剧烈波动,特别是一些尖峰,可能表示这个参数的某些区间样本采样较为稀疏或存在某种异常。
# scatter plot also showing divergences
color_scheme_set("darkgray")
mcmc_scatter(
as.matrix(fit2),
pars = c("tau", "theta[1]"),
np = nuts_params(fit2),
np_style = scatter_style_np(div_color = "green", div_alpha = 0.8)
)
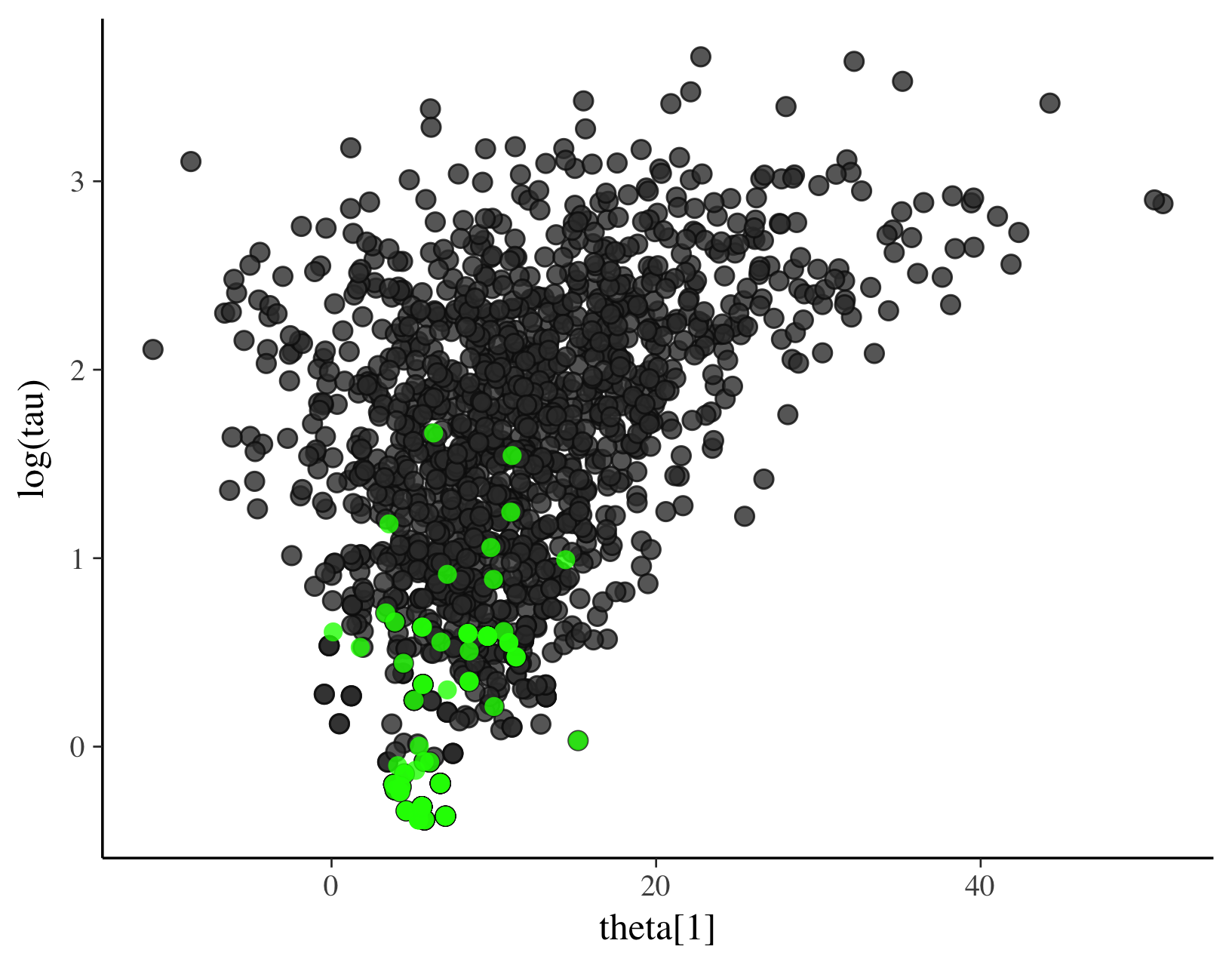
横轴表示某个变量 theta[1],竖轴表示另一个变量的对数值 log(tau)。图中的点代表两个变量之间的关系或观测点。大部分点用黑色表示,但也有一些点用绿色突出显示,这些绿色的点可能代表特定的子集或具有特殊意义的数据点(例如,可能表示异常值、特定群组的数据点、或者是满足某种条件的数据点)。
这种类型的图通常用于探索两个变量之间的关系,查看数据分布的模式,或识别数据的特定特征。例如,在统计或数据分析中,绿色点可能表示标准差内的数据点,或是那些在某种统计检验下显著的点。在贝叶斯分析中,可能表示后验分布中高概率密度区域的样本点。
color_scheme_set("red")
np <- nuts_params(fit2)
mcmc_nuts_energy(np) + ggtitle("NUTS Energy Diagnostic")
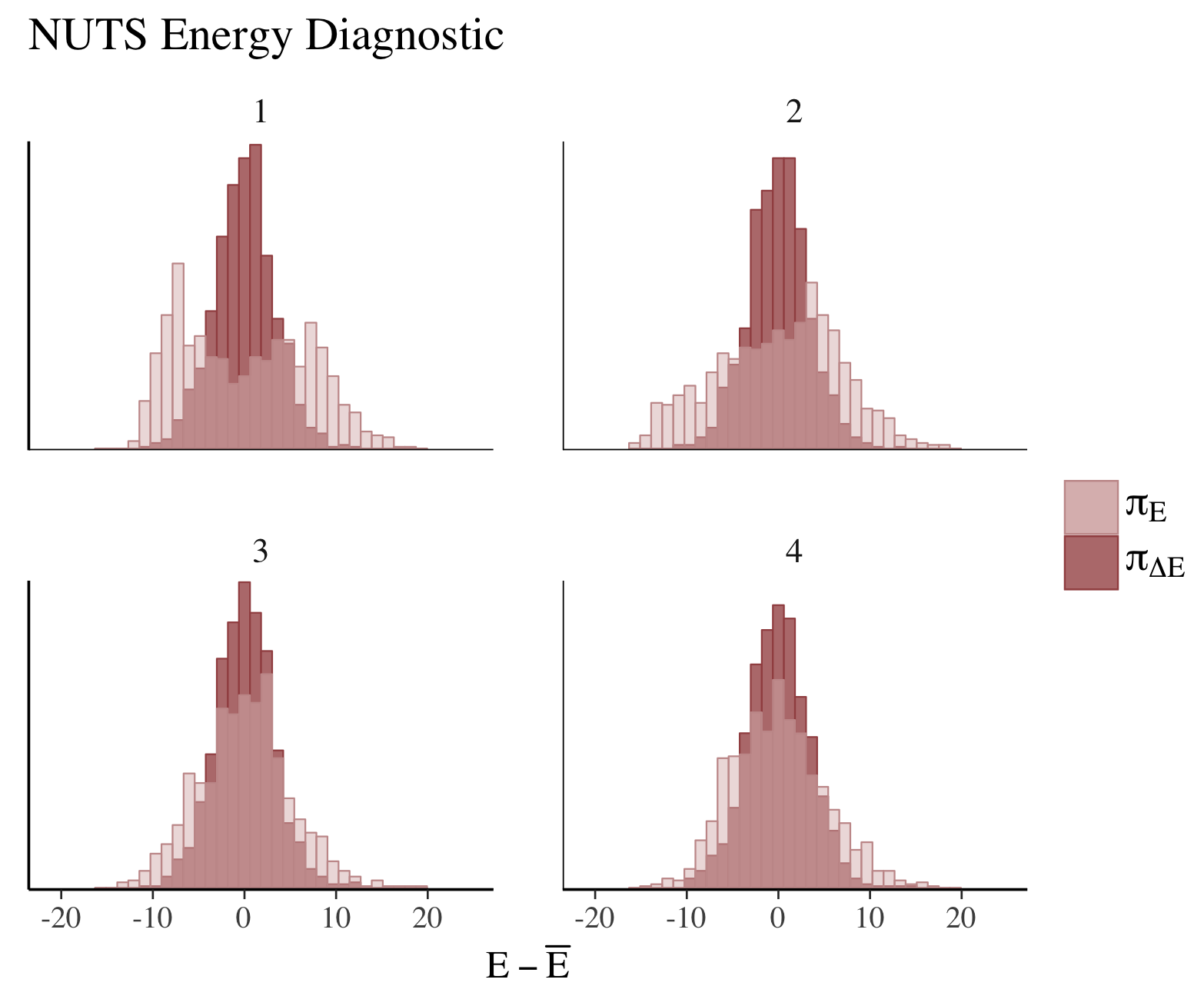
图中的四个直方图分别代表了不同的 MCMC 链或是同一链的不同采样段,显示了以下内容:
- E− Eˉ:横轴上的差值 E− Eˉ是单个采样的能量减去所有采样的平均能量。理想情况下,这个分布应该是以 0 为中心的,这表示能量水平在采样间是一致的。
- Eˉ和 ΔEˉ:在图例中提到的这两个参数,一般表示能量的平均值 (Eˉ) 和能量差的平均值 (ΔEˉ)。
能量诊断图可以帮助诊断采样过程中可能的问题。如果这些能量差的分布不是以 0 为中心,或者分布的形状看起来非对称或者非常长的尾巴,这可能意味着采样过程有问题。这种问题可能是由于模型设置不当、采样步长不合适,或者可能需要更多的迭代来达到平稳分布。
# another example with rstanarm
color_scheme_set("purple")
fit <- stan_glmer(mpg ~ wt + (1|cyl), data = mtcars)
ppc_intervals(
y = mtcars$mpg,
yrep = posterior_predict(fit),
x = mtcars$wt,
prob = 0.5
) +
labs(
x = "Weight (1000 lbs)",
y = "MPG",
title = "50% posterior predictive intervals \nvs observed miles per gallon",
subtitle = "by vehicle weight"
) +
panel_bg(fill = "gray95", color = NA) +
grid_lines(color = "white")

这张图显示了汽车重量与每加仑行驶英里数(miles per gallon, MPG)之间的关系,并用贝叶斯模型的后验预测区间进行了标注。横轴是汽车的重量(以千磅为单位),纵轴是MPG。图中有两种类型的点:
- 实心圆点 (y): 这些表示实际观察到的每加仑行驶英里数的数据点。
- 空心圆点 (y_rep): 表示后验预测数据点,即基于模型参数后验分布的预测值。
每个预测点旁边的线表示该点的50%后验预测区间。这个区间是从模型的预测分布中得到的,表示我们有50%的信心该实际值会落在这个区间内。
原文地址:https://blog.csdn.net/weixin_48093827/article/details/138164819
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!