YOLC: You Only Look Clusters for Tiny Object Detection in Aerial Images
摘要
由于以下因素,从航拍图像中检测物体面临着重大挑战:1)航拍图像通常具有非常大的尺寸,通常有数百万甚至数亿像素,而计算资源有限。2)物体尺寸较小导致有效信息不足,无法进行有效检测。3)物体分布不均匀导致计算资源浪费。为了解决这些问题,我们提出YOLC(You Only Look Clusters),一种基于无锚点目标检测器CenterNet的高效且有效的框架。为了克服大规模图像和非均匀物体分布带来的挑战,我们引入了一个局部尺度模块(LSM),该模块自适应地搜索聚类区域以进行缩放以进行准确检测。此外,我们使用高斯Wasserstein距离(GWD)修改回归损失,以获得高质量的边界框。在检测头中采用了可变形卷积和细化方法,以增强对小物体的检测。我们在两个航拍图像数据集Visdrone2019和UAVDT上进行了大量实验,以证明我们提出的方法的有效性和优越性。
关键词:航拍图像、小物体、目标检测、非均匀数据分布。

一、引言
近年来,目标检测领域取得了显著进展,尤其是随着深度学习的快速发展。目标检测器(例如Faster R-CNN[1]、YOLO[2]和SSD[3])在自然图像数据集(例如MS COCO[4]、Pascal VOC[5])上取得了令人瞩目的成果。然而,它们在航拍图像上的表现,在准确性和效率方面仍远未达到令人满意的水平。
航拍图像通常由无人机(UAVs)、飞机和卫星捕获,这种鸟瞰视角和广阔的视野使它们与自然图像有所不同。在航拍图像中进行目标检测更具挑战性,这主要有三个原因:1)航拍图像通常非常大,超出了当前设备的处理能力。因此,这些图像需要缩小尺寸或分割成小块以进行检测。2)微小物体在航拍图像中占有相当大的比例,这使得检测器在有限分辨率和视觉特征的情况下难以识别小物体。一般来说,小物体指的是面积小于32×32的物体[4]。3)航拍图像中的物体分布不均匀。例如,在图1(b)中,一些车辆聚集在交叉路口,而一些车辆或行人则零星出现。密集区域的物体应得到更多关注,而背景则应被忽略。
早期的研究工作[6]、[7]提出了新颖的多尺度训练策略,如用于图像金字塔的尺度归一化(SNIP)[6]及其改进版本[7]。这些方法可以有效地提高小物体的检测性能,但多尺度训练对计算资源和内存容量的需求较大。另一种方法是提高图像分辨率或特征分辨率。例如,可以使用生成对抗网络(GAN)来补偿小物体信息损失[8],从而缩小小物体和大物体在特征表示上的差异;但计算成本会很高。最近,一些基于标签分配的方法[9]、[10]旨在改进针对罕见小物体样本的样本分配策略。它们提高了小物体的检测性能,但在准确性或效率方面仍有改进空间。
高分辨率航拍图像中小物体分布的不均匀性给检测器带来了重大挑战,导致在大规模航拍图像上效率或准确性降低。为了解决这些问题,一个直接的方法是将图像分割成多个小块并放大它们,如均匀裁剪方法[11]所示。然而,这种方法没有考虑到物体分布的不均匀性,并且检测所有小块仍然需要花费大量时间。
为了应对上述挑战,主流解决方案提出了设计专门方案来定位聚类区域的方法[11]-[15],随后用于检测。ClusDet[12]采用聚类检测网络来检测物体聚类。DMNet[13]通过密度图对物体分布进行建模,并生成聚类区域。这些策略由于保留了聚类区域并尽可能抑制了背景,因此展现出了令人鼓舞的结果。然而,对每个裁剪块的独立检测降低了推理速度。此外,虽然上述方法生成了聚类区域,但一些聚类中的物体分布是稀疏的,对最终性能贡献不大。因此,在航拍图像的目标检测中实现准确性和效率之间的最佳权衡是一个关键问题。
受到这些观察的启发,我们提出了一种创新性的无锚点聚类网络——You Only Look Clusters(YOLC),用于航拍图像的目标检测。我们的模型以CenterNet[16]为基础,该模型具有简单性、可扩展性和高推理速度,直接预测物体的中心,无需依赖特定的锚点框。这使得它成为检测航拍图像中密集和小物体更合适的选择。值得注意的是,其他研究人员也利用CenterNet框架,通过中心点感知网络[17]或关键点[18]对遥感物体进行建模。CenterNet[16]使用密度图(也称为热图)来估计物体位置。热图提供了关于物体分布的洞察,使我们能够区分聚类区域和稀疏区域。基于这一洞察,我们开发了一个局部尺度模块(Local Scale Module,LSM),它可以自适应地搜索聚类区域,并将它们调整到适合检测器有效工作的适当尺度。
所提出的LSM相比现有的图像裁剪策略[12]、[13]、[15]具有几个优势。首先,它是一个无监督模块,这意味着它可以无缝地集成到任何基于关键点的检测器中,无需额外的聚类提议网络。这简化了训练过程并降低了检测系统的整体复杂性。其次,LSM易于实现且内存消耗低,使其适用于现实世界的应用。最后,与现有工作[12]、[13]、[15]相比,LSM生成的图像裁剪块更少,并以高推理速度实现了出色的性能。这使得它成为检测大规模航拍图像中物体的实用解决方案。
为了实现更精确的目标检测,我们对CenterNet进行了几项改进。首先,我们使用高斯Wasserstein距离(GWD)[19]修改了回归损失,它特别适合检测小物体,但可能导致大物体性能下降。为了解决这个问题,我们提出了 G W D + L 1 GWD+L_{1} GWD+L1损失,它结合了两种损失函数的优点。
此外,我们通过使用可变形卷积来改进检测头,以细化边界框回归。我们还为热图设计了一个解耦分支,允许更准确地定位不同物体类别。总的来说,这些改进使我们的YOLC模型能够在航拍图像中实现更精确和准确的目标检测。
总结来说,本文的主要贡献如下:
1)我们提出了一种新颖且高效的无锚点目标检测框架YOLC,该框架在两个航拍图像数据集上达到了最先进的性能。与许多现有方法相比,它简单而优雅,仅包含一个网络,从而减少了参数数量并提高了效率。
2)我们引入了一个轻量级的无监督局部尺度模块(LSM),用于自适应地搜索聚类区域。
3)我们设计了一个基于GWD的改进回归损失函数,该函数对小物体检测更为高效。
4)我们还提出了一个改进的检测头,它利用可变形卷积进行精确的边界框回归,并设计了一个解耦的热图分支,以精确定位不同类别的物体。
5)在两个航拍图像数据集上进行的大量实验证明了所提出方法的有效性和相对于最先进方法的优越性。
II. 相关工作
目标检测方法大致可分为两类:基于锚点的方法和无锚点方法。基于锚点的模型又可以进一步分为两阶段和单阶段方法,这取决于它们是否使用候选提议。两阶段方法主要包括Faster RCNN [1]、Mask RCNN [20]和R-FCN [21]。另一方面,单阶段检测器直接回归边界框和类别,无需提议阶段。单阶段方法的代表性例子包括YOLO系列[22]、[23]、SSD [3]和RetinaNet [24]。
无锚点模型则不需要复杂的手工制作的锚点。一些无锚点模型,如FCOS [26]和Foverbox [25],预测位置到边界框四边的距离。另外,还有一些无锚点方法只预测物体的角点或中心点,包括CornerNet [27]、Cornernet-lite [28]和CenterNet [16]、[29]。虽然这些检测器在自然场景中的表现良好,但当应用于航拍图像时,往往无法获得满意的结果。
小物体检测是一个具有挑战性但又具有重要意义的话题。与一般目标检测不同,小物体检测面临着信息丢失、特征表示噪声多、对边界框扰动的容忍度低以及样本不足等问题[30]。程等人[30]对小物体检测方法进行了广泛的综述,将它们归类为样本导向[10]、[31]、尺度感知[6]、[7]、[32]、[33]、基于超分辨率[8]、[34]、上下文建模[35]以及聚焦与检测[12]、[13]、[36]等多种方法。然而,航拍图像通常包含大量小物体且尺寸较大,在庞大的背景上进行检测会消耗大量计算资源却毫无效果。在各种方法中,聚焦与检测技术被发现更为准确且内存高效,尤其优于超分辨率方法。因此,聚焦与检测技术被广泛用于航拍图像目标检测,也被称为基于图像裁剪的方法。
III. 提出的方法
A.预备知识
密度图是一种强大的工具,能够提供图像中物体分布的信息。在CenterNet中,密度图用于定位物体。为了提高检测器对小物体的检测性能,我们使用转置卷积层将特征图上采样到与输入图像大小相匹配。此外,我们还提出了一个局部尺度模块,该模块利用热图自适应地搜索聚类区域,并调整其大小以适应检测器,从而进一步提高检测准确性。
B. 你只看集群(YOLC)
所提出的YOLC遵循与CenterNet [16]相似的流程,但其在骨干网络、检测头、回归方式和损失函数上与CenterNet有所不同。具体来说,YOLC采用HRNet [38]作为骨干网络,以生成高分辨率的热图,这些热图更擅长检测小物体。此外,由于航拍图像中物体的分布不均衡,我们设计了一个局部尺度模块(LSM)来自适应地搜索聚类区域。在检测原始图像和裁剪图像后,密集区域的精炼结果将直接替代原始图像的结果。
在后续部分,我们将深入探讨YOLC中各个模块的细节。
C. 高分辨率热图
为了提高充满小物体的密集区域中物体检测的准确性,YOLC使用了高分辨率热图。在CenterNet中,每个物体都被建模为其边界框中心的单个点,并在热图中表示为高斯斑点。然而,热图的分辨率相对于输入图像会缩小4倍。这种下采样可能会导致小物体在热图中收缩成几个点,甚至是一个点,这使得准确定位它们的中心变得困难。
为了解决这个问题,YOLC采用了一个修改后的流程,该流程使用高分辨率热图。具体来说,我们添加了一个卷积层和两个转置卷积层,以将热图的大小扩展到与输入图像相同。这使得我们能够捕获关于小物体的更多详细信息,从而提高了在密集区域中物体检测的准确性。
在应用解码前的高斯滤波器有助于减少CenterNet中的误报预测。该滤波器能够平滑热图并抑制物体周围的多个峰值。这种方法有助于提高物体的定位准确性,并降低误分类的可能性。
D. 局部尺度模块
感兴趣区域提议方法是基于裁剪的对象检测模型的关键组成部分。然而,在航拍图像中,诸如车辆和行人等物体往往聚集在少数几个聚类区域中。图像中的大多数区域都是背景,不需要进行检测。此外,密集区域的有限分辨率可能导致检测性能显著下降。现有的基于裁剪的方法,如DMNet [13],会产生许多裁剪结果,或者像ClusDet [12]那样使用额外的网络,从而导致检测速度降低和模型参数增加。
因此,我们提出了局部尺度模块(Local Scale Module,LSM)来解决这一问题。LSM旨在自适应地搜索这些聚类区域,并调整其大小以适应检测器。通过减少不必要的背景裁剪并专注于包含物体的聚类区域,LSM能够显著提高检测效率并减少计算资源的浪费。此外,通过精心调整裁剪区域的大小,我们可以更好地处理不同尺度的物体,从而提高检测精度。
为了解决这些问题,我们提出了一个局部尺度模块(LSM),它可以自适应地定位聚类区域。我们的LSM受到了AutoScale [39]的启发,但我们对其进行了几项修改,使其更适合航拍图像。首先,与仅搜索单个最大聚类区域不同,我们的LSM可以通过对每个网格中的密度进行排序来定位前K个密集区域。这很重要,因为航拍图像中往往存在多个聚类区域。其次,AutoScale是为人群计数和定位设计的[40],[41],它只适用于包含单一类别物体的场景。然而,在航拍图像中,存在多个物体类别。
我们还注意到,UCGNet [42]使用诸如DBSCAN和K-Means等聚类方法来从密集区域生成图像裁剪。然而,UCGNet生成的裁剪结果仍然尺寸较大,并且没有考虑不同裁剪之间密度的差异。
接下来,我们将详细介绍我们提出的LSM,其结构如图2所示。
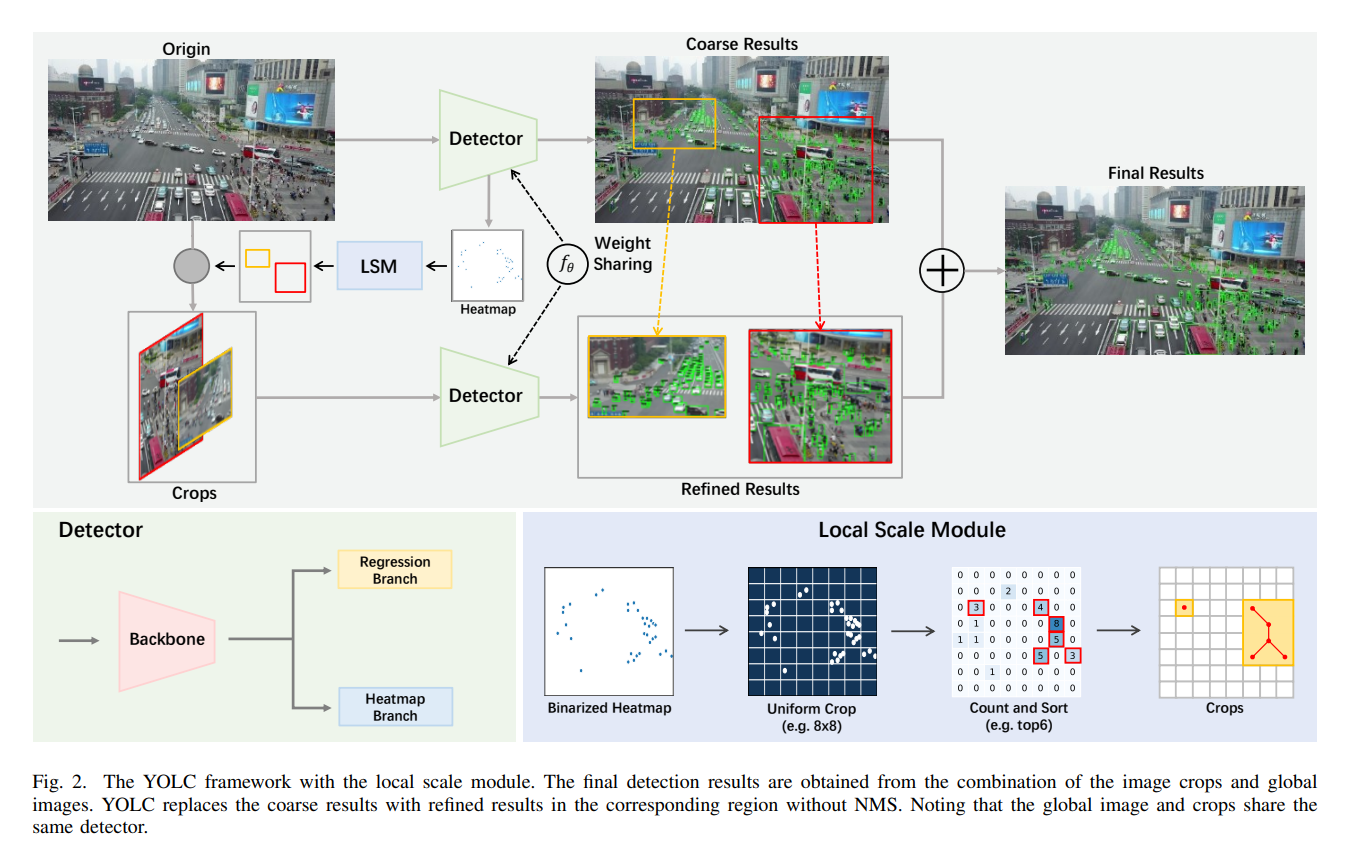
为了生成候选区域,第一步是生成一个二值图像,表示物体的存在。这是通过从每个图像的heatmap分支获取heatmap,然后使用经验阈值对heatmap进行二值化并生成位置掩码来实现的。接着,将二值化的heatmap划分为多个网格(例如,16×10),并选择前K个(例如,K=15)密集网格作为候选区域。对于VisDrone数据集,最佳超参数是网格=(16,10)和前K=50。为了确保捕获完整的物体,将八个相邻的密集网格组合成更大的候选区域,这与[13]中的方法类似。然后,将这些区域放大1.2倍以避免截断。
最后,通过从原始图像中裁剪密集区域并调整其大小以适应检测器,获得k个图像块。完整的算法如算法1所示。
为了加速检测并实现更高的性能提升,我们旨在生成更少的裁剪结果。我们为每个图像设置k=2,并专注于较大的密集区域,因为在较大的裁剪结果上进行精细检测可以带来更高的性能提升。在后续的实验中,观察到当k从3开始增加时,性能趋于饱和。因此,LSM利用极少量的高质量裁剪结果来进行精确检测,在检测速度和准确性之间取得了良好的平衡。此外,LSM是一个无监督的模块,可以轻松地集成到任何基于关键点的检测器中。
E. 损失函数
CenterNet [16] 整合了三个损失函数来优化整个网络,
L d e t = L k + λ s i z e L s i z e + λ o f f L o f f (1) L_{det} = L_{k} + \lambda_{size} L_{size} + \lambda_{off} L_{off} \tag{1} Ldet=Lk+λsizeLsize+λoffLoff(1)
其中, L k L_{k} Lk 是 CenterNet [16] 中的改进焦点损失。 L o f f L_{off} Loff 是中心点偏移损失。 L s i z e L_{size} Lsize 是尺寸回归损失。默认情况下, λ s i z e \lambda_{size} λsize 和 λ o f f \lambda_{off} λoff 分别设置为 0.1 和 1。
CenterNet 目前使用 L 1 L_{1} L1 损失(即平均绝对误差 MAE)进行尺寸回归的做法存在局限性。具体来说,它对物体尺寸的变化很敏感,并且单独回归物体的高度和宽度,导致损失忽略了每个物体坐标之间的相关性。这与基于 IoU 的损失不同,后者将这些坐标作为一个整体进行优化,从而提供更稳健的预测。此外,使用 L 1 L_{1} L1 损失可能会导致度量和回归损失之间的不一致,因为较小的训练损失并不能保证更高的性能 [19]。最后,一些具有相同 L 1 L_{1} L1 损失的预测边界框可能对应于每个边界框与匹配的真实值之间的不同 IoU,这进一步突出了 L 1 L_{1} L1 损失在尺寸回归方面的局限性。
为了解决这个问题,我们引入了一种基于高斯瓦瑟斯坦距离(GWD) [19] 的度量方法,用于测量两个边界框之间的相似性。具体来说,给定一个边界框 B ( x , y , h , w ) \mathcal{B}(x, y, h, w) B(x,y,h,w),其中 ( x , y ) (x, y) (x,y) 表示中心坐标, w w w 和 h h h 分别表示宽度和高度。我们首先将其转换为一个二维高斯分布。根据 GWD,转换后的高斯分布定义如下:
f ( x ∣ μ , Σ ) = exp ( − 1 2 ( x − μ ) ⊤ Σ − 1 ( x − μ ) ) 2 π ∣ Σ ∣ 1 2 (2) f(\mathbf{x} \mid \boldsymbol{\mu}, \boldsymbol{\Sigma}) = \frac{\exp \left(-\frac{1}{2}(\mathbf{x}-\boldsymbol{\mu})^{\top} \boldsymbol{\Sigma}^{-1}(\mathbf{x}-\boldsymbol{\mu})\right)}{2 \pi|\boldsymbol{\Sigma}|^{\frac{1}{2}}} \tag{2} f(x∣μ,Σ)=2π∣Σ∣21exp(−21(x−μ)⊤Σ−1(x−μ))(2)
其中, μ \boldsymbol{\mu} μ 和 Σ \boldsymbol{\Sigma} Σ 分别表示高斯分布的均值向量和协方差矩阵。 μ \boldsymbol{\mu} μ 和 Σ \boldsymbol{\Sigma} Σ 的具体形式为:
μ = ( x , y ) T , Σ = ( ω 2 / 4 0 0 h 2 / 4 ) (3) \boldsymbol{\mu} = (x, y)^{T}, \quad \boldsymbol{\Sigma} = \left(\begin{array}{cc} \omega^{2} / 4 & 0 \\ 0 & h^{2} / 4 \end{array}\right) \tag{3} μ=(x,y)T,Σ=(ω2/400h2/4)(3)
根据最优传输理论,两个分布 μ \mu μ 和 ν \nu ν 之间的瓦瑟斯坦距离可以计算为:
W ( μ ; ν ) : = inf E ( ∥ X − Y ∥ 2 2 ) 1 / 2 (4) \mathbf{W}(\mu ; \nu) := \inf \mathbb{E}\left(\|\mathbf{X}-\mathbf{Y}\|_{2}^{2}\right)^{1 / 2} \tag{4} W(μ;ν):=infE(∥X−Y∥22)1/2(4)
其中,下确界遍历所有随机向量 ( X , Y ) (\mathbf{X}, \mathbf{Y}) (X,Y),属于 R n × R n \mathbb{R}^{n} \times \mathbb{R}^{n} Rn×Rn 且满足 X ∼ μ \mathbf{X} \sim \mu X∼μ 和 Y ∼ ν \mathbf{Y} \sim \nu Y∼ν。因此,给定两个二维高斯分布 N ( μ 1 , Σ 1 ) \mathcal{N}\left(\boldsymbol{\mu}_{1}, \boldsymbol{\Sigma}_{1}\right) N(μ1,Σ1) 和 N ( μ 2 , Σ 2 ) \mathcal{N}\left(\boldsymbol{\mu}_{2}, \boldsymbol{\Sigma}_{2}\right) N(μ2,Σ2),瓦瑟斯坦距离计算为:
W 2 = ∥ μ 1 − μ 2 ∥ 2 2 + Tr ( Σ 1 + Σ 2 − 2 ( Σ 1 1 / 2 Σ 2 Σ 1 1 / 2 ) 1 / 2 ) (5) \mathbf{W}^{2} = \left\|\boldsymbol{\mu}_{1}-\boldsymbol{\mu}_{2}\right\|_{2}^{2} + \operatorname{Tr}\left(\boldsymbol{\Sigma}_{1}+\boldsymbol{\Sigma}_{2}-2\left(\boldsymbol{\Sigma}_{1}^{1 / 2} \boldsymbol{\Sigma}_{2} \boldsymbol{\Sigma}_{1}^{1 / 2}\right)^{1 / 2}\right) \tag{5} W2=∥μ1−μ2∥22+Tr(Σ1+Σ2−2(Σ11/2Σ2Σ11/2)1/2)(5)
通过这种方法,我们能够更全面地衡量两个边界框之间的相似性,特别是在考虑其尺寸和形状时。这有助于改进检测器的性能,特别是在处理具有不同尺寸和形状的物体时。
值得注意的是,我们有:
Tr ( ( Σ 1 1 / 2 Σ 2 Σ 1 1 / 2 ) 1 / 2 ) = Tr ( ( Σ 2 1 / 2 Σ 1 Σ 2 1 / 2 ) 1 / 2 ) (6) \text{Tr}\left(\left(\boldsymbol{\Sigma}_{1}^{1 / 2} \boldsymbol{\Sigma}_{2} \boldsymbol{\Sigma}_{1}^{1 / 2}\right)^{1 / 2}\right)=\text{Tr}\left(\left(\boldsymbol{\Sigma}_{2}^{1 / 2} \boldsymbol{\Sigma}_{1} \boldsymbol{\Sigma}_{2}^{1 / 2}\right)^{1 / 2}\right) \tag{6} Tr((Σ11/2Σ2Σ11/2)1/2)=Tr((Σ21/2Σ1Σ21/2)1/2)(6)
由于检测任务使用水平边界框作为真实值,我们有 Σ 1 Σ 2 = Σ 2 Σ 1 \Sigma_{1} \Sigma_{2} = \Sigma_{2} \Sigma_{1} Σ1Σ2=Σ2Σ1。那么方程(5)可以重写为以下形式[19]:
W 2 = ∥ μ 1 − μ 2 ∥ 2 2 + ∥ Σ 1 1 / 2 − Σ 2 1 / 2 ∥ F 2 = ( x 1 − x 2 ) 2 + ( y 1 − y 2 ) 2 + ( w 1 − w 2 ) 2 + ( h 1 − h 2 ) 2 4 = l 2 -norm ( [ x 1 , y 1 , w 1 2 , h 1 2 ] ⊤ , [ x 2 , y 2 , w 2 2 , h 2 2 ] ⊤ ) (7) \begin{aligned} \mathbf{W}^{2} & = \left\|\boldsymbol{\mu}_{1}-\boldsymbol{\mu}_{2}\right\|_{2}^{2}+\left\|\boldsymbol{\Sigma}_{1}^{1 / 2}-\boldsymbol{\Sigma}_{2}^{1 / 2}\right\|_{F}^{2} \\ & = \left(x_{1}-x_{2}\right)^{2}+\left(y_{1}-y_{2}\right)^{2}+\frac{\left(w_{1}-w_{2}\right)^{2}+\left(h_{1}-h_{2}\right)^{2}}{4} \\ & = l_{2} \text{-norm }\left(\left[x_{1}, y_{1}, \frac{w_{1}}{2}, \frac{h_{1}}{2}\right]^{\top},\left[x_{2}, y_{2}, \frac{w_{2}}{2}, \frac{h_{2}}{2}\right]^{\top}\right) \end{aligned} \tag{7} W2=∥μ1−μ2∥22+ Σ11/2−Σ21/2 F2=(x1−x2)2+(y1−y2)2+4(w1−w2)2+(h1−h2)2=l2-norm ([x1,y1,2w1,2h1]⊤,[x2,y2,2w2,2h2]⊤)(7)
其中
∥
⋅
∥
F
\left\|\cdot\right\|_{F}
∥⋅∥F 表示Frobenius范数。
仅使用上述损失(方程(7))可能对大误差敏感,因此,我们执行一个非线性函数,并将损失转换为亲和度度量
1
τ
+
f
(
W
2
)
\frac{1}{\tau+f\left(\mathbf{W}^{2}\right)}
τ+f(W2)1。根据[43]和[44],基于GWD的最终损失可以表示为[19]:
L g w d = 1 − 1 τ + f ( W 2 ) , τ ≥ 1 (8) L_{g w d} = 1 - \frac{1}{\tau + f\left(\mathbf{W}^{2}\right)}, \quad \tau \geq 1 \tag{8} Lgwd=1−τ+f(W2)1,τ≥1(8)
其中 f ( ⋅ ) f(\cdot) f(⋅) 是非线性函数,用于使Wasserstein距离更加平滑并更容易优化模型。我们定义 f ( x ) = ln ( x + 1 ) f(x) = \ln (x + 1) f(x)=ln(x+1)。 τ \tau τ 是一个调制超参数,经验性地设置为1。
由于基于GWD的损失已经考虑了中心偏移,我们修改了整体的检测损失如下:
L det = L k + λ g w d L g w d (9) L_{\text{det}} = L_{k} + \lambda_{g w d} L_{g w d} \tag{9} Ldet=Lk+λgwdLgwd(9)
其中 λ g w d \lambda_{g w d} λgwd 是一个权衡超参数,我们将其设置为2。
根据后续实验,用GWD损失替换 L 1 L_{1} L1损失在检测小物体时取得了显著改进。然而,对于中等和大型物体的检测性能并不如之前。为了研究GWD损失对物体大小的敏感性,我们计算了GWD损失的梯度:
∇ W L g w d = 2 W ( 1 + W 2 ) ( 1 + log ( 1 + W 2 ) ) 2 (10) \nabla_{\mathbf{W}} L_{g w d} = \frac{2 \mathbf{W}}{\left(1 + \mathbf{W}^{2}\right)\left(1 + \log \left(1 + \mathbf{W}^{2}\right)\right)^{2}} \tag{10} ∇WLgwd=(1+W2)(1+log(1+W2))22W(10)
对于大型物体,我们观察到在模型训练的早期阶段,Wasserstein距离 W \mathbf{W} W往往较高,这可能导致梯度接近0,从而影响中等和大型物体的检测。为了解决这个问题,我们提出将GWD损失与 L 1 L_{1} L1损失结合使用。具体地,我们修改了损失函数如下:
L d e t = L k + λ g w d L g w d + λ l 1 L 1 (11) L_{d e t} = L_{k} + \lambda_{g w d} L_{g w d} + \lambda_{l 1} L_{1} \tag{11} Ldet=Lk+λgwdLgwd+λl1L1(11)
其中,我们将 λ g w d \lambda_{g w d} λgwd设置为2, λ l 1 \lambda_{l 1} λl1设置为0.5。
通过引入 L 1 L_{1} L1损失,模型仍然可以学习大型物体尺寸的回归,这有助于克服上述问题。这种修改后的损失函数可以显著提高YOLC(假设这是您提到的某种物体检测算法)在检测不同大小物体时的性能。通过将GWD损失与 L 1 L_{1} L1损失相结合,我们可以平衡对小型物体检测的敏感性和对大型物体检测的准确性,从而全面提升模型的检测能力。这种混合损失策略使得模型在训练过程中能够同时关注不同尺度的物体,进而提升整体检测效果。
F. 改进的检测头
为了提升航拍图像中小物体的检测性能,我们在回归分支中增强了可变形卷积的应用。由于可变形卷积能够自适应地调整卷积操作中的采样位置,因此可以更好地捕捉小物体的细节。此外,为了更好地捕获不同类别物体的精细细节,我们将热图分支解耦为多个子分支,每个子分支负责预测特定物体类别的热图。这样做不仅减轻了同时预测所有热图的计算负担,而且使网络能够专注于学习每个类别的独特特征,从而提高了检测器的整体性能。这些改进后的检测头结构如图3所示。
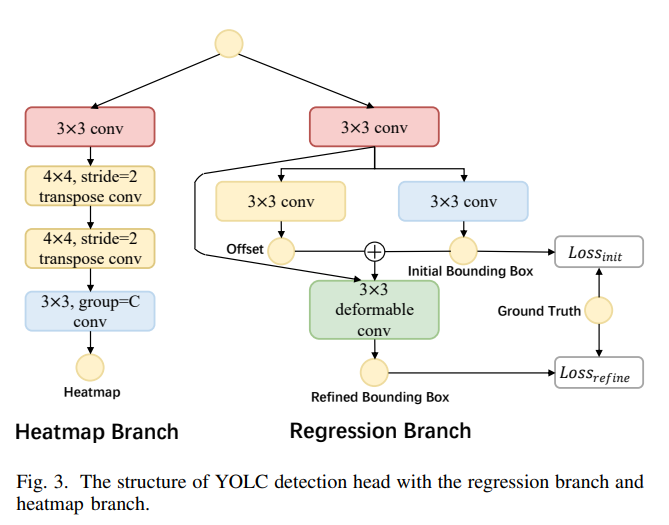
回归分支。在传统的目标检测器中,点特征被用来识别物体,这导致预测结果不够准确。为了克服这一限制,我们在回归分支中采用了可变形卷积。与在固定 3 × 3 3 \times 3 3×3网格上操作的常规卷积不同,可变形卷积动态地调整采样点以适应物体的姿态和形状。具体来说,一个常规的 3 × 3 3 \times 3 3×3网格有9个采样点,定义为 { ( − 1 , − 1 ) , ( − 1 , 0 ) , … , ( 1 , 1 ) } \{(-1,-1),(-1,0), \ldots,(1,1)\} {(−1,−1),(−1,0),…,(1,1)},而可变形卷积则估计从常规采样点到动态采样点的偏移量。
在我们的方法中,我们并行地预测粗略的边界框和偏移场。为了确保卷积能够覆盖整个物体,我们将偏移量限制在粗略的边界框内,并在它们上应用一个可变形卷积层。这产生了位置和大小更准确的细化边界框。在计算损失时,初始边界框与真实值之间的损失用 L o s s initial L o s s_{\text {initial }} Lossinitial 表示。同样地,我们可以计算关于细化边界框的 L o s s refine Loss_{\text {refine }} Lossrefine (如图3所示)。
热图分支。我们受到YOLOX [45]和DEKR [46]中使用的方法的启发,通过引入一个解耦结构来改进热图分支。模型现在并行地预测不同物体类别的热图,这使得检测更加高效和准确。具体来说,热图分支包括一个标准卷积、两个转置卷积和一个有 C C C个组的组卷积,其中每个组对应于一个特定的物体类别。
四、实验与分析
本节将介绍实验中所使用的数据集、评估指标、实现细节,并通过消融实验验证所提模块、骨干网络和损失函数的有效性。最后,我们将从定性和定量两个角度进行比较实验,以展示我们方法相较于最先进方法的优越性。
A. 数据集
我们在两个公开可用的航空图像数据集上评估我们的方法:VisDrone 2019 [47] 和 UAVDT [48]。这两个数据集的详细信息如下:
VisDrone [47] 包含 10,209 张高分辨率图像(大约 2000 × 1500 像素),涵盖十个类别:行人、人、自行车、汽车、货车、卡车、三轮车、篷三轮车、公共汽车和摩托车。数据集包含 6,471 张训练图像、548 张验证图像和 3,190 张测试图像。由于评估服务器已关闭,我们遵循 [12]、[13] 的做法,使用验证集进行评估。
UAVDT [48] 包含 38,327 张图像,平均分辨率为 1,080 × 540 像素。数据集包含三个类别,即汽车、公共汽车和卡车。其中,23,258 张图像用于训练,15,069 张图像用于测试。
B. 评估指标
我们遵循 MS COCO [4] 数据集上的评估协议,使用 AP、 A P 50 AP_{50} AP50 和 A P 75 AP_{75} AP75 作为我们的评估指标。AP 代表所有类别的平均精度,而 A P 50 AP_{50} AP50 和 A P 75 AP_{75} AP75 分别表示在所有类别上,IoU 阈值为 0.5 和 0.75 时的平均精度。此外,我们还报告每个对象类别的平均精度,以衡量每个类别的性能。为了衡量不同对象尺度的性能,我们采用三个指标,即 A P small AP_{\text{small}} APsmall、 A P medium AP_{\text{medium}} APmedium 和 A P large AP_{\text{large}} APlarge。最后,我们还通过测量每 GPU 处理一张原始图像的时间来报告我们方法的效率。
C. 实现细节
我们提出的方法基于开源的MMDetection工具箱实现 1 ^{1} 1。我们选择CenterNet [16] 作为基准方法,并采用Hourglass-104 [49] 作为骨干网络。模型使用SGD优化器进行训练,动量设为0.9,权重衰减设为0.0001。训练过程在GeForce RTX 2080 Ti GPU平台上进行,批处理大小设置为2。初始学习率设为0.01,并采用线性预热策略。对于两个数据集,输入图像的分辨率均设置为 1024 × 640 1024 \times 640 1024×640。
D. 实验结果
表I和表II分别展示了在VisDrone[47]和UAVDT[48]数据集上与最先进方法的定量比较结果。实验结果表明,我们提出的模型在这两个数据集上均一致地优于其他方法。值得注意的是,在VisDrone[47]上,由于航拍图像中存在大量小目标实例和非均匀数据分布,一般的目标检测器如Faster R-CNN[1]和CenterNet[16]表现不佳。然而,无锚点检测模型(即CenterNet[16])的表现优于基于锚点的检测方法(即Faster RCNN[1]),这与前文的分析是一致的。
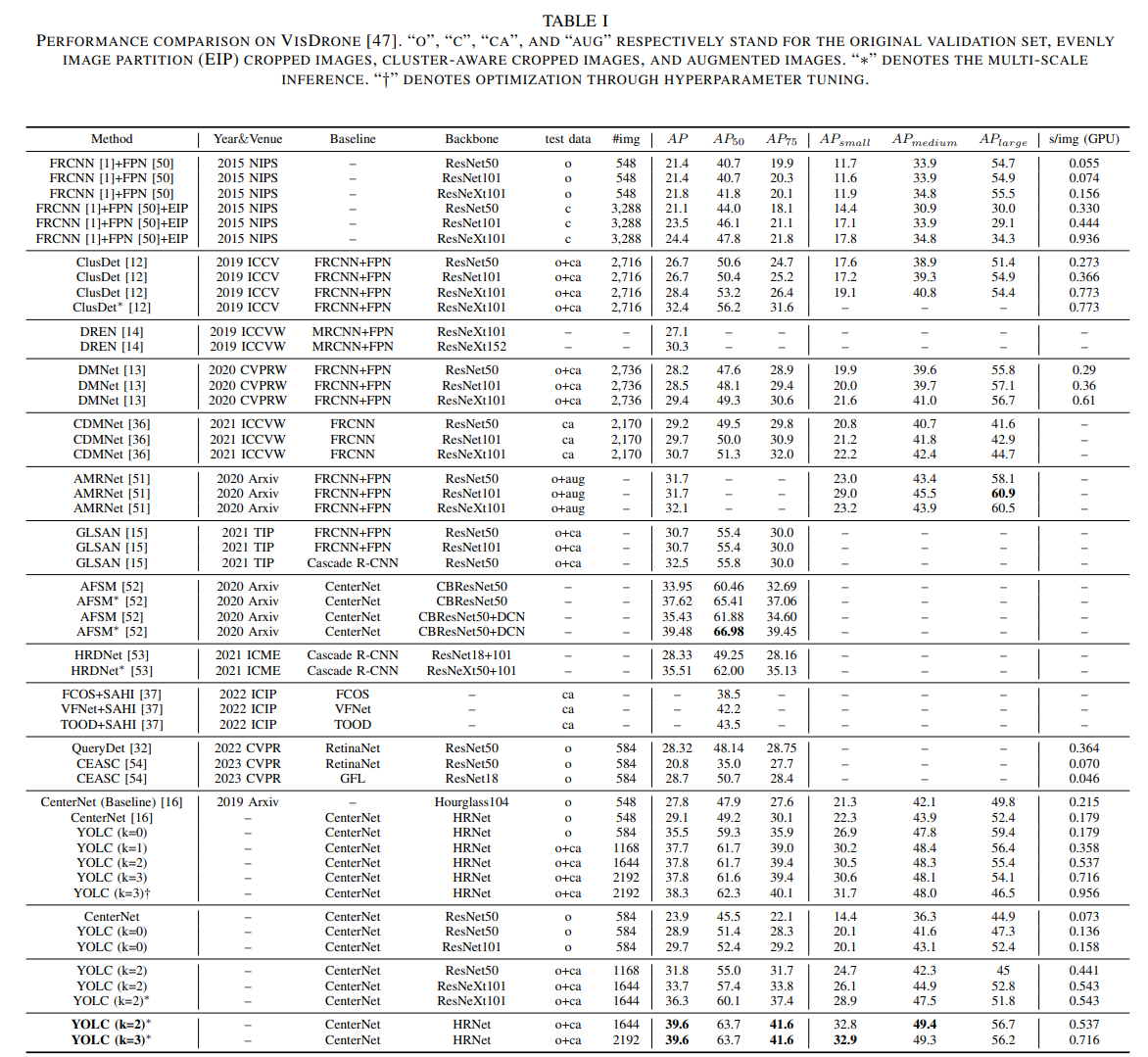
我们提出的YOLC在不使用LSM的情况下就优于现有方法,如ClusDet[12]和DMNet[13]。然而,在融入LSM后,性能得到了进一步提升。通过采用优化方案,我们实现了最佳性能,达到了38.3 AP。我们还对多尺度测试的检测结果进行了评估,这导致AP进一步提高了1.8%。值得注意的是,我们提出的YOLC显著提高了小目标的检测性能,而中大型目标的改进则不那么明显。这是可以接受的,因为小目标在航拍图像中占多数,提高它们的检测率可以显著提升整体性能。
此外,我们提出的方法在处理的图像数量(# img)相对较少、推理速度(s/img)更高、框架更简单且参数更少的情况下取得了最佳的检测结果。这充分表明了我们方法的有效性和高效性。
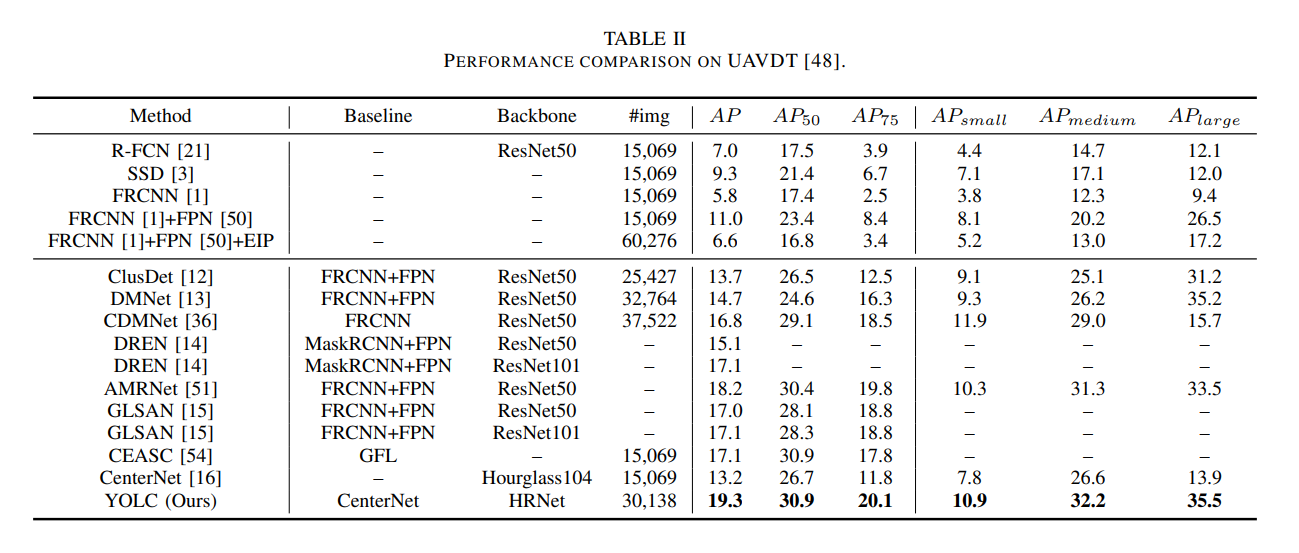
如表II所示,在UAVDT数据集上的性能评估与VisDrone[47]数据集得出了类似的结论。它表明,一般的目标检测器无法达到令人满意的检测结果,而我们提出的YOLC则优于最先进的模型,并以19.3的AP达到了最高性能。值得注意的是,YOLC在小、中、大目标上的准确度均得到了持续提升,这验证了我们专用检测框架的有效性。

在表III中,我们进一步分析了在VisDrone[47]数据集上各类别的AP。我们提出的YOLC在大多数情况下都显著优于基准模型,包括RetinaNet[24]、Faster R-CNN[1]和Cascade R-CNN[55],特别是在行人和小型人物等小目标上。然而,我们观察到某些类别,如汽车和公交车,相比于其他类别(如自行车和三轮车)取得了更好的检测性能,这可以归因于数据集中存在的严重类别不平衡问题。
为了解决这一问题,已经提出了多种方法,包括重采样[60]、[61]、重加权[62]、重平衡[63]、[64]以及两阶段训练范式[56]、[58]。尽管我们的方法并未专门针对长尾问题进行优化,但与一些专为长尾问题设计的模型相比,我们的方法在所有类别上仍然取得了最高的性能,如表III所示。这进一步验证了YOLC的泛化能力和鲁棒性,使其在不同类别的目标检测中都能表现出色。

此外,我们在图4中展示了两个数据集的检测结果可视化。从这些可视化结果中,我们可以观察到我们提出的方法实现了令人满意的检测精度。特别是,我们的方法可以检测到许多小目标,这些小目标通常容易被一般检测器遗漏,如图4第二列所示。此外,我们的方法还可以对非均匀分布的目标获得准确的检测结果,如图4第一行的第三张图所示。

进一步地,我们在图5中比较了YOLC与CenterNet的检测结果。在密集区域,YOLC能够比CenterNet更准确地检测到目标,特别是对于小目标。
E. 消融实验
为了证明我们模型中各个组件的有效性,我们在VisDrone数据集上进行了消融实验[47]。在我们的框架中,LSM是关键组件,对整体性能的提升最为显著。
-
不同骨干网络。为了增强航空图像中小物体的检测能力,我们将CenterNet中的Hourglass骨干网络[16]替换为高分辨率网络HRNet[38]。如表I所示,这一简单的修改使性能提高了 1.3 % 1.3\% 1.3%,证明了使用HRNet提取更鲁棒的特征的有效性,特别是对于小物体。因此,在后续的实验中,我们使用HRNet作为我们的骨干网络。
-
LSM的影响。我们提出了一个LSM模块来解决非均匀分布问题。如表I所示,我们发现当裁剪的聚类区域数量设置为 k = 1 k=1 k=1时,性能提高了 2.2 % 2.2\% 2.2%。值得注意的是,小物体的性能提升更为显著,提高了 3.3 % 3.3\% 3.3%。然而,随着 k k k的增加,性能提升趋于饱和。当 k = 2 k=2 k=2和 k = 3 k=3 k=3时,我们在 A P small AP_{\text{small}} APsmall上观察到进一步的提升,分别为 0.3 % 0.3\% 0.3%和 0.1 % 0.1\% 0.1%。因此,为了充分利用LSM模块的优势,我们在后续的实验中设置 k = 3 k=3 k=3。

-
LSM中的超参数。我们展示了LSM中两个超参数Grid和top-K的消融实验(如图6所示)。Grid表示网格的大小,而top-K表示候选区域的数量。特别地,我们观察到初始的超参数配置并不是最优的。当Grid为 ( 16 , 10 ) (16,10) (16,10)且top-K超过总Grid数量的 30 % 30\% 30%时,可以获得最佳结果,达到 38.3 % m A P 38.3\% \mathrm{mAP} 38.3%mAP。
-
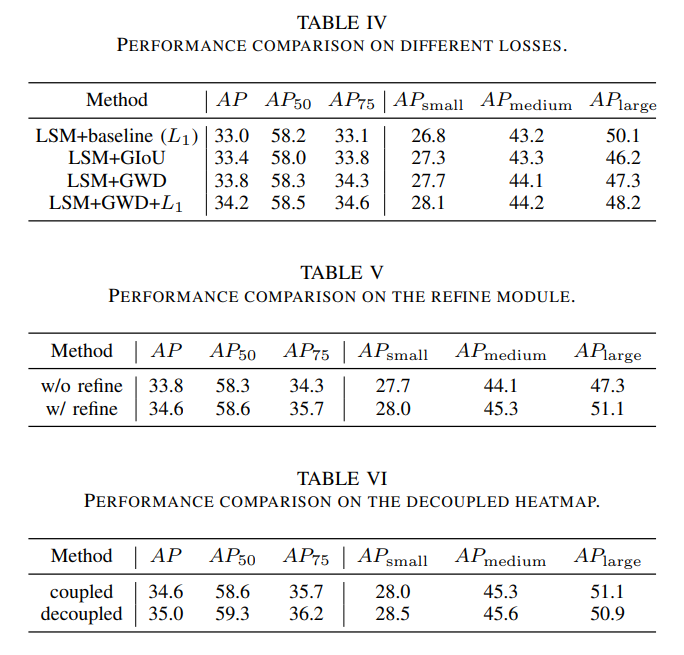
不同的损失函数。为了优化提出的YOLC网络,我们对回归损失进行了若干改进。具体来说,我们将原始的 L 1 L_{1} L1损失替换为GWD损失[19],并尝试使用基于IoU的损失,如GIoU[43]、DIoU[44]和CIoU[44]。我们还使用改进的GIoU损失来适应我们的无锚点检测器[52]。选择这些损失函数是为了解决对尺度变化的敏感性和度量与损失之间的不一致性。这些实验的结果如表IV所示。我们发现,使用替代回归损失时,性能进一步提高, A P AP AP提高了 0.4 % 0.4\% 0.4%和 0.8 % 0.8\% 0.8%,其中 A P small AP_{\text{small}} APsmall分别提高了 0.5 % 0.5\% 0.5%和 0.9 % 0.9\% 0.9%。然而, A P medium AP_{\text{medium}} APmedium和 A P large AP_{\text{large}} APlarge有所下降。基于第三节-E的分析,我们发现GWD+ L 1 L_{1} L1损失缓解了这一现象, A P small AP_{\text{small}} APsmall进一步提高了 1.3 % 1.3\% 1.3%。
-
细化模块的影响。为了进一步提高YOLC网络在小物体上的性能,我们引入了一个可变形卷积模块来细化回归头。该模块可以动态地提取点特征,为每个对象生成更精确的表示。如表V所示,提出的可变形卷积提高了 A P 75 AP_{75} AP75达 1.4 % 1.4\% 1.4%,表明边界框回归实现了更高的定位精度。此外,所有评估指标均显示了一致的改进,对于较大对象的改进更为明显。这一改进可归因于可变形卷积能够更好地捕获整个对象,尤其是对于大对象,传统卷积可能难以覆盖对象的全部内容。
-
解耦热图分支的影响。为了提高对象定位精度,我们将热图分支解耦为并行分支,每个分支独立地为对应对象类别生成热图。表VI中的结果表明,这种方法在所有评估指标上都取得了一致的改进,验证了解耦热图的有效性。特别值得注意的是, A P small AP_{\text{small}} APsmall进一步提高了 0.4 % 0.4\% 0.4%,这表明这种技术对于检测小对象特别有效。
V. 结论
本文介绍了YOLC框架,一个无锚点网络,旨在解决航空物体检测中的两个挑战性问题:小物体检测以及严重非均匀数据分布的处理。为了解决前者,我们提出了一个基于CenterNet的改进模型,该模型使用转置卷积输出高分辨率特征图,并解耦热图以学习不同物体类别的专用表示。这种方法显著提高了检测性能,特别是对于小物体。对于后者,我们引入了一个局部尺度模块,该模块自适应地搜索聚类物体区域并重新缩放它们,以更好地适应物体检测器。为了进一步提高网络的性能,我们采用基于GWD的损失函数来替代原始CenterNet中的大小回归损失,使模型更专注于小物体。为了补偿上述损失导致的大物体性能下降,我们提出使用L₁损失来辅助GWD损失。此外,我们还利用一个可变形模块来优化边界框回归。我们的框架通过局部尺度模块在准确性和速度之间取得了平衡。我们通过在两个航空图像数据集上进行的大量实验,与最先进的方法相比,展示了我们的方法的有效性和优越性。
在未来的工作中,我们将努力将我们的方法扩展到特征级别,用于微小物体检测。例如,模型可以直接学习放大图像的特征,而不是将放大图像输入到骨干网络中获取特征。
原文地址:https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/137777103
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!