ProtoBuf快速上手
此篇文章实现内容:
- 对一个通讯录的联系人信息,使用PB进行序列化,并将结果输出
- 对序列化的内容使用PB进行反序列化,解析联系人信息并输出
- 联系人信息包含:姓名、年龄
创建 .proto文件
- 建议文件名采用小写
- 后缀名为
.proto
messgae可以定义属性字段,格式为:字段类型 字段名 = 字段唯一编号
- 命名规范:全小写,多个字母之间用
_连接 - 字段类型分为标量数据类型和特殊类型
- 字段唯一编号:用来标识字段,一旦开始使用就不能改变
| .proto Type | Notes | C++ Type |
|---|---|---|
| double | double | |
| float | float | |
| int32 | 使用变长编码[1]。负数的编码效率较低⸺若字段可能为负值,应使用 sint32 代替 | int32 |
| int64 | 使用变长编码[1]。负数的编码效率较低⸺若字段可能为负值,应使用 sint64 代替 | int64 |
| uint32 | 使用变长编码[1] | uint32 |
| uint64 | 使用变长编码[1] | uint64 |
| sint32 | 使用变长编码[1]。符号整型。负值的编码效率⾼于常规的 int32 类型 | int32 |
| sint64 | 使用变长编码[1]。符号整型。负值的编码效率⾼于常规的 int64 类型 | int64 |
| fixed32 | 定长 4 字节。若值常大于2^28 则会比 uint32 更高效 | uint32 |
| fixed64 | 定长 8 字节。若值常大于2^56 则会比 uint64 更高效 | uint64 |
| sfixed32 | 定长4字节 | int32 |
| sfixed64 | 定长8字节 | int64 |
| bool | bool | |
| string | 包含 UTF-8 和 ASCII 编码的字符串,长度不能超过2^32 | string |
| bytes | 可以包含任意的字节序列,长度不超过2^32 | string |
[1]边长编码指的是:结果protobuf编码后,原本4字节或8字节的数可能会变为其他字节数
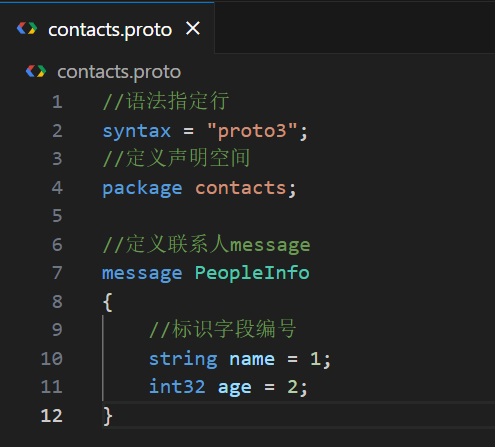
//语法指定行
syntax = "proto3";
//定义声明空间
package contacts;
//定义联系人message
message PeopleInfo
{
//标识字段编号
string name = 1;
int32 age = 2;
}
这里字段唯一编号范围:
[1 ~ 536, 870, 911(2^29-1)]其中
19000 ~ 19999不可用,因为protobuf协议实现中,对这些数进行了预留
1 ~ 15字段编号需要一个字节进行编码
6 ~ 2047需要两个字节进行编码。编码之后的字节不仅仅包含编号,还包含字段类型,所以
1 ~ 15要用来标记频繁出现的字段
可以按照
protobuf插件,代码会有高亮显示
编译 .proto文件
protoc --cpp_out=. contacts.proto
--cpp_out=.表明编译的proto文件会生成C++的代码,=.表明生成的C++文件在当前目录下contacts.proto表明所依赖的文件

如果不在这个目录下还想对
contacts.proto进行编译:protoc -I protobuf_10_2/ --cpp_out=protobuf_10_2/ contacts.proto
-I protobuf_10_2表示指定的搜索目录

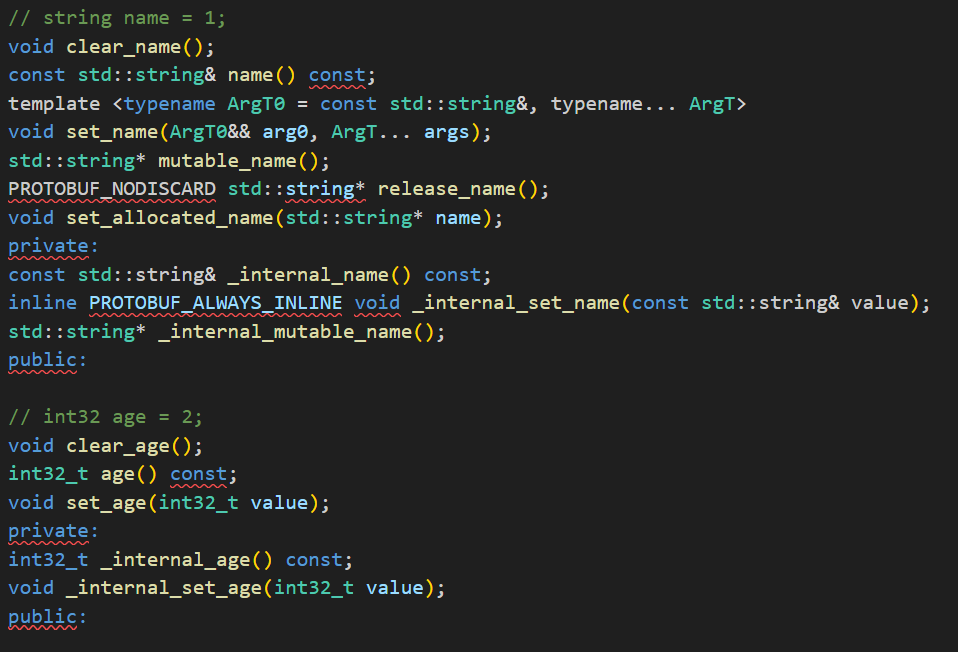
编译后生成的文件
编译之后生成了*.h和*.cc文件,分别存放类的声明和类的实现
*.h文件为例:
这里就是生成的get和set方法
序列反序列方法:
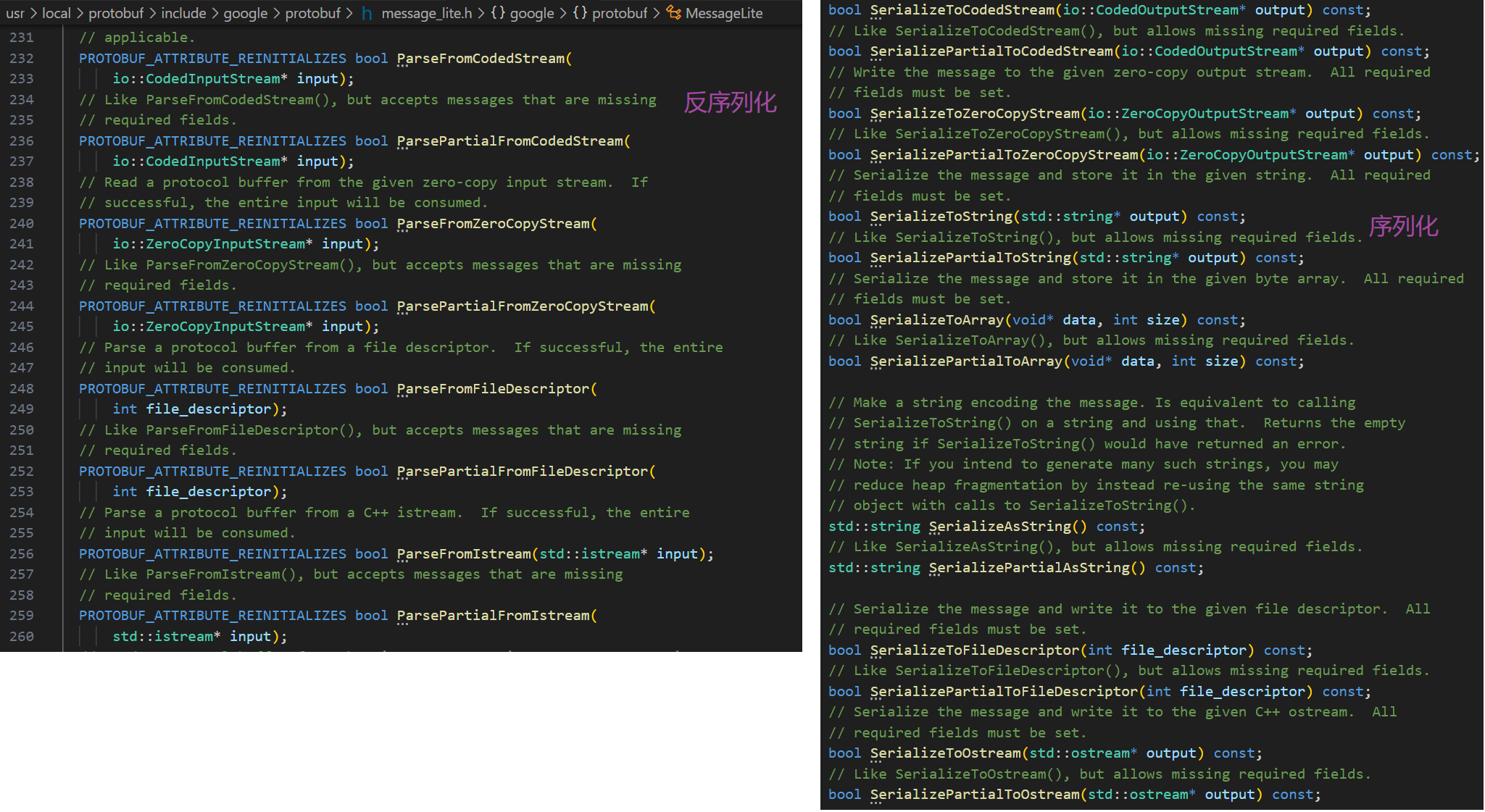
- 在序列反序列化方法,都是继承
message,message继承MessageLite,里面提供了序列反序列化的方法- 序列化之后的结果为二进制字节序列
- 序列化的API都是
const成员函数,因为序列化不会改变类对象的内容,而是将序列化的结果保存到函数入参指定地址当中
序列化与反序列化的使用
编写测试文件main.cc:
- 对联系人信息使用PB进行序列化,将结果输出
- 对序列化内容使用PB进行反序列化,解析联系人信息并输入
#include<iostream>
#include<string>
#include<fstream>
#include"contacts.pb.h"
int main()
{
std::string people_str;
//序列化
{
contacts::PeopleInfo people;
people.set_name("张三");
people.set_age(20);
if(!people.SerializeToString(&people_str))
{
std::cerr << "serialize error" << std::endl;
return -1;
}
std::cout << "serialize success: " << people_str << std::endl;
}
//反序列化
{
contacts::PeopleInfo people;
if(!people.ParseFromString(people_str))
{
std::cerr << "parse error" << std::endl;
}
std::cout << "parse success: " << std::endl;
std::cout << "name: " << people.name() << std::endl;
std::cout << "age: " << people.age() << std::endl;
}
return 0;
}
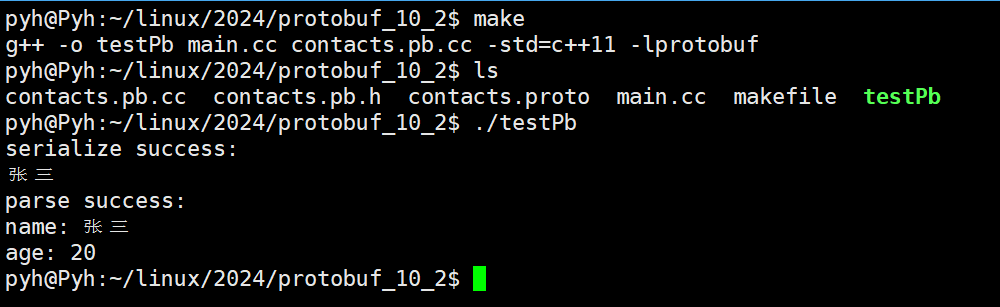
编译main.cc:
g++ -o testPb main.cc contacts.pb.cc -std=c++11 -lprotobuf
也可以使用makefile:
testPb:main.cc contacts.pb.cc
g++ -o $@ $^ -std=c++11 -lprotobuf
.PHONY:clean
clean:
rm testPb
相对于json和xml来说,protobuf编码成了二进制,破解成本较大,所以protobuf编码是较安全的。
ProtoBuf需要依赖通过编译生成的头文件和源文件使用,所以开发人员就无需编写解析协议的代码,大大提高了开发效率。
原文地址:https://blog.csdn.net/Dirty_artist/article/details/142679598
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!