记录些Redis题集(3)
分布式锁
分布式锁是一种用于在分布式系统中实现互斥访问的机制,它可以确保在多个节点、或进程同时访问共享资源。如果没有适当的锁机制,就可能导致数据不一致或并发冲突的问题。
分布式锁需要的介质
- 需要一个多个微服务节点都能访问的存储介质,需要能保存锁信息。
- 该工具上锁时要能保证原子操作,能处理并发,且能对结果进行感知。
- 节点具有强一致性,不论几个节点,客户端最终结果一致。
- 老生常谈的高可用,高性能。
分布式锁需要实现的功能
- 锁的基本要求:锁最大的要求就是互斥和可重入。
- 不同的对象不能拿到同一个锁,同一个对象可以再次访问该锁。
- 需要避免死锁:死锁四大条件里面,只要破坏一个就可以避免死锁。
互斥条件:资源是排他的,一个资源一次只能被一个对象获取。请求与保持条件:当前对象持有这个资源的是时候会请求其他的资源,并且不会放弃持有当前资源。不可剥夺条件:不可以强行从一个对象手中剥夺资源。循环等待条件:当前对象需要去等待其他对象的资源,其他对象也要等待当前对象的资源。解决方案: 超时退出最简单。
- 锁对象独占:能拿到锁,能校验锁,也能解除锁,保证锁的独占性。
- 尝试获取时间 / 超时自动释放:一个是尝试获取锁时,多久超时失败。一个是拿到锁后,多久自动释放。
- 高并发,高可用:除了锁介质需要满足这些,实现锁的方案上也有满足。
分布式锁的特点
- 互斥性:在任何时刻,只有一个客户端能够持有锁。这是分布式锁最基本的要求,确保了数据的一致性和安全性。
- 锁超时释放:锁应该有一个超时时间,在超时后自动释放,以防止客户端因异常情况无法释放锁而造成死锁。
- 可重入性:同一个客户端在持有锁的情况下可以重复获取锁,防止客户端因再次请求锁而陷入死锁。
- 公平性:锁的获取应该尽可能公平,避免某些客户端长时间等待或饿死。
- 容错性:在分布式系统中,网络或节点故障是常见问题。一个健壮的分布式锁应该能够在部分故障的情况下仍然保持其功能。
- 高可用性和高性能:分布式锁应该能够在高并发和高负载的情况下稳定运行,且性能损失尽可能小。具有较低的延迟和高吞吐量,以确保对共享资源的访问不会成为系统性能的瓶颈。
- 支持多种锁模式:如共享锁(读锁)和排他锁(写锁),以适应不同的业务场景。
- 锁的状态同步:在分布式环境中,锁的状态需要在不同的节点间同步,确保一致性。
- 锁的粒度控制:可以根据需要设置锁的粒度,如对整个资源加锁或只对资源的一部分加锁。
- 锁的阻塞和非阻塞获取:支持客户端选择阻塞或非阻塞方式获取锁,以满足不同的业务需求。
- 安全性:分布式锁应具备一定的安全性措施,如防止恶意客户端获取或释放锁。
- 可靠性(Reliability):分布式锁应该能够在各种异常情况下保持正确的行为,包括:网络分区、节点故障、客户端崩溃等情况。即使某个客户端持有锁的过程中发生异常,也应该确保锁最终能够被释放,以避免死锁等问题。
分布式锁的解决方案
Redis:高性能简单的分布式锁方案
- 本身的
单线程方式保证了操作的并发性。 - 通过
EVAL 命令可以保证操作的原子性。 - 虽然
没有达到强一致,但是多节点时可以保证最终一致性。
基于 ZooKeeper 或 Etcd 实现
ZooKeeper或Etcd实现分布式锁的优势在于:
1、两者都是分布式的,天然具备高可用能力。
2、都有临时节点的能力,能够很好支持锁超时释放等机制的实现。
3、基于顺序节点、Revision 机制等,更方便实现可重入、公平性等特性。
4、基于Watch、Revision 机制更容易避免分布式锁争抢中的「惊群效应」问题(抢占分布式锁时被频繁唤醒和重新休眠,造成浪费)。解决方案为:分布式锁释放后,只唤醒满足条件的下一个节点。
ZK实现分布式锁的基本原理是:以某个资源为目录,然后这个目录下面的节点就是需要获取锁的客户端,未获取到锁的客户端注册需要注册Watcher到上一个客户端。如下图所示:
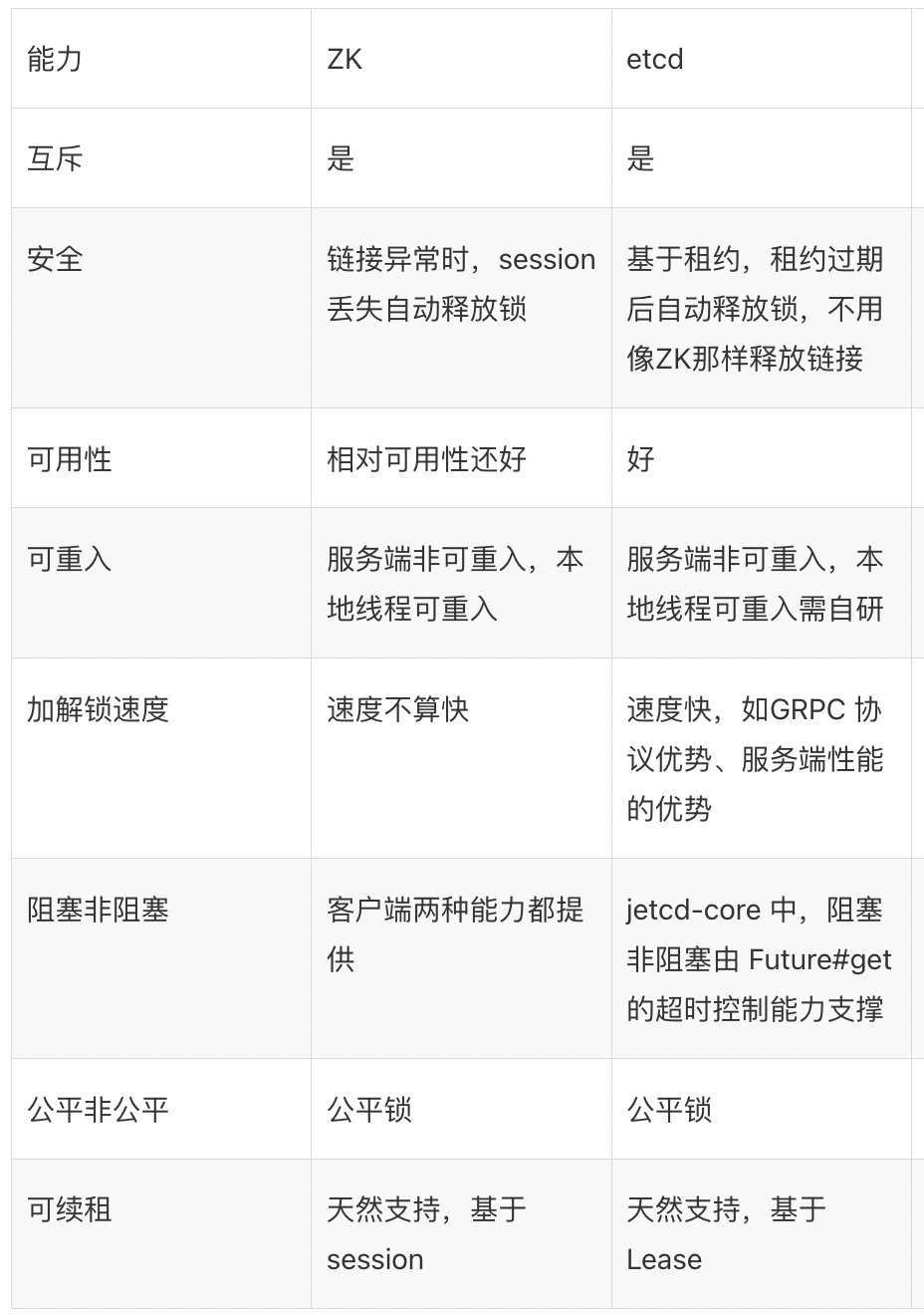
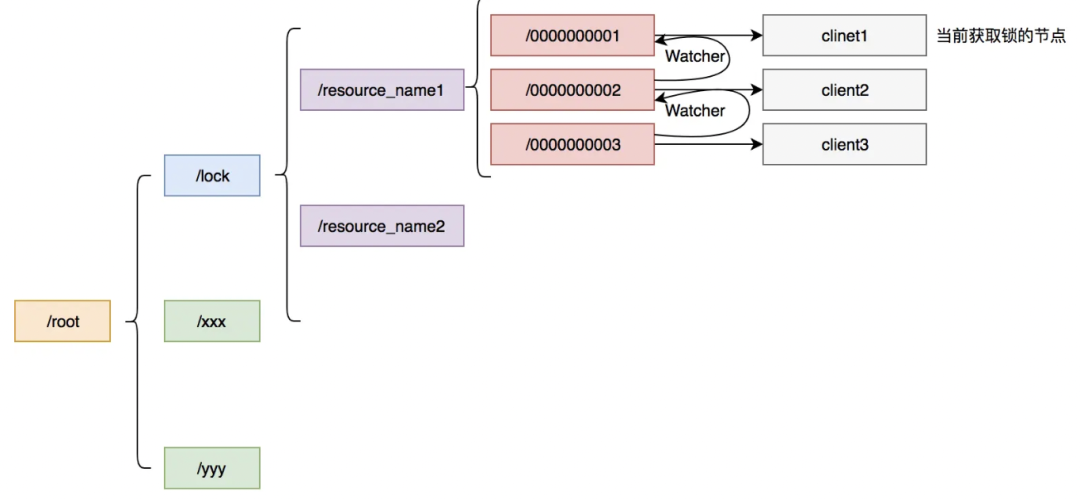
临时节点和事件监听机制,创建临时有序节点,判断是否是最小从而获取到锁。- 通过事件监听等待锁的释放。
- 解锁则删除节点。
MySQL:性能较低
- MySQL的事务机制和锁机制足够满足上述的基本需求。
- 阻塞等机制我们可以借助MySQL的事务和锁机制(select...for update)。
- 性能较低,不适合高并发场景,实现比较繁琐,很少使用MySQL去实现分布式锁。
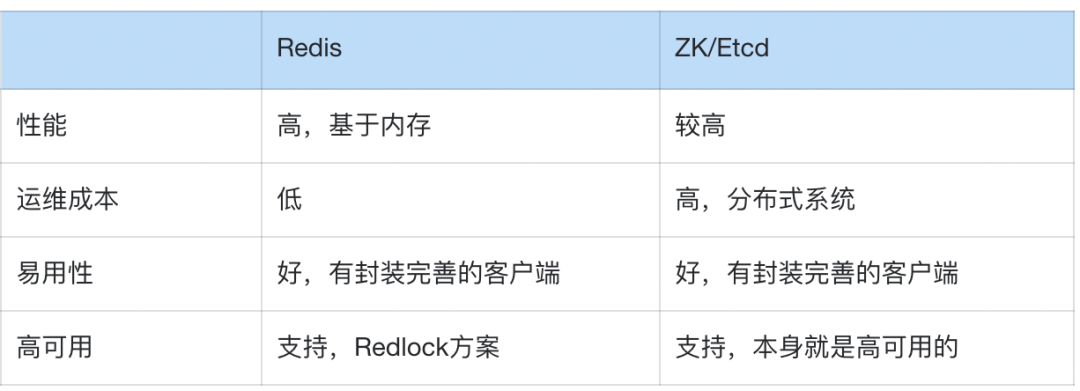
Redis与ZK/Etcd的方案主要异同点:
- 性能:Redis基于内存,读写性能高,适合高并发。ZK/Etcd相对弱一些。
- 运维成本:Redis更常用、是基础组件,运维也更简单。ZK/Etcd都是分布式系统,运维相对复杂一些。
- 易用性:都有较成熟的客户端封装,差别不大。
- 高可用:均支持,Redis采用Redlock方案,ZK/Etcd本身就是高可用的。
以上的几种实现方式里面,用的最多的还是
Redis。
- ZK 需要
额外的部署,有些项目并没有使用 ZK 的场景 。ZK 在性能上比 Redis 要差。- 对一致性的要求
没想象那么高,小概率事件,Redis 基本上可以满足。- 非要强一致,
Redis 也有替代的方案, 比如 RedissonRedLock。- 在锁的处理上,数据库算是
性能最差的,占用资源最多。- 通常用上分布式锁的时候,系统已经比较大了,这个时候大概率已经
分库分表,增加了复杂度。- 对于一些复杂的功能,数据库实现不了(解锁,判断锁)。
- 用数据库做分布式锁还不如让它作为
乐观锁。
分布式锁的使用场景
Martin Kleppmann是英国剑桥大学的分布式系统的研究员,之前和Redis之父 Antirez 进行过关于RedLock(红锁)是否安全有过激烈讨论。正如Martin所说,我们使用分布式锁一般有两个场景:正确性和效率。
1、保证数据正确性,比如抢红包、秒杀下单等场景,需要保障不会出现超卖等问题。
因为红包、秒杀商品等场景下,只能被先到达的人才能抢到,所以要顺序执行库存扣减等操作,这样就需要限制同一时间只能有一个线程或进程对资源进行访问和修改。分布式锁可以确保在多个副本部署服务或高并发的情况下,同一时间只有一个线程或进程能够执行相应的业务代码,从而避免数据不一致的问题。
2、避免重复执行某些操作,浪费资源。比如多个客户端可能都执行发送短信通知,但是需要保证这个通知只被发送一次。这些操作可能是非幂等性的,即执行多次会产生不同的结果。为了避免重复执行这些操作,可以使用分布式锁来确保同一时间只有一个客户端能够执行该操作。比如,业务逻辑可能包括以下步骤:
(1)先获取分布式锁;
(2)获取到锁后,先查询是否已发送短信通知,
(3)之后如果查询到未发送状态后才发送,
(4)发送成功后更新发送状态到数据库中。
这样只有第一次执行该逻辑时才能成功发送,此处应用分布式锁能避免因并发操作导致的重复发送问题。
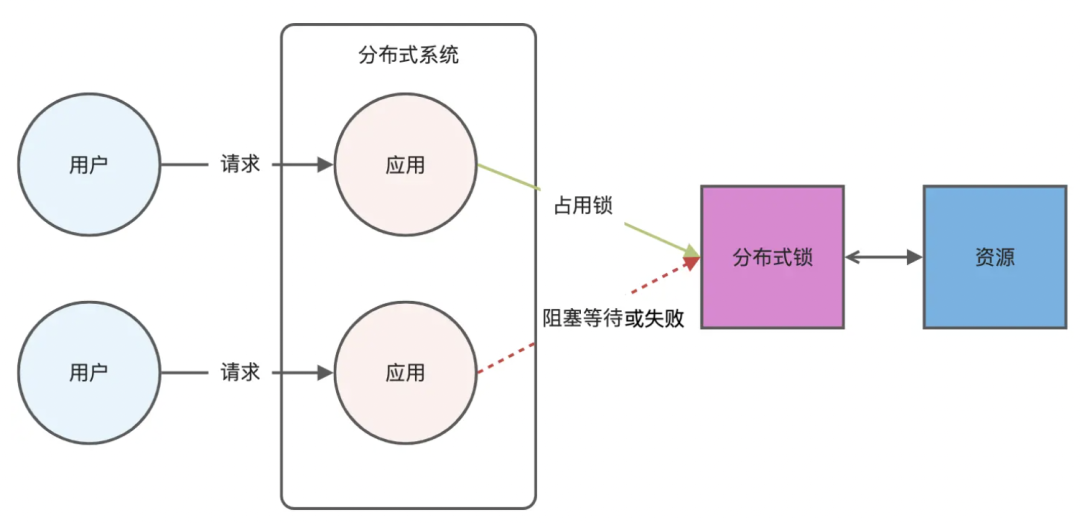
类比单个服务中,操作全局共享变量会先加锁避免并发修改资源造成错误,分布式锁是用于分布式环境下避免并发修改资源导致破坏数据正确性,用于控制某个资源在同一时刻只能被一个应用所使用。如下图所示:
分布式锁的业务场景
场景一 :限制资源写入
资源访问限制是一个很宽泛的领域,来细化一下就是 API 的访问,数据库的访问等等场景都可以通过分布式锁来控制。而往业务场景去偏移,包括超卖问题 ,重复消费问题,等等也都在分布式锁的解决范围之内。同时可以在一定程度上避免数据库级别的锁竞争问题。避免同时的数据写入和修改。
场景二 : 限制资源的产生
这种最常见的场景在于缓存过期的问题上,当并发到来的时候,如果缓存服务器即将过期,可能会基于缓存的特性限制缓存的重复读取和写入。 避免查询重复的数据。再就例如分布式ID的场景下,也会通过分布式锁类似的方式,来获取一个粗粒度的 ID 范围,用于后续ID的细分。
场景三 : 限制触发的频率
这种体现在 Job 定时任务的执行上。不过如果使用的是类似于 XXL-JOB 这类外部的 Job 组件,可能这个特性就用不上。但是如果是单个服务内置的 Job 组件,微服务之间没有互相通信,那么就需要分布式锁来限制任务触发的频率。对应的还包括 API 的访问频率,也可以在分布式锁的基础上进行扩展(主要就是要求原子性的计数)。
场景四 : 维护资源的一致性
由于分布式场景的特性,可能在单机上面被视为原子对象的资源,在分布式场景下就变成了多个资源。分布式锁并不能改变这种状态,但是可以增强一致性 ,维护他们的统一状态。常见的场景包括分布式事务。
分布式锁的实现思路
关于锁的实现要点
- 要实现锁的等待,首先要有个明确的等待时间,然后在业务代码里面等待(比如自旋,Java的锁)。
- 锁的主键:一般情况下实现的时候都是通过 类 + 方法 + 参数 + 值
- 锁的重入:使用 redisson 的情况下 ,它是通过线程ID来实现的重入(如果同一个应用线程相同,就可能存在问题)。
分布式锁的实现方式
- Zookeeper 有提供完整功能的第三方包,例如 Curator。
- Redis 使用更加简单。
基于 Redis 的方案:
- 基于 LUA 脚本自定义分布式锁。
- 基于 redisson 的分布式锁 (其实本质上还是 LUA 脚本)。
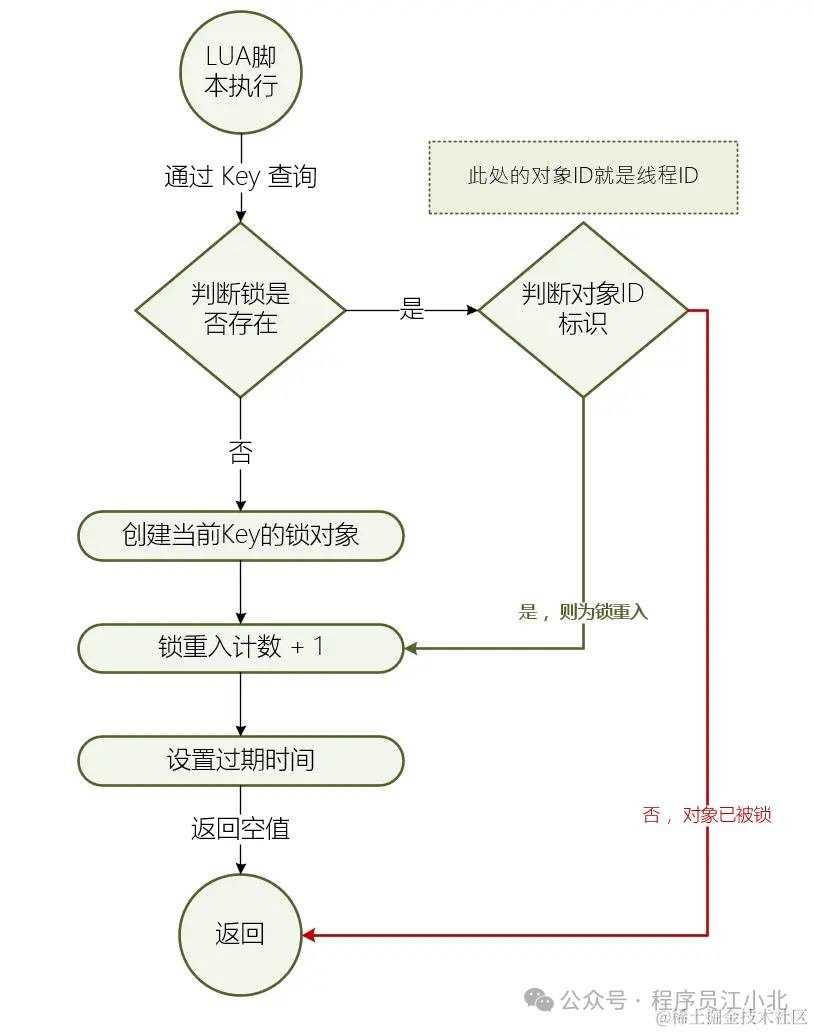
解锁原理
// 如果锁不存在,则直接返回
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then
return nil;
end;
// 若锁存在,且唯一标识(线程ID)匹配:则先将锁重入计数减1
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);
if (counter > 0) then // 如果锁的持有数还是大于 0 ,则不可以删除锁,只是设置时间
redis.call('pexpire', KEYS[1], ARGV[2]);
return 0;
else
redis.call('del', KEYS[1]); // 否则则直接删除锁,锁释放
redis.call('publish', KEYS[2], ARGV[1]); // 广播锁释放消息,唤醒等待的线程
return 1;
end;
return nil;
分布式锁过期的业务处理
首先,在设置过期时间时要结合业务场景去考虑,尽量设置一个比较合理的值,就是理论上正常处理的话,在这个过期时间内是一定能处理完毕的。接着考虑对这个问题进行兜底设计。关于这个问题,目前常见的解决方法有两种:
-
守护线程“续命”:额外起一个线程,定期检查线程是否还持有锁,如果有则延长过期时间。Redisson 里面就实现了这个方案,使用“看门狗”定期检查(每1/3的锁时间检查1次),如果线程还持有锁,则刷新过期时间。
-
超时回滚:当解锁时发现锁已经被其他线程获取了,说明此时我们执行的操作已经是“不安全”的了,此时需要进行回滚,并返回失败。
同时,需要进行告警,人为介入验证数据的正确性,然后找出超时原因,是否需要对超时时间进行优化等等。
守护线程“续命”
Redisson 的 RLock 对象会自动处理锁的续期。当一个线程获取了锁,Redisson 会在后台启动一个定时任务(看门狗),用于在锁即将过期时自动续期。 详细流程步骤:
获取锁:当调用 lock.lock() 时,Redisson 会尝试在 Redis 中创建一个具有过期时间的锁。锁的自动续期:Redisson 会启动一个后台线程(看门狗),它会在锁的过期时间的一半时检查锁是否仍然被当前线程持有。续期锁:如果锁仍然被持有,看门狗会延长锁的过期时间。这确保了即使业务逻辑执行时间较长,锁也不会过期。执行业务逻辑:在锁的保护下,执行业务逻辑。释放锁:当业务逻辑执行完毕后,调用 lock.unlock() 释放锁。如果当前线程是最后一个持有锁的线程,Redisson 会从 Redis 中删除锁。异常处理:如果在执行业务逻辑时发生异常,finally 块中的 unlock() 调用确保了锁能够被释放,防止死锁。看门狗线程终止:一旦锁被释放,看门狗线程会停止续期操作,并结束。
通过这种方式,Redisson 提供了一个简单而强大的机制来处理分布式锁的自动续期,从而减少了锁过期导致的问题。
超时回滚
使用超时回滚机制处理 Redis 分布式锁过期的情况,是指当一个线程因为执行时间过长导致持有的分布式锁过期,而其他线程又获取了同一把锁时,原线程需要能够检测到这一情况并执行业务逻辑的回滚操作。无论业务逻辑是否成功执行,都需要在 finally 块中释放锁,以避免死锁。在释放锁之后,如果业务逻辑执行失败,可能需要通知用户或者记录日志,以便进一步处理。
常见的 Redis 锁实现
基于SETNX + EXPIRE命令
SETNX是"SET if Not eXists"的缩写,命令格式:SETNX key value。
- 获取锁:使用
SETNX命令尝试设置唯一锁标识符。返回1表示成功创建锁,返回0表示锁已被占用。 - 设置过期时间:成功获取锁后,用
EXPIRE命令为锁设定超时时间,防止客户端崩溃导致锁无法释放。 - 释放锁:完成任务后,使用
DEL命令删除锁标识符,释放锁。
需要注意的是,在获取锁后,执行业务逻辑时应设定合理的超时时间,以避免锁被长时间占用。这种方式实现的锁存在一定的缺陷,当 Redis 服务器故障或者出现网络分区时,可能会导致锁无法正常释放,从而导致死锁的问题。SETNX 和 EXPIRE 是两个命令,不是原子操作,如果执行完 SETNX 后宕机,这个锁就会一直存在。
先拿setnx来争抢锁,抢到之后,再用expire给锁加一个过期时间防止锁忘记了释放。如果在setnx之后执行expire之前进程意外crash或者要重启维护了,那会怎么样?
set指令有非常复杂的参数,这个应该是可以同时把setnx和expire合成一条指令来使用。
基于 SET 扩展命令
命令格式:SET key value [EX seconds | PX milliseconds] [NX]。
- 获取锁并设置过期时间:使用 SET $lock_key $val EX $second NX 命令保证加锁原子性,并为锁设置过期时间。NX 表示只有在锁不存在的情况下才设置锁。
- 释放锁:完成任务后,使用
DEL命令删除锁标识符,释放锁。
缺陷:一个客户端可能会误删除别的客户端的锁。比如,客户端A获得分布式锁,之后执行业务操作过久,导致分布式锁已经过期了。此时客户端B成功获得分布式锁,之后A完成业务操作,就把客户端B的锁操作删除了。
基于 SET 命令 + LUA脚本
基于SET扩展命令 + SET 随机 value 以便删除时校验 + LUA脚本保证删除时对比数据和DEL操作的原子性。
1、获取锁并设置过期时间
使用 SET $lock_key $unique_val EX $second NX 命令保证加锁原子性,并为锁设置过期时间。
多个客户端使用同一个lock_key,但是各个客户端应该使用自己唯一的unique_val,以便删除的时候进行校验,防止自己的锁被别的客户端误操作删除。
2、释放锁
完成任务后,获取当前lock_key的 value 与 unique_val 是否相同,相同则使用DEL命令删除锁标识符,释放锁。为保证释放锁为原子操作,需使用lua脚本完成这两步操作。
RedLock 实现锁
RedLock 锁它是由Redis的作者Salvatore Sanfilippo提出的,旨在提供一个可靠的分布式锁方案。
以下是RedLock 算法的基本步骤:
- 获取当前时间戳:所有Redis实例使用相同的时间源,例如:NTP获取当前时间戳。
- 尝试在多个Redis实例上获取锁:在每个Redis实例上尝试使用SET命令获取锁,设置一个带有唯一标识符的键,设置的键名应该是全局唯一的,以避免与其他锁冲突。
- 计算获取锁所花费的时间:计算从第一步获取时间戳到成功获取锁所花费的时间,记为
elapsed_time。 - 判断锁是否获取成功:如果获取锁的时间
elapsed_time小于设定的锁超时时间,并且大多数(例如大于一半)的Redis实例成功获取了锁,那么认为锁获取成功。 - 释放锁:在所有成功获取锁的Redis实例上执行释放锁的操作,使用DEL命令删除对应的键。
关于Redlock还有这么一段趣事:
Redis 作者把这个方案一经提出,就马上受到业界著名的分布式系统专家Martin的质疑。Martin指出了分布式系统的三类异常场景(NPC):
N:Network Delay,网络延迟
P:Process Pause,进程暂停(GC)
C:Clock Drift,时钟漂移
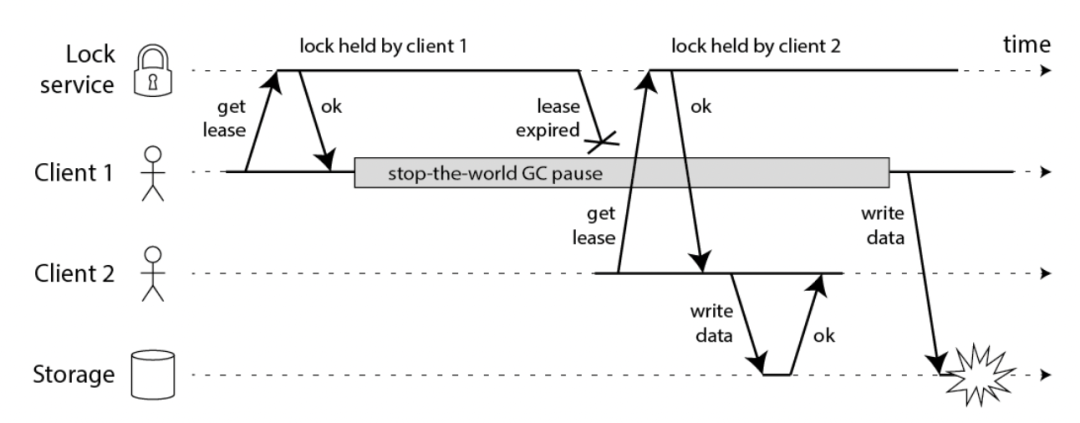
Martin 用一个进程暂停(GC)的例子,指出了 Redlock 安全性问题,由于GC问题会导致分布式锁的正确性出现问题,如下图所示:
之后Redis 作者毫不客气地进行了回怼,Redis 作者同意对方关于时钟跳跃对Redlock的影响,但认为通过运维手段是可以避免的。Redlock中有超时时间判断的机制,可以有效避免NPC问题,但是如果Redlock 步骤3(成功拿到锁)之后发生GC,不止是 Redlock 有问题,其它分布式锁服务同样也有问题,所以不在讨论范畴内。
Redisson 对分布式锁的改进
首先,Redis能做分布式锁,主要是因为是单线程执行的,所以如果能在一个指令里面操作完获取以及设置锁的话,就不会有并发问题。
比如setnx指令,以及新版的set支持相关的参数。当然也可以用lua脚本来保证多个指令的原子性。
但是基于简单的一条指令去做锁的话,是一个不可重入锁,另外一个锁过期时间不好把控,可能会出现业务没有执行完锁过期。
所以redisson主要解决这2个问题,当然还有一些比如读写锁、联锁等等。
可重入的话基于lua+hash去实现可重入锁。然后时间把控,如果你不知道锁多久过期,redisson会基于时间轮+递归来时间锁续期。也就是我们说的看门狗。
时间轮+递归实现续期
时间轮就是hashWheelTimer,是一个netty包下的类,它主要实现的功能是延时执行任务。
它的实现逻辑是会启动一个线程去轮询数组,然后任务根据延时多久添加到对应数组,如果轮询到了的话,通过多线程去执行相关的任务。
看门狗,就是用hashWheelTimer 去根据设置的看门狗时间/3 去延时判断key是否存在,如果存在,就续期,并且递归,做到只要key还在就一直续期。如果key不存在,就不再递归。
Redisson 联锁
Redisson 的联锁(Redisson MultiLock)是 Redisson 分布式锁的一种实现,用于在多个 Redis 节点上同时加锁。它允许多个资源(例如不同的Redis键)同时被锁定,只有当所有的资源都成功锁定时,联锁才会认为锁定成功。这种机制非常适合于需要同时锁定多个资源以执行某些操作的场景。
联锁的目的是因为redis是属于AP模式的中间件,会存在数据丢失,那么锁就会失效。
所以联锁主要做的一件事情就是尽可能的去保证数据不丢失,加锁会加在不同的独立集群机器。当满足一半成功就成功。其实主要思想就是把鸡蛋分散到不同的篮子。降低风险。只要不是超过一半的失败,就是成功的。
实现Redis分布式锁的高可用
首先想到的还是Redis的单点故障问题,如果Redis挂了,分布式锁就不能正常工作,因此可以引入Redis主从模式。
但是,如果在Redis集群的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节点。但是此时分布式锁也已经失效了。
怎么解决这个问题呢?为此,Redis 的作者提出一种解决方案,就是经常听到的 Redlock(红锁)。为此,需要部署5个单独的Redis,Redlock的实现步骤如下:
- 向5个Redis master节点请求加锁。
- 根据设置的超时时间来判断(加锁的总耗时要小于锁设置的过期时间),是不是要跳过该master节点。
- 如果大于等于3个节点加锁成功,并且使用的时间小于锁的有效期,即可认定加锁成功。
- 释放锁,向全部节点发起释放锁请求。
Redis 脑裂问题
Redis 脑裂问题是指,在 Redis 哨兵模式或集群模式中,由于网络原因,导致主节点(Master)与哨兵(Sentinel)和从节点(Slave)的通讯中断,此时哨兵就会误以为主节点已宕机,就会在从节点中选举出一个新的主节点,此时 Redis 的集群中就出现了两个主节点的问题,就是 Redis 脑裂问题。
脑裂问题影响
Redis 脑裂问题会导致数据丢失。
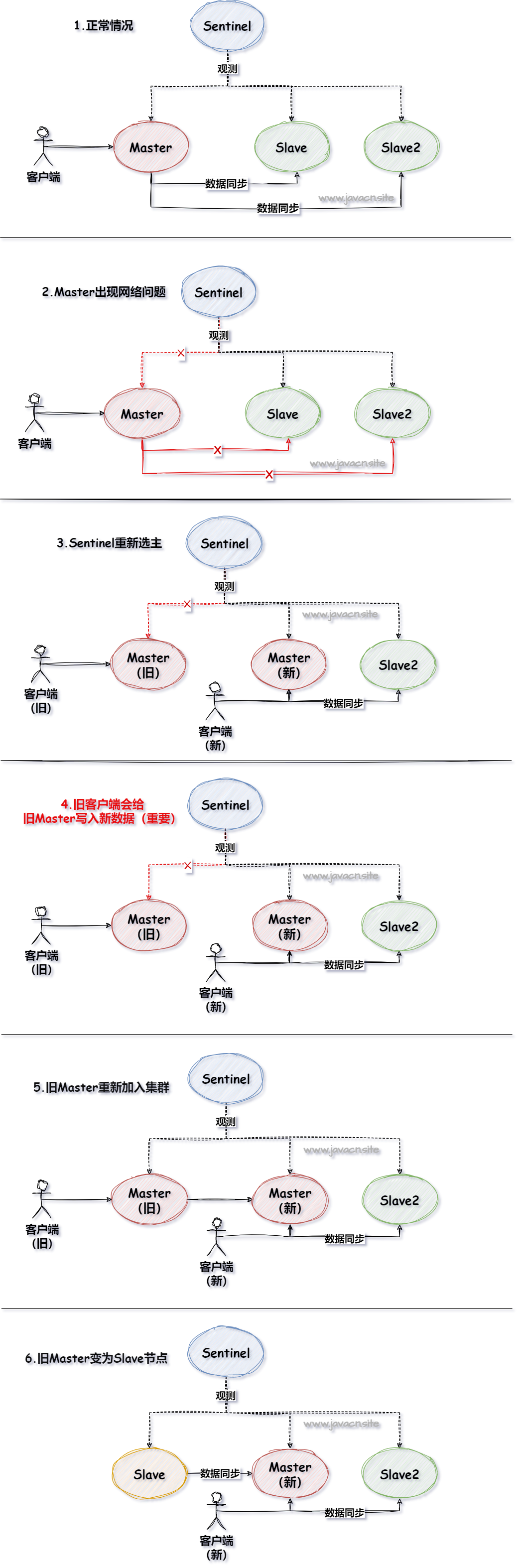
而最后一步,当旧的 Master 变为 Slave 之后,它的执行流程如下:
- Slave(旧 Master)会向 Master(新)申请全量数据。
- Master 会通过 bgsave 的方式生成当前 RDB 快照,并将 RDB 发送给 Slave。
- Slave 拿到 RDB 之后,先进行 flush 清空当前数据(此时第四步旧客户端给他的发送的数据就丢失了)。
- 之后再加载 RDB 数据,初始化自己当前的数据。
从以上过程中可以看出,在执行到第三步的时候,原客户端在旧 Master 写入的数据就丢失了,这就是数据丢失的问题。
脑裂问题解决方法
脑裂问题只需要在旧 Master 恢复网络之后,切换身份为 Slave 期间,不接收客户端的数据写入即可,那怎么解决这个问题呢?
Redis 为我们提供了以下两个配置,通过以下两个配置可以尽可能的避免数据丢失的问题:
- min-slaves-to-write:与主节点通信的从节点数量必须大于等于该值主节点,否则主节点拒绝写入。
- min-slaves-max-lag:主节点与从节点通信的 ACK 消息延迟必须小于该值,否则主节点拒绝写入。
这两个配置项必须同时满足,不然主节点拒绝写入。
在假故障期间满足 min-slaves-to-write 和 min-slaves-max-lag 的要求,那么主节点就会被禁止写入,脑裂造成的数据丢失情况自然也就解决了。
设置了参数之后,Redis 脑裂问题能完全被解决吗?Zookeeper 是如何解决脑裂问题的?
设置了
min-slaves-to-write和min-slaves-max-lag参数后,Redis 的脑裂问题可以得到一定程度的缓解,但并不能完全解决。原因如下:
网络分区:当网络发生分区时,主节点可能会与部分从节点失去连接,但仍然能够接收客户端的写入请求。如果剩余的从节点数量满足
min-slaves-to-write的要求,主节点将继续处理写入操作,而这些写入可能不会同步到被网络分区隔离的从节点,从而导致数据不一致。假故障:如果主节点或从节点发生临时故障(如进程暂停、网络延迟等),在故障恢复之前,主节点可能会拒绝写入,这会影响系统的可用性。
配置复杂性:正确配置这两个参数需要深入理解系统的性能和网络状况,配置不当可能会导致不必要的写入拒绝或数据不一致。
Zookeeper 也会面临脑裂问题,但它通过以下机制来解决:
Zab 协议:Zookeeper 使用 Zab(Zookeeper Atomic Broadcast)协议来保证分布式系统的一致性。该协议确保了即使在发生网络分区时,也只有一个领导节点能够处理写操作。
过半机制:Zookeeper 集群中的每个操作都需要得到超过半数节点的同意才能执行。这确保了在网络分区时,至少有一半的节点与领导节点相连,从而避免了脑裂问题。
领导选举:当领导节点发生故障或网络分区时,Zookeeper 集群会自动进行领导选举,选举出一个新的领导节点来处理写操作。
通过这些机制,Zookeeper 在保证一致性的同时,也提高了系统的可用性和容错性。
限流算法与实现原理
高并发系统有三大特征:限流、缓存和熔断。
限流是指在各种应用场景中,通过技术和策略手段对数据流量、请求频率或资源消耗进行有计划的限制,以避免系统负载过高、性能下降甚至崩溃的情况发生。限流的目标在于维护系统的稳定性和可用性,并确保服务质量。
使用限流有以下几个好处:
- 保护系统稳定性:过多的并发请求可能导致服务器内存耗尽、CPU 使用率饱和,从而引发系统响应慢、无法正常服务的问题。
- 防止资源滥用:确保有限的服务资源被合理公平地分配给所有用户,防止个别用户或恶意程序过度消耗资源。
- 优化用户体验:对于网站和应用程序而言,如果任由高并发导致响应速度变慢,会影响所有用户的正常使用体验。
- 保障安全:在网络层面,限流有助于防范 DoS/DDoS 攻击,降低系统遭受恶意攻击的风险。
- 运维成本控制:合理的限流措施可以帮助企业减少不必要的硬件投入,节省运营成本。
限流常见算法
计数器算法:将时间周期划分为固定大小的窗口(如每分钟、每小时),并在每个窗口内统计请求的数量。当窗口内的请求数达到预设的阈值时,后续请求将被限制。时间窗口结束后,计数器清零。
- 优点:实现简单,易于理解。
- 缺点:在窗口切换时刻可能会有突刺流量问题,即在窗口结束时会有短暂的大量请求被允许通过。
滑动窗口算法:改进了计算器算法(固定窗口算法)的突刺(在短时间内突然出现的流量高峰或数据量激增的现象)问题,将时间窗口划分为多个小的时间段(桶),每个小时间段有自己的计数器。随着时间流逝,窗口像滑块一样平移,过期的小时间段的计数会被丢弃,新时间段加入计数。所有小时间段的计数之和不能超过设定的阈值。
- 优点:更平滑地处理流量,避免了突刺问题。
- 缺点:实现相对复杂,需要维护多个计数器。
漏桶算法:想象一个固定容量的桶,水(请求)以恒定速率流入桶中,同时桶底部有小孔让水以恒定速率流出。当桶满时,新来的水(请求)会被丢弃。此算法主要用来平滑网络流量,防止瞬时流量过大。
- 优点:可以平滑突发流量,保证下游系统的稳定。
- 缺点:无法处理突发流量高峰,多余的请求会被直接丢弃。
令牌桶算法:与漏桶相反,有一个固定速率填充令牌的桶,令牌代表请求许可。当请求到达时,需要从桶中取出一个令牌,如果桶中有令牌则允许请求通过,否则拒绝。桶的容量是有限的,多余的令牌会被丢弃。
- 优点:既能平滑流量,又能处理一定程度的突发流量(因为令牌可以累积)。
- 缺点:需要精确控制令牌生成速度,实现较漏桶复杂。
使用Redis实现限流
使用 Redis 也可以实现简单的限流,它的常见限流方法有以下几种实现:
- 基于计数器和过期时间实现的计数器算法:使用一个计数器存储当前请求量(每次使用 incr 方法相加),并设置一个过期时间,计数器在一定时间内自动清零。计数器未到达限流值就可以继续运行,反之则不能继续运行。
- 基于有序集合(ZSet)实现的滑动窗口算法:将请求都存入到 ZSet 集合中,在分数(score)中存储当前请求时间。然后再使用 ZSet 提供的 range 方法轻易的获取到 2 个时间戳内的所有请求,通过获取的请求数和限流数进行比较并判断,从而实现限流。
- 基于列表(List)实现的令牌桶算法:在程序中使用定时任务给 Redis 中的 List 添加令牌,程序通过 List 提供的 leftPop 来获取令牌,得到令牌继续执行,否则就是限流不能继续运行。
计数器算法
- 使用 Redis 的计数器保存当前请求的数量。
- 设置一个过期时间,使得计数器在一定时间内自动清零。
- 每次收到请求时,检查计数器当前值,如果未达到限流阈值,则增加计数器的值,否则拒绝请求。
滑动窗口算法
- 使用有序集合(ZSet)来存储每个时间窗口内的请求时间戳,成员(member)表示请求的唯一标识,分数(score)表示请求的时间戳。
- 每次收到请求时,将请求的时间戳作为成员,当前时间戳作为分数加入到有序集合中。
- 根据有序集合的时间范围和滑动窗口的设置,判断当前时间窗口内的请求数量是否超过限流阈值。
具体实现代码如下:
public class RedisSlidingWindowRateLimiter {
private static final String ZSET_KEY = "request_timestamps";
private static final int WINDOW_SIZE = 60; // 时间窗口大小(单位:秒)
private static final int REQUEST_LIMIT = 100; // 限流阈值
public boolean allowRequest() {
Jedis jedis = new Jedis("localhost");
long currentTimestamp = System.currentTimeMillis() / 1000;
// 添加当前请求的时间戳到有序集合
jedis.zadd(ZSET_KEY, currentTimestamp, String.valueOf(currentTimestamp));
// 移除过期的请求时间戳,保持时间窗口内的请求
long start = currentTimestamp - WINDOW_SIZE;
long end = currentTimestamp;
jedis.zremrangeByScore(ZSET_KEY, 0, start);
// 查询当前时间窗口内的请求数量
Set<Tuple> requestTimestamps = jedis.zrangeByScoreWithScores(ZSET_KEY, start, end);
long requestCount = requestTimestamps.size();
jedis.close();
// 判断请求数量是否超过限流阈值
return requestCount <= REQUEST_LIMIT;
}
}
令牌桶算法
① 添加令牌
在 Spring Boot 项目中,通过定时任务给 Redis 中的 List 每秒中添加一个令牌(当然也可以通过修改定时任务的执行时间来控制令牌的发放速度),具体实现代码如下:
redisTemplate.opsForList().rightPush("limit_list",UUID.randomUUID().toString());
② 获取令牌
令牌的获取代码如下:
Object result = redisTemplate.opsForList().leftPop("limit_list");在上述代码中,每次访问 allowRequest() 方法时,会尝试从 Redis 中获取一个令牌,如果拿到令牌了,那就说明没超出限制,可以继续执行,反之则不能执行。
使用 Redis 实现限流有什么优缺点?为什么微服务中不会使用 Redis 实现限流?
优点
- 高性能:基于内存的键值存储系统,读写速度非常快,适合用于需要高性能的限流场景。
- 分布式环境友好:支持分布式部署,可以在多个服务器之间共享计数器和状态。
- 灵活的限流策略:数据结构多,可以实现各种复杂的限流策略,如固定窗口、滑动窗口等。
- 原子操作:如 INCR、DECR 等,可以保证在并发场景下的数据一致性。
- 易于集成:Redis 在多种编程语言中都有客户端库,易于和各种应用系统集成。
缺点
- 依赖外部系统:依赖于 Redis 服务器,如果服务器出现问题,会影响限流功能的正常运行。
- 网络延迟:虽然 Redis 性能高,但网络请求比本地计算要慢,可能会引入额外的延迟。
- 资源消耗:虽然 Redis 是基于内存的,但在大规模和高并发的场景下,Redis 仍然可能消耗大量的内存和 CPU 资源。
至于为什么微服务中不会使用 Redis 实现限流,这个说法可能有些绝对。实际上,Redis 在微服务架构中经常被用于限流,尤其是在需要跨服务限流或全局限流的场景下。然而,微服务架构中不使用 Redis 进行限流的原因可能包括:
- 避免单点故障:微服务架构强调去中心化和容错性,过度依赖外部系统(如 Redis)可能会引入单点故障的风险。
- 简化架构:有些微服务架构可能会选择更简单的限流方案,如使用本地计数器或基于时间的令牌桶算法,以减少对外部系统的依赖。
- 性能考虑:对于一些对性能要求极高的微服务,可能会选择在服务内部实现限流逻辑,以避免网络通信的开销。
Redis 的持久化
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。Redis 提供了两种持久化方式:RDB(默认) 和AOF。
RDB:Redis DataBase缩写
功能核心函数rdbSave(生成RDB文件)和rdbLoad(从文件加载内存)两个函数

AOF:Append-only file缩写
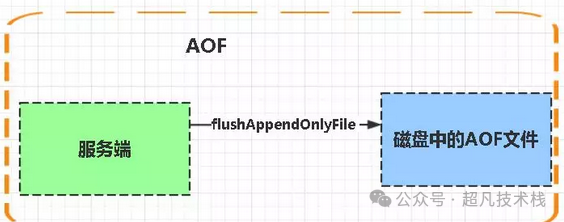
每当执行服务器(定时)任务或者函数时flushAppendOnlyFile 函数都会被调用, 这个函数执行以下两个工作。
AOF写入保存:
WRITE:根据条件,将 aof_buf 中的缓存写入到 AOF 文件。
SAVE:根据条件,调用 fsync 或 fdatasync 函数,将 AOF 文件保存到磁盘中。
存储结构:
内容是redis通讯协议(RESP)格式的命令文本存储。
比较:
- AOF文件比RDB更新频率高,优先使用AOF还原数据。
- AOF比RDB更安全也更大。
- RDB性能比AOF好。
- 如果两个都配了优先加载AOF。
Redis 宕机处理方法
在现代的互联网应用中,Redis因其出色的性能和简便的使用方法,被广泛用作缓存和消息队列系统。然而,Redis作为一个基于内存的数据库,一旦服务宕机,内存中的数据就会全部丢失。因此,Redis的数据持久化机制对于数据恢复至关重要。
为什么需要数据持久化?
数据持久化是确保系统稳定性和数据完整性的重要手段。对于Redis而言,持久化可以防止因服务宕机导致的内存数据丢失。如果不进行持久化,一旦Redis服务异常停止,所有未持久化的数据都将丢失,这对于一些对数据一致性要求极高的应用场景来说是不可接受的。
Redis的持久化策略
Redis提供了多种数据持久化策略,主要包括:
- RDB(Redis Database):通过创建数据集的时间点快照来实现持久化。RDB持久化可以手动触发,也可以根据配置文件中设置的时间间隔自动触发。
- AOF(Append Only File):记录服务器接收到的每个写操作,并将这些操作追加到文件末尾。在Redis重启时,通过重放这些操作来重建原始数据集。
- RDB + AOF:结合使用RDB和AOF两种持久化方式,以获得两者的优势。
- 无持久性:完全不启用持久化,这种方式风险极高,不推荐在生产环境中使用。
RDB持久化
RDB持久化通过生成内存数据的快照并保存到磁盘上的dump.rdb文件来实现。Redis提供了save和bgsave两个命令来生成RDB文件。save命令在主线程中执行,会阻塞其他操作;而bgsave命令会在后台创建一个子进程来执行快照操作,不影响主线程。
为了减少对性能的影响,Redis允许通过配置文件redis.conf设置自动快照的条件,例如:
save 900 1
save 300 10
save 60 10000这些配置表示在不同的键变化数量和时间条件下触发快照。
RDB的优点与缺点
优点:
- RDB文件是某一时间点的数据快照,适合用于数据备份和全量复制。
- 使用LZF算法压缩,文件体积小,恢复速度快。
缺点:
- 快照方式无法做到实时持久化,存在数据丢失的风险。
- 使用
bgsave创建快照时,频繁fork子进程对性能有一定影响。
AOF持久化
与RDB不同,AOF持久化记录了服务器接收到的每个写操作命令,并在Redis重启时重放这些命令来恢复数据。AOF持久化提供了三种同步策略:
- Always:每个写命令后都同步,数据安全性高,但可能影响性能。
- Everysec:每秒同步一次,折衷了性能和数据安全性。
- No:由操作系统控制何时同步,可能在宕机时丢失数据。
AOF的优点与缺点
优点:
-
提供了更好的持久性保证,可以做到秒级的数据处理。
缺点:
- 随着时间的推移,AOF文件可能会变得非常大,恢复速度慢。
- 需要定期进行AOF日志重写以优化性能。
RDB与AOF混合持久化
Redis 4.0引入了RDB和AOF的混合持久化方式。这种方式结合了两者的优点:快照不频繁执行,减少了对主线程的影响;AOF日志只记录两次快照间的操作,避免了文件过大的问题。
数据恢复策略
在Redis宕机后,数据恢复的策略取决于之前选择的持久化方式:
- 仅使用RDB:从最近的RDB快照文件恢复数据。
- 仅使用AOF:重放AOF日志中的写操作来恢复数据。
- RDB + AOF:优先使用AOF日志恢复,因为它可能包含了RDB快照之后的数据变更。
- 无持久化:如果没有任何持久化数据,将无法恢复数据。
Redis的持久化策略对于确保数据的安全性和系统的稳定性至关重要。选择合适的持久化方式需要根据具体的业务需求和性能考虑。在实践中,通常推荐使用RDB和AOF的混合持久化策略,以获得较好的性能和数据安全性。同时,定期的备份和监控也是保证Redis数据安全的重要措施。
Redis实现分布式锁的8大坑
首先还是大家都知道,使用 Redis 实现分布式锁,是两步操作,设置一个key,增加一个过期时间,所以我们首先需要保证的就是这两个操作是一个原子操作。
1、原子性
在获取锁和释放锁的过程中,要保证这个操作的原子性,确保加锁操作与设置过期时间操作是原子的。Redis 提供了原子操作的命令,如SETNX(SET if Not eXists)或者 SET 命令的带有NX(Not eXists)选项,可以用来确保锁的获取和释放是原子的。
2、锁的过期时间
为了保证锁的释放,防止死锁的发生,获取到的锁需要设置一个过期时间,也就是说当锁的持有者因为出现异常情况未能正确的释放锁时,锁也会到达这个时间之后自动释放,避免对系统造成影响。
如果释放锁的过程中,发生系统异常或者网络断线问题,不也会造成锁的释放失败吗?是的,这个极小概率的问题确实是存在的。所以我们设置锁的过期时间就是必须的。当发生异常无法主动释放锁的时候,就需要靠过期时间自动释放锁了。
3、锁的唯一标识
在上面对锁都加锁正常的情况下,在锁释放时,能正确的释放自己的锁吗,所以每个客户端应该提供一个唯一的标识符,确保在释放锁时能正确的释放自己的锁,而不是释放成为其他的锁。一般可以使用客户端的ID作为标识符,在释放锁时进行比较,确保只有当持有锁的客户端才能释放自己的锁。
如果我们加的锁没有加入唯一标识,在多线程环境下,可能就会出现释放了其他线程的锁的情况发生。
有些朋友可能就会说了,在多线程环境中,线程A加锁成功之后,线程B在线程A没有释放锁的前提下怎么可以再次获取到锁呢?所以也就没有释放其他线程的锁这个说法。
下面我们看这么一个场景,如果线程A执行任务需要10s,锁的时间是5s,也就是当锁的过期时间设置的过短,在任务还没执行成功的时候就释放了锁,此时,线程B就会加锁成功,等线程A执行任务执行完成之后,执行释放锁的操作,此时,就把线程B的锁给释放了,这不就出问题了吗。
所以,为了解决这个问题就是在锁上加入线程的ID或者唯一标识请求ID。对于锁的过期时间短这个只能根据业务处理时间大概的计算一个时间,还有就是看门狗,进行锁的续期。
4、锁非阻塞获取
非阻塞获取意味着获取锁的操作不会阻塞当前线程或进程的执行。通常,在尝试获取锁时,如果锁已经被其他客户端持有,常见的做法是让当前线程或进程等待直到锁被释放。这种方式称为阻塞获取锁。
相比之下,非阻塞获取锁不会让当前线程或进程等待锁的释放,而是立即返回获取锁的结果。如果锁已经被其他客户端持有,那么获取锁的操作会失败,返回一个失败的结果或者一个空值,而不会阻塞当前线程或进程的执行。
非阻塞获取锁通常适用于一些对实时性要求较高、不希望阻塞的场景,比如轮询等待锁的释放。当获取锁失败时,可以立即执行一些其他操作或者进行重试,而不需要等待锁的释放。在 Redis 中,可以使用 SETNX 命令尝试获取锁,如果返回成功(即返回1),表示获取锁成功;如果返回失败(即返回0),表示获取锁失败。通过这种方式,可以实现非阻塞获取锁的操作。在规定的时间范围内,假如说500ms,自旋不断获取锁,不断尝试加锁。
如果成功,则返回。如果失败,则休息
50ms然后在开始重试获取锁。如果到了超时时间,也就是500ms时,则直接返回失败。
说到了多次尝试加锁,在 Redis,分布式锁是互斥的,假如我们对某个 key 进行了加锁,如果 该key 对应的锁还没有释放的话,在使用相同的key去加锁,大概率是会失败的。
下面有这样一个场景,需要获取满足条件的菜单树,后台程序在代码中递归的去获取,知道获取到所有的满足条件的数据。我们要知道,菜单是可能随时都会变的,所以这个地方是可以加入分布式锁进行互斥的。后台程序在递归获取菜单树的时候,第一层加锁成功,第二层、第n层 加锁不就加锁失败了吗?
递归中的加锁伪代码如下
private int expireTime = 1000;
public void fun(int level,String lockKey,String requestId){
try{
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(level<=10){
this.fun(++level,lockKey,requestId);
} else {
return;
}
}
return;
} finally {
unlock(lockKey,requestId);
}
}如果直接使用的话,看起来问题不大,但是真正执行程序之后,就会发现报错啦。因为从根节点开始,第一层递归加锁成功之后,还没有释放这个锁,就直接进入到了第二层的递归之中。因为锁名为lockKey,并且值为requestId的锁已经存在,所以第二层递归大概率会加锁失败,最后就是返回结果,只有底层递归的结果返回了。所以,我们还需要一个可重入的特性。
5、可重入
redisson 框架中已经实现了可重入锁的功能,所以可以直接使用,加锁主要通过以下代码实现的。
if (redis.call('exists', KEYS[1]) == 0)
then
redis.call('hset', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);
- KEYS[1]:锁名
- ARGV[1]:过期时间
- ARGV[2]:uuid + ":" + threadId,可认为是requestId
1、先判断如果加锁的key不存在,则加锁。
2、接下来判断如果key和requestId值都存在,则使用hincrby命令给该key和requestId值计数,每次都加1。注意一下,这里就是重入锁的关键,锁重入一次值就加1。
3、如果当前 key 存在,但值不是 requestId ,则返回过期时间。
释放锁的脚本如下
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0)
then
return nil
end
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);
if (counter > 0)
then
redis.call('pexpire', KEYS[1], ARGV[2]);
return0;
else
redis.call('del', KEYS[1]);
redis.call('publish', KEYS[2], ARGV[1]);
return1;
end;
return nil
1、先判断如果 锁名key 和 requestId 值不存在,则直接返回。
2、如果 锁名key 和 requestId 值存在,则重入锁减1。
3、如果减1后,重入锁的 value 值还大于0,说明还有引用,则重试设置过期时间。
4、如果减1后,重入锁的 value 值还等于0,则可以删除锁,然后发消息通知等待线程抢锁。
6、锁竞争
对于大量写入的业务场景,使用普通的分布式锁就可以实现我们的需求。但是对于写入操作少的,有大量读取操作的业务场景,直接使用普通的redis锁就会浪费性能了。所以对于锁的优化来说,我们就可以从业务场景,读写锁来区分锁的颗粒度,尽可能将锁的粒度变细,提升我们系统的性能。
6.1、读写锁
对于降低锁的粒度,上面我们知道了读写锁也算事在业务层面进行降低锁粒度的一种方式,所以下面我们以 redisson 框架为例,看看实现读写锁是如何实现的。
读锁
RReadWriteLock readWriteLock = redisson.getReadWriteLock("readWriteLock");
RLock rLock = readWriteLock.readLock();
try {
rLock.lock();
//业务操作
} catch (Exception e) {
log.error(e);
} finally {
rLock.unlock();
}
写锁
RReadWriteLock readWriteLock = redisson.getReadWriteLock("readWriteLock");
RLock rLock = readWriteLock.writeLock();
try {
rLock.lock();
//业务操作
} catch (InterruptedException e) {
log.error(e);
} finally {
rLock.unlock();
}
通过将锁分为读锁与写锁,最大的提升之后就在与大大的提高系统的读性能,因为读锁与读锁之间是没有冲突的,不存在互斥,然后又因为业务系统中的读操作是远远多与写操作的,所以我们在提升了读锁的性能的同时,系统整体锁的性能都得到了提升。
读写锁特点
- 读锁与读锁不互斥,可共享
- 读锁与写锁互斥
- 写锁与写锁互斥
6.2、分段锁
上面我们通过业务层面的读写锁进行了锁粒度的减小,下面我们在通过锁的分段减少锁粒度实现锁性能的提升。如果你对 concurrentHashMap 的源码了解的话你就会知道分段锁的原理了。是的就是你想的那样,把一个大的锁划分为多个小的锁。
举个例子,假如我们在秒杀100个商品,那么常规做法就是一个锁,锁 100个商品,那么分段的意思就是,将100个商品分成10份,相当于有 10 个锁,每个锁锁定10个商品,这也就提升锁的性能提升了10倍。
具体的实现就是,在秒杀的过程中,对用户进行取模操作,算出来当前用户应该对哪一份商品进行秒杀。
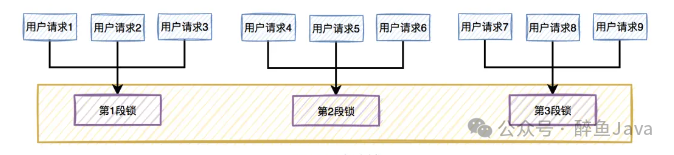
通过上述将大锁拆分为小锁的过程,以前多个线程只能争抢一个锁,现在可以争抢10个锁,大大降低了冲突,提升系统吞吐量。
不过需要注意的就是,使用分段锁确实可以提升系统性能,但是相对应的就是编码难度的提升,并且还需要引入取模等算法,所以我们在实际业务中,也要综合考虑。
7、锁时
在上面我们也说过了,因为业务执行时间太长,导致锁自动释放了,也就是说业务的执行时间远远大于锁的过期时间,这个时候 Redis 会自动释放该锁。
针对这种情况,我们可以使用锁的续期,增加一个定时任务,如果到了超时时间,业务还没有执行完成,就需要对锁进行一个续期。
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
//自动续期逻辑
}
}, 10000, TimeUnit.MILLISECONDS);
获取到锁之后,自动的开启一个定时任务,每隔 10s 中自动刷新一次过期时间。这种机制就是上面我们提到过的看门狗。对于自动续期操作,我们还是推荐使用 lua 脚本来实现
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
redis.call('pexpire', KEYS[1], ARGV[1]);
return 1;
end;
return 0;
需要注意的一点就是,锁的续期不是一直续期的,业务如果一直执行不完,到了一个总的超时时间,或者执行续期的次数超过几次,我们就不再进行续期操作了。
上面我们讲了这么几个点,下面我们来说一下 Redis 集群中的问题,如果发生网络分区,主从切换问题,那么该怎么解决呢?
8、网络分区
假设 Redis 初始还是主从,一主三从模式。
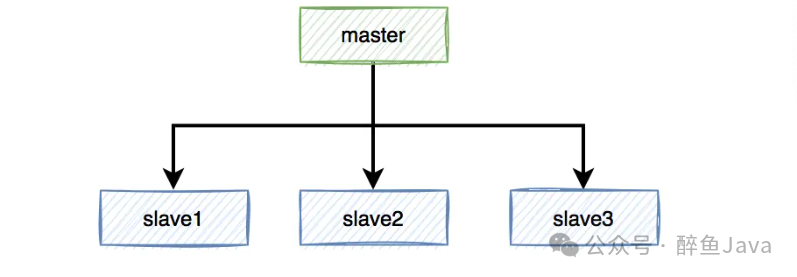
Redis 的加锁操作都是在 master 上操作,成功之后异步不同到 slave上。
当 master 宕机之后,我们就需要在三个slave中选举一个出来当作 master ,假如说我们选了slave1。
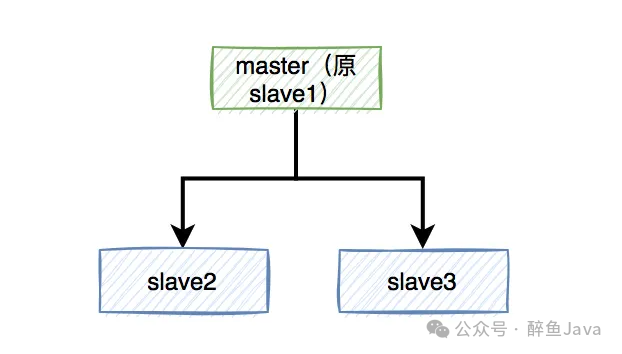
现在有一个锁A进行加锁,正好加锁到 master上,然后 master 还没有同步到 slave 上,master 就宕机了,此时,后面在来新的线程获取锁A,也是可以加锁成功的,所以分布式锁也就失效了。
Redisson 框架为了解决这个问题,提供了一个专门的类,就是 RedissonRedLock,使用 RedLock 算法。
RedissonRedLock 解决问题的思路就是多搭建几个独立的 Redisson 集群,采用分布式投票算法,少数服从多数这种。假如有5个 Redisson 集群,只要当加锁成功的集群有5/2+1个节点加锁成功,意味着这次加锁就是成功的。
1、搭建几套相互独立的 Redis 环境,我们这里搭建5套。
2、每套环境都有一个 redisson node 节点。
3、多个 redisson node 节点组成 RedissonRedLock。
4、环境包括单机、主从、哨兵、集群,可以一种或者多种混合都可以。
我们这个例子以主从为例来说
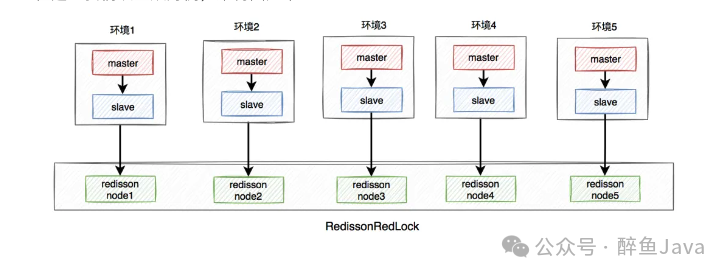
RedissonRedLock 加锁过程如下
1、向当前5个 Redisson node 节点加锁。
2、如果有3个节点加锁成功,那么整个 RedissonRedLock 就是加锁成功的。
3、如果小于3个节点加锁成功,那么整个加锁操作就是失败的。
4、如果中途各个节点加锁的总耗时,大于等于设置的最大等待时间,直接返回加锁失败。
通过上面这个示例可以发现,使用 RedissonRedLock 可以解决多个示例导致的锁失效的问题。但是带来的也是整个 Redis 集群的管理问题。
1、管理多套 Redis 环境
2、增加加锁的成本。有多少个 Redisson node就需要加锁多少次。
由此可见、在实际的高并发业务中,RedissonRedLock 的使用并不多。
在分布式系统中,CAP 理论应该都是知道的,所以我们在选择分布式锁的时候也可以参考这个。
C(Consistency) 一致性
A(Acailability) 可用性
P(Partition tolerance)分区容错性
如果我们的业务场景,更需要数据的一致性,我们可以使用 CP 的分布式锁,例子 zookeeper。
如果我们更需要的是保证数据的可用性,那么我们可以使用 AP 的分布式锁,例如 Redis。
其实在我们绝大多数的业务场景中,使用Redis已经可以满足,因为数据的不一致,我们还可以使用
BASE理论的最终一致性方案解决。因为如果系统不可用了,对用户来说体验肯定不是那么好的。
原文地址:https://blog.csdn.net/lichunericli/article/details/140404242
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!