【面试深度解析】腾讯音乐校招 Java 后端一面:LRU、HTTPS校验证书、文件下载安全、HashMap、volatile、乐观锁(上)
欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术的推送!
在我后台回复 「资料」 可领取
编程高频电子书!
在我后台回复「面试」可领取硬核面试笔记!文章导读地址:点击查看文章导读!
感谢你的关注!
腾讯音乐校招 Java 后端一面:LRU、HTTPS校验证书、文件下载安全、HashMap、volatile、乐观锁
题目分析
1、手写 LRU
LRU(Least Recently Used) 其实是一种数据淘汰策略,当数据达到容量上限之后,就会去淘汰最久未使用的数据,Redis 中也有 LRU 内存淘汰策略,用于淘汰位于内存中的数据
我们将 LRU 定义为双向链表,这样以 O(1) 的复杂度就可以取出表头的表尾的节点,将最近使用过的数据放在表头,最不常使用的数据放在表尾,并且向链表中放入一个虚拟头节点,避免链表为空,主要有两个核心操作:
1、插入元素:如果插入的元素在链表中已经有了,就更新 value;如果没有的话,就插入到链表头
2、获取元素:如果元素不在链表中,返回 Null;如果元素在链表中,将链表移动到表头,表示这个元素比较常用
接下来给出代码实现:
package com.zzu.utils;
import java.util.HashMap;
import java.util.Map;
public class LRUCache {
public static void main(String[] args) {
LRUCache lruCache = new LRUCache(2);
lruCache.put(1, 1);
lruCache.put(2, 2);
lruCache.printLRUCache();
lruCache.put(3, 3);
System.out.println("淘汰后:");
lruCache.printLRUCache();
}
private static class Node {
int key, value;
Node prev, next;
Node(int k, int v) {
key = k;
value = v;
}
}
private final int capacity;
private final Node dummy = new Node(0, 0); // 虚拟头节点
private final Map<Integer, Node> keyToNode = new HashMap<>();
public LRUCache(int capacity) {
this.capacity = capacity;
dummy.prev = dummy;
dummy.next = dummy;
}
public int get(int key) {
Node node = getNode(key);
return node != null ? node.value : -1;
}
public void put(int key, int value) {
Node node = getNode(key);
if (node != null) {
node.value = value;
return;
}
node = new Node(key, value);
keyToNode.put(key, node);
pushFront(node);
if (keyToNode.size() > capacity) {
Node backNode = dummy.prev;
keyToNode.remove(backNode.key);
remove(backNode);
}
}
// 获取对应节点
private Node getNode(int key) {
if (!keyToNode.containsKey(key)) {
return null;
}
// 将最近用到的节点放到链表头
Node node = keyToNode.get(key);
remove(node);
pushFront(node);
return node;
}
private void remove(Node x) {
x.prev.next = x.next;
x.next.prev = x.prev;
}
// 将节点移动到链表头
private void pushFront(Node x) {
x.prev = dummy;
x.next = dummy.next;
x.prev.next = x;
x.next.prev = x;
}
// 打印 LRU 中存储的数据情况,方便看出哪些数据被淘汰
public void printLRUCache() {
Node node = dummy.next;
while (node != dummy) {
System.out.print("k=" + node.key + ":v=" + node.value + " ");
node = node.next;
}
System.out.println();
}
}
2、HTTPS 客户端校验证书的细节?
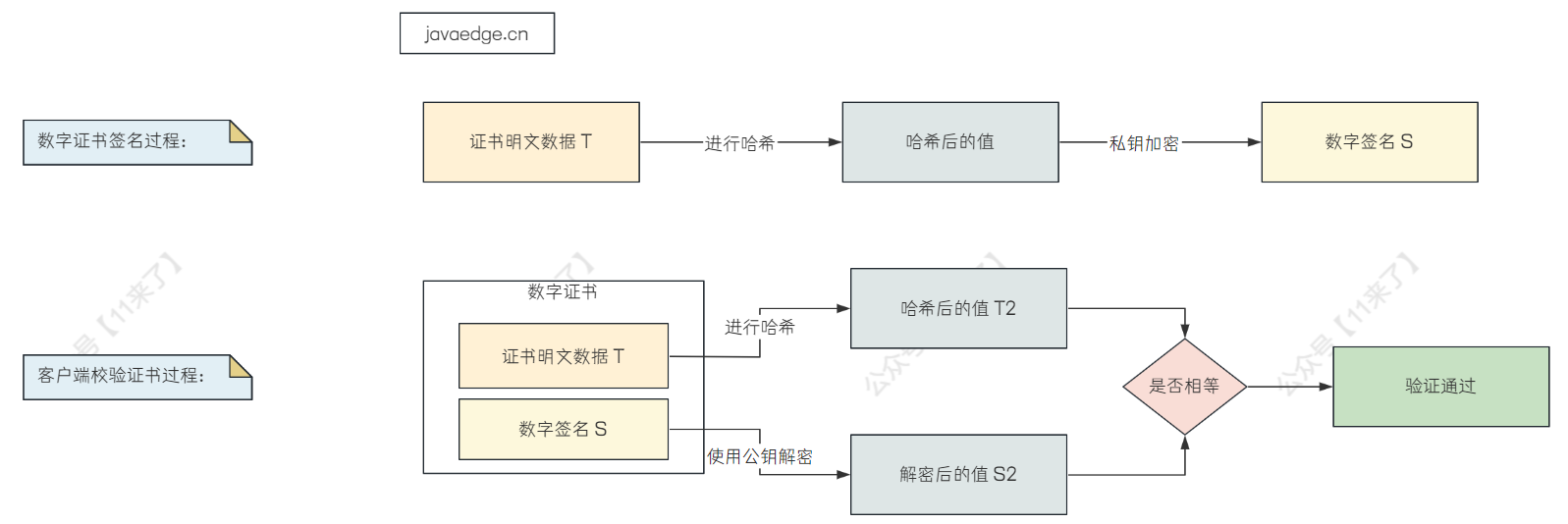
HTTPS 客户端校验证书,这里的证书就是 数字证书 ,网站在使用 HTTPS 之前都会去 CA 机构申请一份数字证书,数字证书包含了:持有者信息、公钥等信息
当客户端与服务器进行通信时,服务器将证书传输给浏览器,这个证书中包含了:
- 证书明文数据:这里用 T 表示
- 数字签名:CA 机构拥有非对称加密的私钥和公钥,CA 机构先对证书明文数据 T 进行哈希,对哈希后的值用私钥进行加密,得到数字签名 S
当客户端拿到证书后,对证书验证的流程如下:
- 拿到证书后,得到明文数据 T,数字签名 S
- 使用 CA 机构的公钥对数字签名 S 进行解密,得到 S2
- 使用证书里的 hash 算法对明文数据 T 进行哈希,得到 T2
最后如果 S2 和 T2 相等,那么说明证书可信:
3、对称加密和非对称加密的区别?HTTPS 使用的哪个?
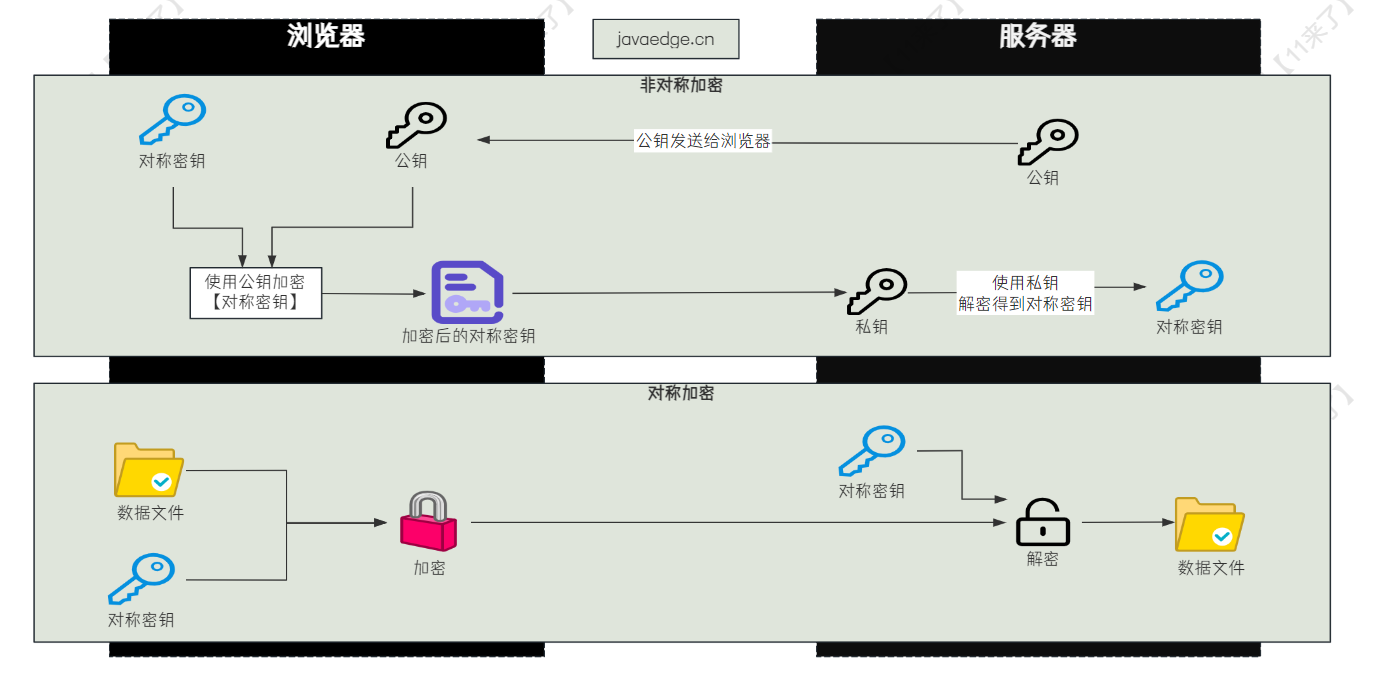
HTTPS 使用的 对称加密 + 非对称加密 两者结合的算法
HTTPS 在 HTTPS 握手的时候,使用的是非对称加密,服务器会发送给浏览器数字证书,包含了公钥,浏览器使用公钥加密一个随机生成的 对称密钥 ,发送给服务器
当浏览器和服务器建立通信之后,使用对称密钥来进行数据的加密解密,这个过程使用的对称加密
为什么要使用两种加密算法的结合呢?
- 对称加密:加密解密过程中使用相同的密钥,速度很快,但是如何让双方都安全的拿到这个密钥比较困难(因此和非对称加密结合,来安全的传输这个对称密钥)
- 非对称加密:加密解密过程中使用一对密钥,即公钥和私钥。公钥是公开的,用于加密;私钥只能自己拿到,用于解密,整个过程相对复杂,比较耗时,一般用于密钥的交换
通过了解这两种算法的区别,也就知道了为什么要使用这两种算法的结合了,HTTPS 既想要对称加密的性能,又想要非对称加密的安全性!
整个 HTTPS 使用非对称加密以及对称加密的流程如下:
4、怎么防止下载的文件被劫持和篡改?
这里说一下我自己的思路,其实跟上边的 HTTPS 中校验证书的流程是差不多的
服务器提供文件下载的功能,在服务器端,先对文件数据进行一个加密,生成一个加密后的值称为指纹,这里设为 S,服务器会将指纹 S 公布出来
当用户下载了文件之后,也对文件中的数据以相同方式进行加密,生成一个加密后的值,这里设为 T,如果 T 和 S 相同,那就证明下载的文件没有被劫持和篡改
加密的时候通过散列函数进行加密,通过散列函数加密的结果是不可逆的,所以说每个文件所生成的指纹都是唯一的,如果文件被篡改的话,加密后的值一定和原文件的指纹不同
5、HashMap 的 put 流程?
这个算是比较常规的面试题了,当向 HashMap 中 put 元素时,流程如下:
- 先计算 key 的哈希值(这里让 key 的 hashCode 的高 16 位也尽量参与运算,让位置更加平均:
(h = key.hashCode()) ^ (h >>> 16)) - 通过哈希值对数组长度进行取模就可以得到当前节点在数组中存储的下标了
- 如果数组的该位置上没有元素,就直接创建一个节点放到该位置
- 如果数组的该位置上有元素,说明发生了哈希碰撞,判断当前位置上是链表还是红黑树,如果是链表就插入到链表尾,如果是红黑树就以红黑树的方式进行插入
扩展:这里扩展一下为什么 HashMap 中使用红黑树而不是 B+ 树
为什么 HashMap 中使用红黑树而不使用 B+ 树呢?
首先说一下红黑树和 B+ 树有什么区别:
- 红黑树: 是自平衡的二叉搜索树,可以保证树的平衡,确保在最坏情况下将查找、插入、删除的操作控制在 O(logN) 的时间复杂度
- B+ 树: 是多路平衡查找树,多用于数据库系统,B+ 树的特点就是非叶子节点不存储数据,只存储子节点的指针,这样可以减少每个节点的大小,在读取一个磁盘页时可以拿到更多的节点,减少磁盘 IO 次数
那么 HashMap 是在内存中存放数据的,不存在说磁盘 IO 次数影响性能的问题,所以说直接使用红黑树就可以保证性能了,并且实现起来也相对比较简单
6、volatile 和 synchronized 的区别?
volatile 是用于保证变量的可见性并且禁止指令重排,保证了变量的有序性和可见性
synchronized 可以保证方法的同步,通过 synchronized 可以保证有序性、可见性和原子性
如果仅仅需要保证变量的可见性,可以使用 volatile
如果需要控制代码块的同步,可以使用 synchronized
这里可以扩展说一下,他们对于可见性和有序性的保证其实都是基于内存屏障来做的
在读取修饰的变量之前,会加一些内存屏障,这个内存屏障的作用就是让当前线程读取这个变量时可以读取到最新的值
在更新修饰的变量之后,也会加一些内存屏障,作用是可以让更新后的值被其他线程感知到
通过这个内存屏障可以让多个线程可以互相之间感知到对变量的更新,达到了可见性的作用
而有序性也是同理,通过内存屏障,来禁止内存屏障对指令进行重排
7、乐观锁如何实现,有哪些缺点?
常见的乐观锁的实现有两种方式:数据库和 CAS
- 通过数据库实现乐观锁:
通过版本号实现乐观锁,如下面 SQL
UPDATE table_name SET column1 = new_value, version = version + 1 WHERE id = some_id AND version = old_version;
如果 version 未被修改,则允许更新;如果 version 已被修改,则拒绝更新操作
- 通过 CAS 实现乐观锁:
CAS 的原理就是,去要写入的内存地址判断,如果这个值等于预期值,那么就在这个位置上写上要写入的值
乐观锁的缺点:
乐观锁适用于并发冲突较少的场景,因为它避免了在读取数据时加锁,从而减少了锁的开销
但是在高并发环境中,如果冲突频繁,乐观锁可能导致大量的重试操作,从而影响性能。在这种情况下,可能需要考虑使用悲观锁或其他并发控制策略
原文地址:https://blog.csdn.net/qq_45260619/article/details/136044336
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!