BERT论文阅读
一.前情提要
1.本文理论为主,并且仅为个人理解,能力一般,不喜勿喷
2.本文理论知识较为成体系
3.如有需要,以下是原文,更为完备
BERT 论文逐段精读【论文精读】_哔哩哔哩_bilibili
二.正文
1.前言:
①BERT是一种基于Transformer架构的预训练语言模型。
②NLP(即自然语言处理)是人工智能领域的一个重要分支,旨在使计算机能够理解、解释和生成自然语言文本。NLP涉及处理人类语言的各个层面,包括语义理解、语法分析、语言生成等。
2.与ELMO、GPT的区别(因为是在这两篇的基础上发展的)
细节(1)--->区别
①训练深得双向的表示(运用了右侧和左侧的信息),而GPT是单向的
②ELMO运用的RNN而BERT运用的是Transformer,故ELMO与用到下游的时候要调整结构而BERT就只用调整最上层--->与GPT是一样的。
细节(2)--->优势
①绝对精度提高7.7%
(ps:BERT本身并没有一个绝对的精度,因为它是一个预训练的模型,其性能取决于具体任务和数据集,但是一些标准的基准数据集上,BERT和其变种通常能够达到非常高的精度。例如,在GLUE上)
3.流程
①普遍流程:语言预训练可以提升自然语言任务:如:句子之间的关系(如:情绪),词源层面输出(如:实体命名)
②预训练策略:(1)基于特征(ELMO):将学到的特征和输入一起放进去
(2)基于微调(GPT):将权重放在下游,最后微调(并且从左到右读句子)
----------->均使用单项的语言模型
③作者新想法:读句子从左到右与从右到左并行
操作:
(1)用带掩码的语言模型(MLM):简而言之是进行句子挖空让机器来预测或着预测两个句子是不是相邻的
(2)好处:1.双向 2.微调 3.直接引用代码
(3)证明了在没有标号的大量数据集训练模型比有标号的小量数据集训练模型(前人常用比如:ImageNet)效果好
4.算法
①预训练:在没有标号的大量数据集训练
②微调:使用预训练中的权重用的是有标号的数据集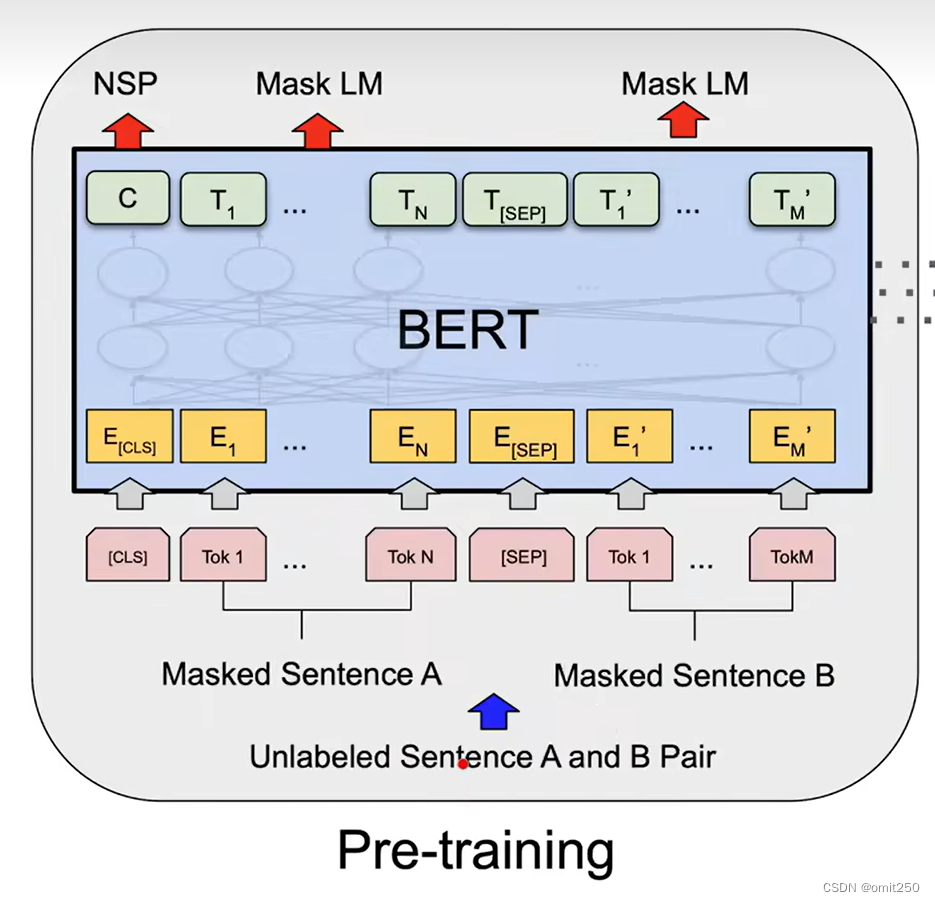
(预训练)
③调参:
(1)transformer的块的个数
(2)隐藏层的大小
(3)自注意力机制的头的个数
(自注意力机制用于序列数据处理的机制,最初引入于Transformer模型中。它允许模型在处理序列数据时,动态地给不同位置的输入赋予不同的注意力权重,从而更有效地捕捉序列中的长距离依赖关系。)
④处理句子
(1)切词:得子序列 (示例如下)

(2)两个句子合在一起仍然可以区分
(3)掩码是占15%----->80%概率真替换 10%概率随机词源 10%概率什么都不干(因为微调不会有掩码)
(示例如下)
(4)正例和负例 (示例如下

5.缺点
①用了Adam的残缺版--->有影响
②训练轮数小
原文地址:https://blog.csdn.net/omit250/article/details/137959560
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!