大模型+强化学习_在线交互调参_GLAM
英文名称: Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning 中文名称: 通过在线强化学习在交互式环境中建立大型语言模型 链接: https://arxiv.org/pdf/2302.02662.pdf 代码: https://github.com/flowersteam/Grounding_LLMs_with_online_RL 作者: Thomas Carta, Clément Romac, Thomas Wolf, Sylvain Lamprier, Olivier Sigaud, Pierre-Yves Oudeyer 机构: 法国波尔多大学,Hugging Face... 日期: 2023-02-06 v1 |
1 读后感
这是一篇倾向于研究性和思考的文章,不仅适用于机器人领域,还可以推广到 Agent 和其他领域,对于希望用大型模型来解决实际生活中的问题,这是大模型应用过程无法跳过的一环。
为了简化问题,作者将整个测试环境转化为语言环境,以便与 LLM 进行交互。
在相关工作和作者的实验中有一些有趣的发现。例如,在专家轨迹上微调 LLM 并不能像使用随机初始化的深度 Q 网络进行强化学习训练那样表现得好。这可能涉及到一个哲学问题:真实世界的动作空间非常广阔且复杂,专家只是找到解决问题途径之一,并不一定是最优策略。
2 摘要
目的: 旨在对齐大型语言模型(LLM)的知识与环境,并研究这种对齐对提高在线强化学习任务的效率以及提升不同形式的泛化的影响。
方法: 提出了一种名为 GLAM 的方法,它将 LLM 作为一个策略,该策略在代理与环境互动的过程中逐步更新,利用在线强化学习来提高其解决问题的性能。使用了一个设计用于研究更高级形式的功能性基础的交互式文本环境,以及一组空间和导航任务,来研究几个科学问题。
实验结果: 研究了几个科学问题:1)可以 LLMs 提高各种 RL 任务的在线学习的样本效率吗?2)它如何促进不同形式的泛化?3)在线学习有什么影响?通过对 FLAN-T5 的几种变体(尺寸、架构)进行功能落地来研究这些问题。
3 引言
作者认为大模型与环境之间存在隔阂的原因包括以下几点:
- 训练过程(预测下一个单词)中缺乏直接激励来解决环境中的问题;
- 缺乏干预环境以识别因果结构的能力;
- 缺乏基于与环境互动而收集的数据进行学习的能力。
作者的研究目标是:探索如何将 LLMs 作为 Agent 做出决策,在互动环境中采取行动以实现目标,并感知这些行动的结果,根据他们收集到的新观察结果逐步巩固和更新他们的知识。
主要探讨以下四个问题(在实验中分别讨论):
- Q1 样本效率:大型语言模型(LLM)如何快速适应并学习解决自然语言中指定的各种空间和导航问题?预训练知识如何提高样本效率?
- Q2 对新对象的泛化:理建立了基础功能,LLM 如何对对象的各种变化进行泛化,同时保持在已训练的任务中的水准?
- Q3 对新任务的泛化:交互式训练的 LLM 如何对新任务进行零样本泛化?泛化根据新任务的类型泛化?
- Q4 在线干预的影响:与从离线的专家轨迹相比,使用在线强化学习进行实时交互的效果如何?
实验在 BabyAI 平台上进行,并将 BabyAI 环境转换为文本版本。BabyAI 是一个平台,用于研究和开发能够理解和执行用户指令的人工智能。这个平台包含了一系列的环境和任务,设计用于训练和评估 AI 的能力,特别是在理解和执行复杂的指令方面。
4 方法
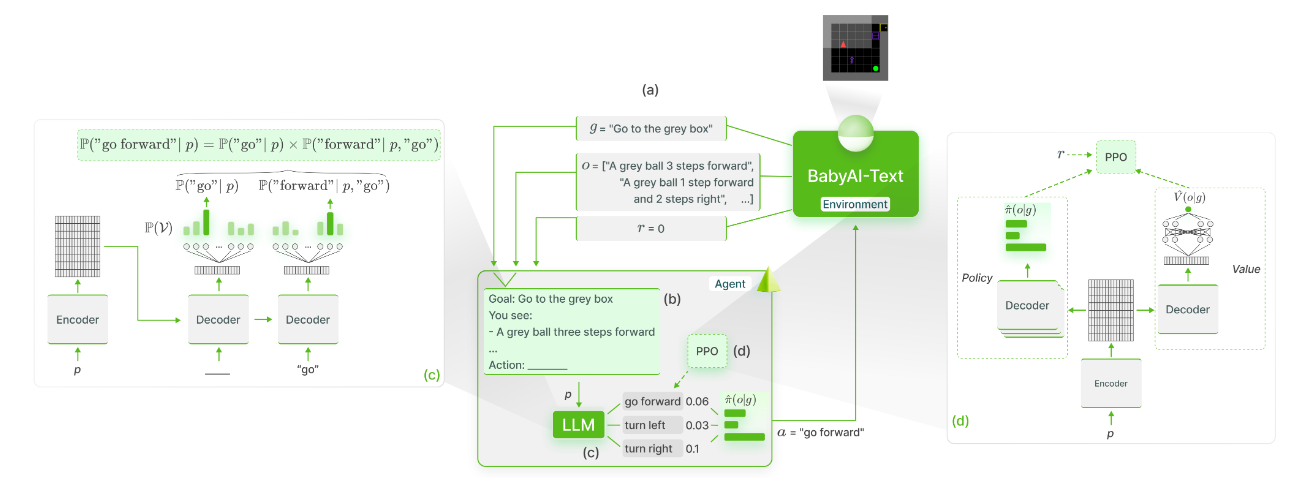
图 -1 LLM 使用在线 RL(PPO)进行训练以实现语言目标,从而实现功能基础。(a)BabyAI-Text 提供当前剧集的目标描述,以及代理观察的描述和当前步骤的标量奖励。(b)在每一步中,我们都会收集目标描述和观察结果,并将其发送到我们的 LLM.(c)对于每个可能的动作,我们使用编码器生成提示的表示(p),并计算在给定提示的情况下组成动作的标记的条件概率。一旦估计了每个动作的概率,我们就会在这些概率上计算一个 softmax 函数,并根据这个分布对动作进行采样。此外的 LLM 是决策代理。(d)我们使用环境返回的奖励来微调 PPO LLM。最后,通过 LLM(及其 value head)反向传播梯度。
4.1 问题概述
定义 o 为观察值,r 为奖励,a 为动作(与一般强化学习相同)。设目标为 g。
这样的环境可以被框定为一个目标增强的部分可观察马尔可夫决策过程 M=(S,V,A,T,R,G,O,Y),其中包括状态空间 V、行动空间 A、目标空间 G、过程传递函数 T、目标条件奖励函数 R,以及将状态映射到文本描述的观察函数 O。折扣因子记作 Y。
根据 BabyAI 的提议,我们扩展了一个名为 BabyAI-Text 的纯文本版本。主要区别在于 BabyAI-Text 返回代理部分观察到的文本描述,而不是 BabyAI 最初返回的符号表示。我们将使用该工具进行实验。
4.2 LLM 作为交互式环境中的策略
收集任务描述、当前观测的文本描述以及一组可能的动作,将这些信息组织成一个提示,用来输入给大型语言模型。选择了一个任意和简单的提示模板(示例见附录 C),并且没有进行任何密集的提示工程。需要 LLM 输出可能动作 ℙ(𝒜) 的概率分布。
核心问题是如何计算各个可选动作的概率 P(A)。现有两种方法:第一种方法是,如果 LLM 生成的字符序列对应可能的动作之一,则选择此动作;否则,需要执行临时 (ad-hoc) 的动作或者通过加一层 MLP 来输出动作。第二种方法是直接使用 LLM 来计算每个动作概率的方法,即在给定提示 p 的条件下计算每个动作 A 中每个 token 的条件概率:
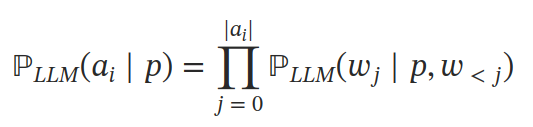
这里的 ai 是第 i 个动作,w 是组成 a 的 token(单词),在提示为 p,且前 j-1 个词为 wx 的情况下,wj 的概率。文中选择的是后一种方法,最后使用 softmax 函数归一化概率以得到 A 的分布。
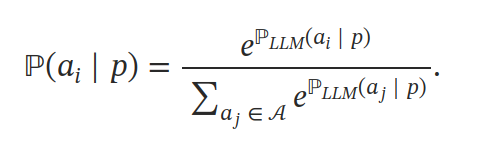
4.3 PPO 微调
具体方法是使用 PPO 强化学习方法,同时学习策略函数和值函数。
在策略方面,使用 LLM:

计算的似然来计算每个动作的概率。
对于值近似,在第一个解码器块的最后一层的顶部添加一个具有单个输出值的 MLP:
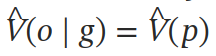
见图 -1 的 (d),实验中使用了 Encoder-Decoder 的 LLMs,但文中方法可以很容易地用于仅解码器模型,方法是将值 head 附加到提示的最后一个提示 token 的 Decoder 块。
4.4 使用 Lamorel 的分布式 LLM 策略
使用大型语言模型(LLM)在动作空间上计算概率是一项昂贵的计算任务,因为它需要为每个动作计算概率。为了解决 BabyAI(扩展到 BabyAI-Text)中的任务,通常需要进行多次交互,研究团队部署了多个 LLM,并将每个工作器并行处理一部分动作的得分,从而使时间几乎线性减少。作者开发了一个名为 Lamorel 的 Python 库来封装上述工作。
5 实验
使用 Flan-T5 780M 训练语料库。实验部分还描述了 prompt 是如何构建的,包含很多细节,建议看一下,这里就不翻译了。
5.1 LLM 适应和学习解决任务的速度
为了研究问题 Q1,我们在 BabyAI-Text 中训练我们的代理 1.5 million 步。
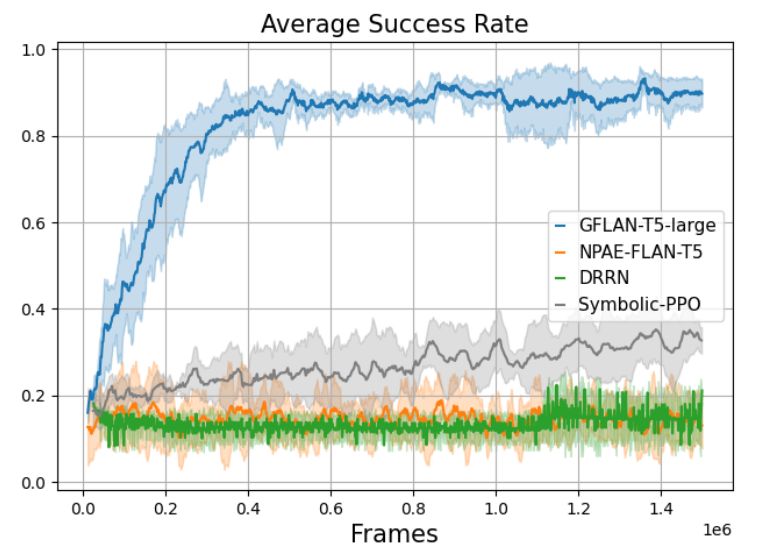
5.2 Q2 对新对象泛化
如何将其技能泛化到新的对象上。通过图 -4 的 b,c 可以看出,当任务中包含词汇表外的名词时,GFlan-T5 不受影响。即使在完全不同的环境中,GFlan-T5 的成功率也降低了 13%。
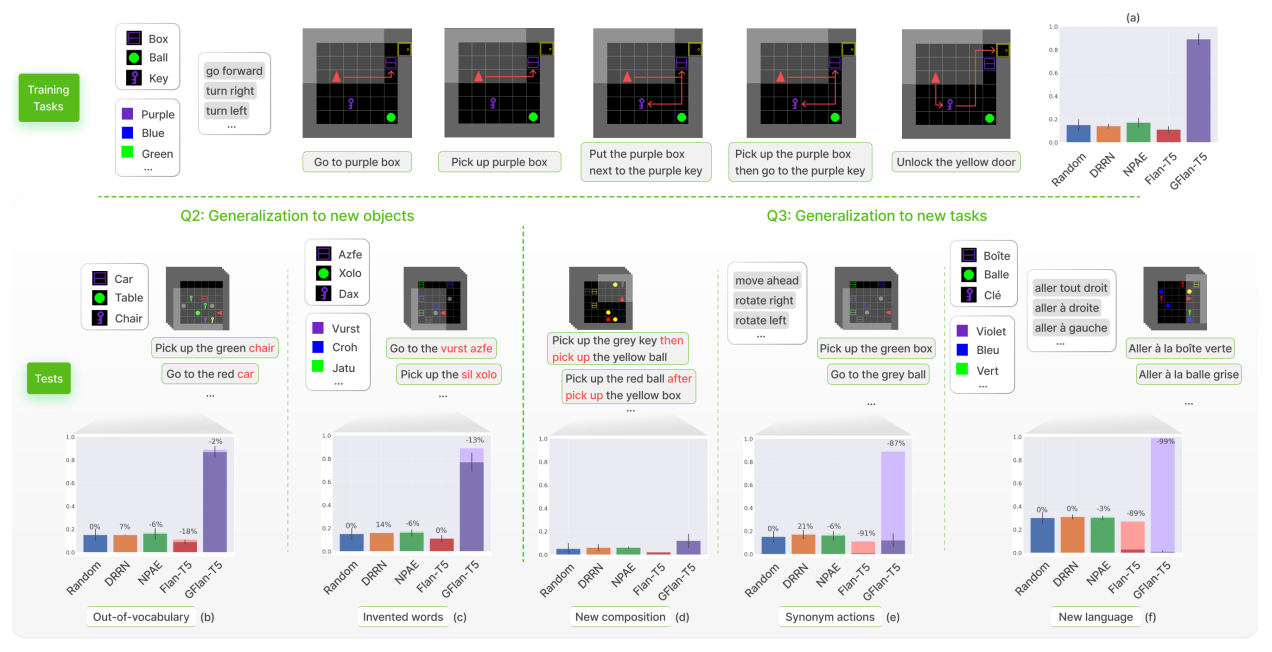
图 -4 泛化测试:我们在 5 个不同任务的混合上训练所有代理,并在 1000 个测试片段(也包含这 5 个任务的混合)上评估他们的泛化能力(a)。我们将他们与两个基线进行比较:一个随机选择动作的代理(随机)和 ZeroShot 的 Flan-T5(没有任何微调)。然后,我们进行几个泛化研究,以回答 Q2 和 Q3,通过(b)用词汇表外的名词替换对象名,(c)用发明的词替换对象和颜色,(d)测试新的任务组合,(e)用同义词替换动作,以及(f)将整个环境的 " 前往 " 任务翻译成法语。
5.3 Q3 对新功能泛化
在图 -4(d) 的新任务组合中,可以看到所有的代理都未能解决这些新任务,但是 GFlan-T5 的表现超过了其他代理。
在图 -4(e) 将动作替换为同义词来测试我们的代理的鲁棒性时,可以看到 GFlan 相对于 Flan 有明显下降,可能是由于对动作单词的过拟合造成的。
在图 -4(f) 语言泛化中,使用训练期间未见过的语言(法语)来测试它们。Flan-T5 是使用多语种语料库进行预训练,并且能够翻译简单的句子。测试结果显示,GFlan-T5 的成功率(0.02)比随机选择(0.30)要差。因此可以认为当一次修改太多 Grounding 的符号时,功能基础化无法转移到这个新的符号子系统。
5.4 Q4 使用 RL 与行为克隆对比
从 Table-1 中可以看到 GFlan-T5 在这两个任务上都超过了行为克隆 BC。

原文地址:https://blog.csdn.net/xieyan0811/article/details/136970468
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!