网络通信中字节流存在的问题,tcp协议特点,自定义协议(引入+介绍,序列化反序列化介绍,实现思路)
目录
字节流存在的问题
介绍
我们前面写的代码都是以字符串形式收发的,虽然暂且没有出现什么问题,但不代表他没问题
- 我们目前无法保证在字节流中,每次都可以读取出一份完整的数据
- 之前可以做到只是因为数据量小+网络良好
- 当数据量很大/网络有波动时,tcp协议会出现数据分片、拥塞、丢包等情况,导致接收方收到的消息可能只有一小部分/多份混在一块
- 就像在普通的二进制文件中,我们无法知道一句的结尾在哪里,我们也无法区分网络数据
tcp协议特点介绍
tcp的收发自主权
- 当然,上面指的问题并不是出在传输层,因为传输层是写在os里的
- 就像我们不用关心在普通文件的io里,数据何时被os刷新到磁盘上一样,它一定会在合适的时间帮我们处理的
- 换句话说,就像os一样处理文件数据一样,tcp协议具有网络数据的收发自主权,我们不需要关心它何时收发数据
- 那么,写的时候就没有任何顾虑了,因为有tcp协议帮我们兜底
- 但是,读取内容的时候,需要额外处理
tcp的全双工通信
之前在进程通信中介绍过的管道文件,它属于单向通信,只能一方收,一方发,且不能同时做
- 因为a和b共用一个缓冲区,a使用读方式操作这个缓冲区,b使用写方式操作它
- 在一方进行文件操作时,另一方只能等着
而tcp协议不一样,它是全双工的
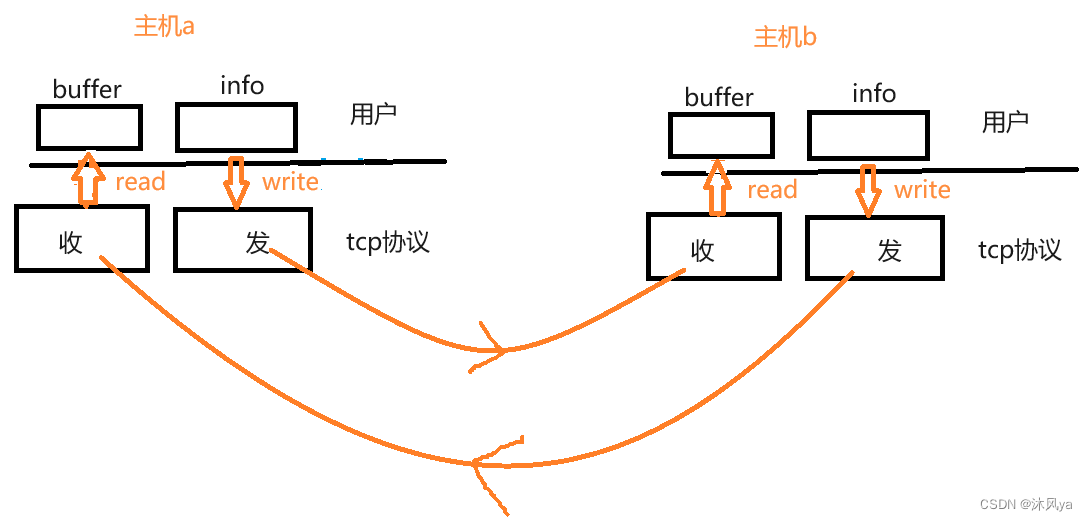
- 因为tcp协议会定义两个缓冲区,分别用于发送和接收
- 这样双方都可以同时进行发送和接收
- 因为此时有四个缓冲区,即使同时rw也都是操作的不同的缓冲区,所以不会有影响:
- 注意,我们之前用于tcp协议的收发数据函数是read和write
- 但他们其实并不涉及网络,而只是一种拷贝函数 -- 将用户数据拷贝到内核缓冲区里,将内核数据拷贝到用户缓冲区(也就是我们定义的数组)里
- 就像上面介绍的一样,tcp协议层数据的收发由tcp协议自己决定 -- 决定什么时候发,发什么,出错了怎么办
- 所以tcp协议属于传输控制协议
- 而read和write只需要等待内容的到来
自定义协议
引入
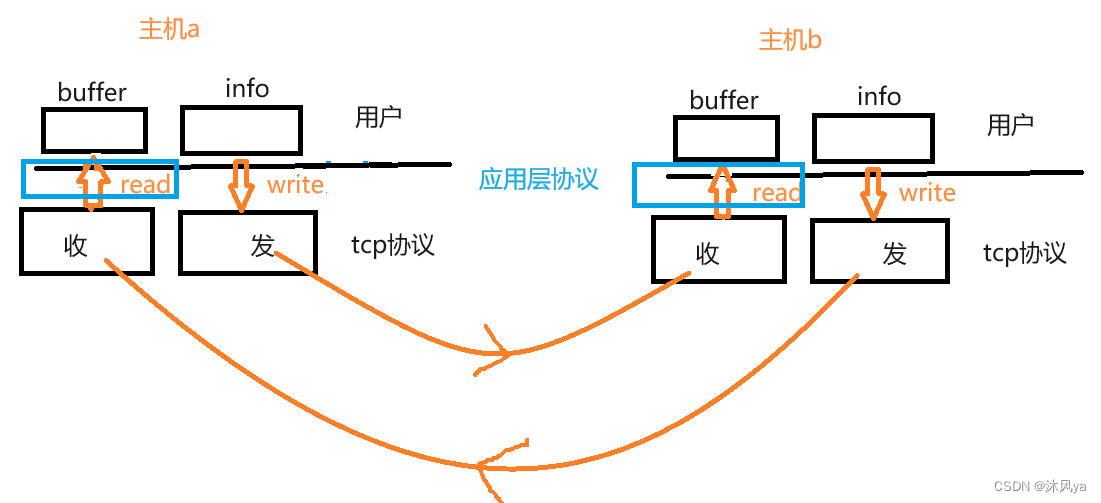
- 就像上面介绍的那样,read不可以直接读取tcp协议传输过来的数据,而是需要处理,因为我们很可能无法正确拿到一份完整的数据
- 并且,很显然tcp不具备这个功能,它只是用来保证数据的可靠性的,而不是正确性,如何解析数据是应用层协议该考虑的
- 所以,我们就需要自定义/使用现有的应用层协议:
其实,前面我们写的都属于自定义协议,只不过定制的只是其中一小部分
- 比如:我们规定好双方都发字符串,规定服务端是echo服务端
- 或者规定好客户端发的是命令,服务端将执行命令
- 或是客户端发的是单词,服务端翻译这个单词
我们以计算器为例,来看看我们该如何自定义协议
计算器
我们需要在cs两端分别传递运算式 和 运算结果+运算是否出错
字符串形式
- 如果使用纯字符串传递,我们需要手动将数据剥离出来
- 比如: 运算式是"1+1" ,需要被剥离成1,1,+
- 计算结果如果是"2,0" (2表示运算结果,0表示运算没有出错)
- 但这样还是会出现上面介绍的问题,我们无法确定一次性读上来的就是一份完整的数据,需要进行字符串分析
结构体形式
- 如果使用结构体,确实可以很轻松地将数据拿到手
- 但是在不同的编译器下,结构体的大小是不一定的
- 还记得结构体的内存对齐吗?
- 不同的系统(比如linux和windows) / 不同的编译器有不同的对齐方式,那么一旦结构体中字段很多, 很可能导致结构体大小不同,同一个字段在结构体内的偏移量不同
- 那么字段就配不上了,客户端在提取时,很可能读出来的字段是空白的/只有一部分/多读了
- 而且,一旦同时有多个请求,服务端会一次拿到多个结构体,如何确定一个完整的结构体的结尾处在哪呢?(因为结构体也是以二进制方式传递的)


思考
所以我们需要考虑其他方法来发送
- 定义结构体的方式很好,只要双方建立起对结构体中字段的约定,使用结构体就可以大大降低我们的通信成本
- 只是,不能直接以结构体对象的方式发送
- 我们可以将两种方式结合在一起使用
结构体是一定要存在的,因为一般我们进行网络通信,都是要传输非常多的结构的
- 比如这里的计算器要传输运算数据,运算符,运算结果,运算状态等等
- 比如聊天时的聊天信息,用户名称,头像,发送时间等等
- 最好的方式就是将他们打包起来
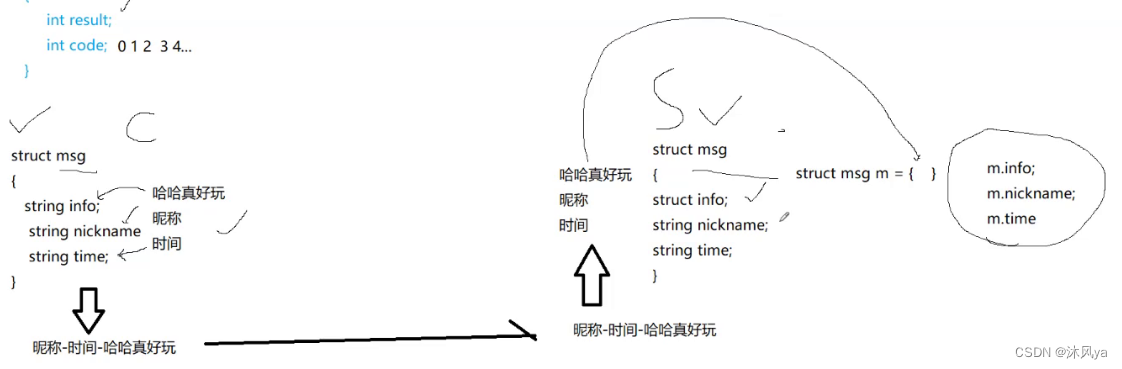
但是我们又不能直接以结构体对象的形式发送给对方,因为双方对于结构体的字段理解虽然相同,但它们不一定处于相同的位置上
- 所以,可以将结构体转换为字符串的形式发送给对方(虽然要进行解析,但总比解决结构体的内存对齐问题要容易的多)
- 然后对方将数据赋值给自己的结构体,结构体会自动将数据填充到对应顺序的字段上
就像下图:
序列化和反序列化
引入
其实
- 定义结构体,也就是定制了协议
- 上面的将结构体->字符串的形式,就是序列化
- 将字符串->结构体的形式,就是反序列化
为什么要进行序列化,反序列化呢?
- 因为以字符串的形式更适合网络通信
- 但我们又不想手动剥离数据
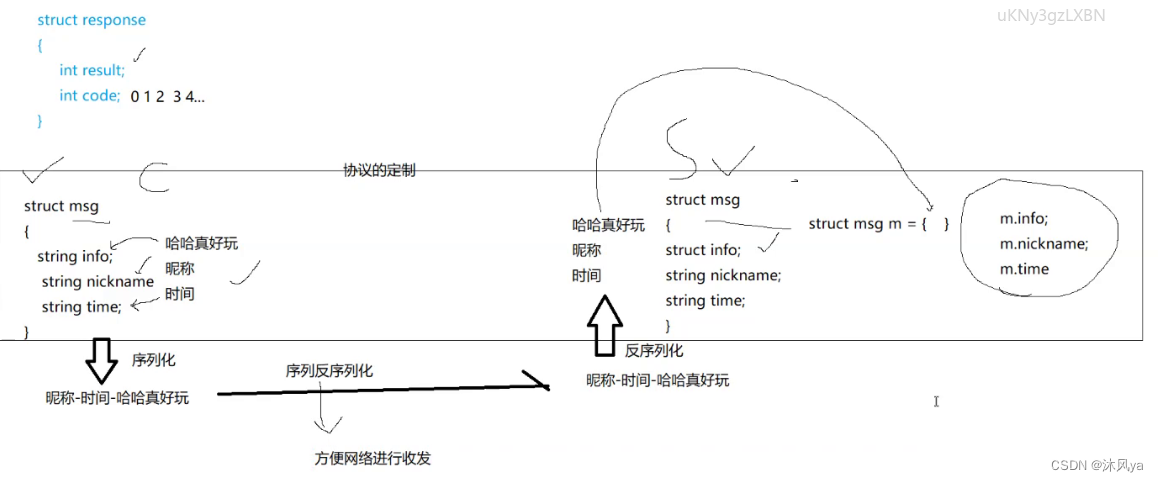
所以,实际上,这样也就形成了分层(两层)
- 第一层只需要定制协议(也就是结构体)
- 第二层只需要保证这个字符串(或者说二进制流)可以被完整发送和接收即可
介绍
序列化
将数据结构或对象转换为字节流的过程
在序列化过程中,对象的状态被保存为一系列字节,可以是二进制格式,也可以是文本格式,例如 JSON 或 XML
序列化后的数据可以在网络上传输或保存到文件中
反序列化
将字节流重新转换为原始数据结构或对象的过程
在反序列化过程中,之前序列化的字节流被解析,并根据其中的数据创建原始的数据结构或对象
计算器代码思路
我们尝试在网络计算器中运用序列化和反序列化
- 定义出请求和响应两个结构体(定制协议)
- 当客户端产生运算请求后,将[赋值好的结构体]经过序列化->字符串,传递给服务端
- 服务端收到报文后,先解析报文(反序列化->请求结构体),然后拿到[操作数和运算符]进行计算,然后将数据赋值给[响应结构体]
- 然后将该结构体序列化->字符串,传回给客户端
- 客户端收到响应报文后,经过解析(反序列化->响应结构体),然后拿到[运算结果和错误码],向用户进行数据显示
而其中的细节 -- 如何区分完整的报文,扩展协议,如何用代码实现,将在下篇博客中介绍
原文地址:https://blog.csdn.net/m0_74206992/article/details/137033058
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!