[iOS]GCD(一)
[iOS]GCD(一)
GCD的概要
GCD的API
Dispatch Queue
dispatch_queue_create
Main Dispatch_set_target_queue
dispatch_after
Dispatch Group
dispatch_barrier_async
复习一下读写锁是啥
读写锁(Readers-Writer Lock)顾名思义是一把锁分为两部分:读锁和写锁,其中读锁允许多个线程同时获得,因为读操作本身是线程安全的,而写锁则是互斥锁,不允许多个线程同时获得写锁,并且写操作和读操作也是互斥的。总结来说,读写锁的特点是:读读不互斥、读写互斥、写写互斥。它适用于多读的业务场景,使用它可以有效的提高程序的执行性能,也能避免读取到操作了一半的临时数据。
前面讲到Concurrent Dispatch Queue可以并行执行操作,显然符合我们读锁的要求,能够高效率地访问数据
而Serial Dispatch Queue显然适合用于在没有读取操作时进行写入操作
这么看单纯使用Serial Dispatch Queue来实现读写操作显然不如二者结合来的效率更快
那么我们要怎么做到这一点呢?
可以使用Dispatch Group和dispatch_set_target_queue实现,但是代码复杂
也有更聪明的方法,那就是dispatch+barrier_async函数
如果只有单纯的读取操作
dispatch_queue_t queue = dispatch_queue_create (
"com. example.gcd. ForBarrier", DISPATCH_QUEUE_CONCURRENT);
dispatch_async (queue, blk0_for_reading);
dispatch_async (queue, bik1_for_reading);
dispatch_async (queue, bik2_for_reading);
dispatch_async (queue, b1k3 for_reading);
dispatch_async (queue, bik4_for_reading);
dispatch_async (queue, bik5 for_reading);
dispatch_async (queue, bik6_for_reading);
dispatch_async (queue, bik7_for_reading);
dispatch_release (queue) ;
在中间加入写入操作时
如果直接加入
NSInteger __block data = 666;
dispatch_queue_t queue = dispatch_queue_create (
"com. example.gcd. ForBarrier", DISPATCH_QUEUE_CONCURRENT);
dispatch_async (queue, ^{
NSLog(@"blk0_for_reading get data:%ld", data);
});
dispatch_async (queue, ^{
NSLog(@"blk1_for_reading get data:%ld", data);
});
dispatch_async (queue, ^{
NSLog(@"blk2_for_reading get data:%ld", data);
});
dispatch_async (queue, ^{
NSLog(@"blk3_for_reading get data:%ld", data);
});
dispatch_async (queue, ^{
NSLog(@"blk4_for_reading get data:%ld", data);
});
dispatch_async (queue, ^{
data = 999;
NSLog(@"data has changed");
});
dispatch_async (queue, ^{
NSLog(@"blk5_for_reading get data:%ld", data);
});
dispatch_async (queue, ^{
NSLog(@"blk6_for_reading get data:%ld", data);
});
dispatch_async (queue, ^{
NSLog(@"blk7_for_reading get data:%ld", data);
});
我们希望的结果是读取结果是在blk5之前读取到的data为666 其余为999
但是结果是这样的
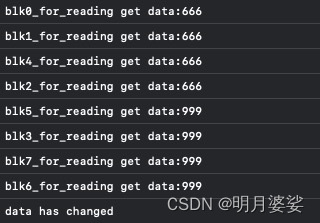
简单地在dispatch_async函数中加入写入处理,那么根据Concurrent Dispatch Queue 的性质,就有可能在追加到写入处理前面的处理中读取到与期待不符的数据,还可能因非法访问导致应用程序异常结束。如果追加多个写入处理,则可能发生更多问题,比如数据竞争等
因此我们要使用dispatch_barrier_async函数。dispatch_barrier_async函数会等待追加到 Concurrent Dispatch Queue 上的并行执行的处理全部结束之后,再将指定的处理追加到该 Concurrent Dispatch Queue中。然后在由dispatch_barrier_async函数追加的处理执行完毕后, Concurrent Dispatch Queue 才恢复为一般的动作,追加到该 Concurrent Dispatch Queue 的处理又开始并行执行。
NSInteger __block data = 666;
dispatch_queue_t queue = dispatch_queue_create (
"com. example.gcd. ForBarrier", DISPATCH_QUEUE_CONCURRENT);
dispatch_async (queue, ^{
NSLog(@"blk0_for_reading get data:%ld", data);
});
dispatch_async (queue, ^{
NSLog(@"blk1_for_reading get data:%ld", data);
});
dispatch_async (queue, ^{
NSLog(@"blk2_for_reading get data:%ld", data);
});
dispatch_async (queue, ^{
NSLog(@"blk3_for_reading get data:%ld", data);
});
dispatch_async (queue, ^{
NSLog(@"blk4_for_reading get data:%ld", data);
});
dispatch_barrier_async (queue, ^{
data = 999;
NSLog(@"data has changed");
});
dispatch_async (queue, ^{
NSLog(@"blk5_for_reading get data:%ld", data);
});
dispatch_async (queue, ^{
NSLog(@"blk6_for_reading get data:%ld", data);
});
dispatch_async (queue, ^{
NSLog(@"blk7_for_reading get data:%ld", data);
});
结果如下
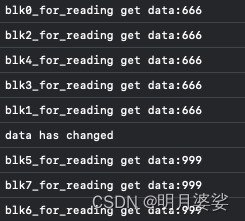
咱们的dispatch_barrier_async函数到底干了啥?一张图告诉你
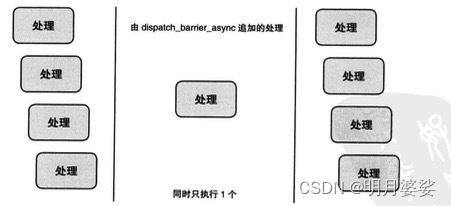
不难看出,使用Concurrent DispatchQueue和dispatch_barrier_async函数可实现高效率的数据库访问和文件访问
哦对了 加个TIPS
从iOS 6和OS X 10.8开始,GCD(Grand Central Dispatch)引入了ARC(Automatic Reference Counting)来管理内存,这意味着你不需要手动调用 dispatch_release 来释放队列。ARC会自动处理内存管理,包括对 GCD 中的对象的管理。因此,调用 dispatch_release(queue) 是多余且无效的,反而可能导致错误。
如果你在使用 ARC 环境下编写代码,并且需要创建和管理 Dispatch Queue,只需简单地调用 dispatch_queue_create 来创建队列,然后将其用于任务调度即可。记住不要在 ARC 下手动释放 GCD 的对象,因为 ARC 会自动处理内存管理。
dispatch_apply
dispatch_async 函 数 的 “ async ” 意 味 着 “ 非 同 步 ” (asynchronous),就是将指定的Block“非同步” 地追加到指定的DispatchQueue中。dispatch_async 函数不做任何等待
既然有“async”,当然也就有“sync”,即dispatch_sync 函数。它意味着“ 同步” (synchronous),也就是将指定的Block“同步”追加到指定的 Dispatch Queue中。在追加Block 结束之前,dispatch_sync 函数会一直等待
如dispatch_group _wait 函数说明所示,“ 等待” 意味着当前线程停止。
一旦调用dispatch_sync函数,那么在指定的处理执行结束之前,该函数不会返回。dispatch_ sync 函数可简化源代码,也可说是简易版的dispatch_group_wait 函数
看看下面这个运用了dispatch_sync函数的简单代码
dispatch_queue_t queue = dispatch_get_global_queue (DISPATCH_QUEUE_ PRIORITY_DEFAULT, 0);
dispatch_sync (queue , ^{/ * 处理 * /});
执行MainDispatchQueue时,使用另外的线程GlobalDispatch Queue 进行处理
在另外的线程GlobalDispatch Queue 处理结束后dispatch_sync再使用所得到的结果进行处理
因为dispatch_sync函数使用简单,所以也容易引起问题,即死锁
不知道大家还记不记得自动引用计数部分提到的保留环?
保留环(Retain Cycle)是指两个或多个对象在彼此之间互相持有对方的强引用,导致它们无法被释放,从而造成内存泄漏的情况。当两个对象互相持有对方的强引用时,它们的引用计数永远不会变为零,因此系统也无法释放它们所占用的内存空间。
保留环里也有自己持有自己强引用的状态
这里的死锁可以类比理解
比如下面这个代码

sync在等待主线程结束再执行自己的的操作
听起来很合理对不对?
那么主线程在干嘛,主线程在追加sync的操作
也是保留环中属于互相持有,释放不掉了
与Main Dispatch Queue共用出现死锁

与Serial Dispatch Queue共用出现死锁

由dispatch_barrier_async函数中含有async可推测出,相应的也有dispatch_barrier_ sync函数。dispatch_barrier_async函数的作用是在等待追加的处理全部执行结束后,再追加处理到DispatchQueue中,此外 ,它还与dispatch_sync函数相同,会等待追加处理的执行结束。
dispatch_apply
dispatch_apply 函数是 dispatch_sync 函 数 和 DispatchGroup 的关联API。该函数按指定的次数将指定的Block 追加到指定的Dispatch Queue 中,并等待全部处理执行结束
来一段代码
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
dispatch_apply(10, queue, ^(size_t index) {
NSLog (@"%zu", index);
});
NSLog (@"done");
结果为

因为在Global Dispatch Queue 中执行处理,所以各个处理的执行时间不定。但是输出结果中 最后的done必定在最后的位置上。这是因为dispatch_apply函数会等待全部处理执行结束
那么这个函数那么多参数,到底传什么?怎么用?
第一个参数为重复次数
第二个参数为追加对象的Dispatch Queue
第三个参数为追加的处理
与到目前为止所出现的例子不同,第三个参数的Block 为带有参数的Block。这是为了按第一 个参数重复追加Block 并区分各个Block 而使用。例如要对NSArray 类对象的所有元素执行处 理时,不必一个一个编写for循环部分,而是可以这样、
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
dispatch_apply(10, queue, ^(size_t index) {
t index) {
NSLog (@"%zu: %@", index, [array objectAtIndex:index]) ;
});
NSLog (@"done");
这样可简单地在Global DispatchQueue 中对所有元素执行Block
另外,由于dispatch_apply函数也与dispatch_sync函数相同,会等待处理执行结束,因此推荐 在 dispatch_async 函数中非同步地执行 dispatch_apply 函数
dispatch_suspend/dispatch_resume
当追加大量处理到Dispatch Queue 时,在追加处理的过程中,有时希望不执行已追加的处理 。例如演算结果被Block截获时, 一些处理会对这个演算结果造成影响。在这种情况下, 只要挂起 Dispatch Queue 即可,当可以执行时再恢复
dispatch_suspend 函数挂起指定的Dispatch Queue
dispatch_suspend (queue) ;
dispatch_resume 函数恢复指定的Dispatch Queue
dispatch_resume (queue) ;
这些函数对已经执行的处理没有影响
挂起后,追加到Dispatch Queue中但尚未执行的处理在此之后停止执行
而恢复则使得这些处理能够继续执行。
Dispatch Semaphore
如前所述,当并行执行的处理更新数据时,会产生数据不一致的情况,有时应用程序还会异 常结束。虽然使用Serial Dispatch Queue和dispatch_barrier_async函数可避免这类问题,但有必要进行更细粒度的排他控制
dispatch_queue_t queue = dispatch_get_global_queue (DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
NSMutableArray *array = [[NSMutableArray alloc]init];
for (int i = 0; i < 100000; ++i) {
dispatch_async (queue, ^{
[array addObject: [NSNumber numberWithInt:i]];
});
}
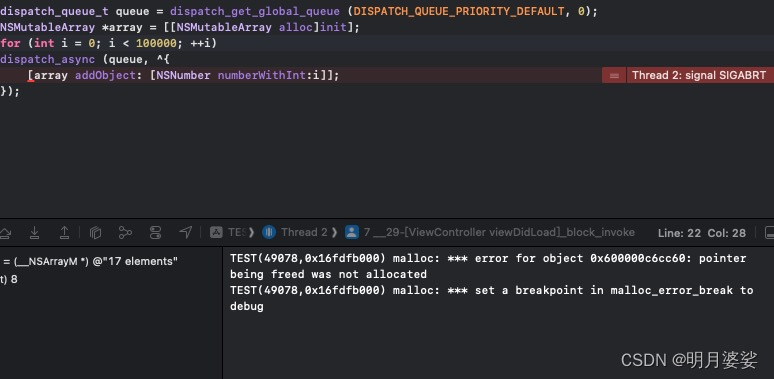
因为该源代码使用Global Dispatch Queue 更新NSMutableArray 类对象,所以执行后由内存错误导致应用程序异常结束的概率很高。此时应使用Dispatch Semaphore
Dispatch Semaphore 是持有计数的信号,该计数是多线程编程中的计数类型信号。所谓信号,类似于过马路时常用的手旗。可以通过时举起手旗,不可通过时放下手旗。而在 Dispatch Semaphore 中,使用计数来实现该功能。计数为0 时等待,计数为1 或大于1 时,减去1 而不等待
通过dispatch_ semaphore_create函数生成DispatchSemaphore
dispatch_semaphore_t semaphore = dispatch_semaphore_create(1);
参数表示计数的初始值。本例将计数值初始化为“1”
dispatch_semaphore_wait (semaphore, DISPATCH_TIME_FOREVER);
dispatch_semaphore_wait 函数等待 DispatchSemaphore的计数值达到大或等于1。当计数值大于等于1,或者在待机中计数值大于等于1时,对该计数进行减法并从dispatch_semaphore_wait 函数返回。第二个参数与dispatch_group_wait 函数等相同,由dispatch_time_t 类型值指定等待时间。该例的参数意味着永久等待。dispatch_semaphore_wait 函数的返回值也与 dispatch_group _wait 函数相同
直接上个代码
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
/*
* 生成DispatchSemaphore
* DispatchSemaphore 的计数初始值设定为“ 1 ”
* 保证可访问NSMutableArray类对象的线程
* 同时只能有1个
*/
dispatch_semaphore_t semaphore = dispatch_semaphore_create(1);
NSMutableArray *array = [[NSMutableArray alloc] init];
for(int i = 0; 1 < 100000; ++i) {
dispatch_async (queue, ^{
/*
* 等待Dispatch Semaphorea
* 一直等待到DispatchSemaphore的计数值达到大于等于1
*/
dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);
/*
* 由于Dispatch Semaphore的计数值达到大于等于1 所以将Dispatch Semaphore的计数值减去1,
* dispatch_semaphore_wait 函数执行返回。
* 即执行到此时的
* DispatchSemaphore 的计数值恒为“ 0 ”
* 由于可访问NSMutableArray 类对象的线程只有 1 个
* 因此可安全地进行更新。
*/
[array addObject: [NSNumber numberWithInt:i]];
/*
* 排他控制处理结束,
* 所以通过 dispatch_semaphore_signal 函数将Dispatch Semaphore的计数值加1
* 如果有通过dispatch _semaphore_wait 函数
* 等待Dispatch Semaphore的计数值增加的线程
* 就由最先等待的线程执行。
*/
dispatch_semaphore_signal(semaphore);
});
}
在没有Serial Dispatch Queue 和dispatch_barrier_async 函数那么大粒度且一部分处理需要进 行排他控制的情况下,Dispatch Semaphore 便可发挥威力
dispatch_once
dispatch _once函数是保证在应用程序执行中只执行一次指定处理的API
下面这种经常出现 的用来进行初始化的源代码可通过dispatch _once函数简化
static int initialized = NO;
if (initialized = NO) {
/*
* 初始化
*/
initialized = YES;
}
如果使用dispatch _once函数,则源代码写为:
static dispatch_once_t pred;
dispatch_once (&pred, ^ (
/*
* 初始化
*/
});
源代码看起来没有太大的变化。但是通过dispatch _once函数,该源代码即使在多线程环境 下执行,也可保证百分之百安全,然后这也是学单例时讲过的老朋友了,不多赘述
Dispatch I/O
大家可能想过,在读取较大文件时,如果将文件分成合适的大小并使用Global Dispatch Queue 并列读取的话,应该会比一般的读取速度快不少。现今的输入/ 输出硬件已经可以做到一 次使用多个线程更快地并列读取了。能实现这一功能的就是Dispatch I/O 和Dispatch Data。
通过Dispatch
I/O读写文件时,使用GlobalDispatchQueue 将1 个文件按某个大小read/write
dispatch_async (queue, ^{/*读取0~8191字节*/});
dispatch_async (queue, ^{/*读取8192~16383字节*/});
dispatch_async (queue, ^(/*速取16384~24575字节*/});
dispatch_async (queue, ^(/*读取24576~32767字节*/});
dispatch_async (queue, ^(/*读取32768~40959字节*/});
可像上面这样,将文件分割为一块一块地进行读取处理。分割读取的数据通过使用Dispatch Data 可更为简单地进行结合和分割
如果想提高文件读取速度,可以尝试使用Dispat ch I/ O
GCD的实现
Dispatch Queue
通常,应用程序中编写的线程管理用的代码要在系统级实现。
实际上正如这句话所说,在系统级即iOS 和OSX的核心XNU内核级上实现。 因此,无论编程人员如何努力编写管理线程的代码,在性能方面也不可能胜过XNU内核级所实现的 GCD
使用GCD要比使用pthreads 和NSThread 这些 一般的多线程编程API更好
并且使用GCD 就不必编写为操作线程反复出现的类似的源代码 (这被称为固定源代码片断),而可以在线程中集中实现处理内容

编程人员所使用GCD的API 全部为包含在libdispatch库中的C语言函数。DispatchQueue 通过 结构体和链表,被实现为FIFO队列。
FIFO队列管理是通过dispatch_async等函数所追加的Block
Block并不是直接加入FIFO队列,而是先加入DispatchContinuation这一dispatch_continuation_t 类型结构体中,然后再加入FIFO队列。该Dispatch Continuation 用于记忆Block 所属的Dispatch Group 和其他一些信息,相当于一般常说的执行上下文
DispatchQueue可通过dispatch_set_target _queue函数设定,可以设定执行该DispatchQueue 处理的DispatchQueue 为目标。该目标可像串珠子一样,设定多个连接在一起的DispatchQueue。
但是在连接串的最后必须设定为Main Dispatch Queue,或各种优先级的Global Dispatch Queue,
或是准备用于Serial DispatchQueue 的各种优先级的Global DispatchQueue
Main Dispatch Queue 在RunLoop 中执行Block
Global Main Dispatch Queue 有如下8种
• Global Dispatch Queue (High Priority)
• Global Dispatch Queue (Default Priority)
• Global Dispatch Queue (Low Priority)
• Global Dispatch Queue (Background Priority)
• Global Dispatch Queue (High Overcommit Priority)
• Global Dispatch Queue (Default Overcommit Priority)
• Global Dispatch Queue (Low Overcommit Priority)
• Global Dispatch Queue (Background Overcommit Priority)
优先级中附有Overcommit 的Global Dispatch Queue 使用在Serial Dispatch Queue 中。如 Overcommit 这个名称所示,不管系统状态如何,都会强制生成线程的DispatchQueue
这8种GlobalDispatchQueue各使用1个pthrcead_workqueue 。GCD初始化时,使用pthread_ work queue_create_np 函数生成pthread_workqueue。
pthread
Lworkqueue包含在Libc提供的pthreadsAPI中。其使用bsdthread_register fil workq_open 系统调用,在初始化XNU内核的workqueue之后获取workqueue信息。
XNU内核持有4种workqueue
• WORKQUEUE_HGIH_PRIOQUEUE
• WORKQUEUE_DEFAULT_PRIOQUEUE
• WORKQUEUE_LOW_PRIOQUEUE
• WORKQUEUE_BG_PRIOQUEUE
以上为4 种执行优先级的workqueue。该执行优先级与Global Dispatch Queue 的4种执行优先级相同
先级相同。
下面看一下Dispatch Queue 中执行 Block 的过程
当在 Global Dispatch Queue 中执行 Block 时 , 从 Global Dispatch Queue 自身的 FIFO 队列中取出 DispatchContinuation,调用 pthread_workqueue_additem_np 函数。将该Global Dispatch Queue 自身、符合其优先级的workqueue 信息 以及为执行DispatchContinuation 的回调函数等传递给参数
pthread_workqueue_additem_np 函数使用workq_kemretur 系统调用,通知workqueue 增加应 当执行的项目。
根据该通知,XNU 内核基于系统状态判断是否要生成线程。
如果是Overcommit 优先级的GlobalDispatchQueue, workqueue则始终生成线程。
该线程虽然与iOS和OSX中通常使用的线程大致相同,但是有一部分pthreadAPI 不能使用。
另外,因为workqueue 生成的线程在实现用 于workqueue 的线程计划表中运行,所以与 一般 线程的上下文切换不同。这里也隐藏着使用GCD的原因。
workqueue 的线程执行pthread_workqueue 函数,该函数调用libdispatch 的回调函数。在该回 调函数中执行加入到DispatchContinuation 的Block。
Block 执行结束后,进行通知Dispatch Group 结束、释放Dispatch Continuation 等处理,开始 准备执行加入到Global DispatchQueue中的下一个Block。
以上就是Dispatch Queue 执行的大概过程
Dispatch Source
GCD中除了主要的DispatchQueue外,还有不太引人注目的Dispatch Source。它是BSD系内核惯有功能kqueue的包装。
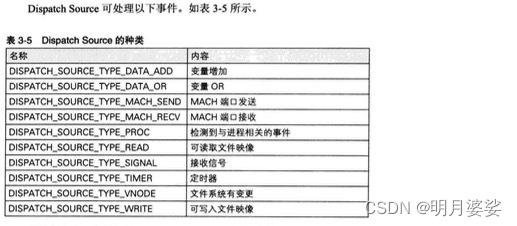
事件发生时,在指定的DispatchQueue 中可执行事件的处理。 下面我们使用DISPATCH_SOURCE _TYPE _READ,异步读取文件映像。
//不贴代码了
//书上这一段一直报错
//and我也没看懂这个部分
实际上 Dispatch Queue 没有“取消”这 一概 念 。 一旦将处理追加到 Dispatch Queue 中,就 没有方法可将该处理去除,也没有方法可在执行中取消该处理。编程人员要么在处理中导入取消这一概念, 要么放弃取消,或者使用NSOperationQueue 等其他方法。
Dispatch Source 与Dispatch Queue 不同,是可以取消的。而且取消时必须执行的处理可指定 为回调用的Block 形式。因此使用Dispatch Source 实现XNU 内核中发生的事件处理要比直接使用 kqueue 实现更为简单。
原文地址:https://blog.csdn.net/m0_74703932/article/details/136970524
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!