Python OCR 文字识别使用模型:读光-文字识别-行识别模型-中英-通用领域
介绍
什么是OCR?
OCR是“Optical Character Recognition”的缩写,中文意为“光学字符识别”。它是一种技术,可以识别和转换打印在纸张或图像上的文字和字符为机器可处理的格式,如计算机文本文件。通过使用OCR技术,可以快速地将纸质文档数字化,从而使文本可以被编辑、搜索和分析。这项技术广泛应用于各种场合,如图书馆和档案馆的文献数字化、 pdf 文件的文本搜索、以及扫描文档中的条形码和二维码等。
阿里云文字识别OCR(读光OCR)
阿里云文字识别OCR(读光OCR),是一款由阿里巴巴达摩院打造的OCR产品,用于识别图片、文档、卡证等文件所包含的文字信息。
行识别模型
行识别模型是一种用于识别文本行中的字符内容的算法模型。它在光学字符识别(OCR)领域中扮演着重要的角色,专注于将文本行中的字符转换成可识别的文本。
行识别模型可以应用于各种应用场景,如自动化文档处理、车牌识别、手写体识别等,为实现自动化文本识别提供了重要的基础,有助于提高工作效率和准确性。
我们这里使用的是 “阿里云文字识别OCR(读光OCR)” 的模型放到本地来进行识别测试。
前置条件
1、准备电脑环境(我当前用的是 4060 显卡)
2、安装环境(conda、python)
3、下载模型(通过下方链接地址下载模型)
https://www.modelscope.cn/models/iic/cv_convnextTiny_ocr-recognition-general_damo/summary
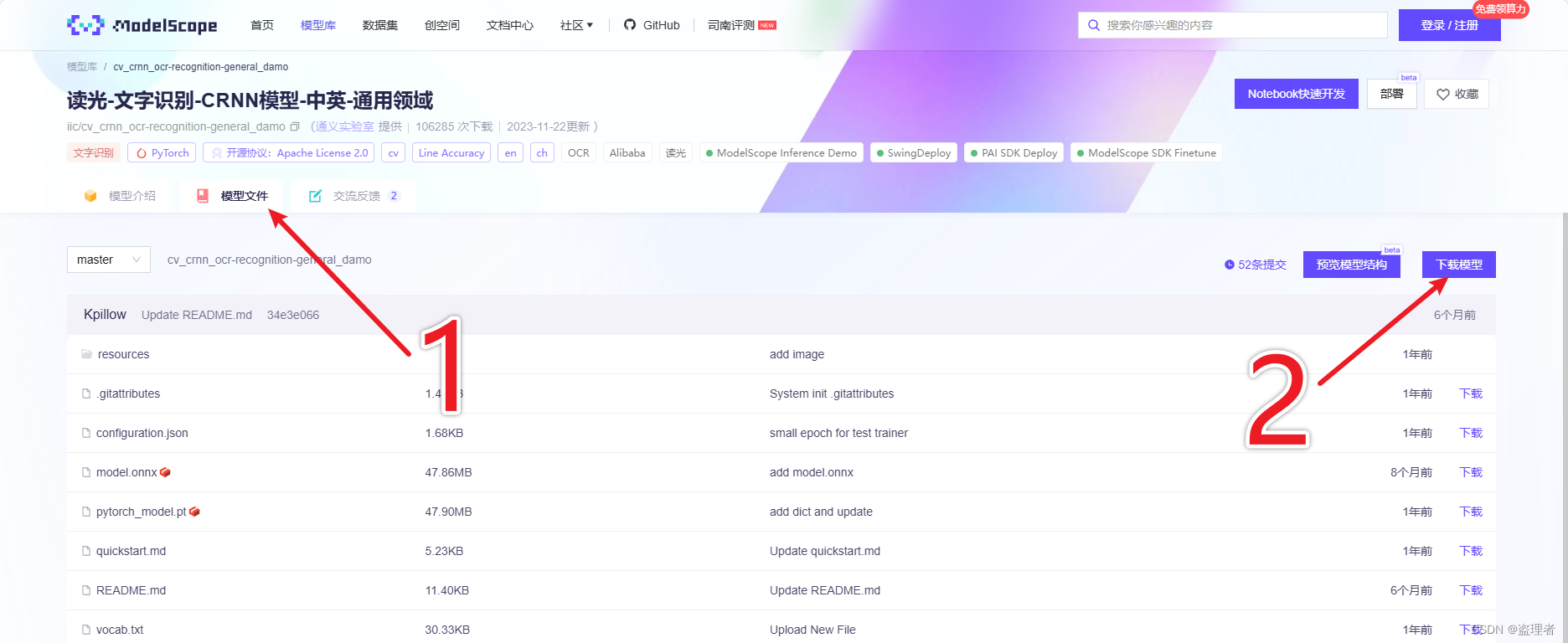
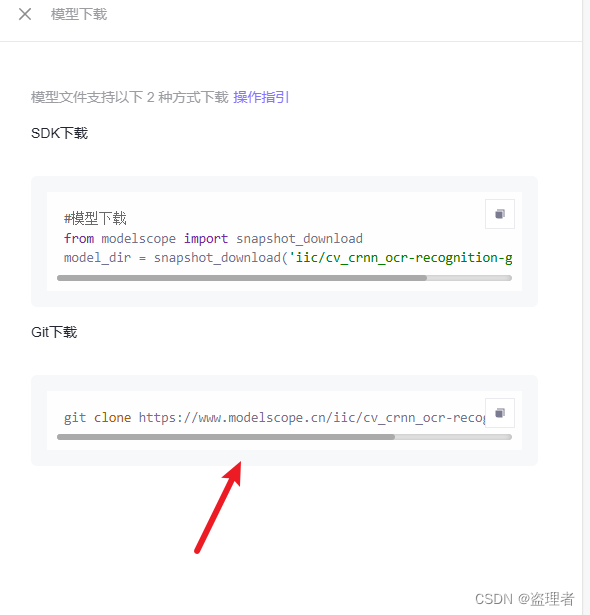
克隆下来后。
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
ocr_recognition = pipeline(Tasks.ocr_recognition, model='damo/cv_convnextTiny_ocr-recognition-general_damo')
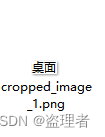
img_url = 'cropped_image_1.png'
result = ocr_recognition(img_url)
print(result)
-
from modelscope.pipelines import pipeline:从 ModelScope 库中的pipelines模块导入pipeline函数。这个函数用于创建一个模型管道,可以用来执行各种任务,如文本分类、命名实体识别、OCR 等。 -
from modelscope.utils.constant import Tasks:从 ModelScope 库中的utils.constant模块导入Tasks常量。这个常量包含了 ModelScope 支持的不同任务类型,包括 OCR。 -
ocr_recognition = pipeline(Tasks.ocr_recognition, model='damo/cv_convnextTiny_ocr-recognition-general_damo'):调用pipeline函数创建一个 OCR 识别任务的管道。Tasks.ocr_recognition指定了这是一个 OCR 识别任务,而'damo/cv_convnextTiny_ocr-recognition-general_damo'则指定了使用的模型名称或者模型路径。 -
img_url = 'cropped_image_1.png':定义一个变量img_url,用来存储待识别的图像文件的路径或者 URL。 -
result = ocr_recognition(img_url):调用ocr_recognition管道,传入待识别的图像路径,并将识别结果保存在result变量中。 -
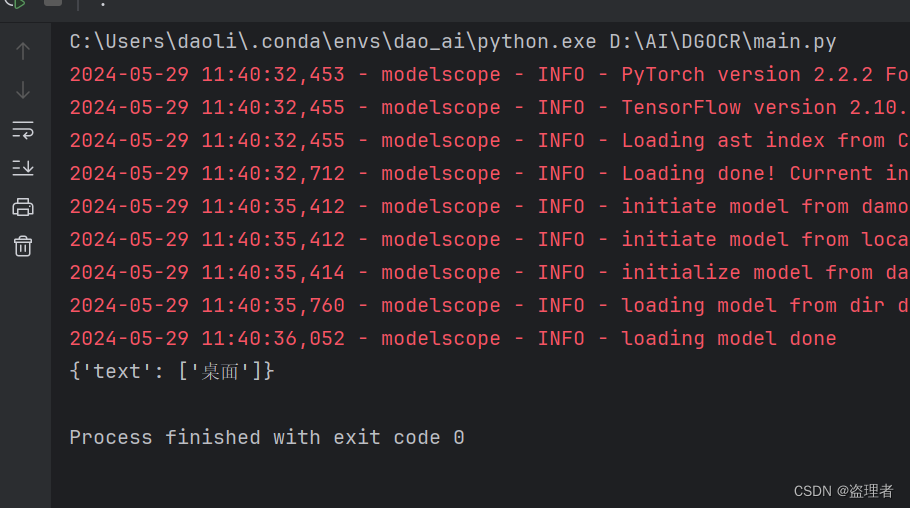
print(result):打印 OCR 识别的结果。
需要识别的图片:
运行结果:
原文地址:https://blog.csdn.net/qq_36051316/article/details/139291286
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!