内存管理概念(一)
目录
一. 内存管理基本原理和要求
内存管理(Memory Management):操作系统设计最重要和最复杂的内容之一,用于对内存的划分和动态分配。
主要功能:
- 内存空间的分配与回收:操作系统负责内存空间的分配和管理,记录内存空闲空间、内存分配情况,并回收已结束进程占用的内存空间。
- **地址转换:**逻辑地址------>物理地址。
- **内存空间的扩充:**利用虚拟存储系统,从逻辑上扩充内存。
- **内存共享:**多进程访问内存空间的相同部分。
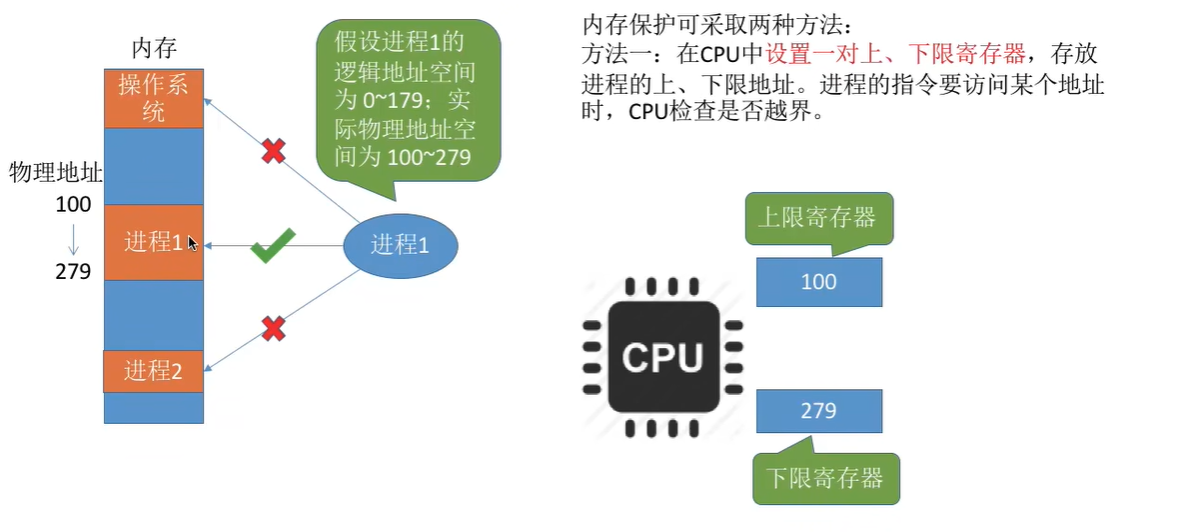
- **存储保护:**保证各个进程在各自存储空间运行,互不干扰。
程序的链接与装入
- 编译:由编译程序完成。源代码 ----> 若干目标模块。
- 链接:链接程序完成。一组目标模块 -----> 一个完整的装入模块。
- 装入:装入程序完成。 装入模块 ----> 装入内存。
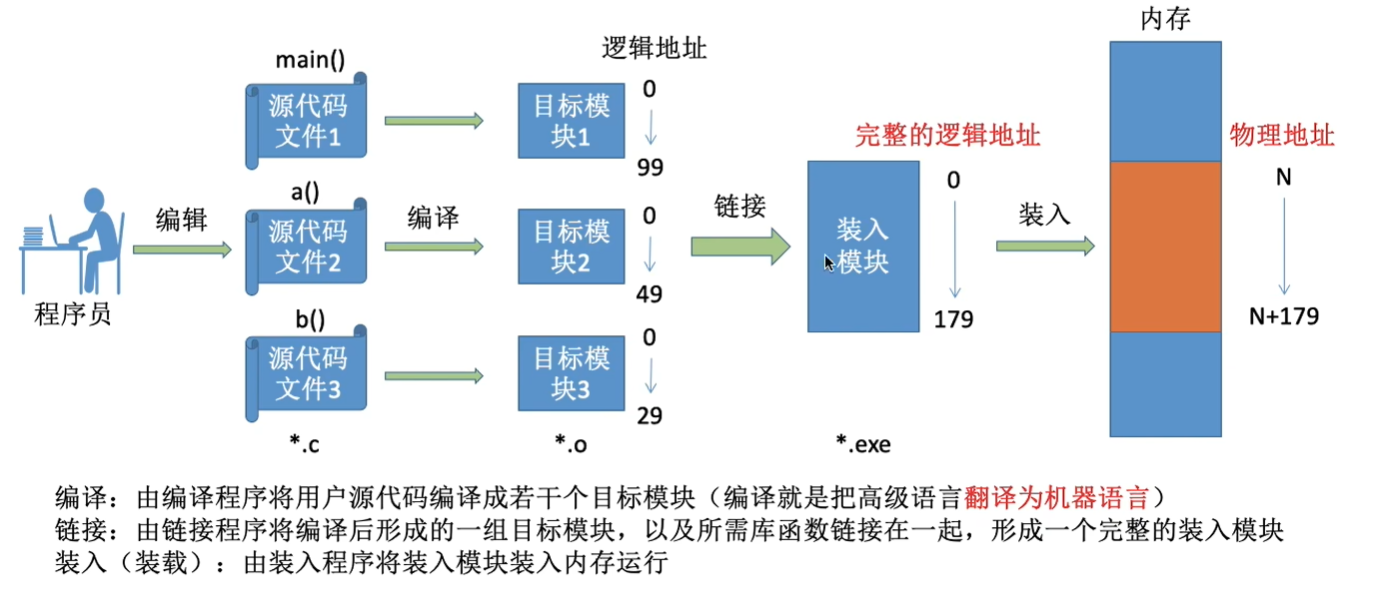
静态链接
- 程序运行之前,将各模块以及所需库函数链接成一个完整装入模块,以后不再拆开。
- 特点
- 修改相对地址:编译后所有目标模块都是从 0 开始的相对地址,链接成一个装入模块时修改相对地址。
- 变换外部调用符号:每个模块中外部调用符号都变换为相对地址。
装入时动态链接
- 编译后得到的一组目标模块,装入内存时,边装入边链接。
- 优点:便于修改和更新,实现目标模块共享。
运行时动态链接
- 执行目标模块时,才进行链接。未用到的目标模块都不会调入内存和链接到装入模块。
- 优点:加快程序装入过程,节省内存空间。
绝对装入
- 编译时已知程序存放在内存中的位置,编译程序产生绝对地址目标代码。
- 特点:
- 只适应于单道程序环境(无操作系统阶段),灵活性低。
- 不需要对程序和数据的地址进行修改。
- 绝对地址来源:编译或汇编时给出;程序员直接赋予。
通常情况,在程序中采用符号地址,编译或汇编时转换为绝对地址。
可重定位装入(静态重定位)
编译,链接后装入模块的起始地址通常从 0 开始,程序中指令和数据地址都是相对于起始地址的。
此时应采用可重定位装入方式。(早期多道批处理阶段)
- 根据内存当前情况,将装入模块装入内存适当位置。
- 重定位:装入时对目标程序中的相对地址进行修改的过程。
由于 地址转换 是在 装入时一次完成的,故称静态重定位。
- 一个作业装入内存时,必须给它分配要求的全部内存空间;若没有足够内存,则无法装入。
- 作业一旦进入内存,整个运行期间不能在内存中移动,也不能再申请内存空间。

动态运行时装入
亦称 动态重定位。若程序需要在内存中发生移动,需要采用的装入方式。(现代操作系统)
- 装入模块进入内存后,不会立即将相对地址转换为绝对地址,而是将地址转换推迟到程序真正执行时候。
- 装入内存后的地址为相对地址,因此需要一个 **重定位寄存器(存放装入模块的起始位置)**的支持。
- 优点
- 可以将程序分配到不连续的存储区。
- 程序运行之前只需要装入部分代码即可投入运行。
- 运行期间根据动态申请分配内存。
- 便于程序段的共享。
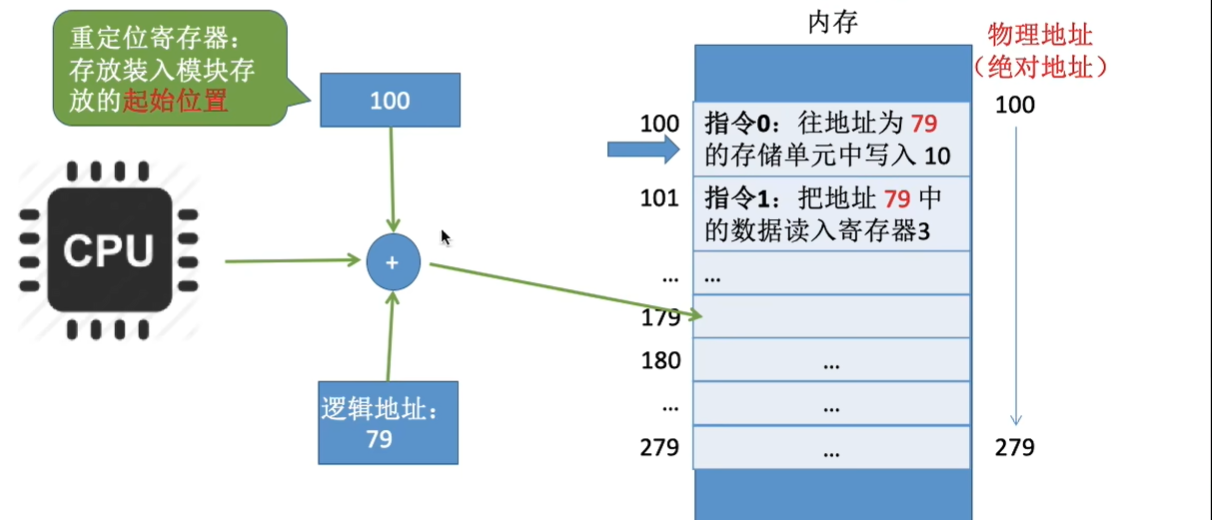
逻辑地址与物理地址
- 物理地址:内存中物理单元的集合,地址转换的最终地址。可执行程序将可执行代码装入内存时,将逻辑地址转换为物理地址的过程 —— 地址重定位。
- 逻辑地址:OS 通过内存管理部件(MMU)将进程的逻辑地址转换为物理地址。逻辑地址通过页表映射到物理内存,页表由操作系统维护并被处理器引用。
进程的内存映像
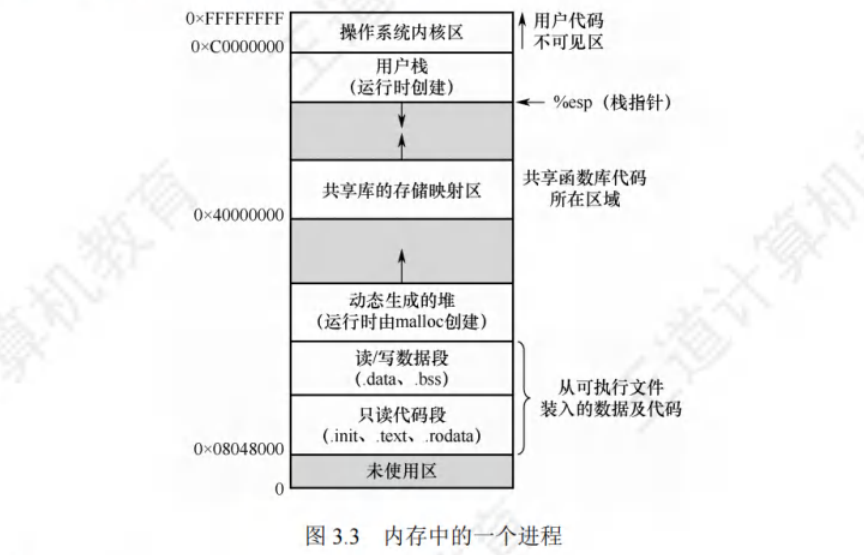
程序调入内存运行时候,构成进程的内存映像。构成要素如下:
- 代码段:程序的二进制代码,只读,可被多进程共享。
- 数据段:程序运行时加工处理的对象,包括全局部变量,静态变量。
代码段,数据段 调入内存时就指定大小。
- 进程控制块(PCB):存放在系统区。OS 通过 PCB 管理和控制进程。
- 堆:存放动态分配的变量。通过调用 malloc 函数动态地从低地址向高地址分配空间。
堆,调用 malloc 和 free 等 C 语言标准库函数时候,堆可以在运行时动态地扩展和收缩。
- 栈:用来实现函数调用。从用户空间(地址最高)最高地址向低地址增长。
用户栈 运行时候 可以动态地扩展和收缩
- 调用一次函数,栈增长;
- 从一个函数返回,栈收缩。
内存映像的其他相关部分
- 共享库:存放进程使用的共享函数库代码,如:printf() 函数等。
- .init:只读代码段中,初始化时调用的 _init 函数。
- .text:用户程序的机器代码。
- .rodata:只读数据。
- .data:读/写数据段中,存放已初始化的全局变量和静态变量。
- .bss:未初始化的数据以及所有初始化为 0 的全局变量和静态变量。
内存保护
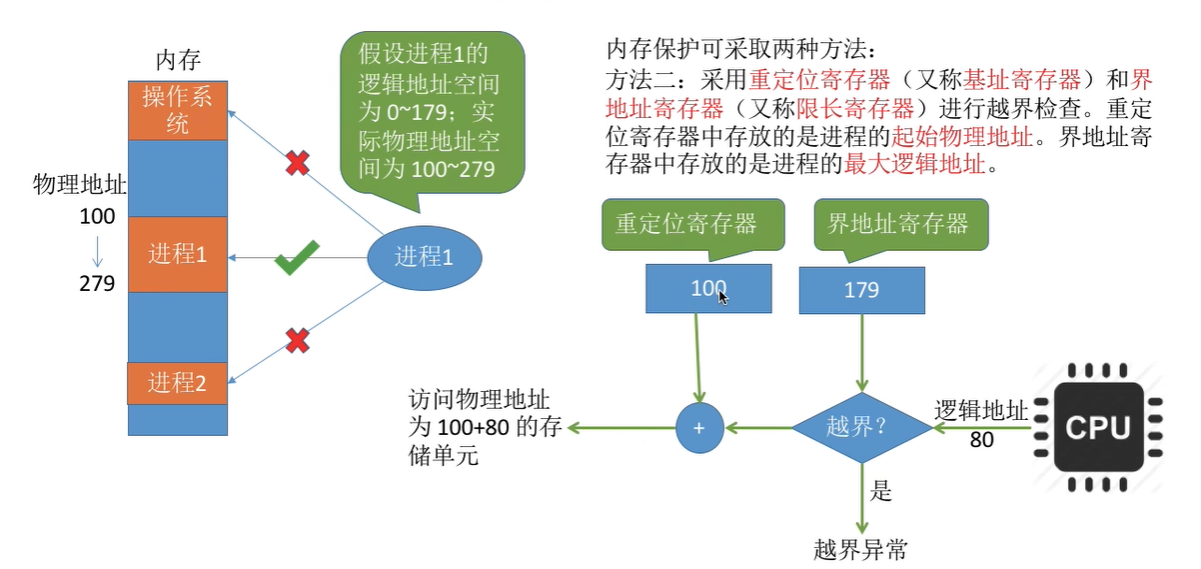
内存共享
- 只有只读区域可以实现共享。
- 可重入代码,亦称 纯代码:一种允许多个进程同时访问但不允许被任何进程修订的代码。
实际执行时,可以为每一个进程分配局部数据区,将执行中可能改变的部分复制到该数据区。
这样,程序执行时,只对该私有数据区中的内存进行修改,并不改变共享代码。
内存分配与回收
存储管理方式随着操作系统的发展而发展。在操作系统由单道向多道发展时,存储管理方式便由单一连续分配发展为固定分区分配。为了能更好地适应不同大小的程序要求,又从固定分区分配发展到动态分区分配。为了更好地提高内存的利用率,进而从连续分配方式发展到离散分配方式——页式存储管理。
引入分段存储管理的目的,主要是满足用户在编程和使用方面的要求,其中某些要求是其他几种存储管理方式难以满足的。
二. 连续分配管理方式
连续分配:即为一个用户程序分配一个连续的内存空间。包括单一连续分配,固定分区分配和动态分区分配。
单一连续分配
- 内存被分为系统区和用户区
- 系统区:仅供操作系统使用,通常在低地址部分。
- 用户区:用户内存仅有一道用户程序,独占内存。
- 特点:
- 优点:简单,无外部碎片;不需要内存保护(由于程序独占内存)。
- 缺点:只能用于单用户,单任务的操作系统;有内部碎片;存储器利用率低。
内部碎片现象:程序小于分区大小,但也会占用一个完整内存分区,出现空间浪费。

固定分区分配
最简单的多道程序存储管理方式。
- 将用户内存空间划分为若干个固定大小的分区,每个分区只装入一道作业。空闲分区时,便可从外部后备作业队列选择装入。
- 划分分区的方法
- 分区大小相等。程序太小造成浪费,太大无法装入,缺乏灵活性。
- 分区大小不等。划分为多个较小分区、适中中等分区和少量大分区。
- 为了方便分配回收,建立分区使用表,通常按分区大小排序。包含部分如下:
- 分区起始地址
- 分区大小
- 分区的状态(是否已分配)
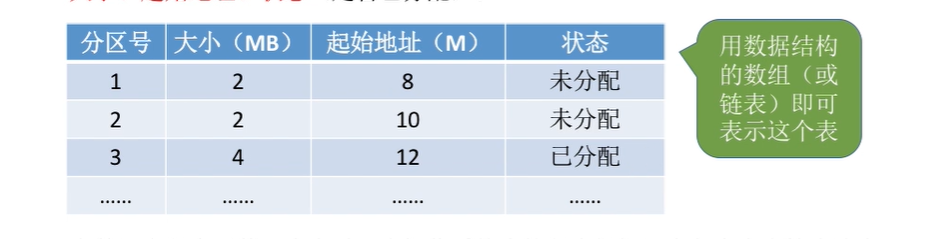
存在的问题:
- 程序太大不能放入任何一个分区。
- 有内部碎片:程序小于一个固定分区,也会占用一个完整内存分区,出现空间浪费。
- 固定分区方式无外部碎片,但是不能实现多进程共享一个主存区,存储空间利用率低。
动态分区分配
基本原理

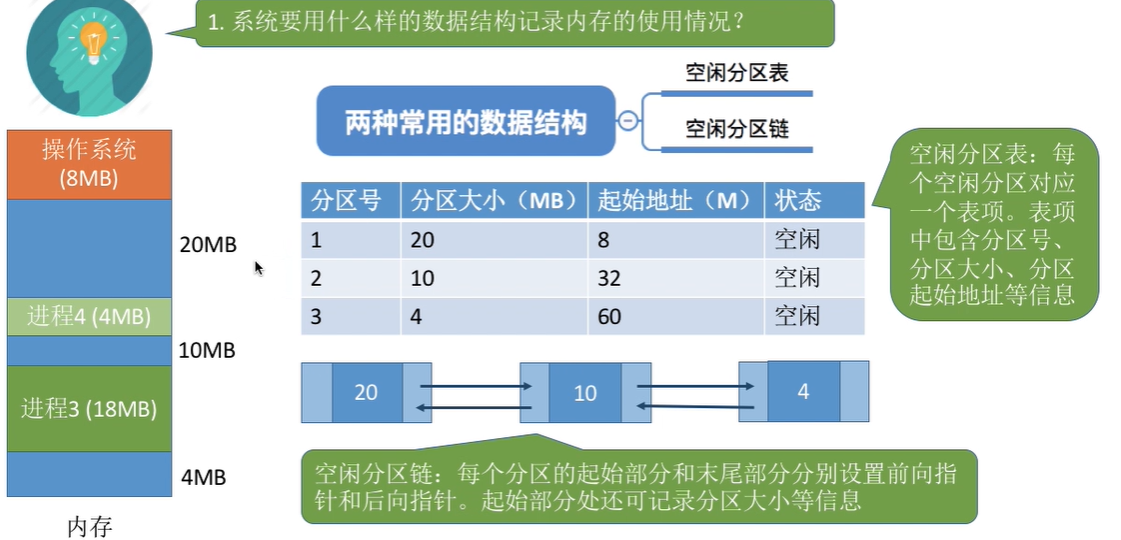

内存分配与回收方法
假设采用空闲分区表结构
- 内存分配
- 分配的空间大小 > 需要的内存空间大小:仅仅修改对应分区的大小和起始地址。
- 分配的空间大小 = 需要的内存空间大小:直接删除该空闲分区对应的表项。
- 内存回收
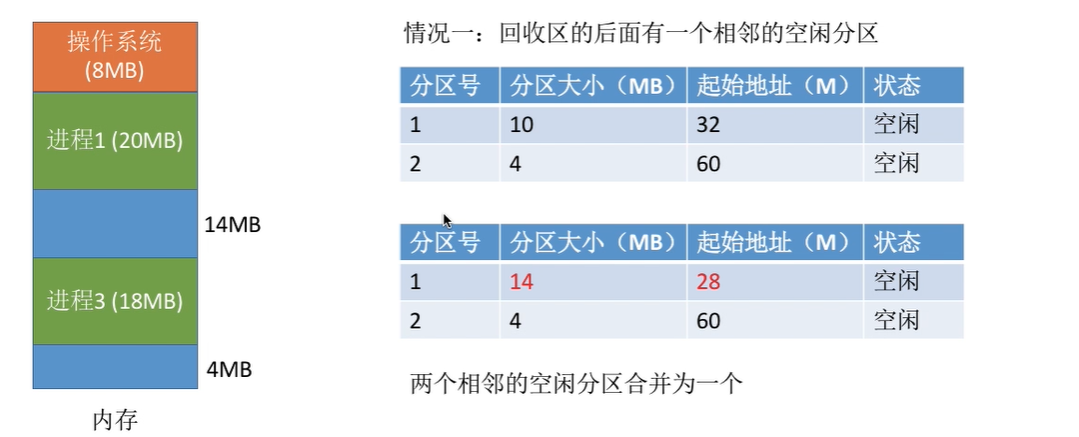
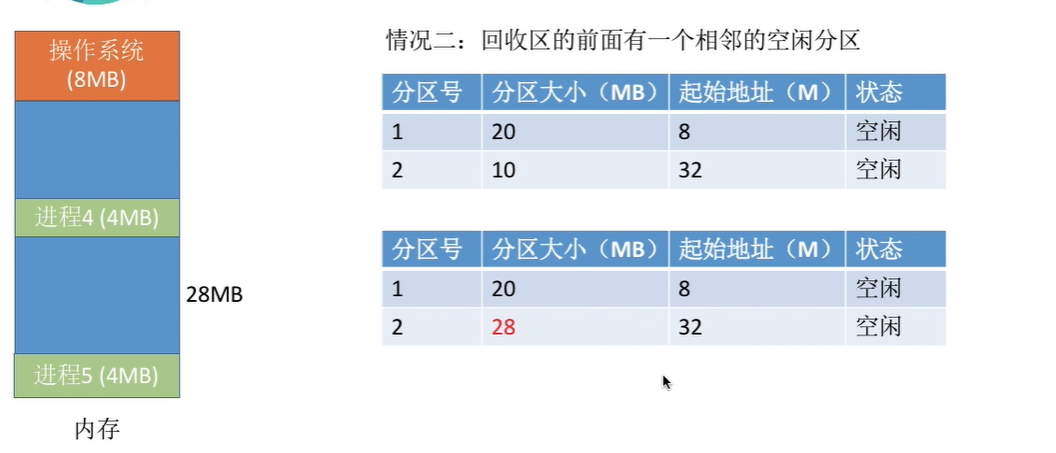
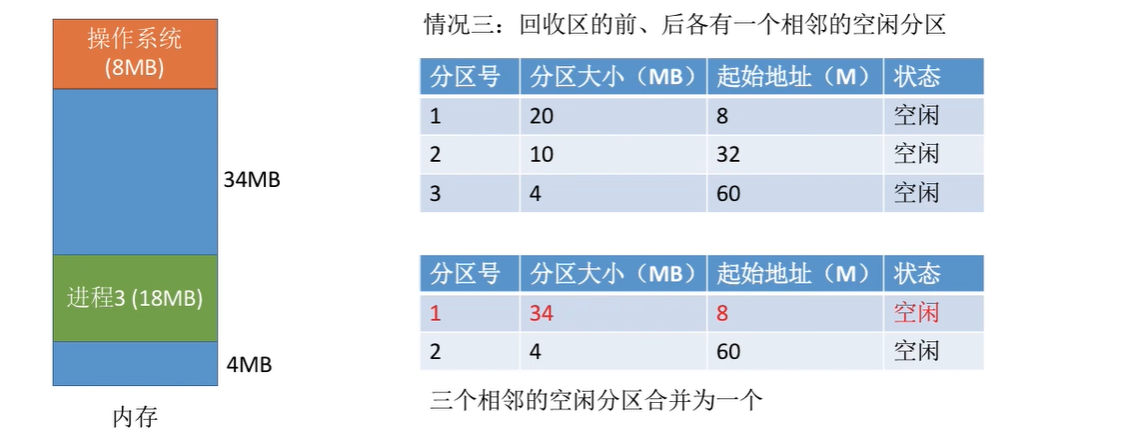
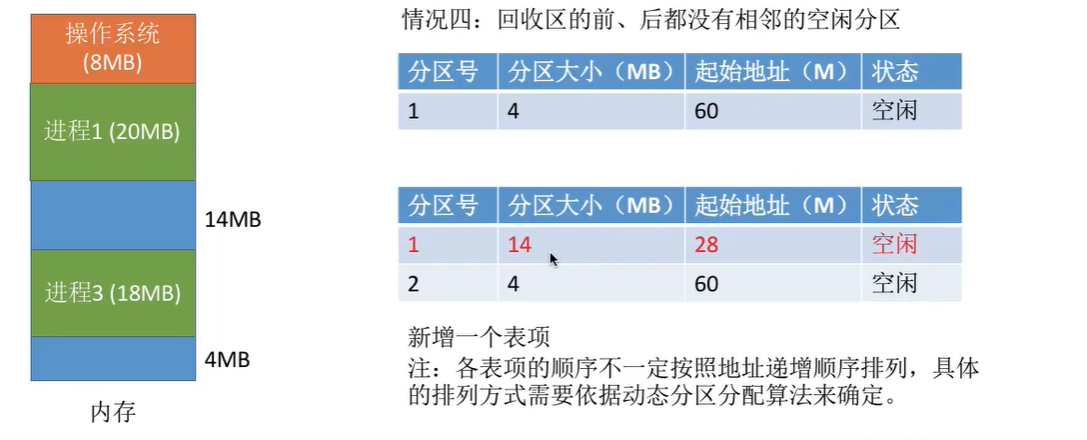
动态分配算法
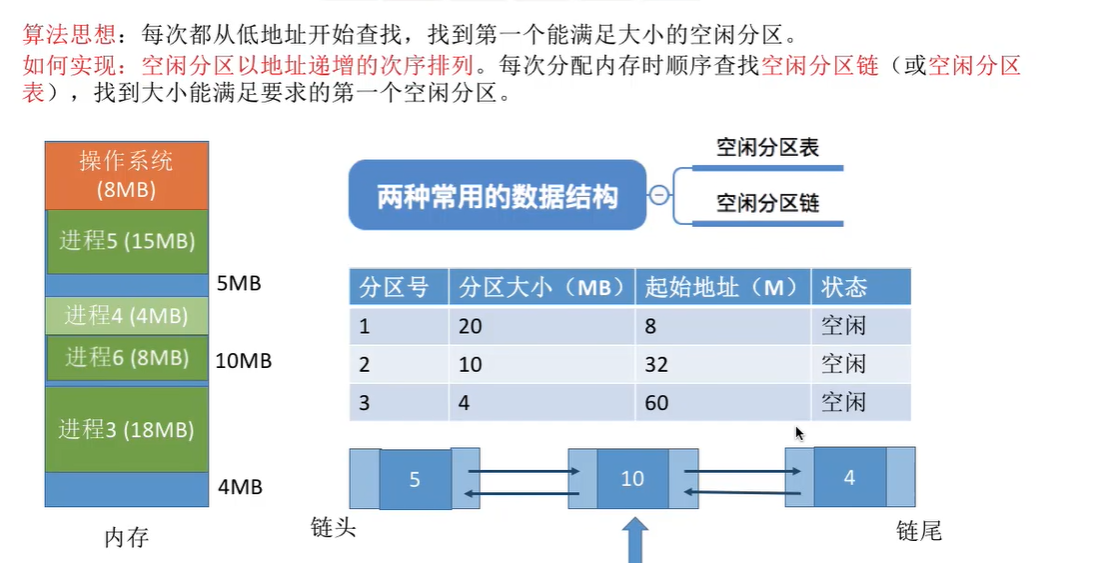
作业装入主存时,需要按照一定的分配算法从空闲分区链(表)中选择分区,以分配给该作业。按分区检索方式,分为顺序分配算法,索引分配算法。
基于顺序搜索的分配算法
- 顺序分配算法:依次搜索该空闲分区链上的空闲分区,以寻找大小满足要求的分区。
- 系统很大时,空闲分区链可能很长,顺序分配算法可能很慢。
- 分为以下四种:
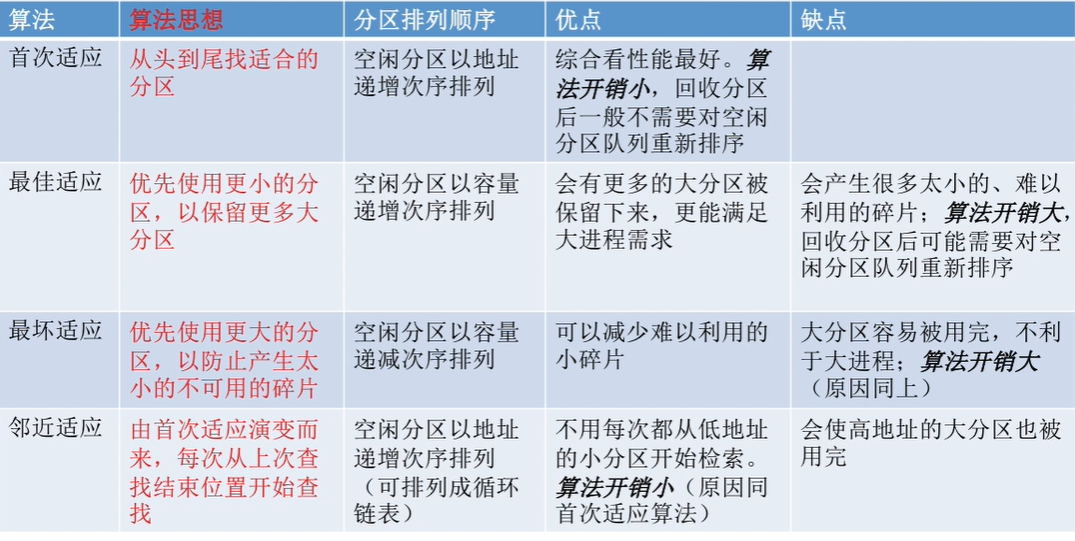
首次适应(First Fit)算法
邻近适应(Next Fit)算法
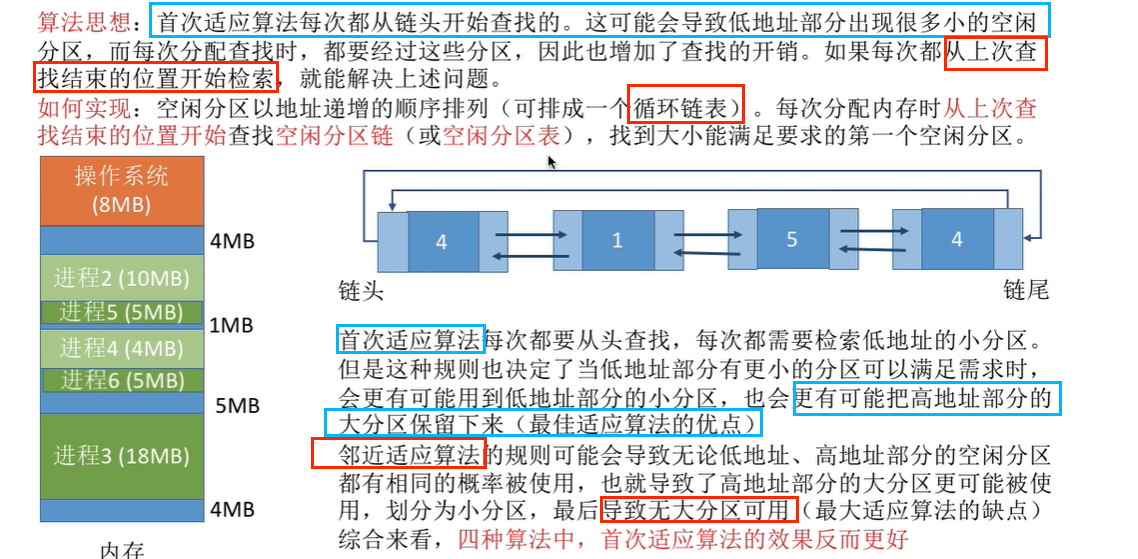
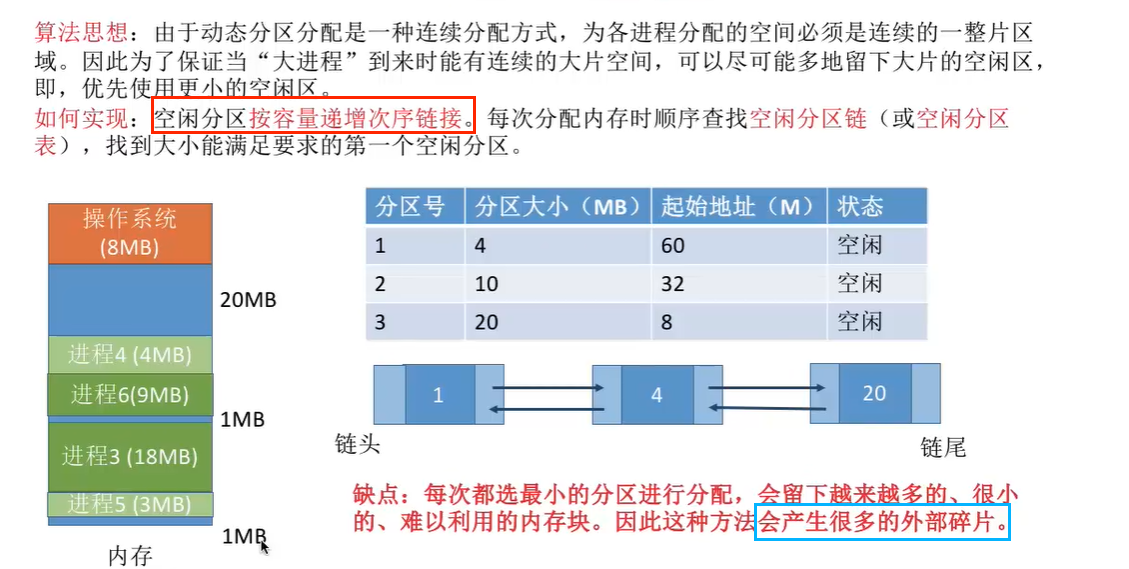
最佳适应(Best Fit)算法
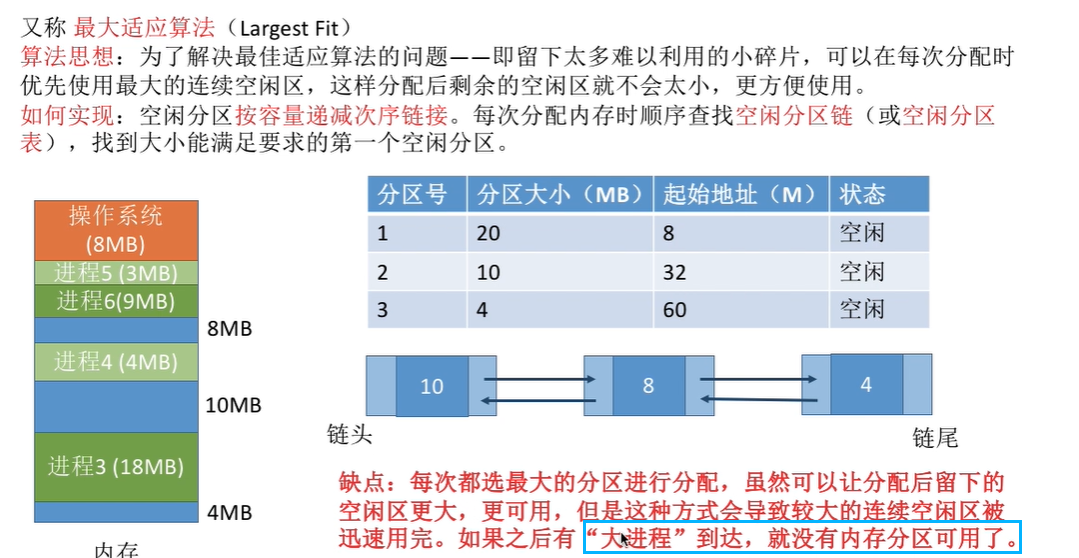
最坏适应(Worst Fit)算法
算法总述
基于索引搜索的分配算法
- 根据大小对空闲分区进行分类,每类(大小相同)空闲分区单独设置空闲分区链,并设置索引表来管理空闲分区链。
- 当为进程分配空间时,在索引表中查找所需空间大小对应的表项,从中多道对应空闲分区链的头指针,进而获得空闲分区。
快速适应算法
空闲分区分类依据:根据进程常用空间大小进行划分。
分配过程:
- 首先根据进程长度,在索引表中找到能容纳它的最小空闲分区链表。
- 从链表中取出第一块进行分配。
优点:查找效率高,不产生内部碎片。
缺点:回收分区时,需要有效合并分区,算法比较复杂,系统开销大。
伙伴系统
规定所有分区大小均为 2 的 k 次幂(k 为正整数)。
- 当请求分配大小为 n 时【2^(i-1) < n ≤ 2^i】,在大小为 2^i 的空闲分区链中查找;
- 若找到,则直接分配给进程。
- 否则,表示大小为 2^i 空闲分区已耗尽。需要在大小为 2^(i+1) 的空闲分区链 继续查找。
- 若找到,则将该空虚分区等分为两个大小为 2^i 的空闲分区,称为一对伙伴。将一个用于分配,一个插入大小为 2^i 的空闲分区链。
- 若不存在,则继续查找,直到找到。
- 回收时,可能需要对伙伴分区进行合并。
哈希算法
- 根据空闲分区链分布规律,建立哈希函数,构建以空闲分区大小为关键字的哈希表。每个表项记录一个对应空闲分区链的头指针。
- 分配时,根据所需分区大小,根据哈希函数计算所在哈希表中的位置,得到相应的空闲分区链表。
原文地址:https://blog.csdn.net/qq_74259765/article/details/140673591
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!