【comfyui教程】ComfyUI基础 - 从最简工作流透视AI绘画工作原理!
前言
前面我们成功安装了ComfyUI,并成功运行了ComfyUI的工作界面,这一篇我们通过一个简单的工作流深入了解AI绘画的工作原理。
所有的AI设计工具,安装包、模型和插件,都已经整理好了,👇获取~

启动并运行ComfyUI
进入ComfyUI根目录,双击run_nvidia_gpu.bat运行ComfyUI
运行完毕后,浏览器自动打开:http://127.0.0.1:8188/
然后我们点击这里,然后点击【默认】
然后界面中就会呈现这样一个工作流,也叫默认工作流:
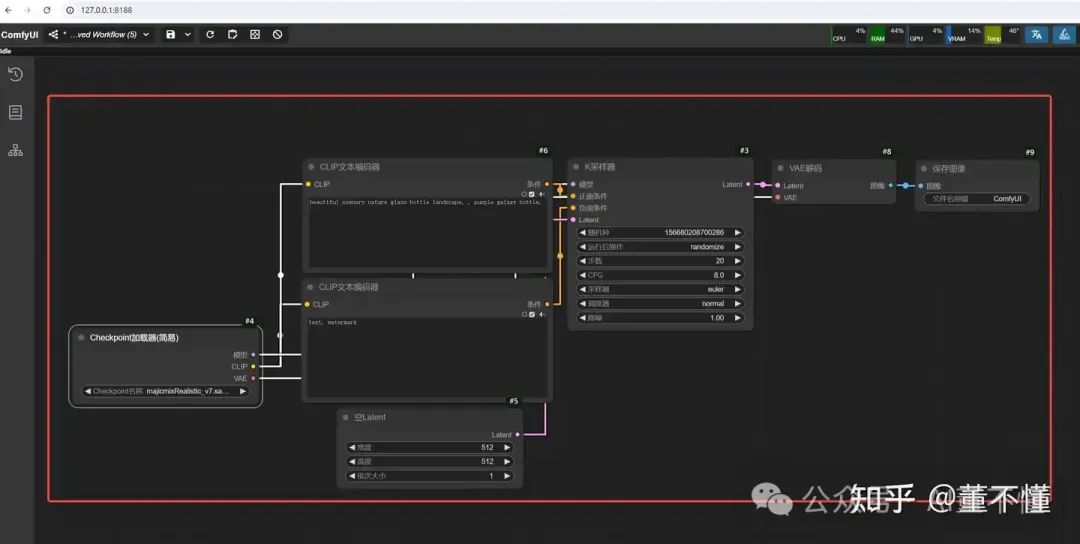
然后我们点击【执行队列】
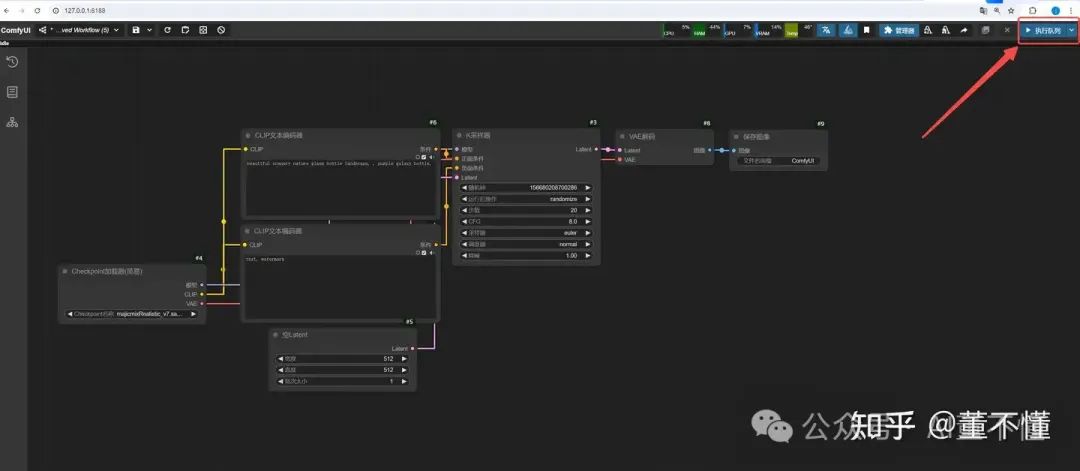
可以看到我们的第一幅AI画作就画出来啦:
生活类比
AI绘画的过程,可以和我们生活中艺术创作过程类似,我们先过一遍艺术创作过程,以【雕塑创作】为例:
`1.你给雕塑家一个任务:“我想要一个大理石雕像,表现的是一位拿着书的学者。” 2.雕塑家听完你的要求,会在脑海中形成一个概念,知道应该雕刻出一个学者拿着书的形象。 3.雕塑家开始工作时,并不会立刻有一个清晰的形象。相反,他从一块粗糙的大理石块开始,石头的表面一片混乱,看不出什么具体的形象。 4.雕塑家会逐步地凿掉多余的石头,一点一点地雕刻出学者的轮廓和细节。随着每一锤下去,雕像就越来越接近你所描述的样子。 5.最后,经过多次雕刻和打磨,一座精美的学者雕像就完成了,完全符合你最初的要求。`
有了这样一个艺术创作过程,我们把它和AI绘画做一个关联:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
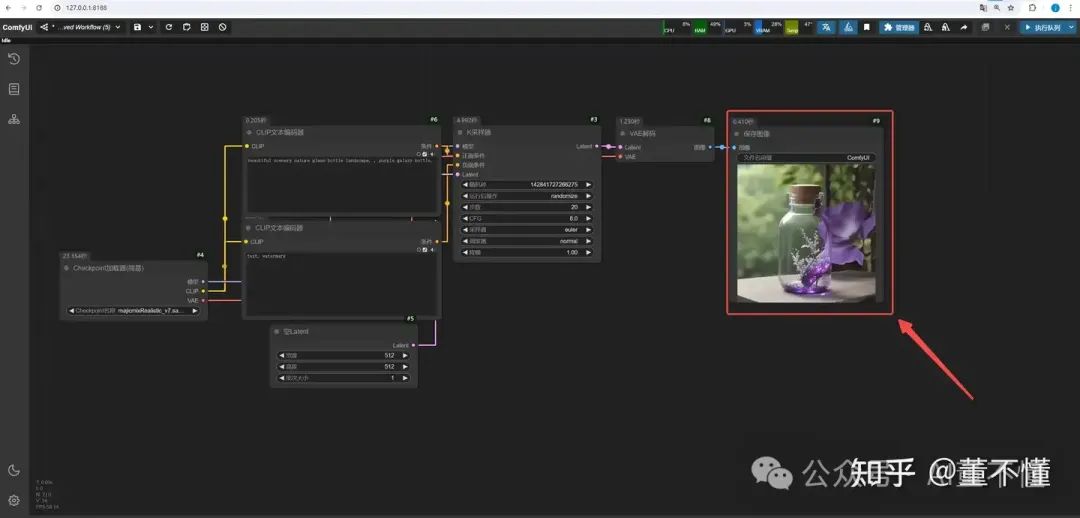
下图是AI绘画的工作原理,每一步都对应雕塑创作的每一步:
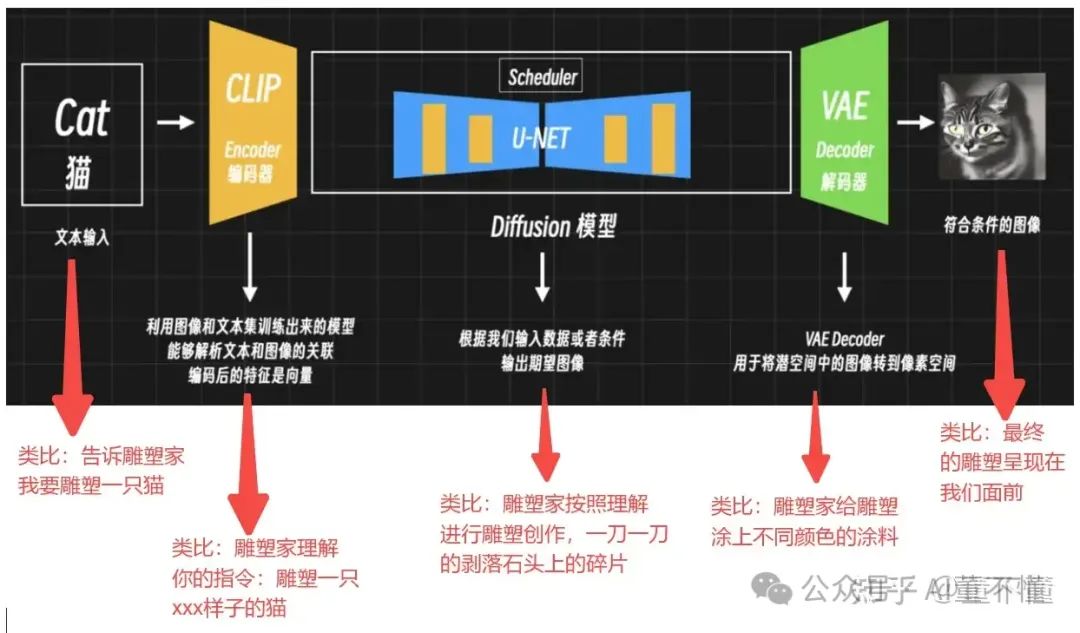
OK, 现在你应该对AI绘画有了一个初步感性的认识,我们继续深入研究。
工作流运行机制
我们回过头来,再来看那个工作流:
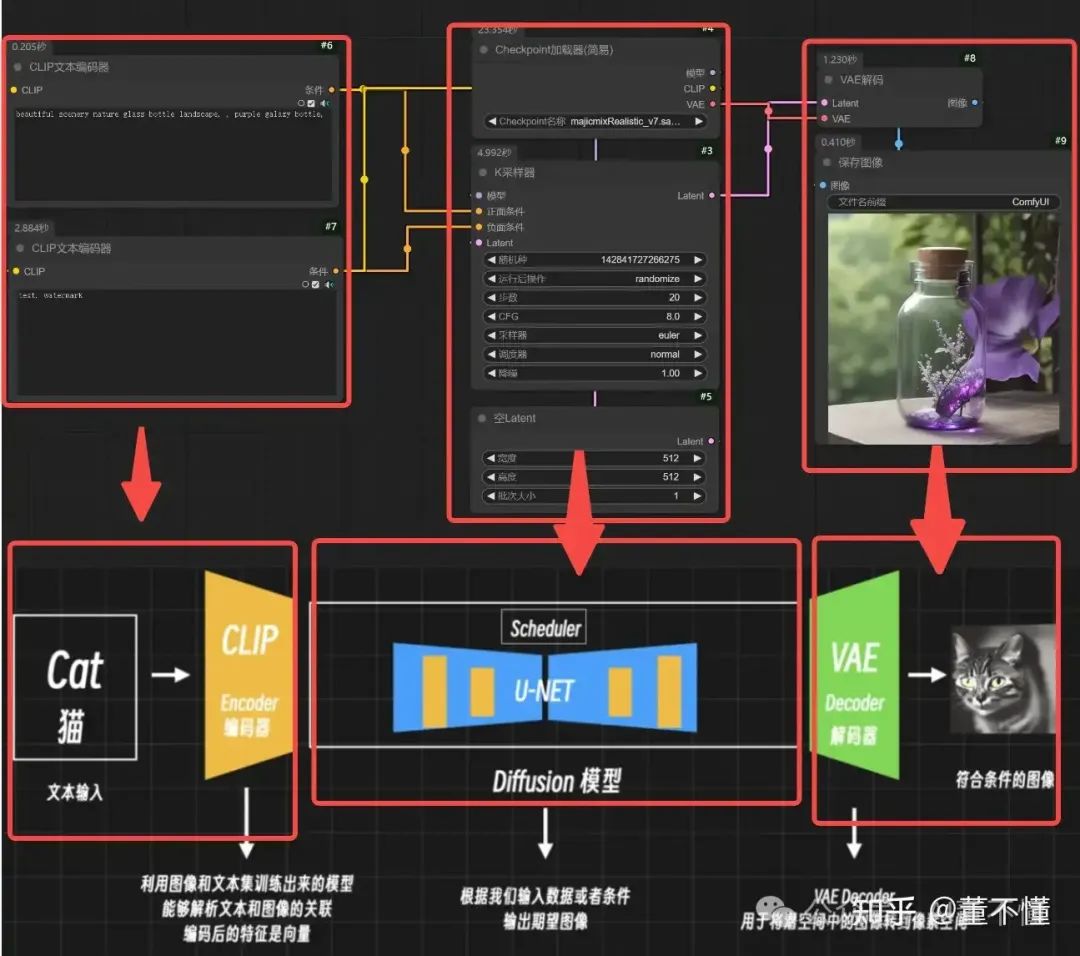
我们透过工作流,也能端倪一些AI绘画的工作原理,我们拆解以下,AI绘画的三大核心组件包括:
1、CLIP文本编码器
2、噪声预测器U-Net(Latent Diffusion模型:潜空间扩散模型)
3、VAE编码器(处理像素空间和潜空间的转化关系)
三大核心组件
我们先知识性的了解一下这三个组件的工作原理:
CLIP文本编码器
包括:文本编码器、图像编码器,这两个编码器会将现实世界中的文本和图像进行一个编码,形成n个文本向量和n个图像向量,它们构成n * n的向量矩阵,通过余弦相似度可以预测哪些图像和哪些文本真实的匹配,这样文本和图像之间就架构起了桥梁。这个过程是需要预先进行训练,因此CLIP是一种预训练模型。
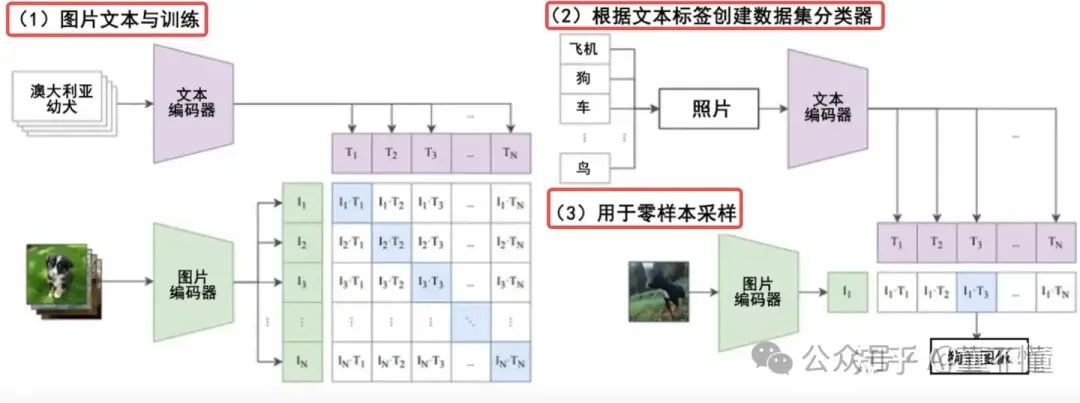
以上是预训练过程中,CLIP的工作内容,而在在文生图阶段,主要做3件事:
1.分词(Tokenization):文本编码器首先将输入的文本分解成单词或短语,然后将其转换为模型可以理解的格式。例如,单词"dog"可能会被分解成一系列的标记(tokens),这些标记与模型在训练时使用的词汇表相匹配。
2.嵌入(Embedding):每个标记被转换为一个高维空间中的向量,称为嵌入。这些嵌入向量能够捕捉单词的语义信息。例如,单词"dog"的嵌入向量会包含与"dog"相关的语义特征,底层使用余弦相似度进行相似度打分,通过相似度可以知道哪两个对象是相似的。
3.编码(Encoding):文本编码器使用基于Transformer的架构来处理这些嵌入向量,并通过自注意力机制(self-attention mechanism)来理解文本的上下文关系。编码过程生成了一系列的文本特征向量,这些向量捕捉了整个文本提示的语义信息。编码之后,CLIP就理解了原始文本的含义。编码过程的输出是一个固定长度的特征向量,这个向量序列包含了文本的语义信息,并且可以与图像信息相结合,以指导图像的生成过程。
第3步生成的特征向量会输送给U-Net进行指定生图过程,CLIP文本编码器提取的文本特征通过cross attention嵌入扩散模型的UNet中,具体来说,文本特征作为attention的key和value,而UNet的特征作为query。也就是说CLIP其实是连接Stable Diffusion模型中文字和图片之间的桥梁
噪声预测器U-Net
它是一个基于扩散模型进行工作的,我们先来看下什么是扩散模型,扩散模型分正向扩散和反向扩散:

正向扩散:将一个纯图像逐步添加噪声,最终形成一个完全是噪声的图像的过程。这个过程发生在预训练过程,通过正向扩散,模型可以学习图像的特征,便于和文本发生关系,这个过程的目的是为了让模型学会如何从纯噪声中恢复出有意义的图像。
反向扩散:模型通过迭代去噪来生成图像,每一步都会利用训练阶段学到的知识来预测和去除噪声,最终生成高质量的图像。
VAE编码器
VAE编码器,包括VAE编码器和VAE解码器
VAE编码器:将图像的像素转换为潜空间数据表示;
VAE解码器:将潜空间数据表示转换为图像的像素表示;
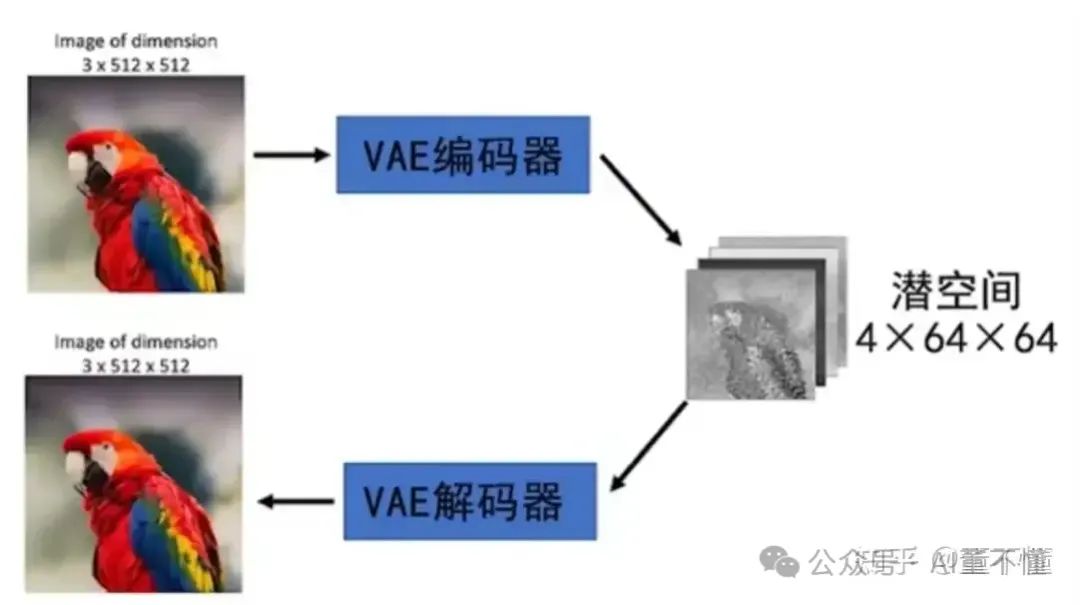
因为整个扩散过程是在潜空间进行,也就是U-Net只处理潜空间信息,不处理图像像素信息,所以就需要VAE将像素空间和潜空间进行一个转换,那什么是潜空间呢?
潜空间是指一个低维的、连续的、通常不可见的空间,用于表示高维数据(如图像、音频或文本)的潜在特征或属性。在潜空间中,每个点都对应一个潜在的表示,这个表示捕捉了数据的关键属性,并且可以通过解码过程生成原始数据的重建或新实例。
通常图像的像素都比较大,如果直接处理图像,计算量会非常大,引入潜空间后,我们就可以将高维的图像像素转为低维的潜空间,这样计算过程就很轻松。
深入工作原理
接下来我们再深入AI绘画的每一步,看看每一步都发生了什么?

基本工作原理
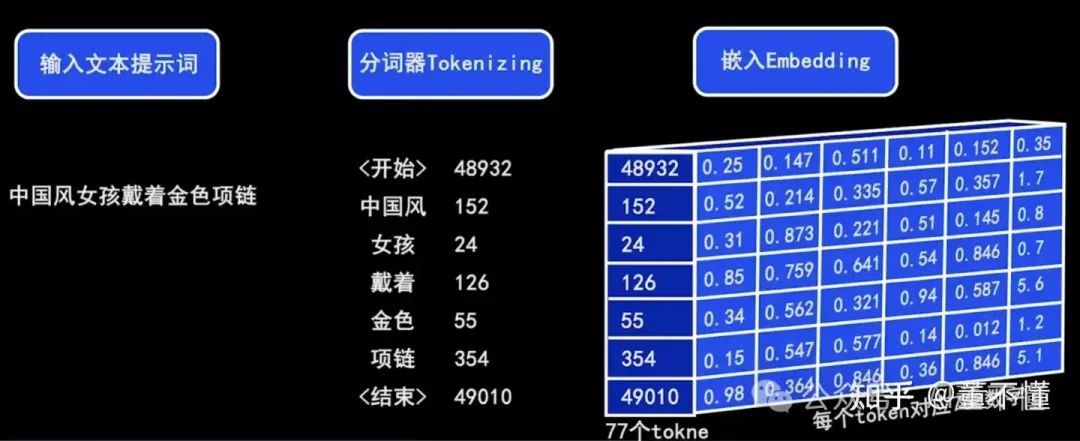
1、文本输入和文本理解
文本输入(我们告诉雕塑家,我要什么样的雕塑)
CLIP文本编码器中的文本框,是我们向AI发送指令的地方,把我们的想法告诉AI,但是这个想法是我们人类可以理解的文本,计算机AI并不理解,这时候CLIP文本编码器得到我们输入的文本之后,它会将我们的文本翻译为计算机AI可以理解的数据。
文本理解(雕塑家理解我们的诉求,并开始打腹稿)
2、噪声预测和分步骤降噪(采样)
“特征向量”输送到潜空间,进行噪声预测和降噪,这个模型会预测噪声和特征向量的关联关系,分步骤去除噪声,最终生成和特征向量相关的图像。(雕塑家逐步凿掉多余部分、雕刻细节的过程。)
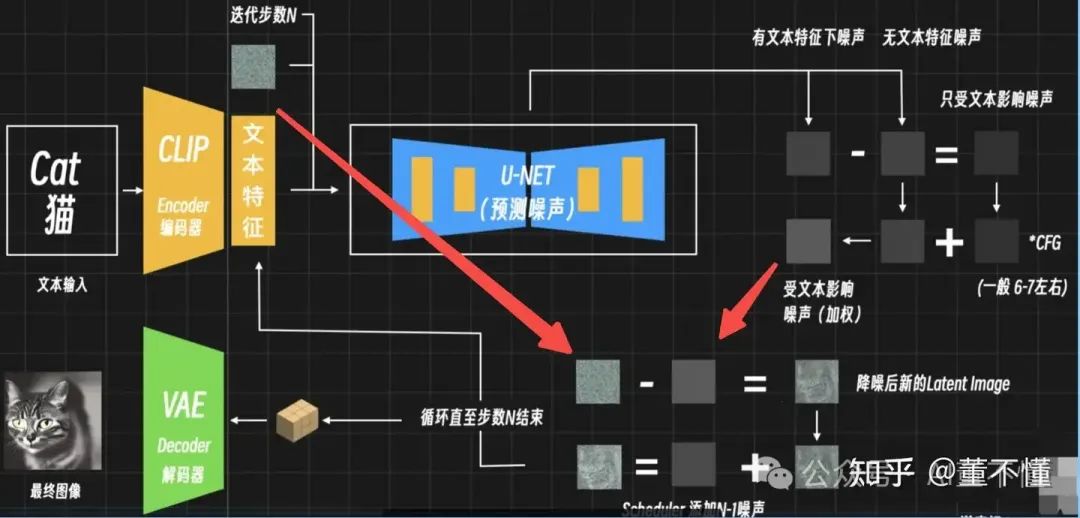
3、VAE解码器将图像从潜空间转换到像素空间
U-Net生成的图像,还不是我们能看到的图像,因为U-Net处理的图像是潜空间,【潜空间像素】可以理解为图像像素的另一种数据表示,采样的过程是在潜空间进行,因此需要VAE解码器将潜空间转换为我们能看得见的图像。
为了帮助大家更好地掌握 ComfyUI,我在去年花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
原文地址:https://blog.csdn.net/2401_84760719/article/details/143689479
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!