多级缓存架构设计
欢迎关注公众号 【11来了】 ,持续 中间件源码、系统设计、面试进阶相关内容
在我后台回复 「资料」 可领取
编程高频电子书!
在我后台回复「面试」可领取硬核面试笔记!文章导读地址:点击查看文章导读!
感谢你的关注!
多级缓存架构设计
对于并发量高的数据一般会采用多级缓存来提升访问效率,越前置的缓存容量越小、访问越快、抗并发能力越强,接下来会介绍如何组成多级缓存架构,看完之后将会知道:
多级缓存架构包括哪些?
数据一致性如何解决?
请求流经多级缓存流程?
复杂的缓存重建如何解决?
多级缓存架构介绍
首先介绍一下多级缓存架构,通用的多级缓存常常包括:本地内存、Redis、DB 三个部分,本地内存作为 Tomcat 服务的一部分,可以承受的请求数量有限,因此对于更高流量的要求,需要再次对多级缓存进行升级改造,如下:
- 应用 Nginx 本地内存
- Redis 缓存
- JVM 内存
- DB
这里 Nginx 分为两层:
- 接入层 Nginx:处理入口流量,用作流量分发
- 应用层 Nginx:接近业务层,处理业务逻辑,用作热点缓存的读取
Nginx 作为高性能的 Web 服务器,经常被作为反向代理服务器用作负载均衡,这里多增加了一层应用层 Nginx,用来处理 热点缓存数据 ,相比于 Tomcat 集群的本地内存来说,可承接的流量更高
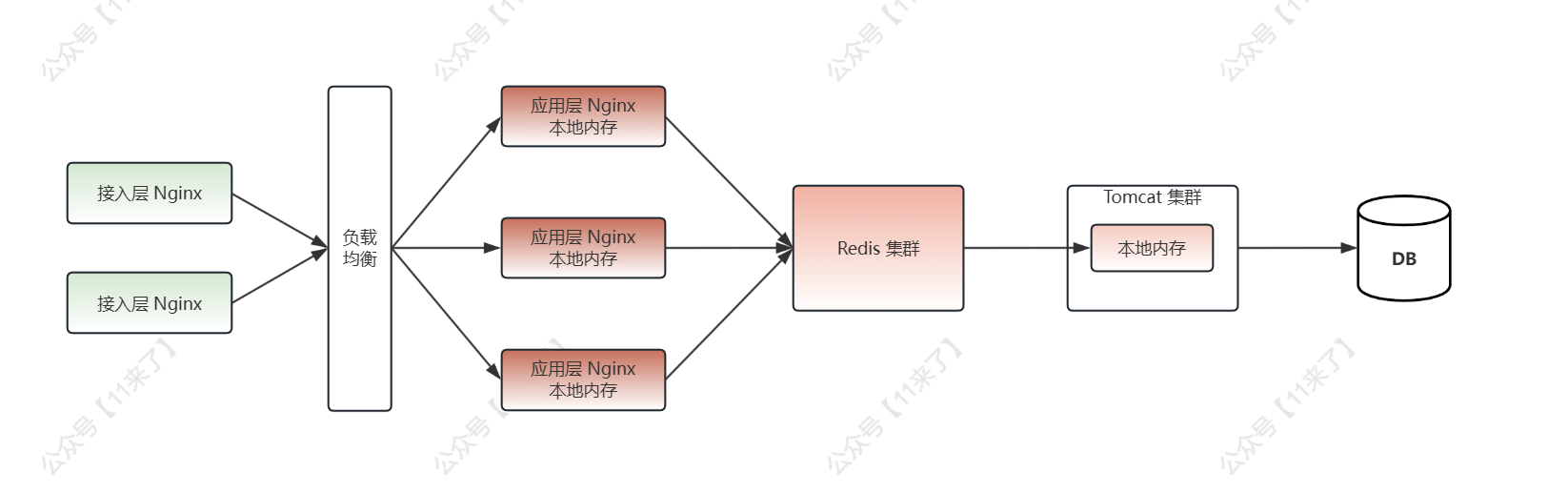
多级缓存请求流程
用户请求进入到接入层 Nginx 之后,会经过负载均衡算法进行分发:
- 用户请求被 负载均衡 到各个应用层 Nginx 上
- 在应用层 Nginx 上,读取 本地缓存 , 降低对热点数据后端服务的冲击
- 如果 Nginx 本地缓存未命中,则读取 Redis 缓存 ,作为第二层缓存, 减少对 Tomcat 集群的压力
- 如果 Redis 缓存未命中,则读取 Tomcat 集群的本地内存,作为第三层缓存, 防止缓存雪崩/穿透之后对 DB 的冲击
- 如果仍然未命中,则读取 DB,并回写多级缓存
接下来逐个介绍流程中相关的一些问题,如负载均衡算法的选择、应用层 Nginx 读取本地缓存的实现方式、缓存更新的脏写问题等等
负载均衡算法的选择
只要是路由到多个节点,都需要负载均衡算法进行节点选择,负载均衡算法有很多,常用的有:轮询和一致性哈希
轮询负载均衡
轮询的优势在于:
- 对请求的负载更加均衡
缺点在于:
- 相同的请求会被转发到不同的节点,因此随着节点的增多,缓存命中率不断降低
一致性哈希
一致性哈希的优势在于:
- 相同的请求会被路由到同一台机器上
- 如果出现节点宕机,只会少部分缓存数据失效
缺点在于:
- 相同的请求路由到同一台机器上,会导致大量请求集中在某台机器上
负载均衡算法选择
- 当负载较低,此时我们更追求缓存的命中率,因此可以使用一致性哈希
- 当负载较高,肯定是热点数据的访问,让热点数据在多节点都存储,此时更加追求请求的平均分散
应用层 Nginx 本地缓存实现
在应用层 Nginx 本地缓存可以使用 Lua Shared Dict 来实现,Lua Shared Dict 是 OpenResty 提供的功能
OpenResty 是一个强大的 Web 平台,将 Nginx 和 Lua 语言集成起来,可以通过 Lua 开发相关业务逻辑,进行热点数据的查询、获取等操作
通过 Lua 可以拿到 Nginx 本地缓存数据,并且也可以请求 Redis 获取缓存数据
热点数据实现
应用层 Nginx 会进行第一层的数据处理,并且在这里会存储热点数据,因此需要在这一层对热点数据进行统计
应用层 Nginx 会将请求上报到 热点发现系统 ,热点发现系统可以进行热点数据的统计,并且将热点数据进行推送(推送到应用层 Nginx 本地缓存)
数据缓存优化
对于不同类型的数据也需要进行对应的缓存优化,如复杂数据的缓存重建、大 Value 问题、热点缓存等
数据缓存过期时间
对于缓存数据的加载有两种:
- 设置过期时间:适合热点、易更新数据,如库存数据缓存几秒,可以短时间内不一致
- 不设置过期时间:适合非热点、长期访问数据,如用户信息、店铺信息、类别、订单等信息
对于 缓存数据淘汰 来说,设置过期时间的数据到时间后就会自动删除,而不设置过期时间的数据,我们需要控制缓存的大小,当缓存空间满了之后,通过淘汰策略进行数据的删除
对于 淘汰策略 来说,有多种算法可供选择:
-
LRU(Least Recently Used,最近最少使用) 根据访问 时间 淘汰最久未被访问的数据;但是对于大批量数据访问来说,会导致缓存命中率下降
-
LFU(Least Frequently Used,最近最不常用) 根据访问 频率 淘汰最不常访问的数据;如果访问内容发生较大变化,会导致缓存命中率下降
-
ARC(Adaptive Replacement Cache,自适应缓存替换)算法,结合了 LRU、LFU 两者的优势,既能根据 时间 又能根据 频率 进行数据的淘汰
对于缓存的加载可以使用 缓存旁路模式 ,先写数据库,再写缓存;对于更新来说,先更新数据库,再删除缓存
对于 查询频率较高的数据 ,如商品数据,当数据修改时不能先删除缓存,如果先删除缓存,会有大量请求出现缓存 miss;而对于 查询频率较低的数据 ,如用户数据,可以先删除缓存
增量化缓存重建
对于复杂数据来说,缓存重建的成本较高,可以通过两个步骤减少缓存重建成本:
- 对复杂数据进行维度划分
- 根据增量数据的变更,只进行对应维度的缓存重建
比如对于商品来说,有多个维度:基础信息、图片、规则、介绍等等,维度化之后的缓存冲减成本大大降低
缓存的更新
如果多个节点同时操作一份缓存数据,那么可能发生缓存数据的覆盖,导致缓存出现脏数据,常用的解决如:
- CAS 乐观锁:通过版本比较来完成数据更新
- 将操作同一份数据的更新请求顺序化,消费端单线程处理保证更新不乱序
- 单节点更新缓存数据:如使用 canal 订阅 MySQL 的 binlog,之后去处理对应 binlog 完成缓存数据的更新,避免多个节点更新同一份缓存
原文地址:https://blog.csdn.net/qq_45260619/article/details/142919698
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!