翻译: GPT-4 with Vision 升级 Streamlit 应用程序的 7 种方式一
随着 OpenAI 在多模态方面的最新进展,想象一下将这种能力与视觉理解相结合。
现在,您可以在 Streamlit 应用程序中使用 GPT-4 和 Vision,以:
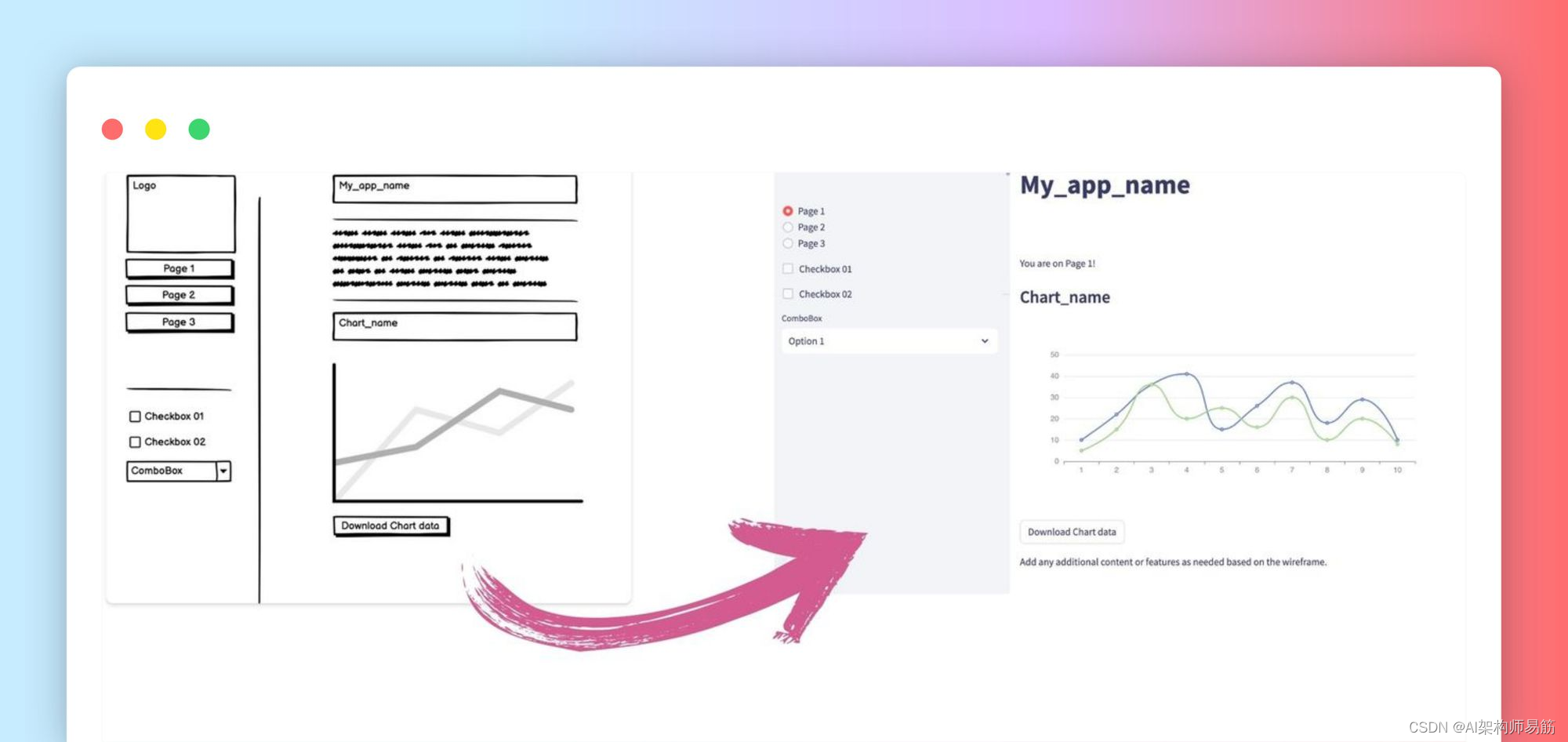
- 从草图和静态图像构建 Streamlit 应用程序。
- 帮助你优化应用的用户体验,包括调试和文档。
- 克服LLM的局限性和幻觉hallucinations。
在本文中,我将带您了解 8 个实际用例,这些用例举例说明了将 GPT-4 与 Vision 结合使用的新可能性!
1. 人工智能中的多模态简史
在我们深入研究各种用例之前,重要的是要为多模态奠定一些概念基础,讨论开创性模型,并探索当前可用的多模态模型。
多模态(Multi-modal LLMs) LLMs 是一种基于多种类型的数据(如文本、图像和音频)进行训练的 AI 系统,而不是专注于单一模态的传统模型。
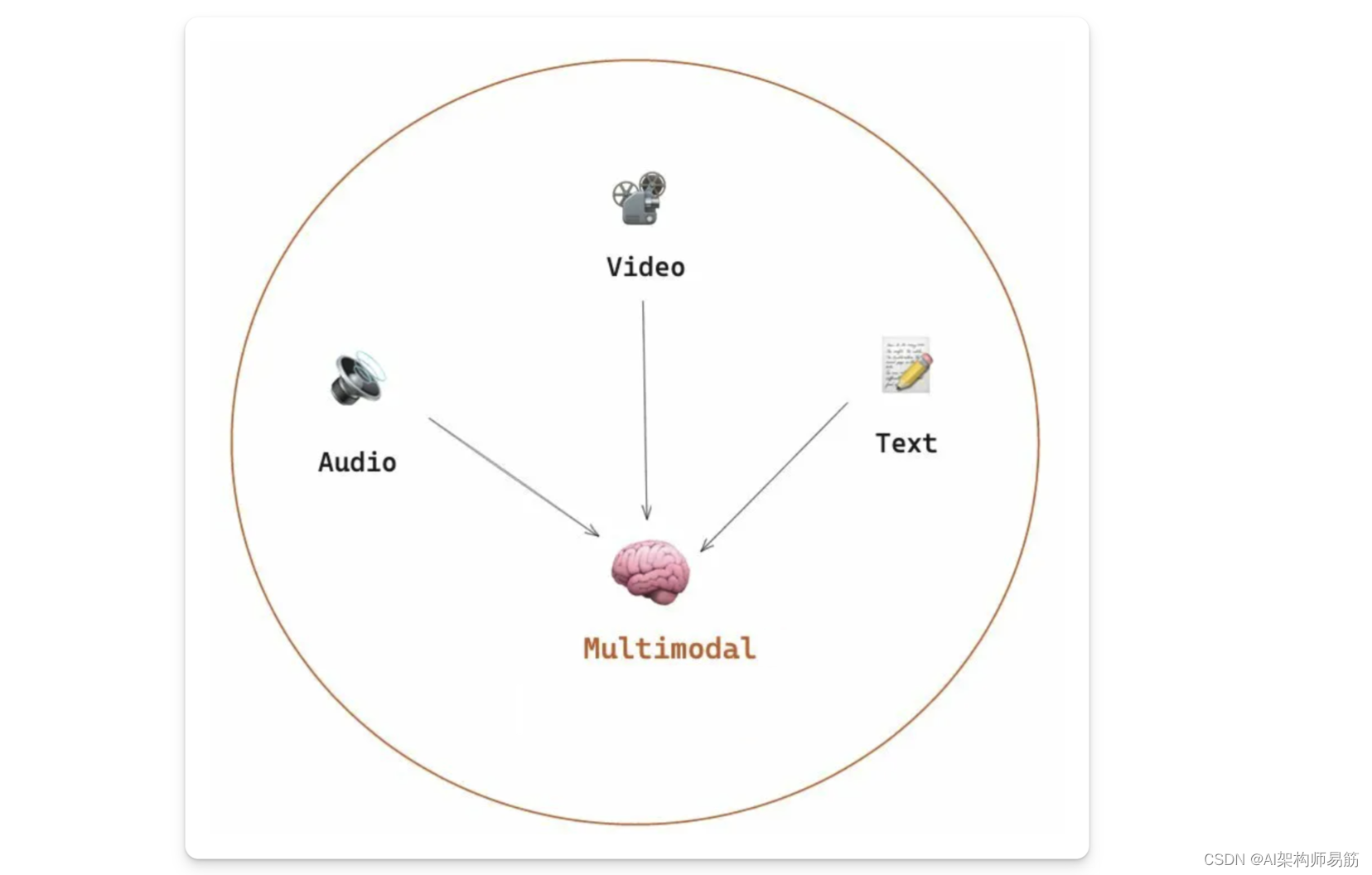
近年来,多模态的旅程取得了长足的进步,各种模式都铺平了道路:
- CLIP 是 OpenAI 于 2021 年推出的 OG 模型,它是一种开创性的模型,能够以零样本和少样本学习的方式泛化到多个图像分类任务。
- 2022 年发布的 Flamingo 以其在多模态领域生成开放式响应方面的强劲表现而著称。
- Salesforce 的 BLIP 模型是一个统一视觉语言理解和生成的框架,可提高一系列视觉语言任务的性能。
GPT-4 with Vision 建立在开创性模型的基础上,以推进视觉和文本模式的整合。然而,它并不是当今唯一争夺注意力的多模态模型;Microsoft 和 Google 也越来越受欢迎:
- Microsoft 的 LLaVA 使用预先训练的 CLIP 视觉编码器,尽管数据集较小,但仍提供与 GPT-4 相似的性能。
- Gemini 是 Google 的多模式模型,它之所以脱颖而出,是因为它从根本上设计为多模式。
参考
https://blog.streamlit.io/7-ways-gpt-4-vision-can-uplevel-your-streamlit-apps/
原文地址:https://blog.csdn.net/zgpeace/article/details/135890457
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!